Share
Japan Community Day at KubeCon + CloudNativeCon Japan 2025で発表した資料です。
イベントについて詳しくはこちらでご覧ください https://community.cncf.io/events/details/cncf-cloud-native-community-japan-presents-japan-community-day-at-kubecon-cloudnativecon-japan-2025/
![Programmable Bandwidth Management with eBPF 2025/06/15 Takeru Hayasaka <[email protected]> Japan](https://files.speakerdeck.com/presentations/89be304cbd8240e3a5f31115f40eb4ca/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
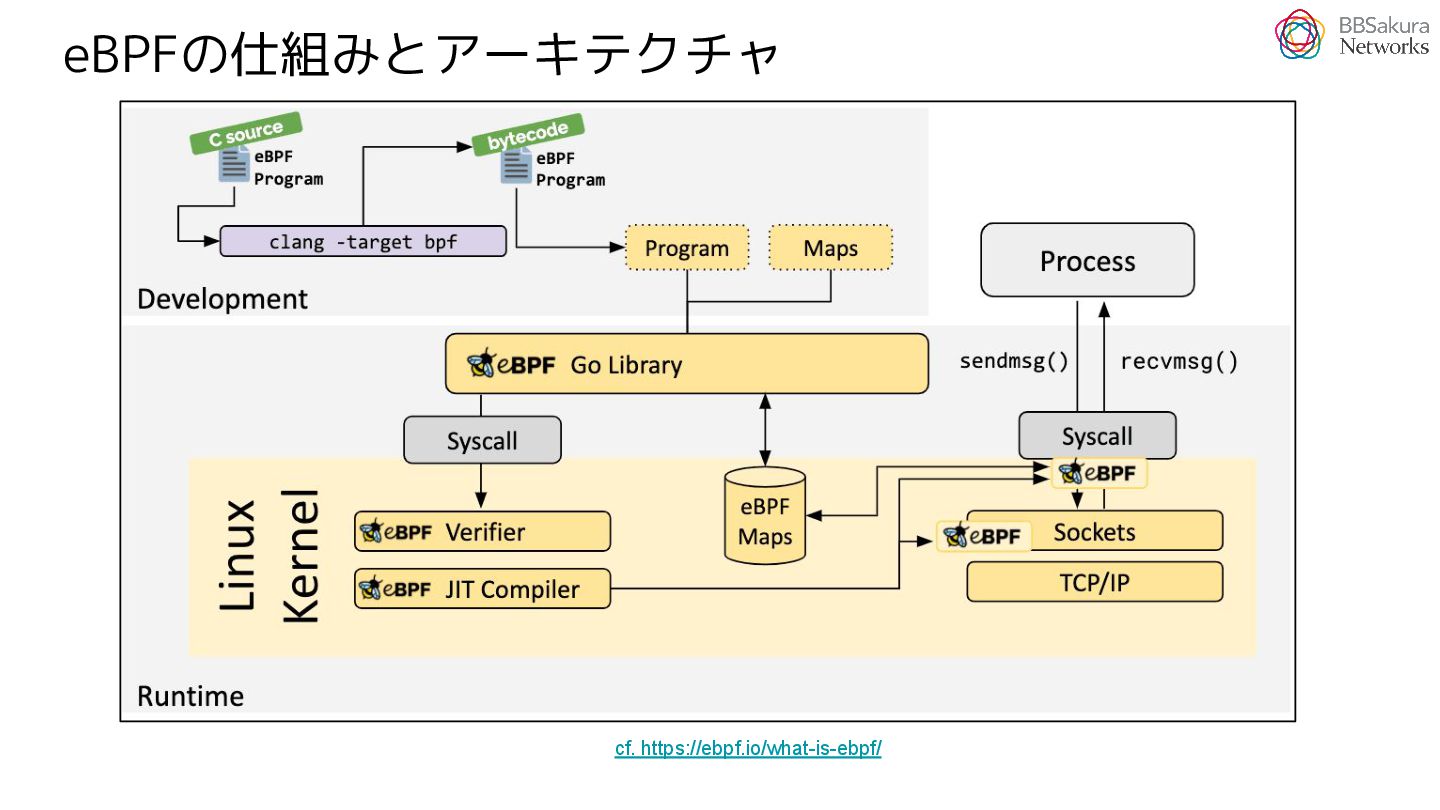{kind=link}
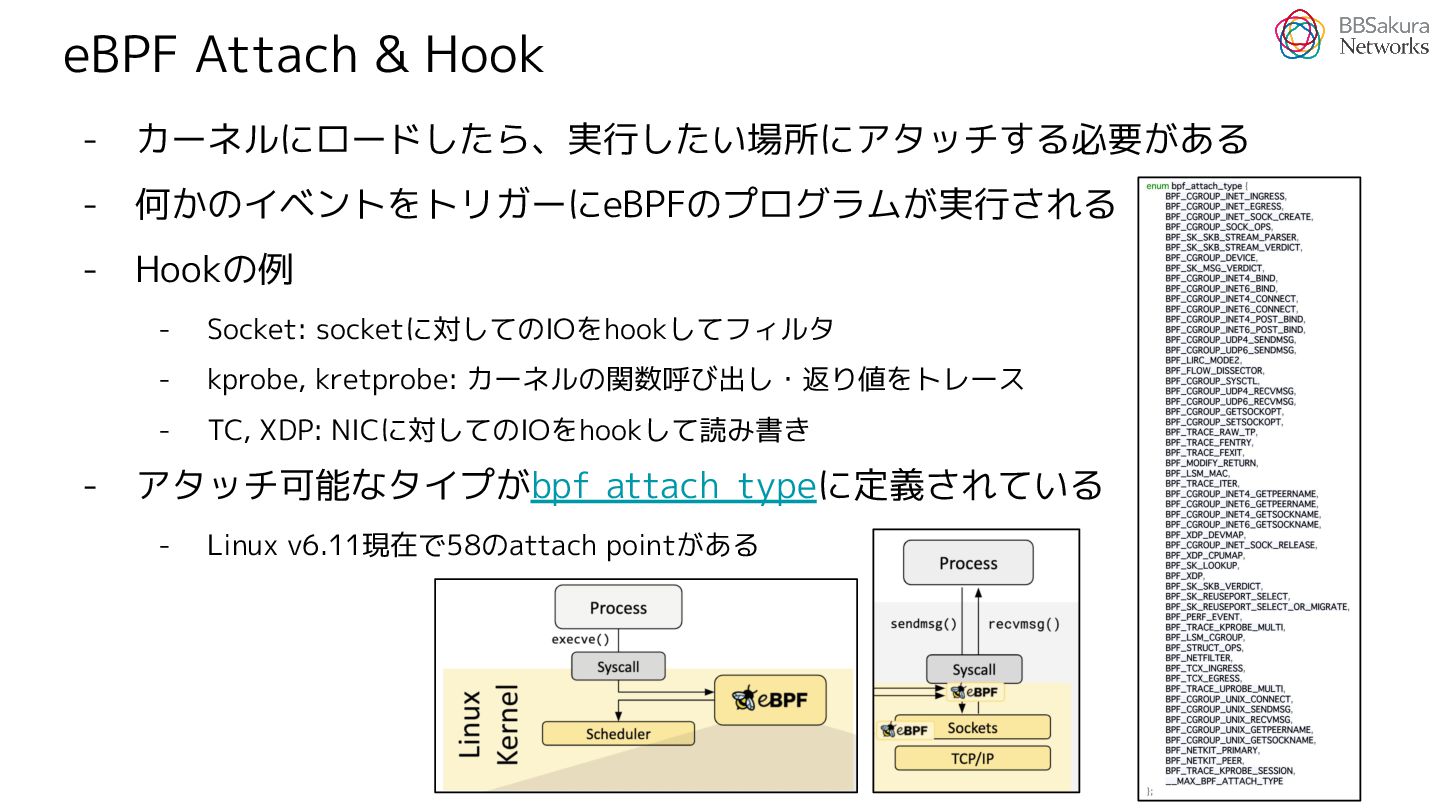{kind=link}
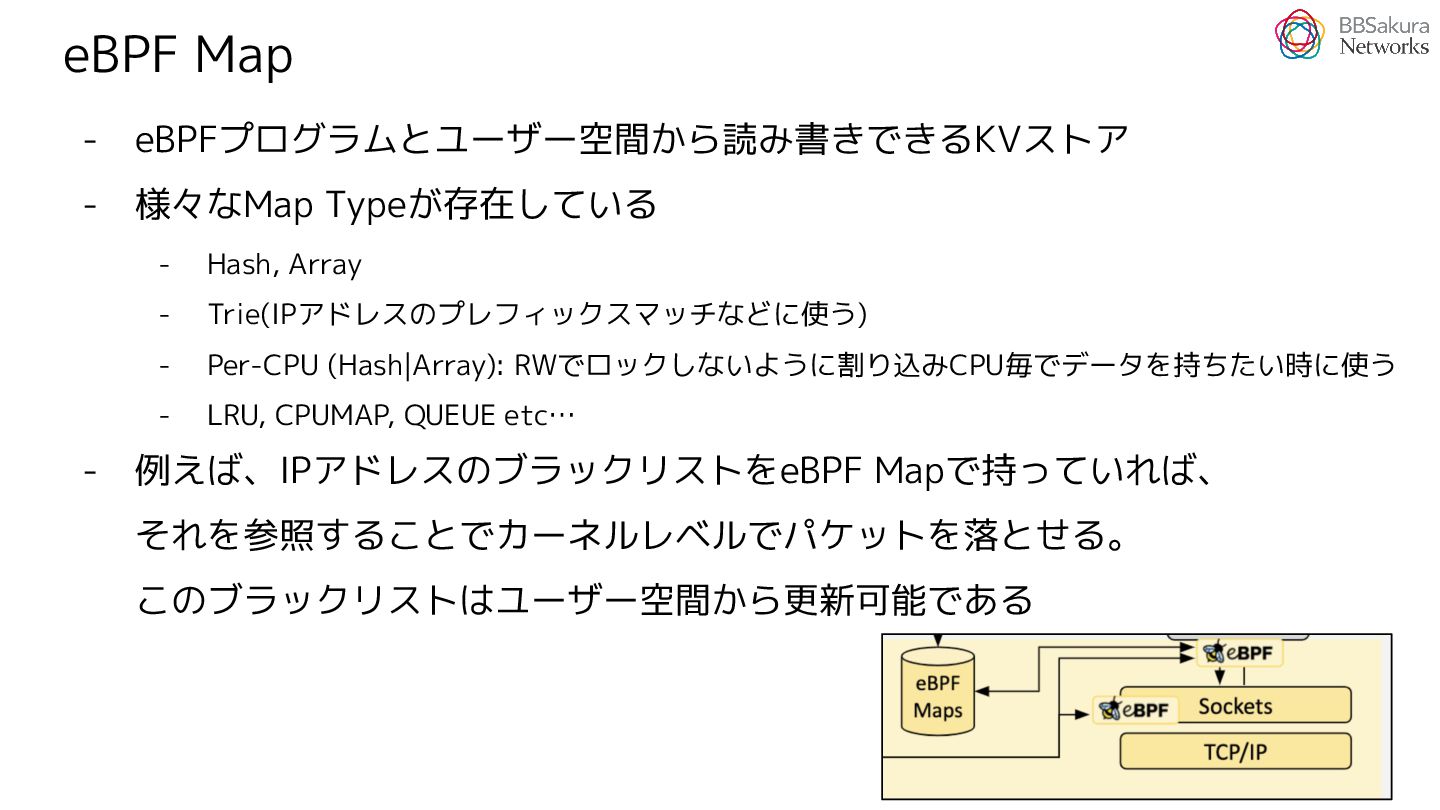{kind=link}
{kind=link}
{kind=link}
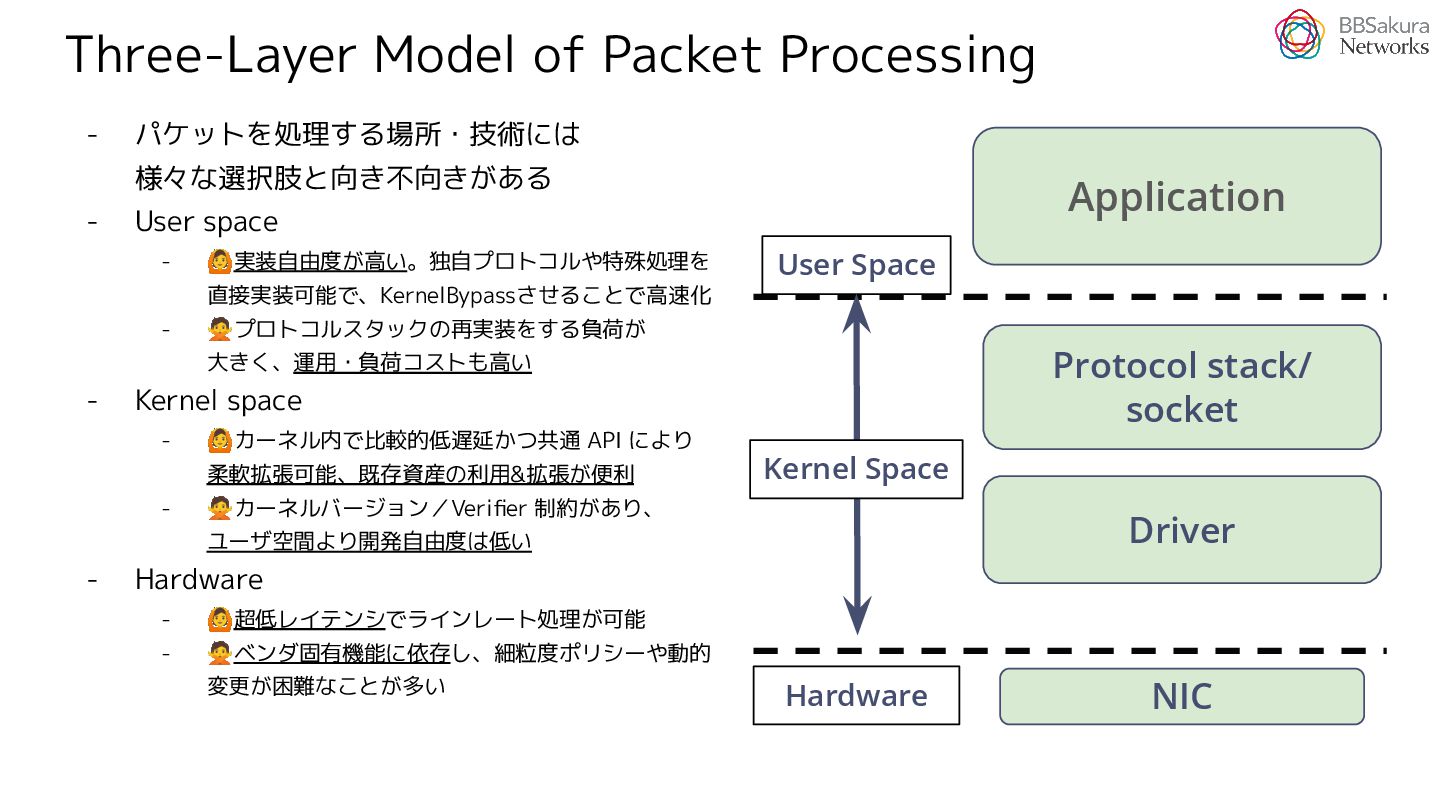{kind=link}
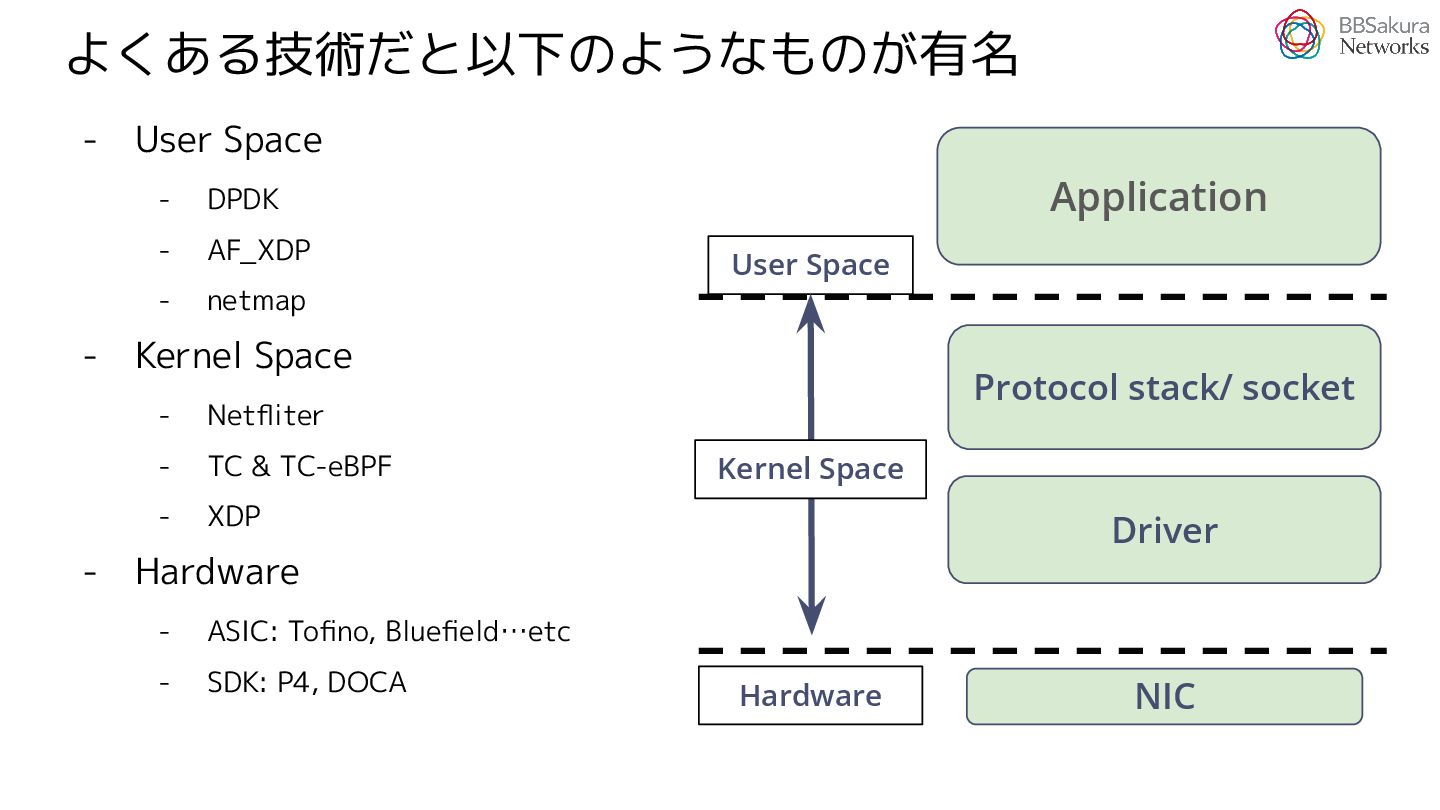{kind=link}
{kind=link}
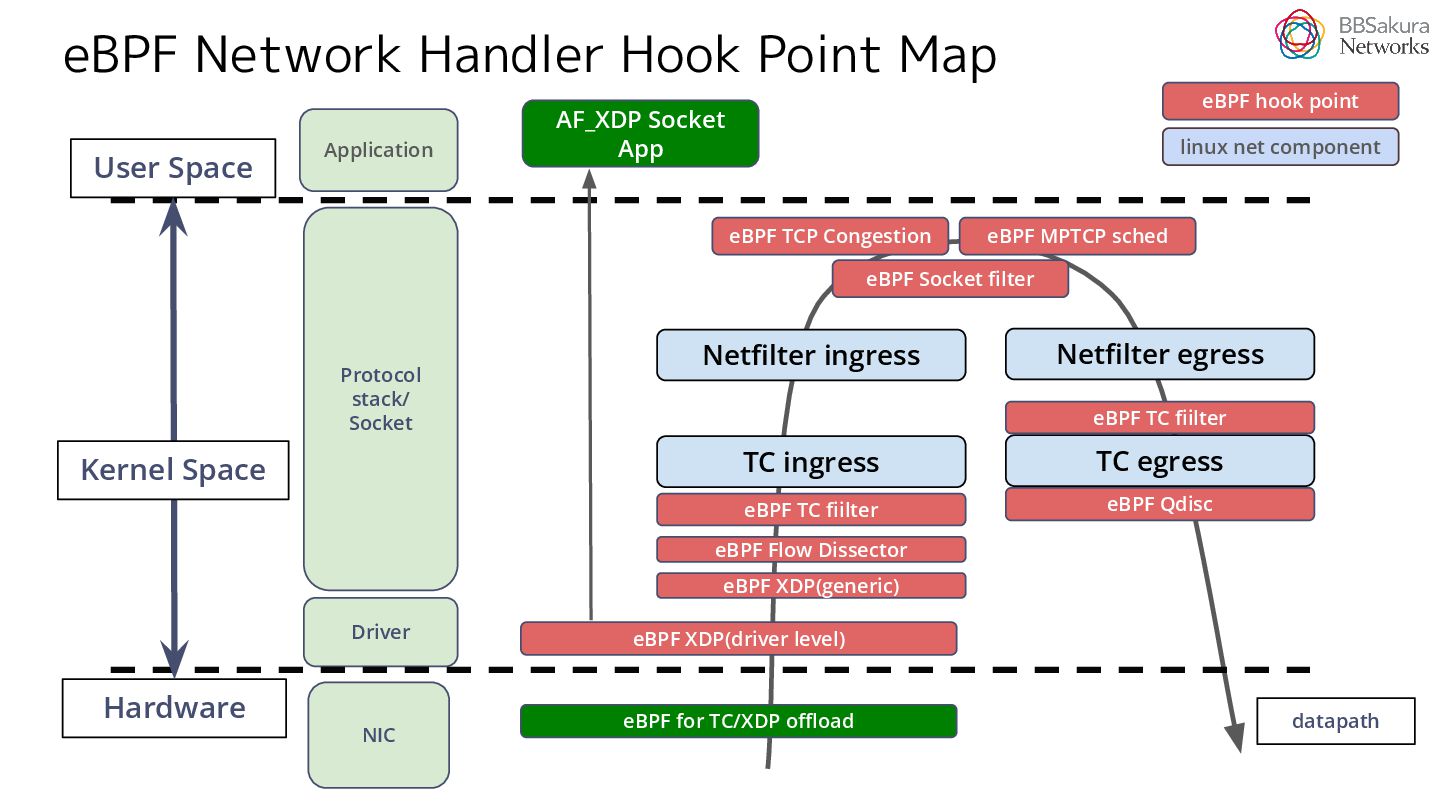{kind=link}
{kind=link}
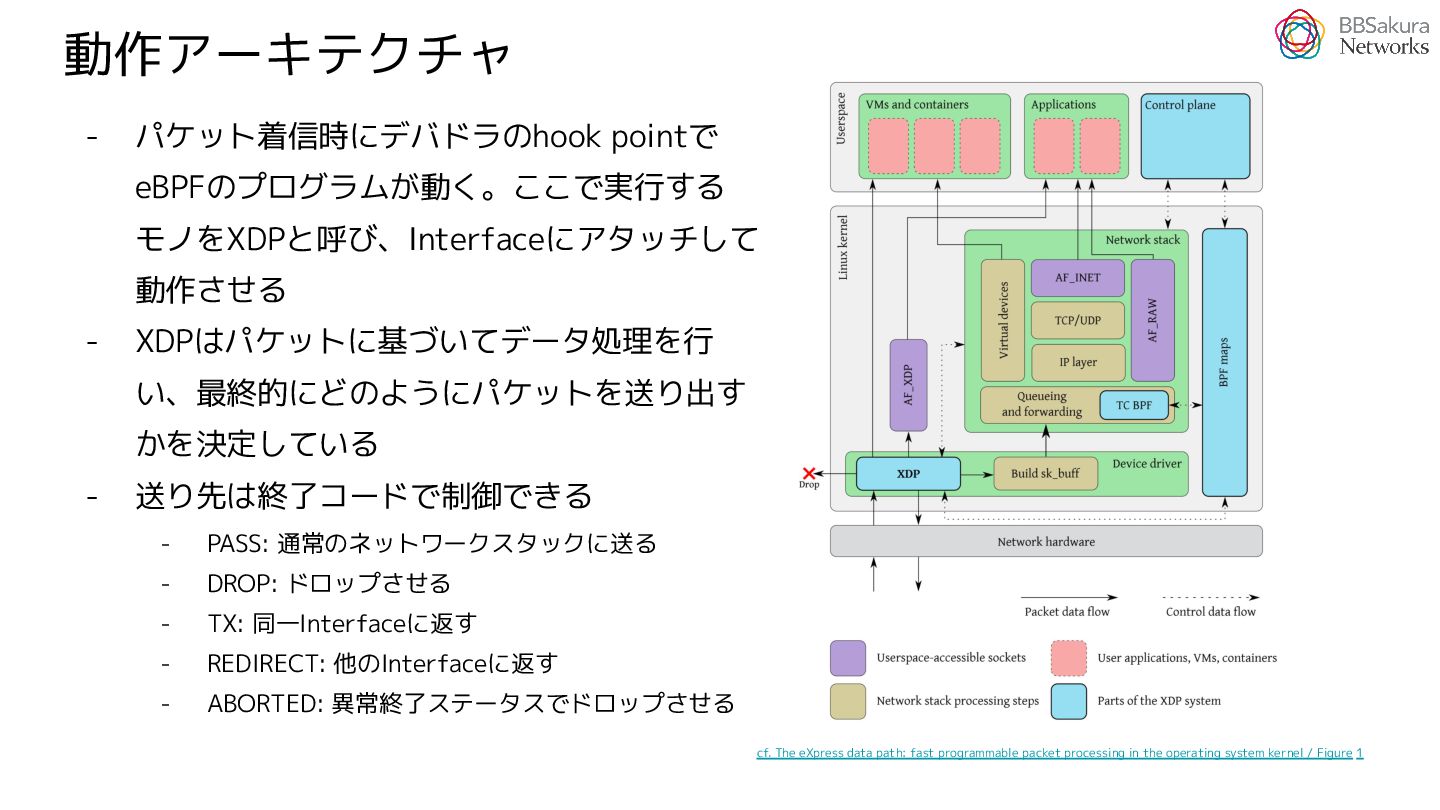{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
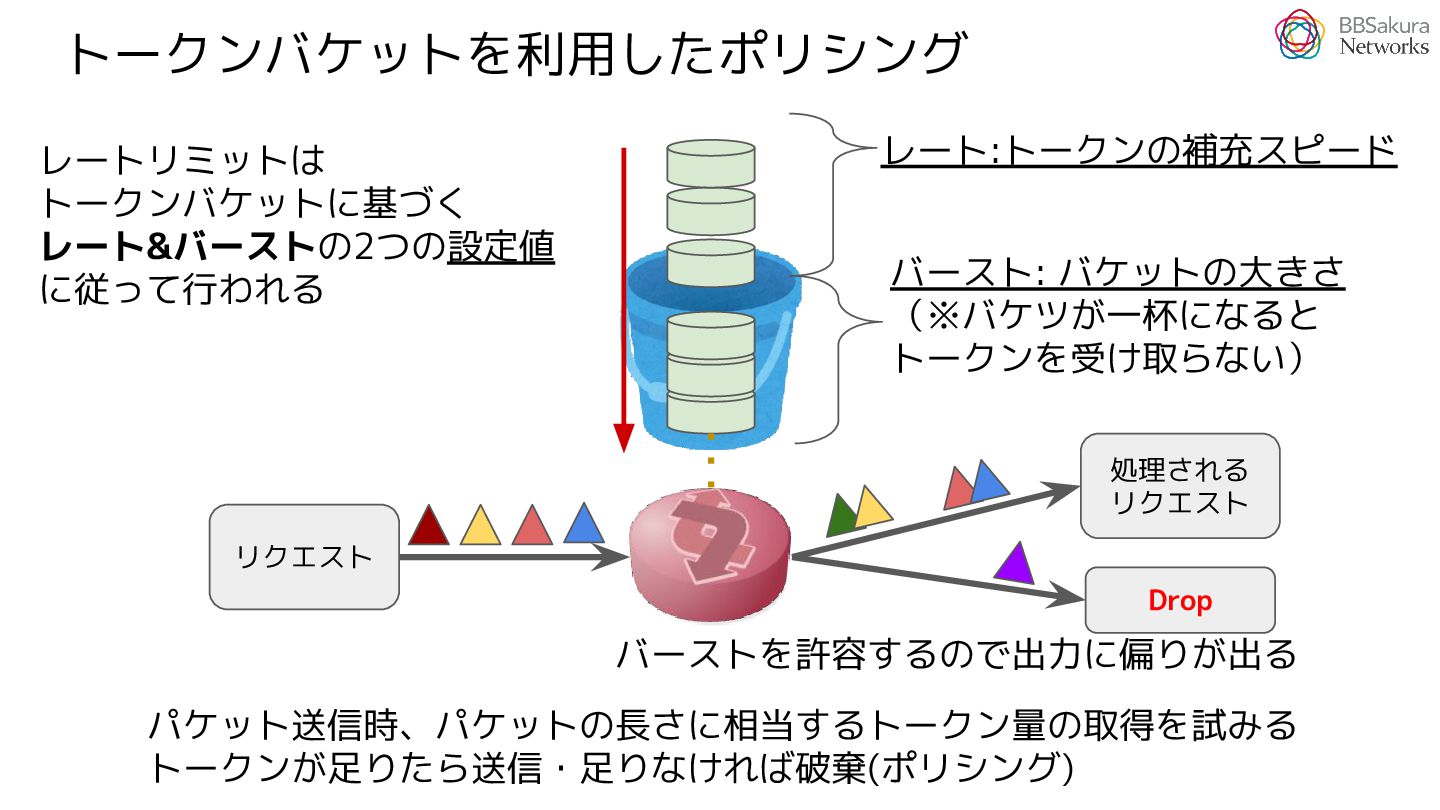{kind=link}
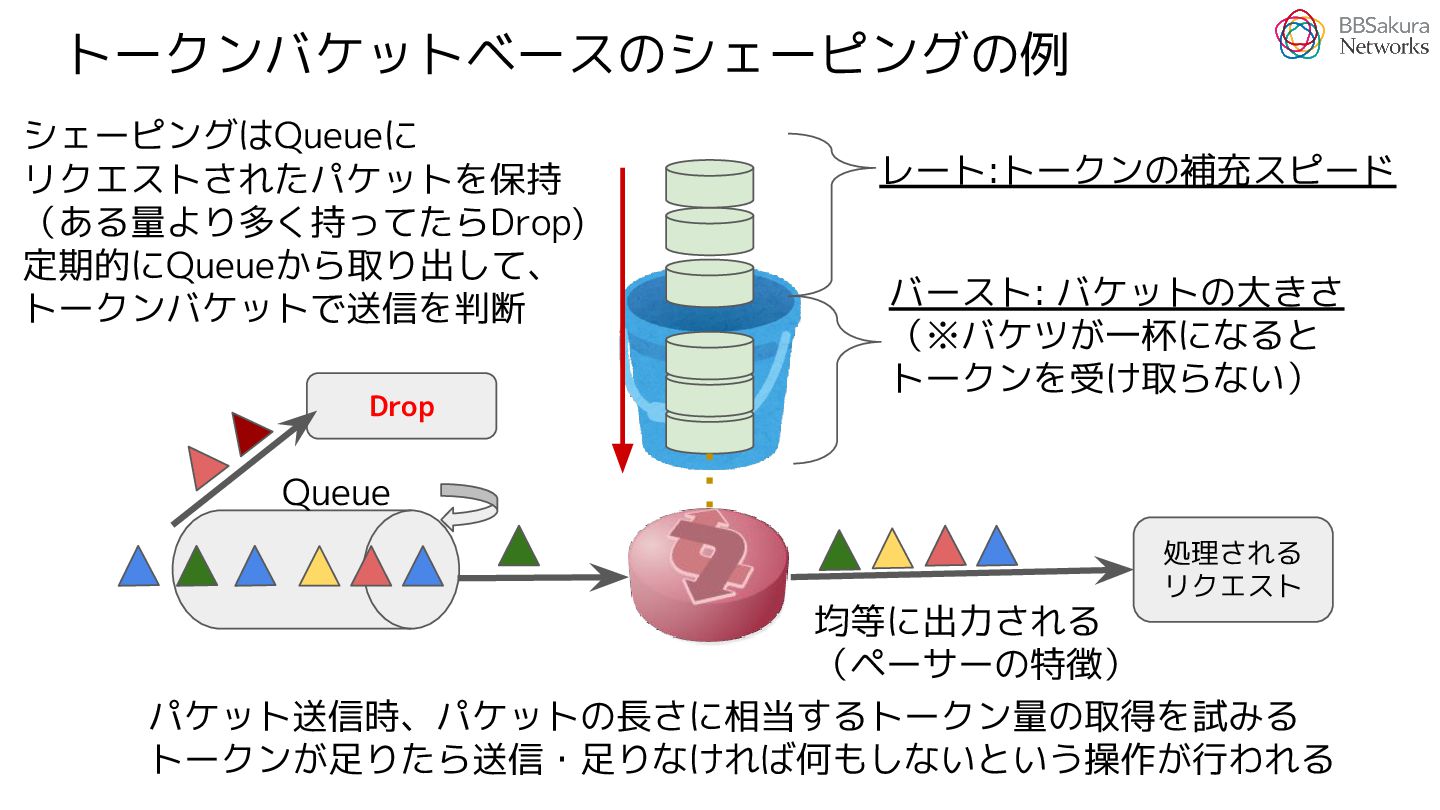{kind=link}
{kind=link}
{kind=link}
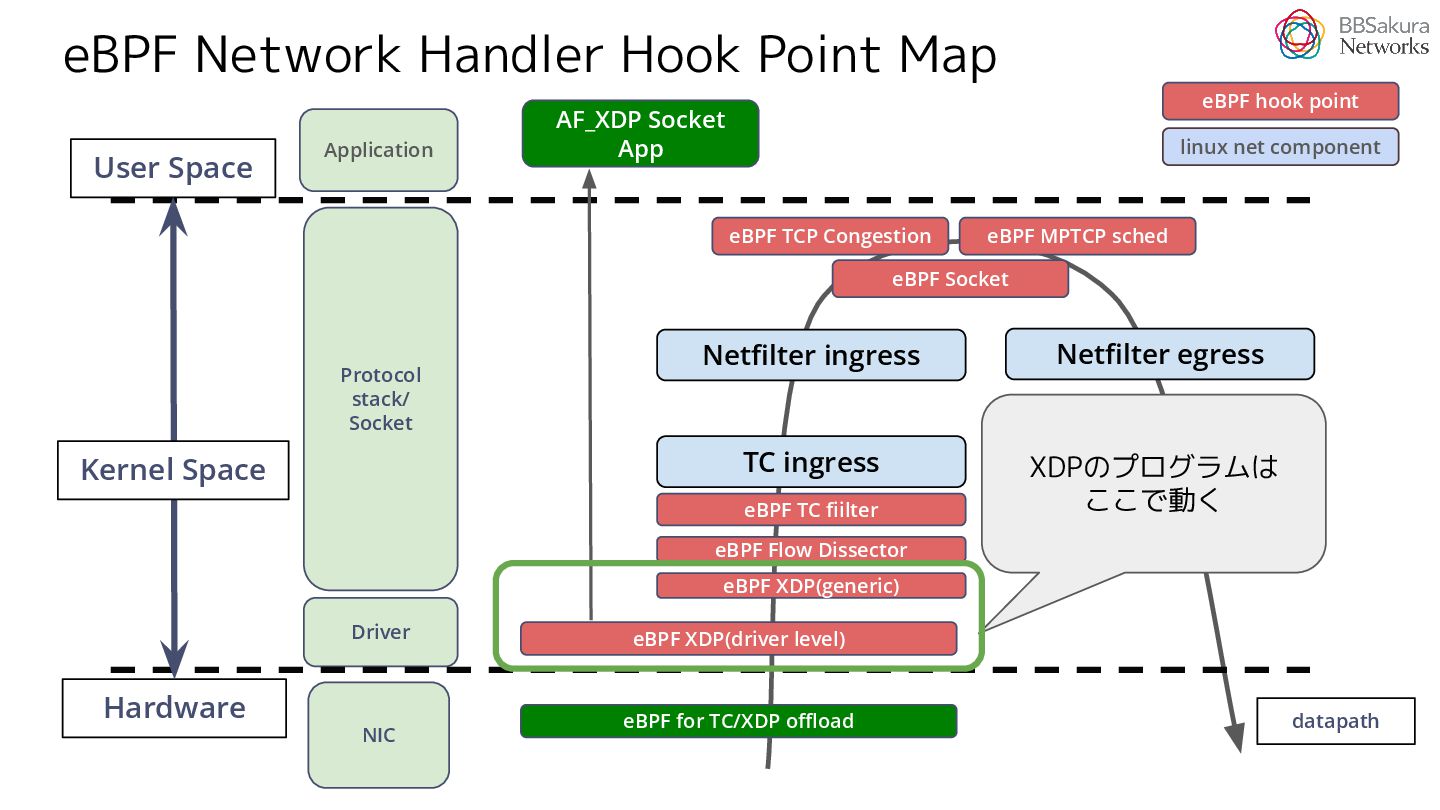{kind=link}
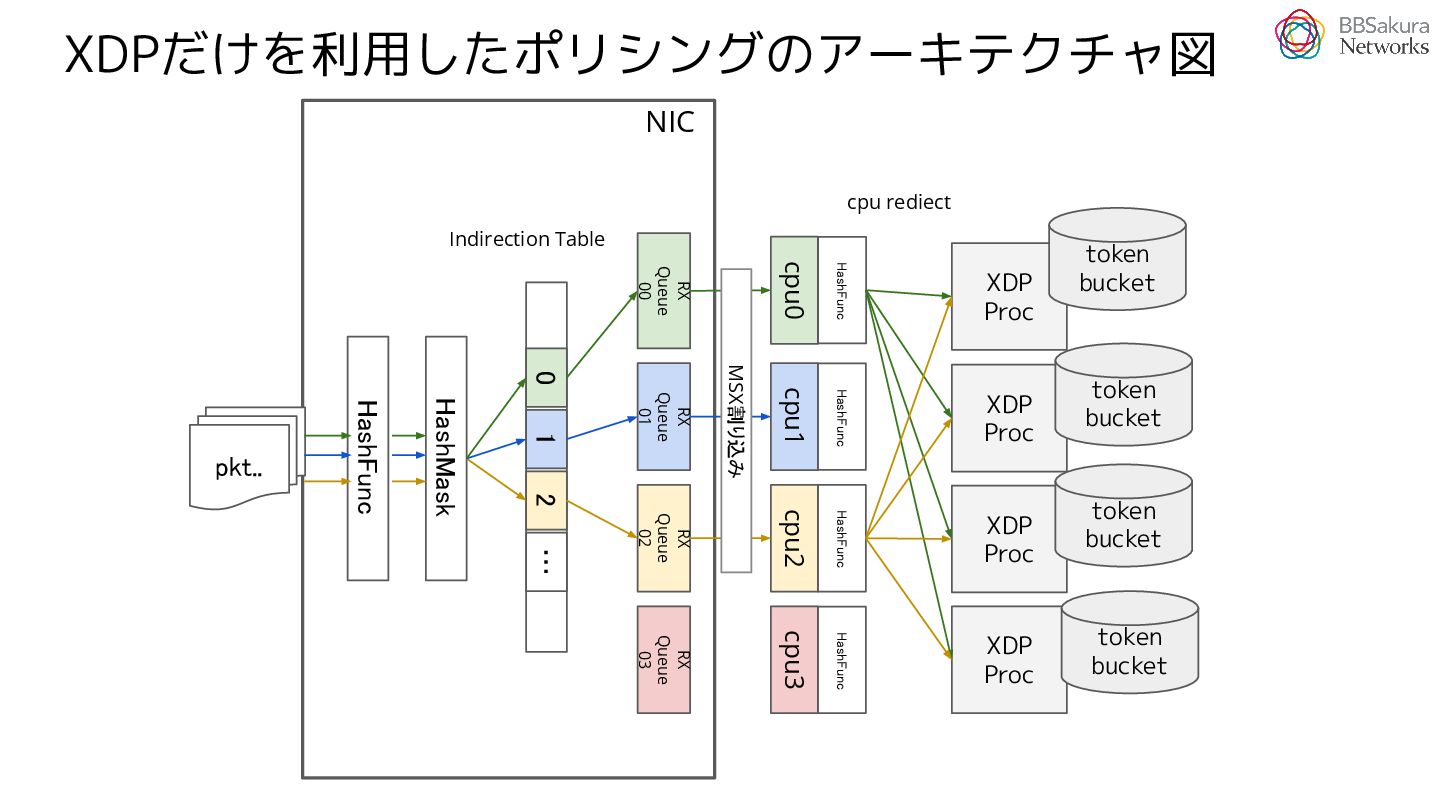{kind=link}
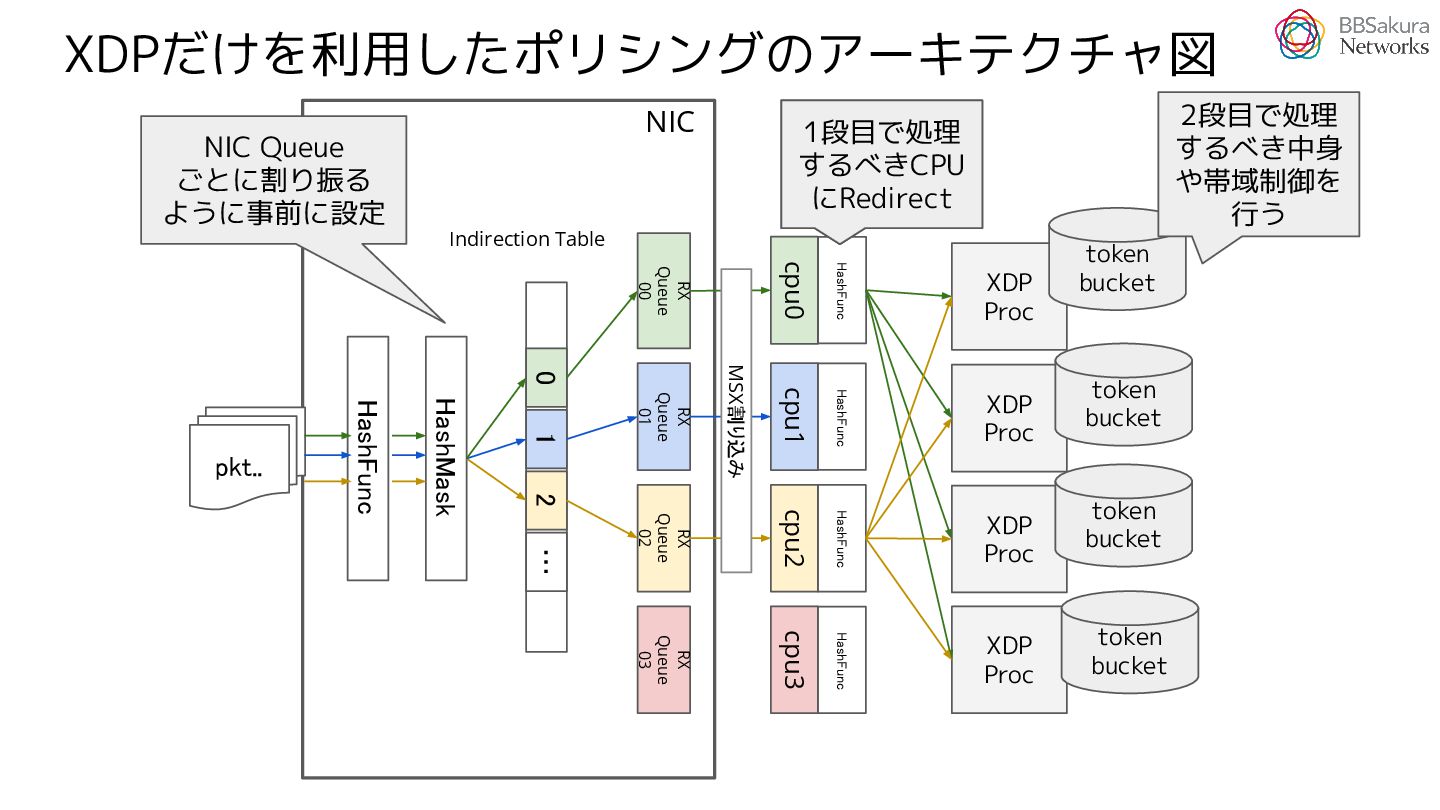{kind=link}
{kind=link}
{kind=link}
{kind=link}
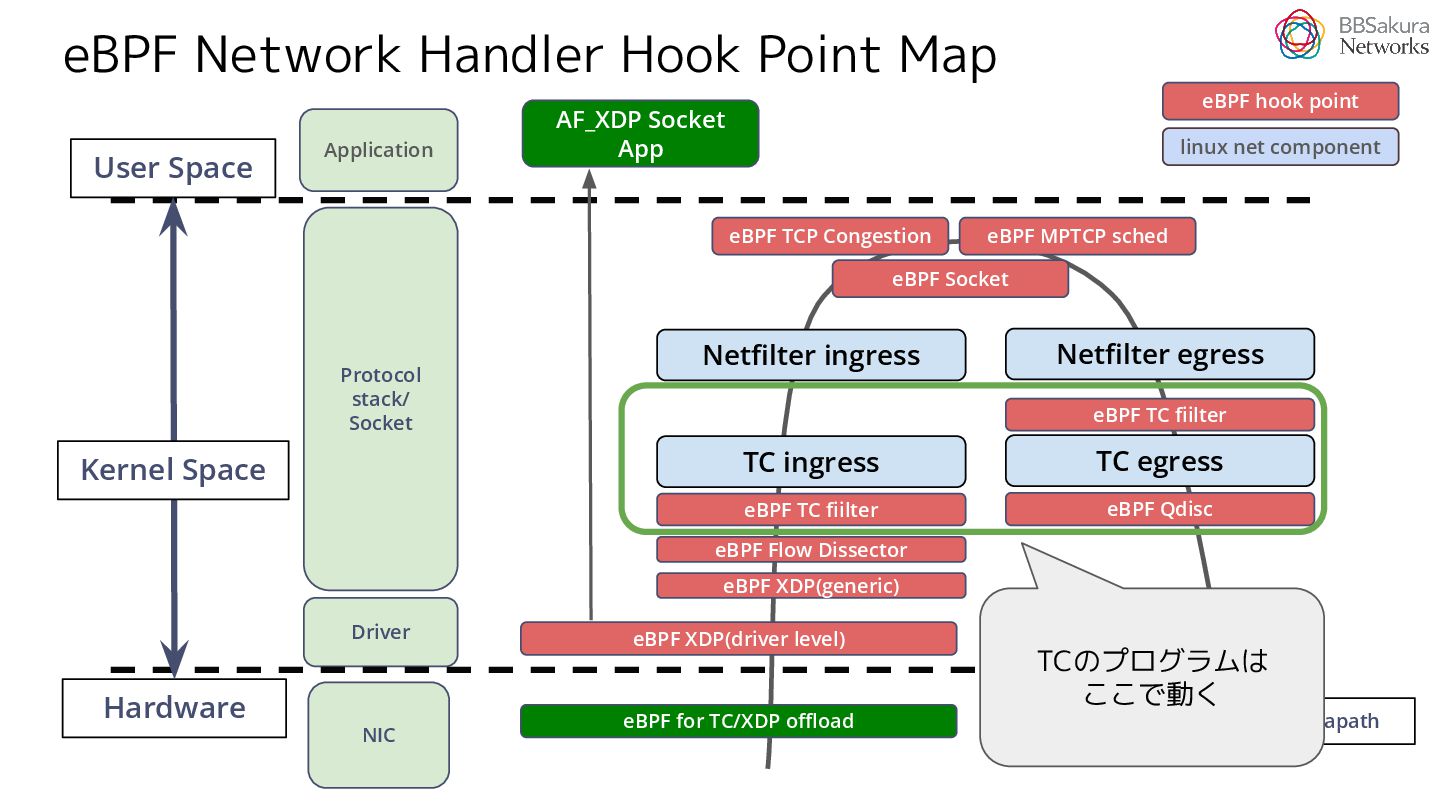{kind=link}
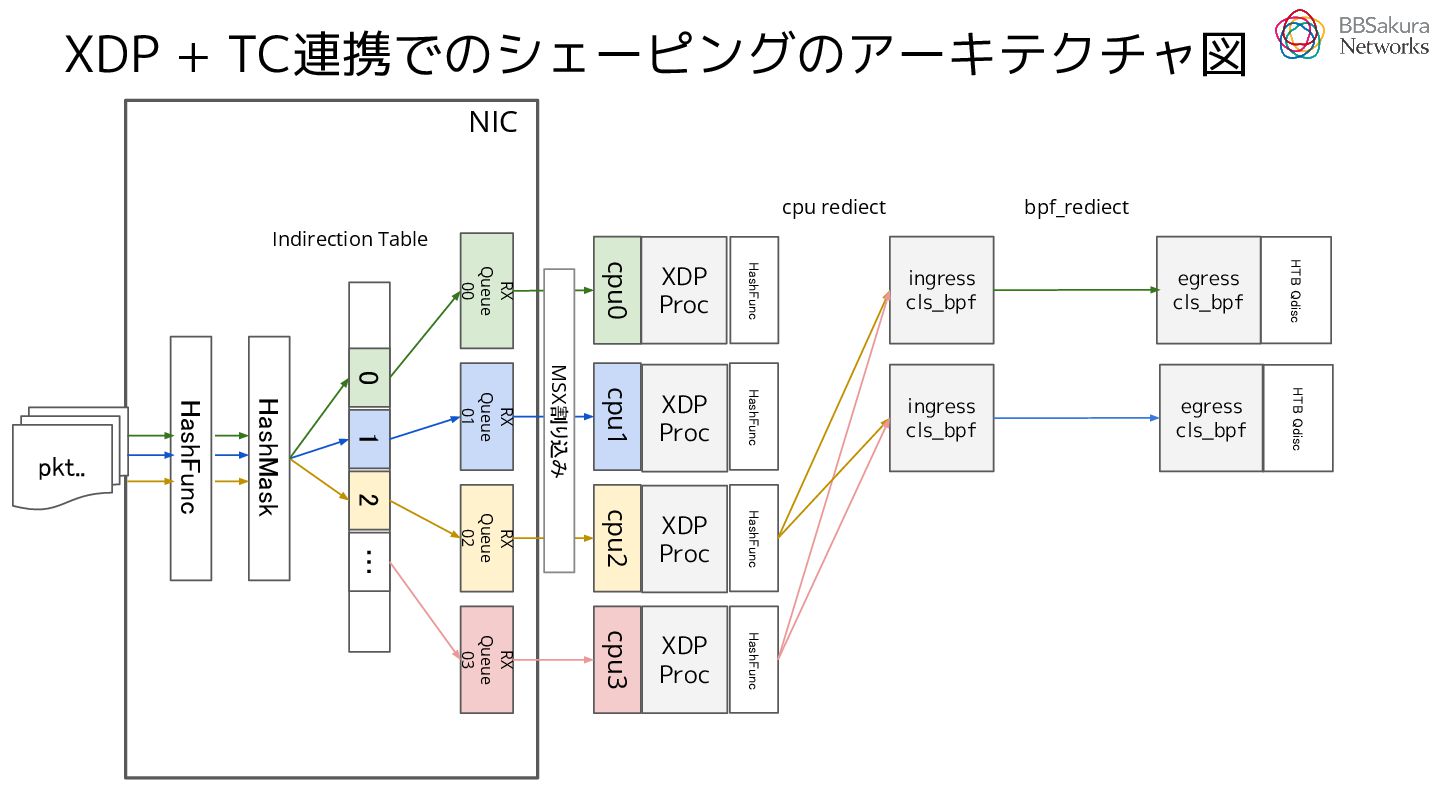{kind=link}
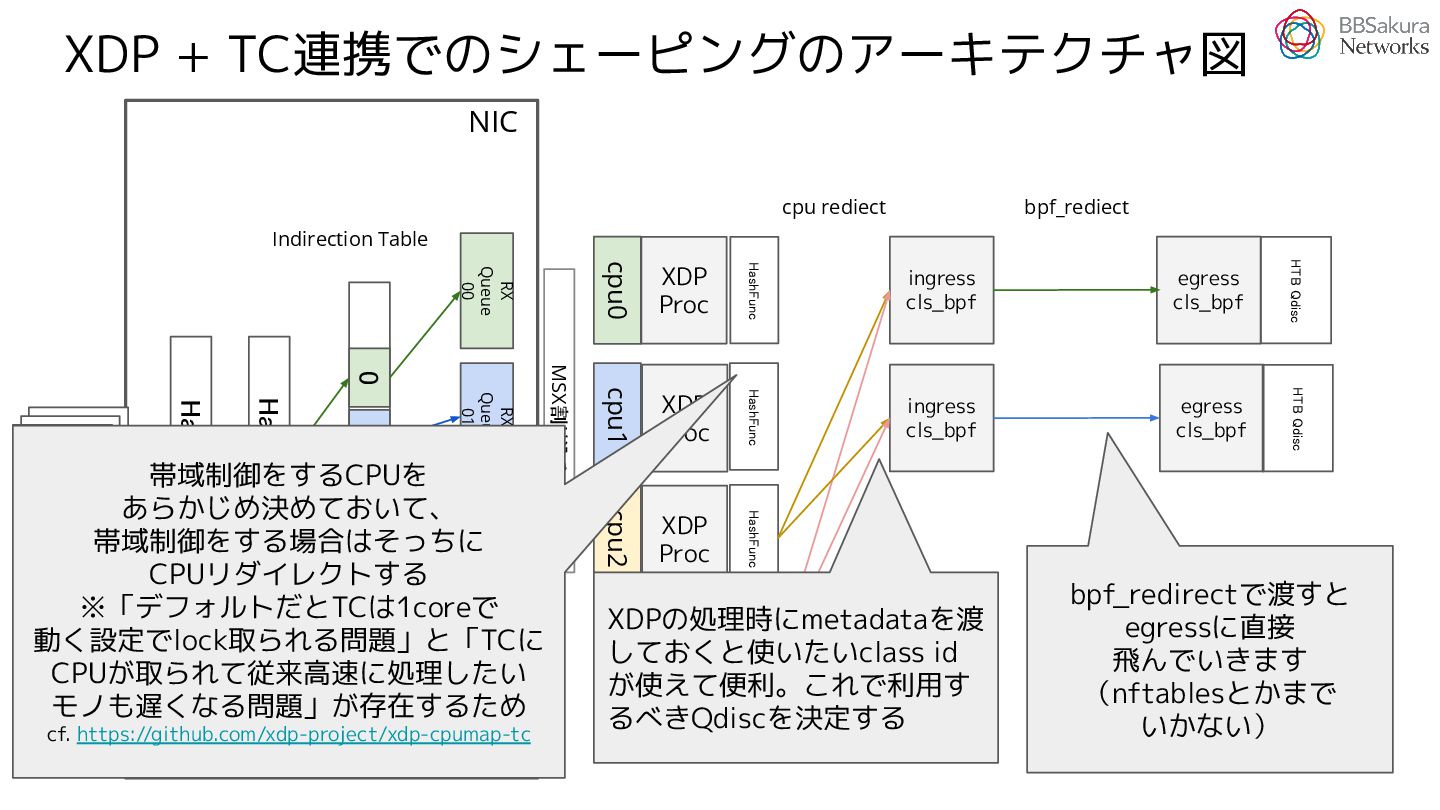{kind=link}
{kind=link}
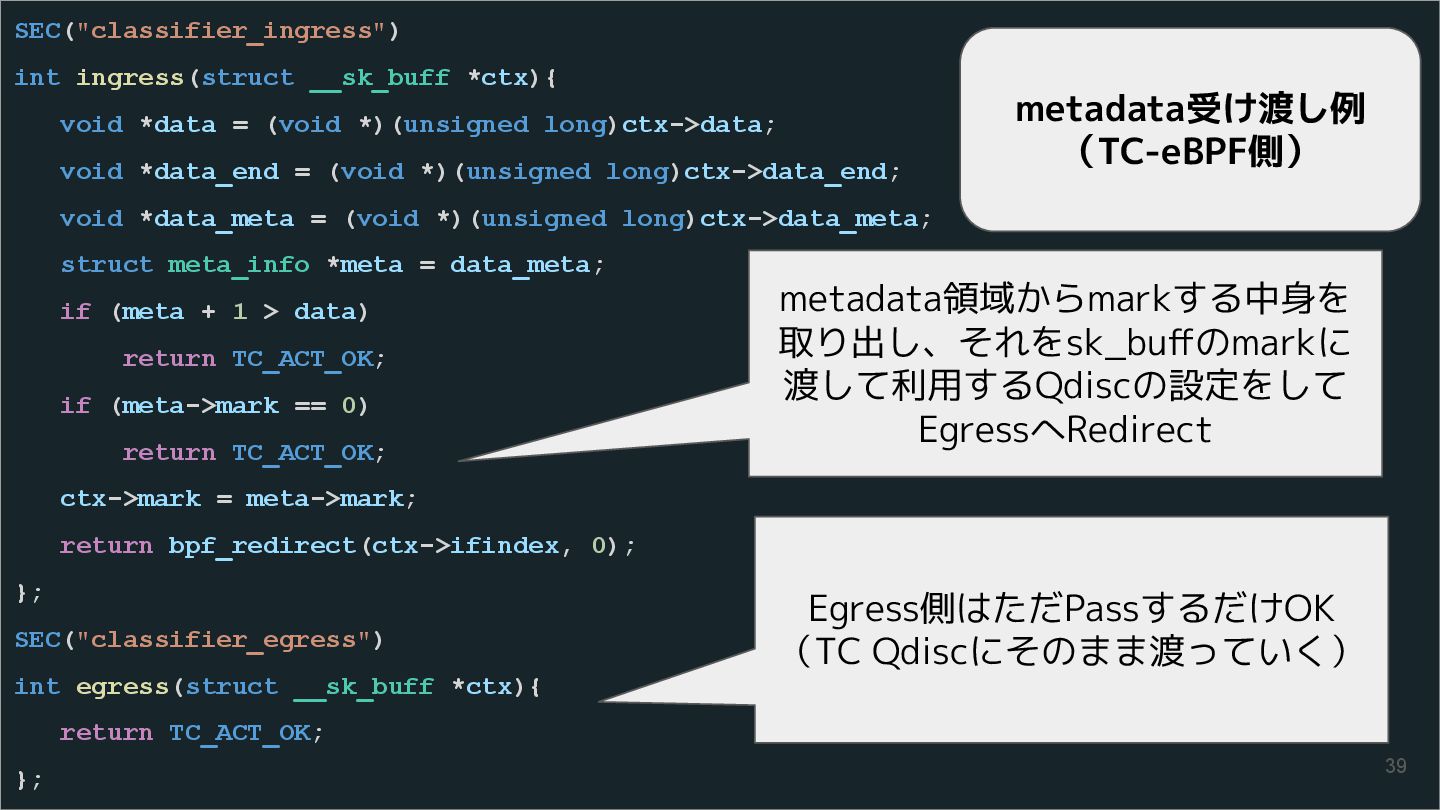{kind=link}
{kind=link}
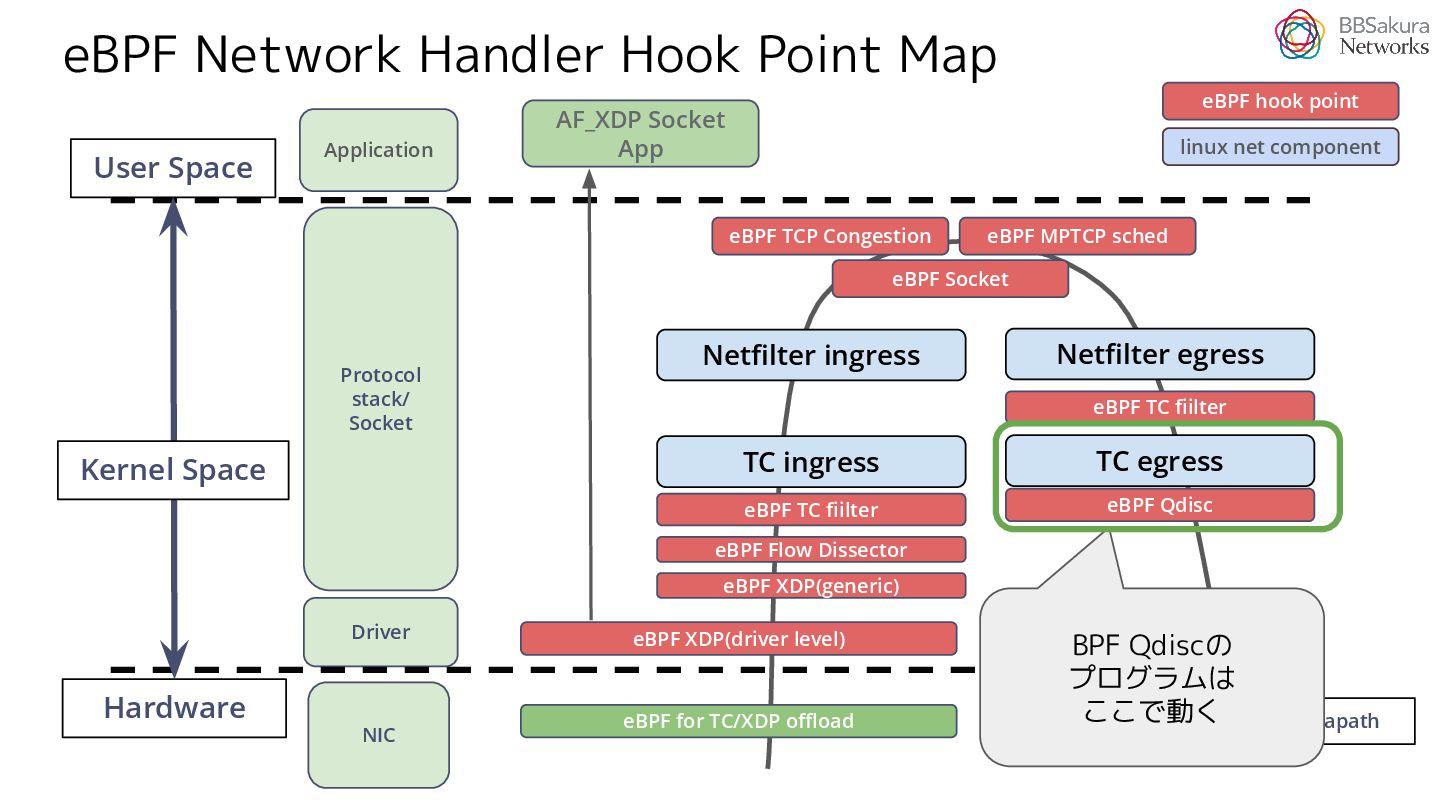{kind=link}
{kind=link}
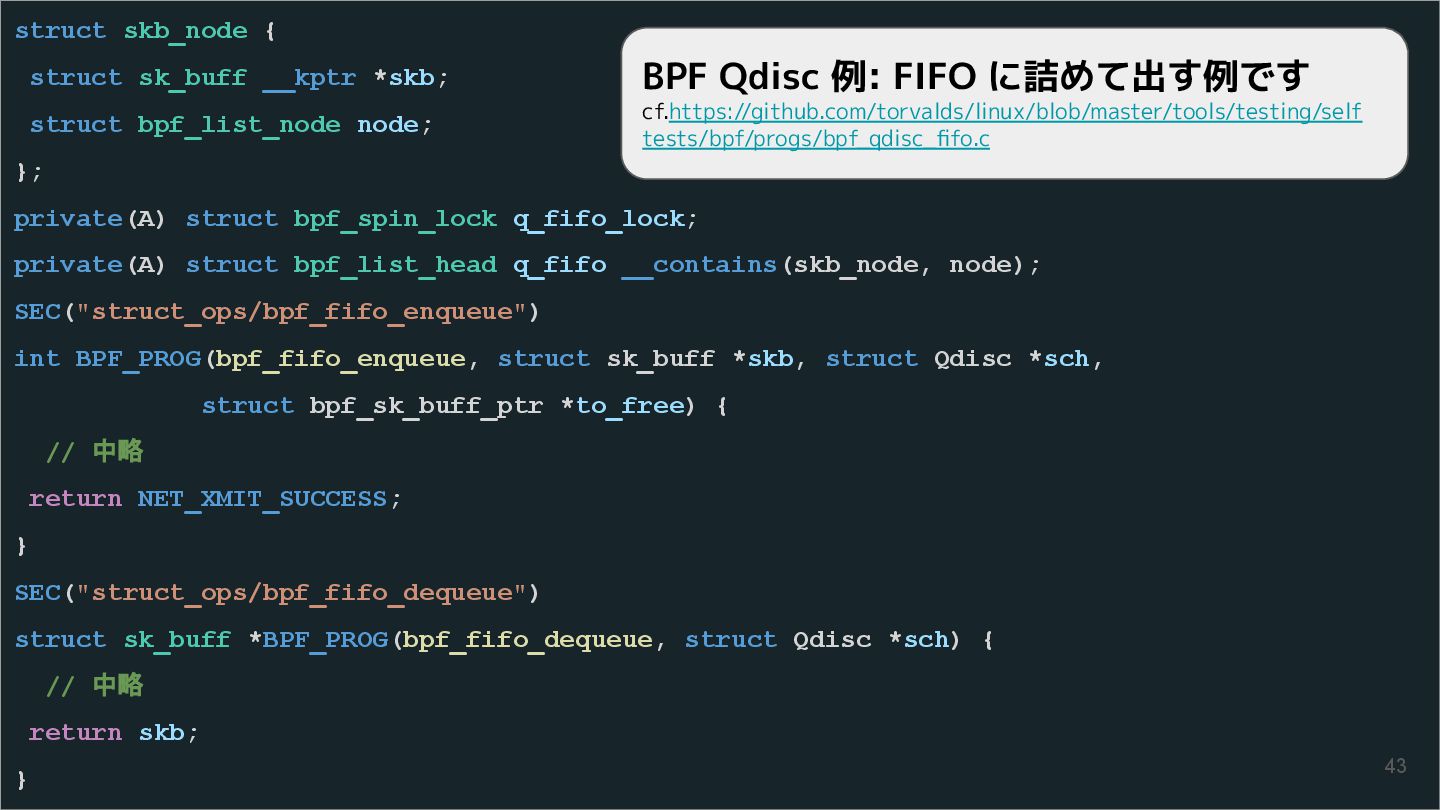{kind=link}
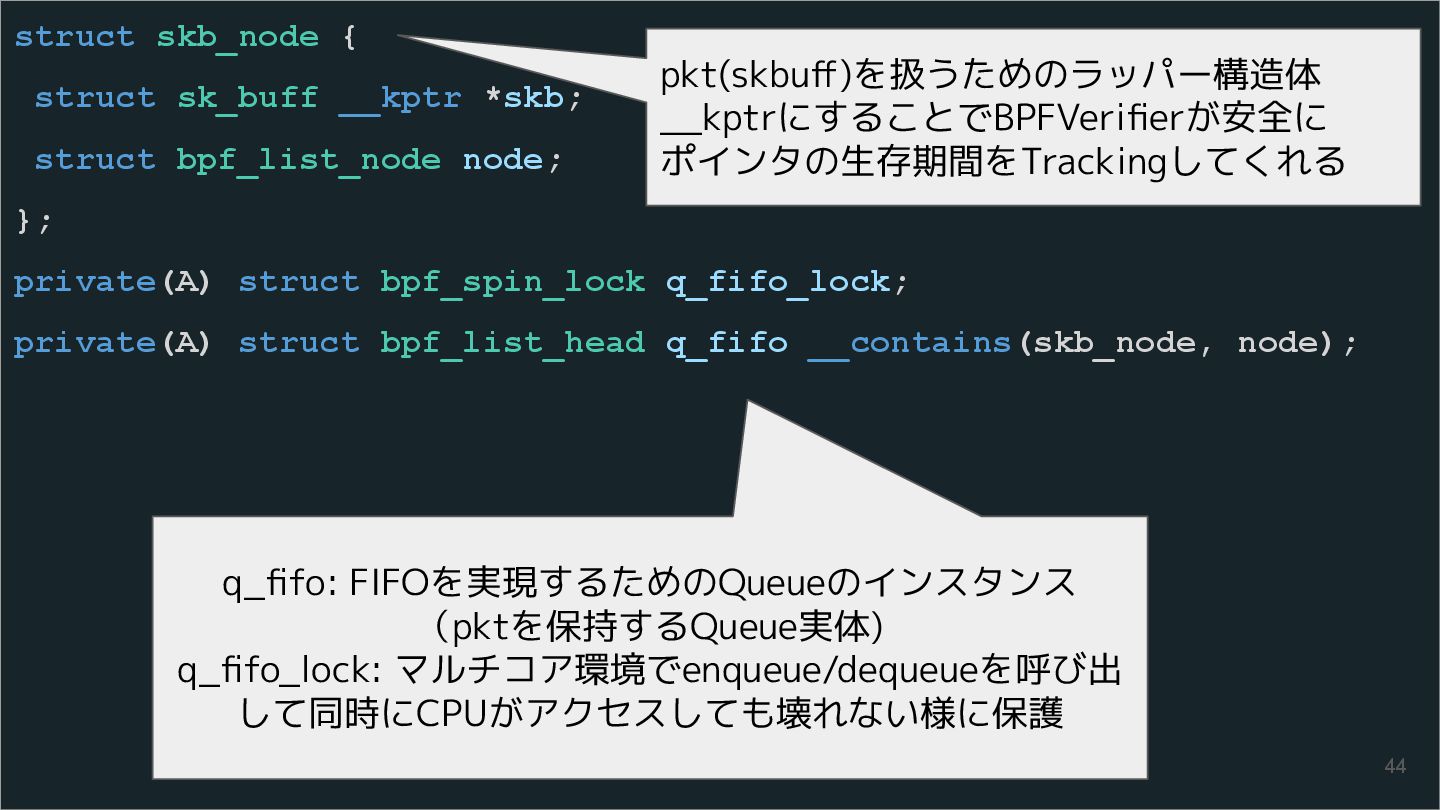{kind=link}
{kind=link}
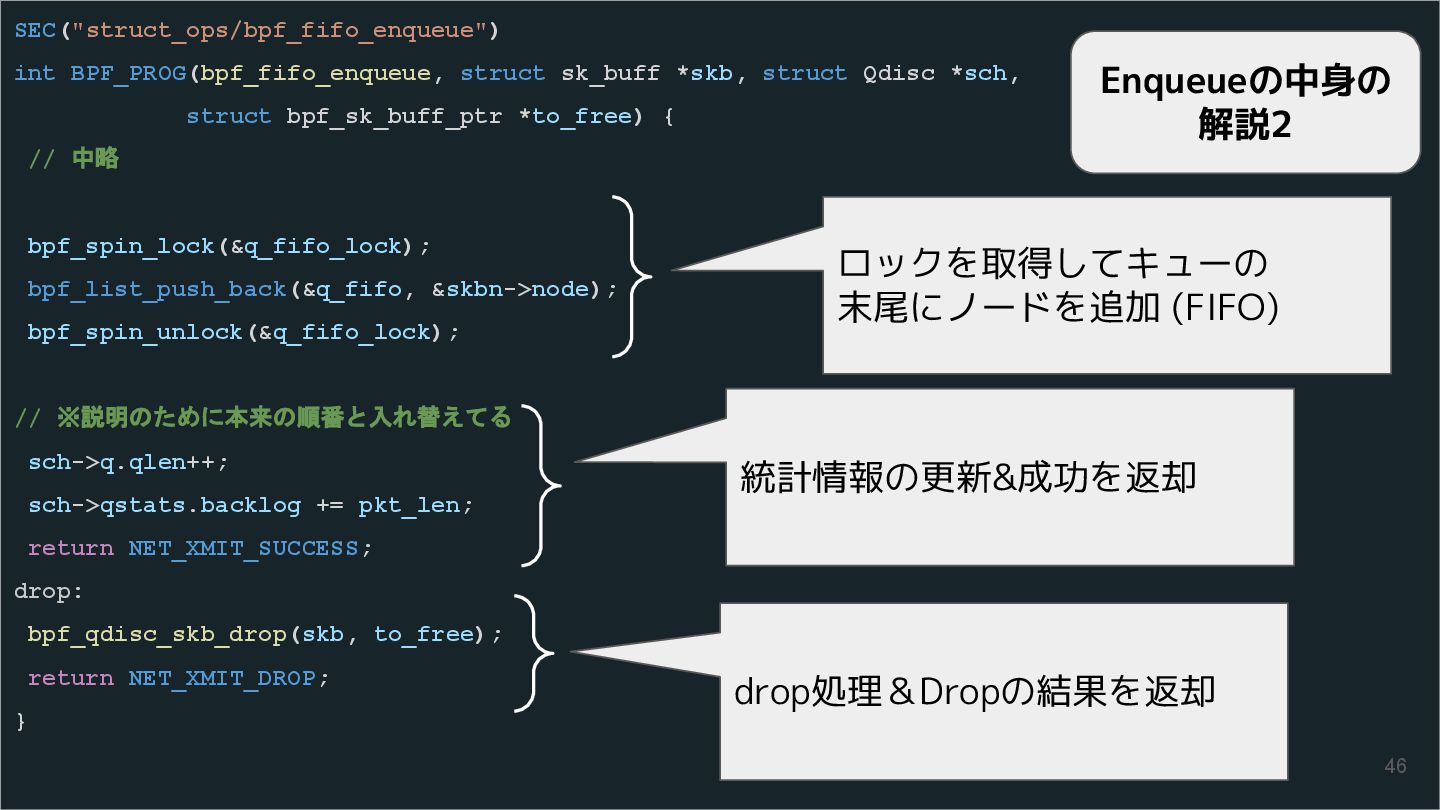{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}