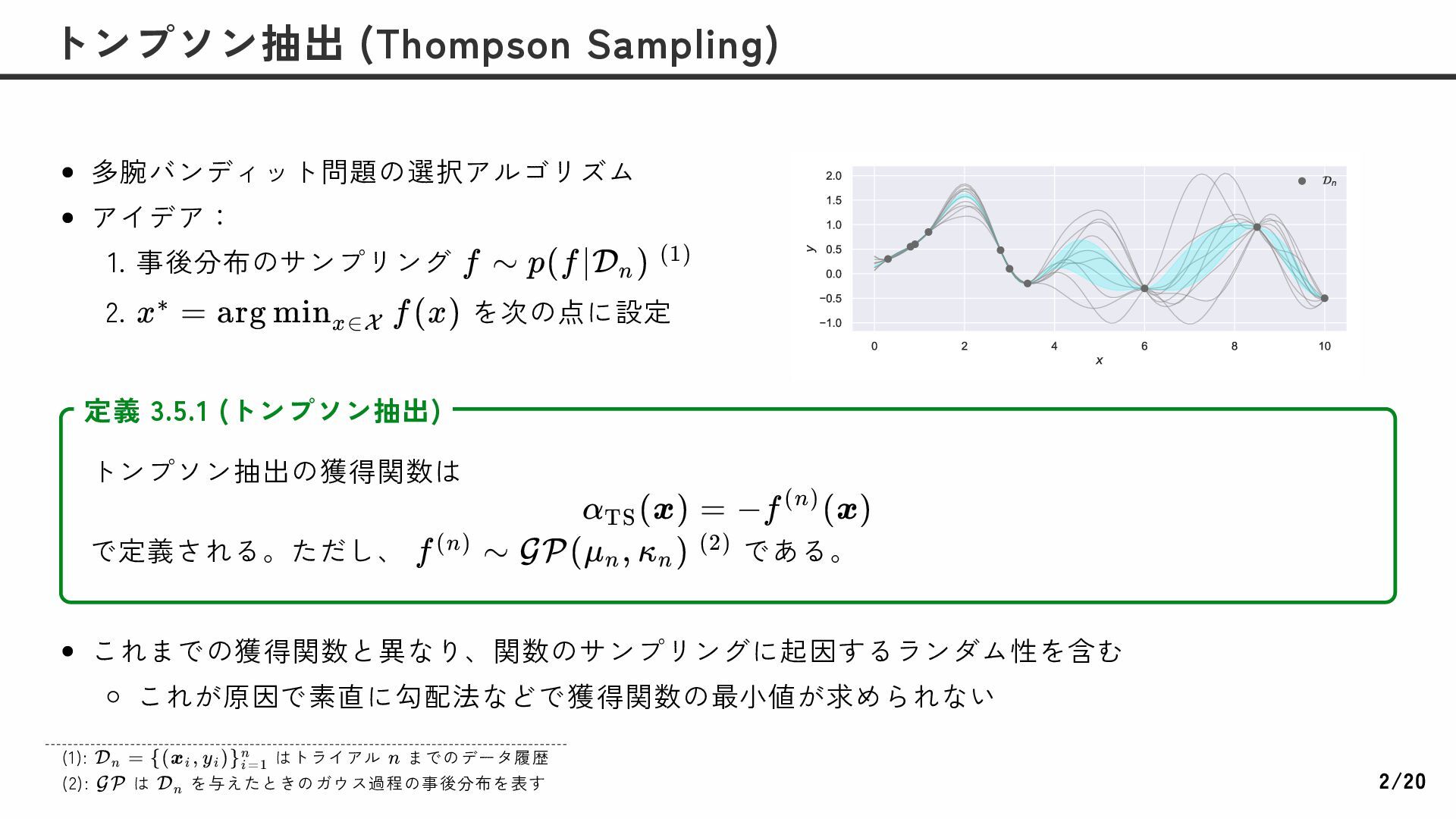
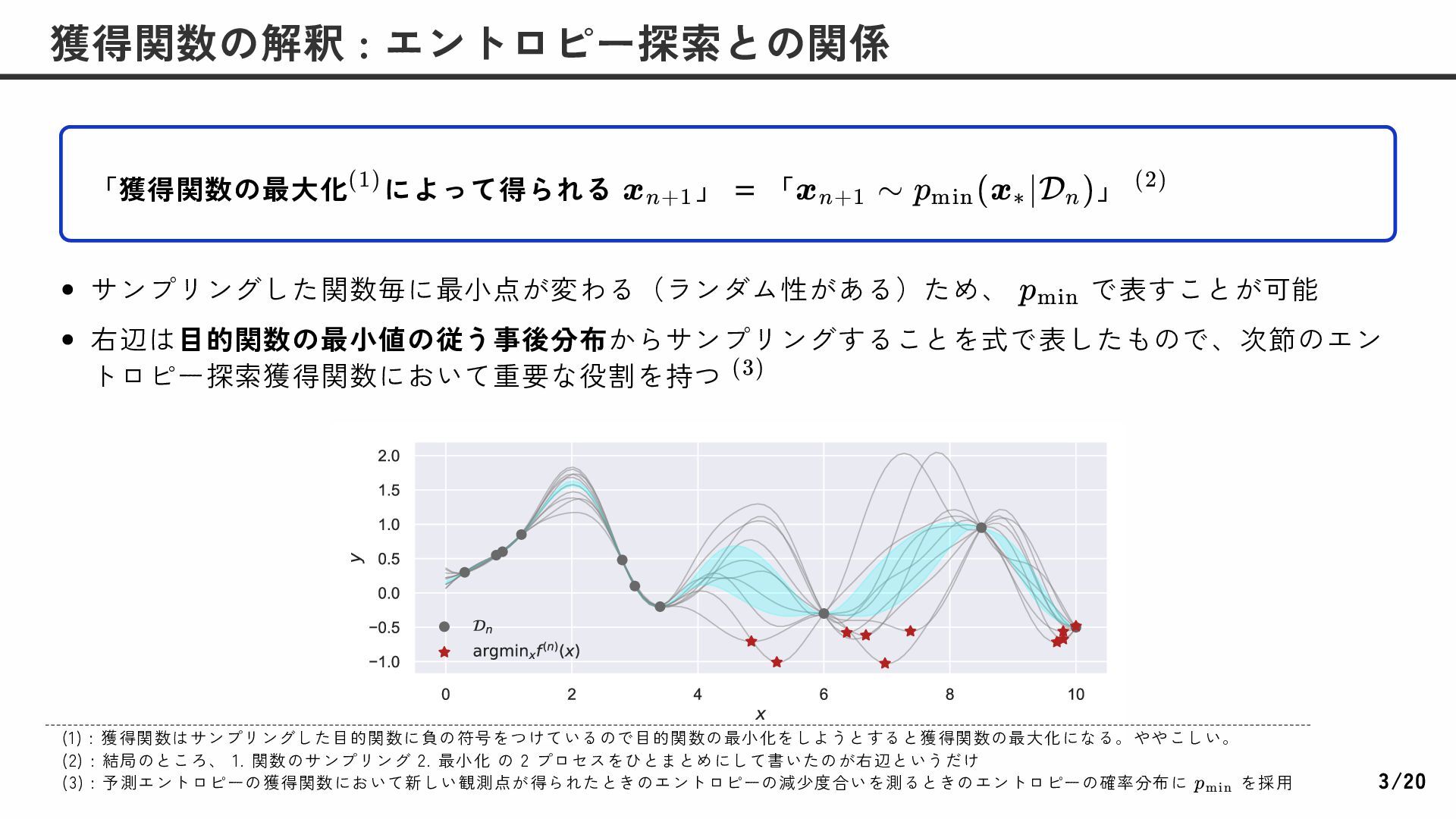
Sampling) f ∼ p(f ∣D ) n (1) x = ∗ arg min f (x) x∈X トンプソン抽出の獲得関数は α (x) = TS −f (x) (n) で定義される。ただし、 である。 定義 3.5.1 (トンプソン抽出) f ∼ (n) GP(μ , κ ) n n (2) (1): はトライアル までのデータ履歴 (2): は を与えたときのガウス過程の事後分布を表す D = n {(x , y )} i i i=1 n n GP D n 2/20
, … , y ) 1 L ≃ {x } i i=1 L ≃ : x ↦ y f ~(n) i i ∼ N (μ , κ + σ I) n n 2 獲得関数も と近似する 獲得関数の実装方法: 1. 素朴な方法 X L Δ α (x) ≃ TS − (x ) f ~(n) i α (x) x∈X arg max TS ≃ − (x ) x ∈{x ,…,x } i 1 L arg max ( f ~(n) i ) = (x ) x ∈{x ,…,x } i 1 L arg min f ~(n) i 計算量は ( 共分散行列の逆行列でのコレスキー分解) トンプソン抽出の素朴な実装方法 O(L ) 3 ∵ 5/20
(x, x ) n ′ = k (x) (K + σ I ) y n ⊤ n 2 n −1 n ≃ ϕ(x) Φ (Φ Φ + σ I ) y ⊤ n ⊤ n n ⊤ 2 n −1 n = k(x, x ) − k (x) (K + σ I ) Φ ϕ(x ) ′ n ⊤ n 2 n −1 n ′ ≃ ϕ(x) ϕ(x ) − ϕ(x) Φ (Φ Φ + σ I ) Φ ϕ(x ) ⊤ ′ ⊤ n ⊤ n n ⊤ 2 n −1 n ′ = ϕ(x) {I − Φ (Φ Φ + σ I ) Φ }ϕ(x ) ⊤ m n ⊤ n n ⊤ 2 n −1 n ′ 目的関数の事後分布 k(x, y) ϕ(x) = ϕ(x) ϕ(y) ⊤ = [ cos {(2πx ω ) + b }] ∈ R , Φ = [ϕ(x )] ∈ R m 2σ 0 2 ⊤ j j j m n i i n×m 疎スペクトル近似 μ n κ n 10/20
) = −1 I − m I Φ (σ I + m n ⊤ 2 n Φ Φ )Φ = n n ⊤ n Ψ n −1 と書けるので、 . を使って平均関数をもう少し整理することが可能 Ψ Φ n −1 n ⊤ μ (x) n = ⋯ = σ Φ (Φ Φ + σ I ) 2 n n n ⊤ 2 n −1 ≃ ϕ(x) Φ (Φ Φ + σ I ) y = ϕ(x) Ψ Φ y ⊤ n ⊤ n n ⊤ 2 n −1 n ⊤ n −1 n ⊤ n 目的関数の事後分布 に対し以下が成立 (A + U CV ) = −1 A − −1 A U (C + −1 −1 V A U ) V A −1 −1 −1 定理 3.5.2 (Woodbury の恒等式) A ∈ R , C ∈ m×m R , U ∈ n×n R , V ∈ m×n Rn×m κ (x, x ) = n ′ ϕ(x) { }ϕ(x ) ⊤ Ψ と定義しておく n −1 I − Φ (Φ Φ + σ I ) Φ m n ⊤ n n ⊤ 2 n −1 n ′ Ψ n −1 A = I , U = m Φ , C = n ⊤ σ I , V = −2 n Φ n Ψ = n A + U CV = I + m σ Φ Φ −2 n ⊤ n Ψ 11/20
(x) n κ (x, x ) n ′ Ψ n Φ n ϕ(x) ≃ σ ϕ(x) Ψ Φ y −2 ⊤ n −1 n ⊤ n ≃ ϕ(x) Ψ ϕ(x ) ⊤ n −1 ′ = I + σ Φ Φ ∈ R m −2 n ⊤ n m×m = [ϕ(x )] ∈ R i i n×m = [ cos (2πx ω ) + b ] ∈ R m 2σ 0 2 ⊤ j j j m 疎スペクトル近似による GP の事後確率 ∵ m < n Φ Φ n ⊤ n O(nm ) 2 Ψ−1 O(m ) 3 12/20
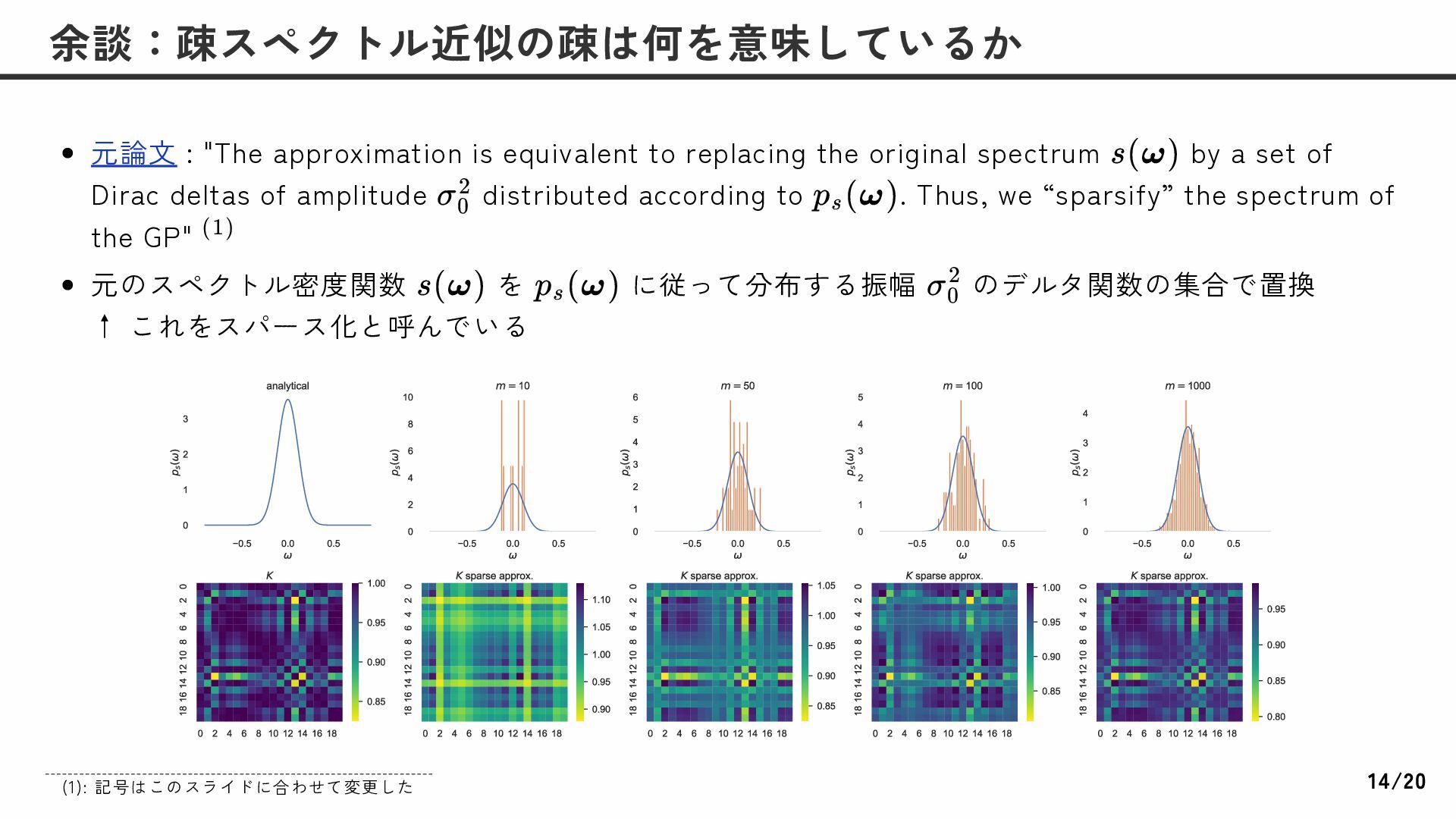
spectrum by a set of Dirac deltas of amplitude distributed according to . Thus, we “sparsify” the spectrum of the GP" 元のスペクトル密度関数 を に従って分布する振幅 のデルタ関数の集合で置換 ↑ これをスパース化と呼んでいる 余談:疎スペクトル近似の疎は何を意味しているか s(ω) σ 0 2 p (ω) s (1) s(ω) p (ω) s σ 0 2 (1): 記号はこのスライドに合わせて変更した 14/20
は疎スペクトル近似した事後分布 に従うはず μ ~ n κ ~ n Φ L = σ ϕ(x )Ψ Φ y = σ Φ Ψ Φ y [ −2 i n −1 n ⊤ n ] i=1 L −2 L n −1 n ⊤ n = [ϕ(x ) Ψ ϕ(x )] j = Φ Ψ Φ i ⊤ n −1 j ij L n −1 L ⊤ = [ϕ(x )] ∈ R i i=1 L L×m 3. で表される が に従うことを利用して をサンプリング とすると、 で .. なので を からサンプリングした後 で OK. 3.5.4 疎スペクトル近似を用いた計算方法 f ∼ (n) GP(μ , κ ) n n X L L x , y i i N ( , ) μ ~ n κ ~ n y = Ax + b, x ∼ N (μ, K) y N (Aμ + b, AKA ) ⊤ y = i f (x ) (n) i A = Φ , b = L 0, μ = σ Ψ Φ y , K = −2 n −1 n ⊤ n Ψ n −1 Aμ + b = σ Φ Ψ Φ y , AKA = −2 L n −1 n ⊤ n ⊤ Φ Ψ Φ L n −1 L ⊤ y = Ax ∼ N ( , ) μ ~ n κ n ~ θ N (μ, K) y = i ϕ(x ) θ, i = i ⊤ 1, … , L 15/20
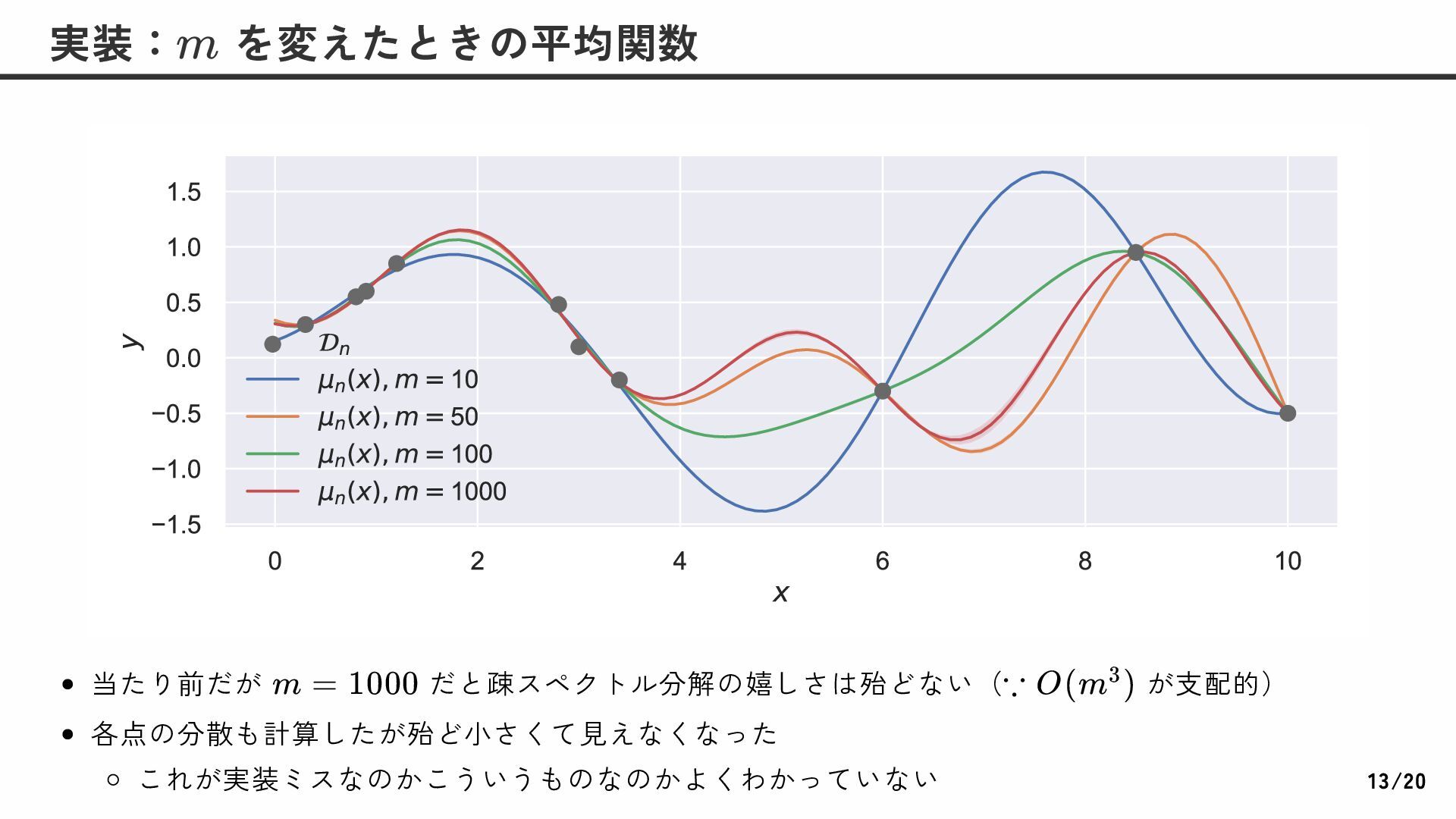
で設定 について線形まで計算量を削減できたが、 が 次元で各次元で 分割することを考えると となるため、 が大きい場合(e.g. )ではまだ不十分 を有限個の点集合で近似せずに求めたい 3.5.4 疎スペクトル近似を用いた計算方法 トンプソン抽出: を計算してその最小値を求めることが目的 X θ ∈ Rm y Φ L ≃ {x } i i=1 L ∼ N (σ Ψ Φ y , Ψ ) −2 n −1 n ⊤ n n −1 = Φ θ L = [ϕ(x )] ∈ R i i=1 L L×m 疎スペクトル近似でトンプソン抽出 y O(nm + 2 mL) θ O(nm ) 2 m × m m × n y = Φ θ L O(mL) m < n ≪ L L X d n L = nd d d > 10 → X 16/20
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![二乗指数カーネル の は s(ω) = F[k(x)] =](https://files.speakerdeck.com/presentations/dcd7f7c68bb24b4b8c5b3ed45ae0c7b2/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
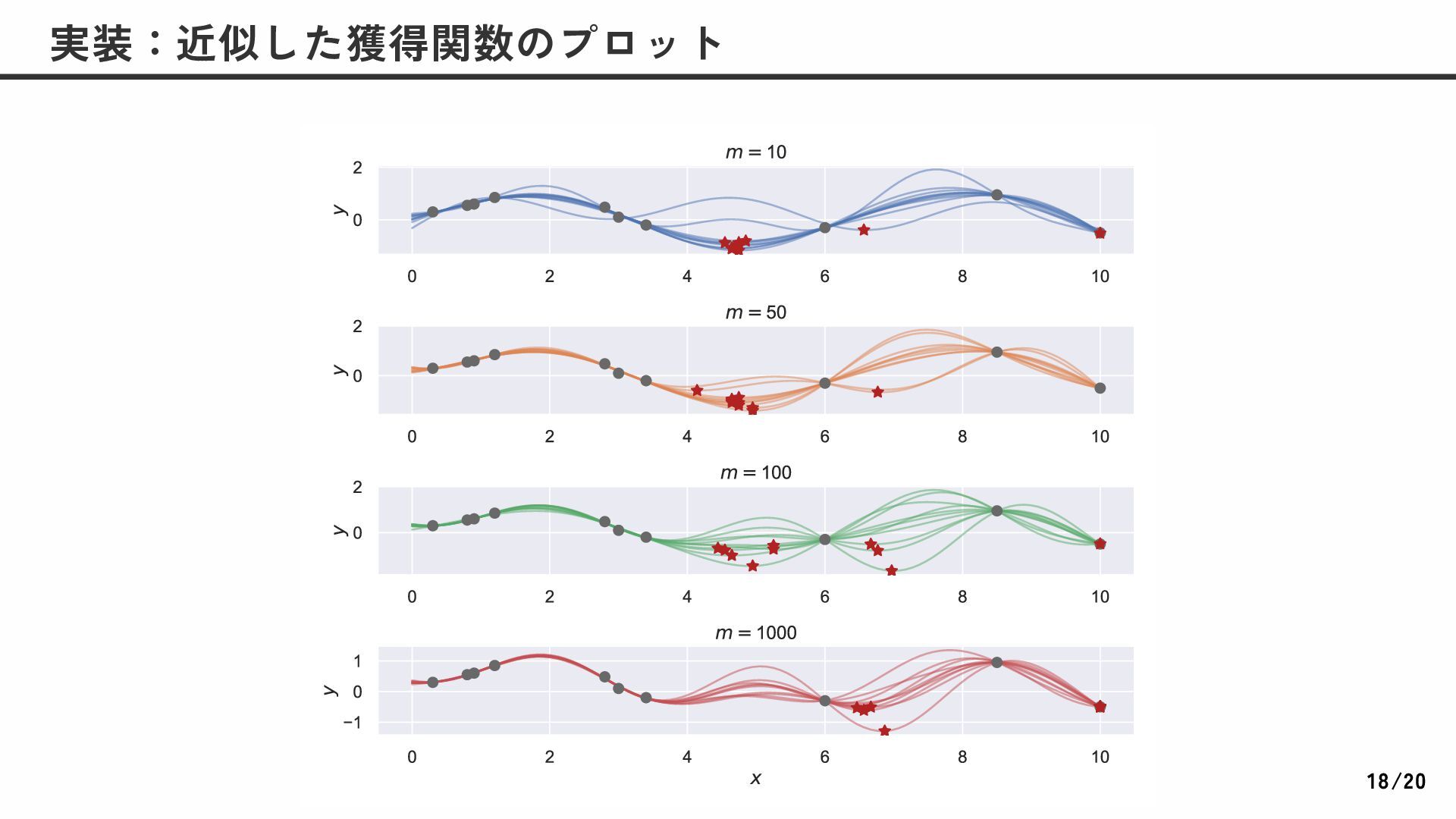
![多腕バンディットだと実用的に高い性能を発揮するアルゴリズムとして知られている ベイズ最適化だとそれほど使われていない 低次元では比較的上手くいく 高次元だと性能が悪化 トンプソン抽出獲得関数が探索と活用の探索に寄りすぎているから、という指摘 [B. Shahriari, et al. (2016)]](https://files.speakerdeck.com/presentations/dcd7f7c68bb24b4b8c5b3ed45ae0c7b2/slide_18.jpg){kind=link}
{kind=link}