DB that’s frequently read and infrequently written • You want robust search & filtering on your data • You want to leverage the faceting feature • You want an awesome scalable data layer
medical survey data • Say: – About 300 multiple choice questions – Responses can be multi-‐dimensional – 7000+ different answer choices per question – 2000+ respondents per survey – 15+ surveys and growing
Psoriatic Arthritis Other Less than a year ago þ ☐ ☐ ☐ ☐ More than a year ago ☐ ☐ þ ☐ ☐ When were you diagnosed with the following types of Arthri5s? What a survey question looks like
Arthri5s? Osteoarthritis Rheumatoid Arthritis Traumatic Arthritis Psoriatic Arthritis Other Less than a year ago 1 0 0 0 0 More than a year ago 0 0 1 0 0 Storing a single response
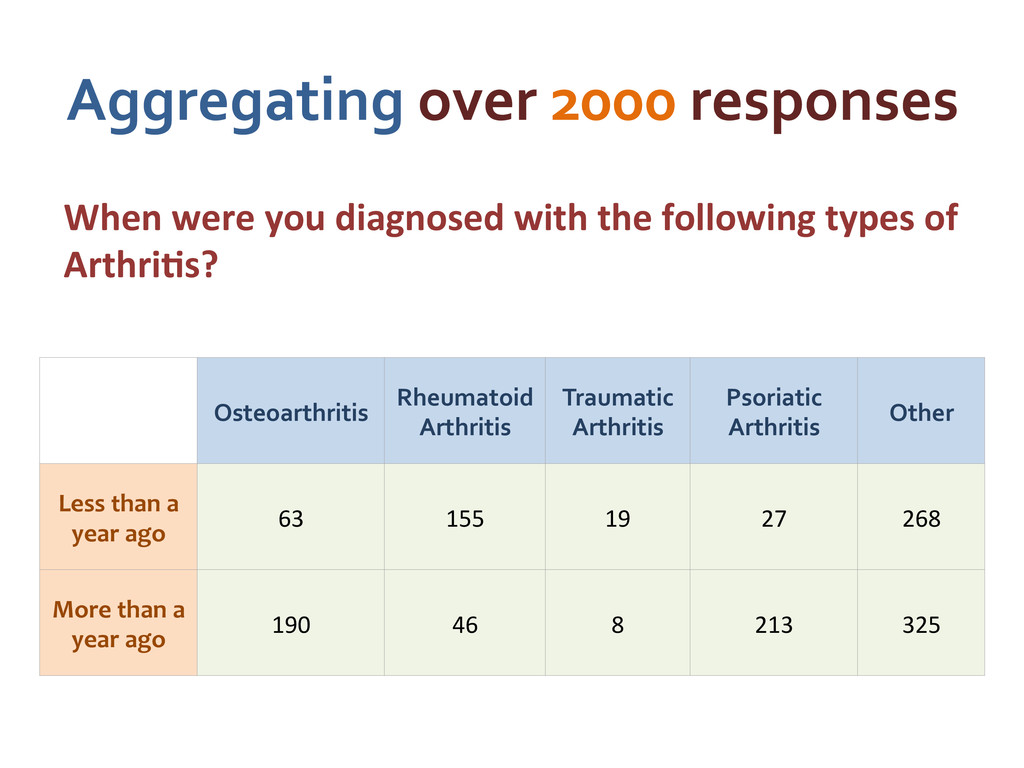
Arthri5s? Osteoarthritis Rheumatoid Arthritis Traumatic Arthritis Psoriatic Arthritis Other Less than a year ago 63 155 19 27 268 More than a year ago 190 46 8 213 325 Aggregating over 2000 responses
uses very little memory • Combining 3000 fields for 2000 documents takes 1 ~ 2 ms • Allowed us to reduce API response time from a variable of 2 ~ 15 seconds (sucked!) to an almost constant ~50 ms
github.com/tow/sunburnt • Programmatic querying as well as raw queries • Supports most advanced solr options • If you only required facets, specify rows=0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}