Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ゲーム理論の基礎 (非協力ゲーム)
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
AiTachi
August 06, 2022
Science
350
0
Share
ゲーム理論の基礎 (非協力ゲーム)
ゲーム理論の本当に基本的なところを書きました。
自分の研究への応用はいずれ書きたいと思っています。
AiTachi
August 06, 2022
More Decks by AiTachi
See All by AiTachi
Dockerを使っていい感じの環境を作る
tcbnai12
0
240
Other Decks in Science
See All in Science
データベース14: B+木 & ハッシュ索引
trycycle
PRO
0
680
Algorithmic Aspects of Quiver Representations
tasusu
0
250
力学系から見た現代的な機械学習
hanbao
3
4k
コンピュータビジョンによるロボットの視覚と判断:宇宙空間での適応と課題
hf149
1
590
NDCG is NOT All I Need
statditto
2
3k
AIPシンポジウム 2025年度 成果報告会 「因果推論チーム」
sshimizu2006
3
440
Accelerating operator Sinkhorn iteration with overrelaxation
tasusu
0
250
Amusing Abliteration
ianozsvald
0
150
HajimetenoLT vol.17
hashimoto_kei
1
200
白金鉱業Meetup_Vol.20 効果検証ことはじめ / Introduction to Impact Evaluation
brainpadpr
2
1.7k
Bear-safety-running
akirun_run
0
120
AIによる科学の加速: 各領域での革新と共創の未来
masayamoriofficial
0
480
Featured
See All Featured
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
3.8k
Bash Introduction
62gerente
615
210k
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
170
AI: The stuff that nobody shows you
jnunemaker
PRO
4
500
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
300
The Limits of Empathy - UXLibs8
cassininazir
1
280
Skip the Path - Find Your Career Trail
mkilby
1
93
KATA
mclloyd
PRO
35
15k
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
440
CoffeeScript is Beautiful & I Never Want to Write Plain JavaScript Again
sstephenson
162
16k
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
420
Transcript
ゲーム理論の基礎 (非協力ゲーム) AiTachi, GitHub:tcbn-ai, Twitter: @tcbn_ai 1
目次 戦略型ゲーム 戦略型ゲームの定義 最適反応とナッシュ均衡 混合戦略と混合戦略ナッシュ均衡 数値計算 ゲーム理論の基礎 (非協力ゲーム) AiTachi, GitHub:tcbn-ai,
Twitter: @tcbn_ai 2
1. 戦略型ゲーム 1.1. 戦略型ゲームの定義 戦略型ゲーム:複数の意思決定主体間の相互作用を表す数理モデル 意思決定主体は自分自身の行動 (純粋戦略) を選択する 行動に対して利得が与えられている 利得は、自分の行動と他の意思決定主体の行動に依存して決まる
数学的に戦略型ゲームを定義する。 ゲーム理論の基礎 (非協力ゲーム) AiTachi, GitHub:tcbn-ai, Twitter: @tcbn_ai 3
Def (戦略型ゲーム) 戦略型ゲーム は、タプル として定義される。 ただし、 : プレイヤーの集合 (有限集合) :
純粋戦略空間 : プレイヤー の純粋戦略集合 : 利得関数、 : プレイヤー の利得関数 ゲーム理論の基礎 (非協力ゲーム) AiTachi, GitHub:tcbn-ai, Twitter: @tcbn_ai 4
例:囚人のジレンマ , , は以下の表のように定義。 \ プレイヤー が戦略 、プレイヤー が戦略 をとったとき
プレイヤー の利得: プレイヤー の利得: ゲーム理論の基礎 (非協力ゲーム) AiTachi, GitHub:tcbn-ai, Twitter: @tcbn_ai 5
補足 :第 要素のみが であるような 次元単位ベクトル とする。 人ゲームの利得は行列 (利得行列) として表現される。 に対して、
, , ゲーム理論の基礎 (非協力ゲーム) AiTachi, GitHub:tcbn-ai, Twitter: @tcbn_ai 6
プレイヤー 、プレイヤー の利得行列 は以下のようになる。 囚人のジレンマの例では、 となる。 ゲーム理論の基礎 (非協力ゲーム) AiTachi, GitHub:tcbn-ai,
Twitter: @tcbn_ai 7
1.2 最適反応とナッシュ均衡 とする。 Def (最適反応) が に対する純粋最適反応 他のプレイヤーの行動を固定したときの最適な行動 等価な条件は、 1つとは限らないが、必ず存在する
ゲーム理論の基礎 (非協力ゲーム) AiTachi, GitHub:tcbn-ai, Twitter: @tcbn_ai 8
Def (ナッシュ均衡) が (純粋戦略) ナッシュ均衡 自分だけが行動を変更しても得をしない 等価な条件は、 1つとは限らず、存在しない場合もある すべてのプレイヤーにとって合理的 実現すればそこから動かない。どのように実現するかは考えな
い。 ゲーム理論の基礎 (非協力ゲーム) AiTachi, GitHub:tcbn-ai, Twitter: @tcbn_ai 9
例:囚人のジレンマ \ プレイヤー の戦略を に固定したときのプレイヤー の利得 プレイヤー が をとる: 、プレイヤー
が をとる: プレイヤー の戦略を に固定したときのプレイヤー の利得 プレイヤー が をとる: 、プレイヤー が をとる: ゲーム理論の基礎 (非協力ゲーム) AiTachi, GitHub:tcbn-ai, Twitter: @tcbn_ai 10
プレイヤー の戦略を固定したときも同様。 最適反応 に対して に対して ナッシュ均衡: 囚人のジレンマでは、ナッシュ均衡はパレート最適ではない。 パレート最適:自分の利得を上げるには他のプレイヤーの利得 を悪化させる状態 双方のプレイヤーにとって利得が一番良いのは
となるこ と。 ゲーム理論の基礎 (非協力ゲーム) AiTachi, GitHub:tcbn-ai, Twitter: @tcbn_ai 11
1.3 混合戦略と混合戦略ナッシュ均衡 ゲーム を考える。 上の確率分布 をプレイヤー の混合戦略と呼ぶ。 は以下のように表される。 また、純粋戦略空間 に対応する混合戦略空間
は、 ゲーム理論の基礎 (非協力ゲーム) AiTachi, GitHub:tcbn-ai, Twitter: @tcbn_ai 12
補足 は単位ベクトル を頂点とする 次元単位単 体となる。 のとき、混合戦略 は、線分 , 上の点である。 ゲーム理論の基礎
(非協力ゲーム) AiTachi, GitHub:tcbn-ai, Twitter: @tcbn_ai 13
以下の記号を定義する。 : で が実際に起こる確率 利得関数の混合戦略への拡張 (期待利得関数) は、以下で定義される。 , ゲーム理論の基礎 (非協力ゲーム)
AiTachi, GitHub:tcbn-ai, Twitter: @tcbn_ai 14
ゲーム は、 に拡張される。 人ゲームとき、利得関数 は利得行列 を用いて以下のよう に表現される。 ゲーム理論の基礎 (非協力ゲーム) AiTachi,
GitHub:tcbn-ai, Twitter: @tcbn_ai 15
例:囚人のジレンマ 混合戦略集合 は以下のように定義される。 利得関数 は以下のように定義される。 ゲーム理論の基礎 (非協力ゲーム) AiTachi, GitHub:tcbn-ai, Twitter:
@tcbn_ai 16
Def (最適反応) を に対する純粋戦略最適反応、 を に対する混合戦略最適反応と呼ぶ。 純粋戦略最適反応対応 : 混合戦略最適反応対応 :
ゲーム理論の基礎 (非協力ゲーム) AiTachi, GitHub:tcbn-ai, Twitter: @tcbn_ai 17
Def (ナッシュ均衡) が成り立つとき、 をナッシュ均衡という。 ナッシュ均衡 すべてのプレイヤーにとって合理的な解 有限ゲームでは必ず存在 (複数存在する可能性あり) ゲーム理論の基礎 (非協力ゲーム)
AiTachi, GitHub:tcbn-ai, Twitter: @tcbn_ai 18
例:調整ゲーム \ ゲーム理論の基礎 (非協力ゲーム) AiTachi, GitHub:tcbn-ai, Twitter: @tcbn_ai 19
プレイヤー の混合戦略を で固定する。プレイヤ ー が純粋戦略をとるときの期待利得は、 ゲーム理論の基礎 (非協力ゲーム) AiTachi, GitHub:tcbn-ai, Twitter:
@tcbn_ai 20
プレイヤー の混合戦略を で固定する。プレイヤー が純粋戦略をとるときの期待利得は、 ゲーム理論の基礎 (非協力ゲーム) AiTachi, GitHub:tcbn-ai, Twitter: @tcbn_ai
21
混合戦略最適反応対応 は、 と求められる。 ゲーム理論の基礎 (非協力ゲーム) AiTachi, GitHub:tcbn-ai, Twitter: @tcbn_ai 22
ナッシュ均衡は ゲーム理論の基礎 (非協力ゲーム) AiTachi, GitHub:tcbn-ai, Twitter: @tcbn_ai 23
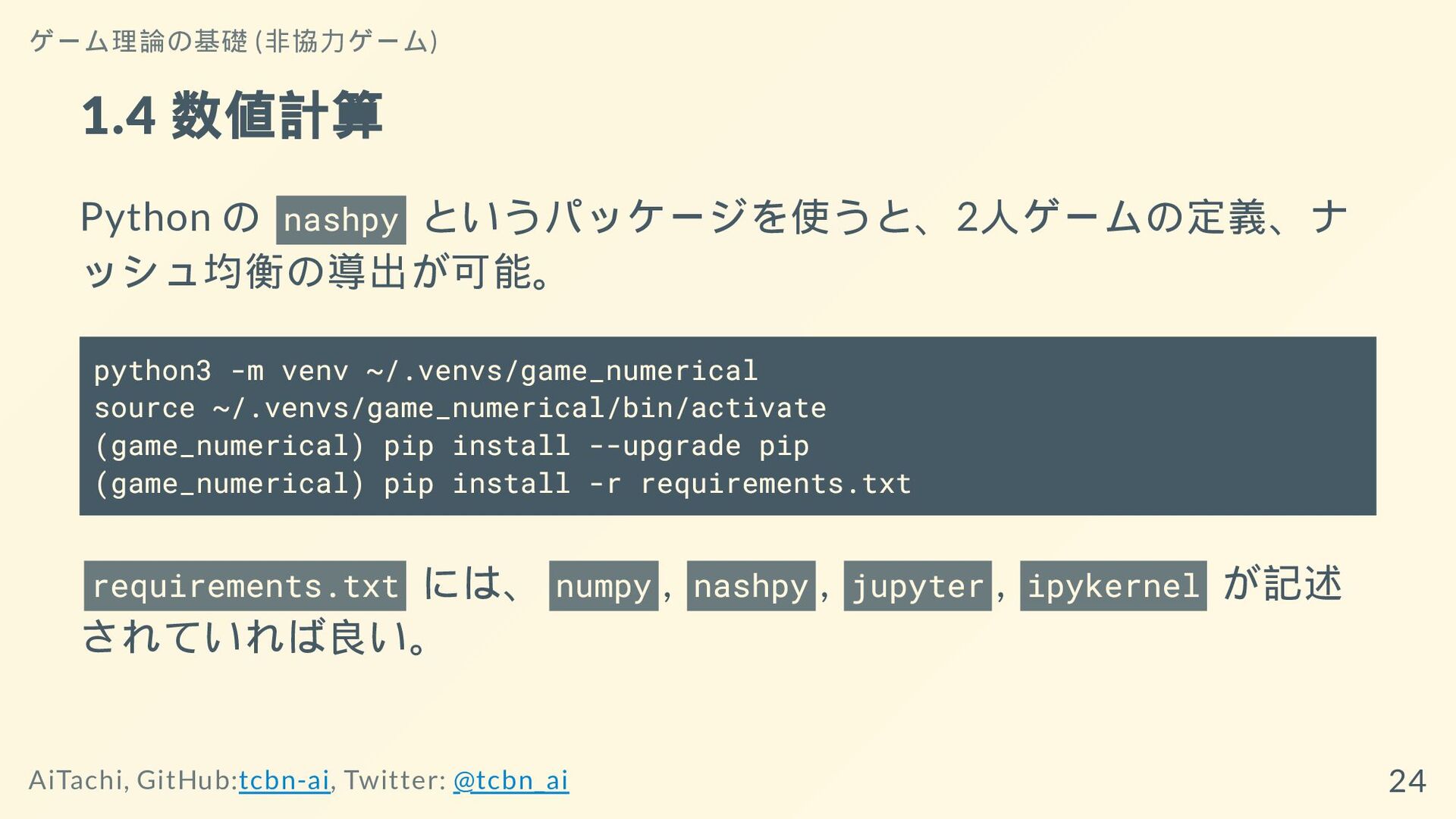
1.4 数値計算 Python の nashpy というパッケージを使うと、2人ゲームの定義、ナ ッシュ均衡の導出が可能。 python3 -m venv
~/.venvs/game_numerical source ~/.venvs/game_numerical/bin/activate (game_numerical) pip install --upgrade pip (game_numerical) pip install -r requirements.txt requirements.txt には、 numpy , nashpy , jupyter , ipykernel が記述 されていれば良い。 ゲーム理論の基礎 (非協力ゲーム) AiTachi, GitHub:tcbn-ai, Twitter: @tcbn_ai 24
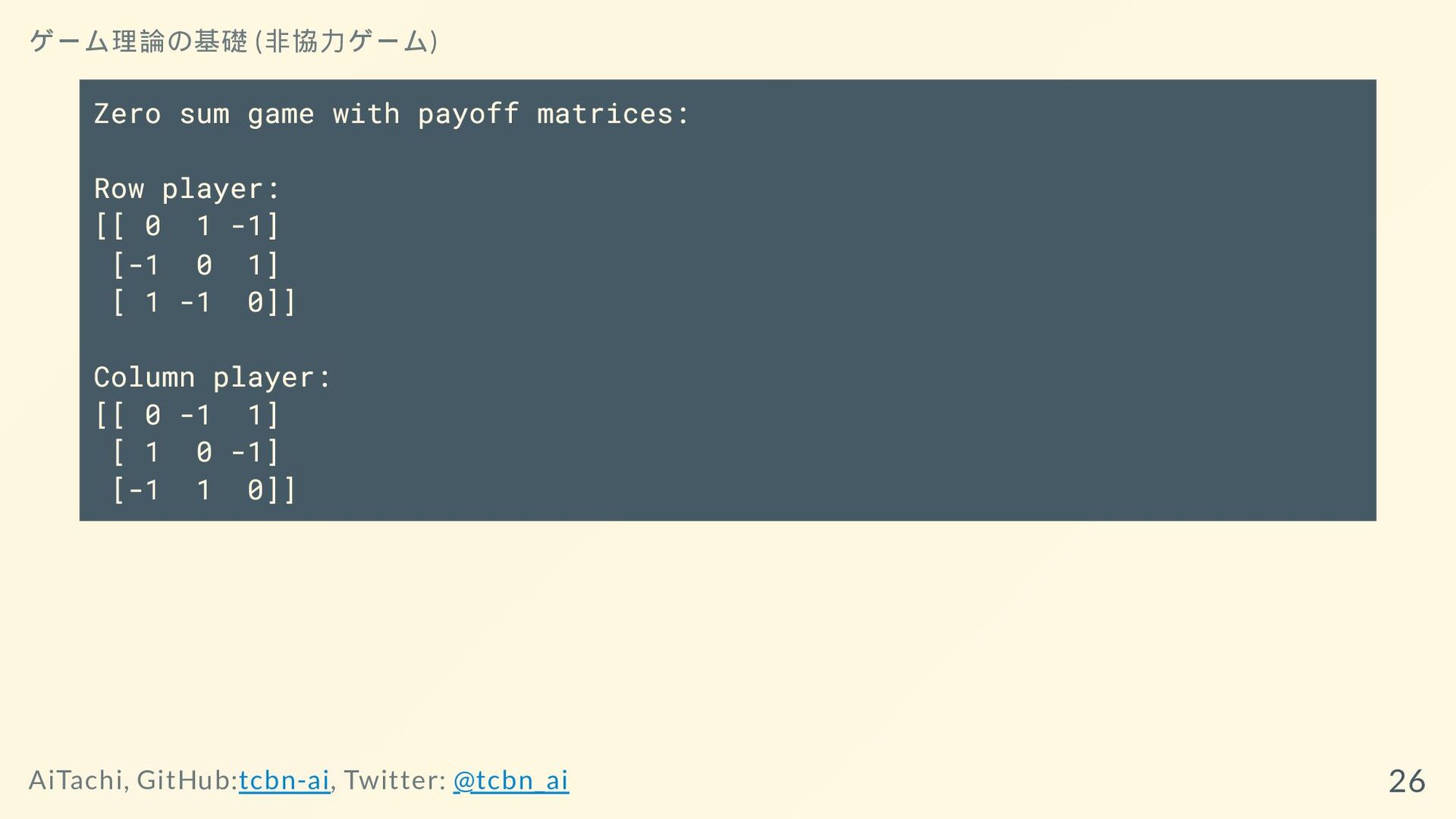
例:じゃんけん A = np.array([[0, 1, -1], [-1, 0, 1], [1,
-1, 0]]) B = np.array([[0, -1, 1], [1, 0, -1], [-1, 1, 0]]) coordination_game = nash.Game(A, B) coordination_game ゲーム理論の基礎 (非協力ゲーム) AiTachi, GitHub:tcbn-ai, Twitter: @tcbn_ai 25
Zero sum game with payoff matrices: Row player: [[ 0
1 -1] [-1 0 1] [ 1 -1 0]] Column player: [[ 0 -1 1] [ 1 0 -1] [-1 1 0]] ゲーム理論の基礎 (非協力ゲーム) AiTachi, GitHub:tcbn-ai, Twitter: @tcbn_ai 26
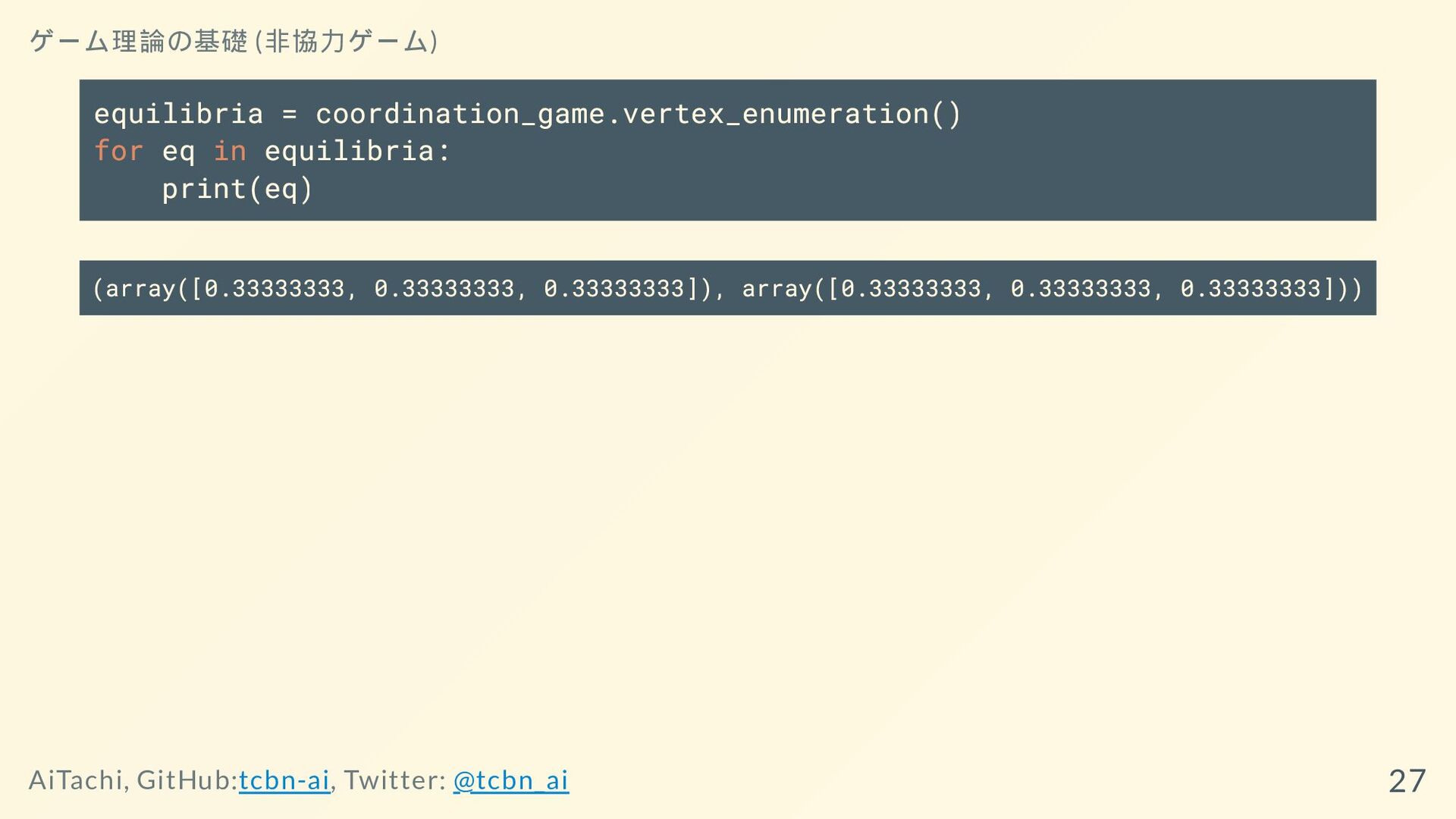
equilibria = coordination_game.vertex_enumeration() for eq in equilibria: print(eq) (array([0.33333333, 0.33333333,
0.33333333]), array([0.33333333, 0.33333333, 0.33333333])) ゲーム理論の基礎 (非協力ゲーム) AiTachi, GitHub:tcbn-ai, Twitter: @tcbn_ai 27
参考文献 [1] 岡田章, ゲーム理論, 2011. [2] H. Peter, Game Theory:
A Multi-Leveled Approach, Springer, 2015. [3] Nashpy's documentation, accessed on 08/06/2022 ゲーム理論の基礎 (非協力ゲーム) AiTachi, GitHub:tcbn-ai, Twitter: @tcbn_ai 28
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![例:じゃんけん A = np.array([[0, 1, -1], [-1, 0, 1], [1,](https://files.speakerdeck.com/presentations/b44119d0252f4cba855162cc34147795/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
![参考文献 [1] 岡田章, ゲーム理論, 2011. [2] H. Peter, Game Theory:](https://files.speakerdeck.com/presentations/b44119d0252f4cba855162cc34147795/slide_27.jpg){kind=link}