Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
データサイエンスコミュニティ LT大会 #1
Search
Tetsuya Mito
July 24, 2024
130
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
データサイエンスコミュニティ LT大会 #1
オンライン登壇で Pandas3 で PyArrow が必須になる件について登壇しました。
Tetsuya Mito
July 24, 2024
More Decks by Tetsuya Mito
See All by Tetsuya Mito
JAWS FESTA 2024 in 広島のご紹介
tetsuya_mito
0
91
ORマッパを使ってる場合の監視とパフォーマンスチューニング
tetsuya_mito
0
55
Featured
See All Featured
Fireside Chat
paigeccino
42
4k
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
The Impact of AI in SEO - AI Overviews June 2024 Edition
aleyda
5
1.1k
The Spectacular Lies of Maps
axbom
PRO
1
870
Music & Morning Musume
bryan
47
7.3k
A Tale of Four Properties
chriscoyier
163
24k
Skip the Path - Find Your Career Trail
mkilby
1
170
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
160
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
420
Sharpening the Axe: The Primacy of Toolmaking
bcantrill
46
2.9k
[RailsConf 2023 Opening Keynote] The Magic of Rails
eileencodes
31
10k
Transcript
Pandas3へ向けての 依存関係まわり データサイエンスコミュニティ LT会 #1
自己紹介 氏名: 三戸 鉄也 (みと てつや) 所属: Wardish合同会社 CEO 社歴:
SIer → 起業(SIer) 年齢: 47歳
申込状況: 273/300
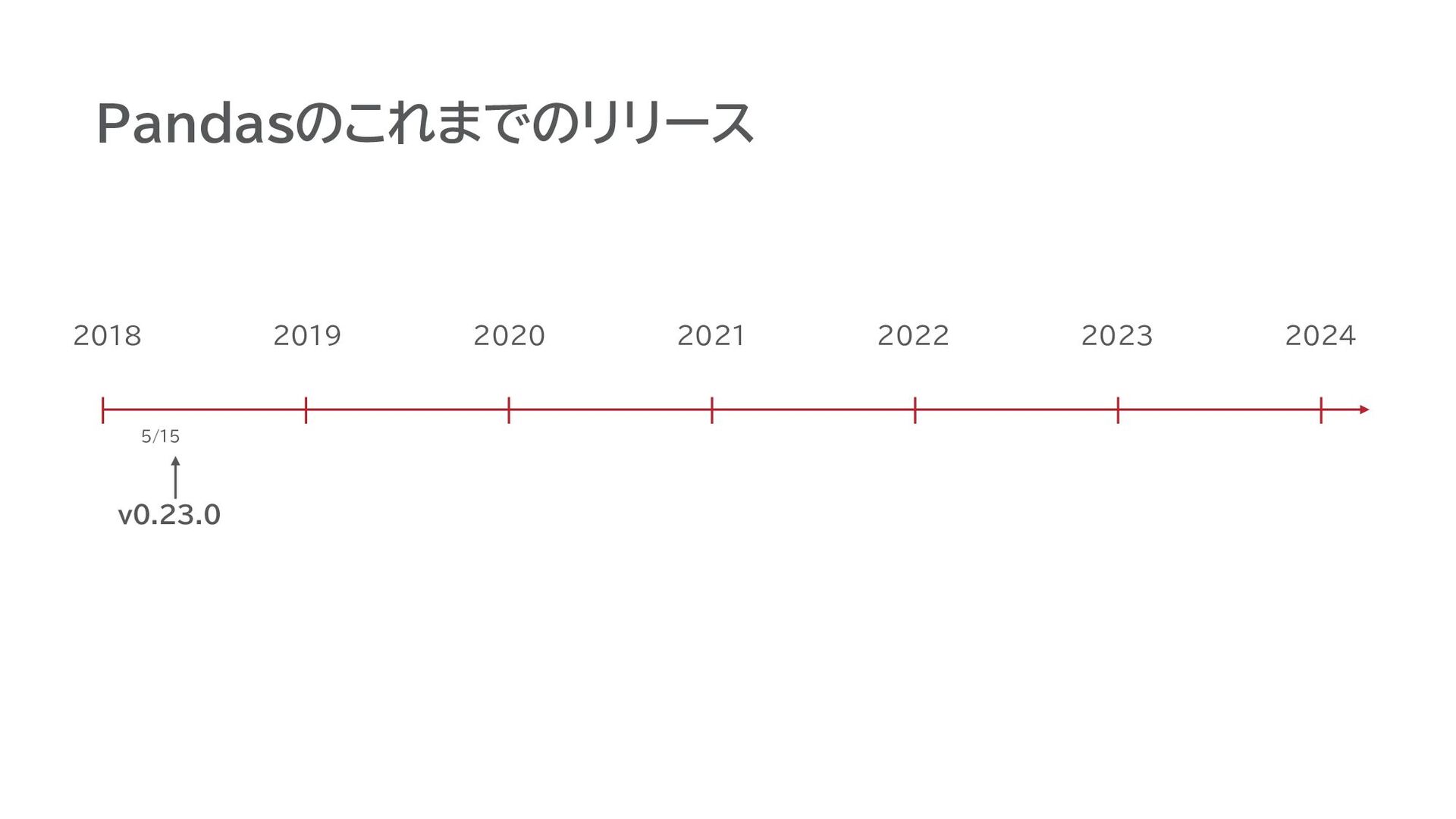
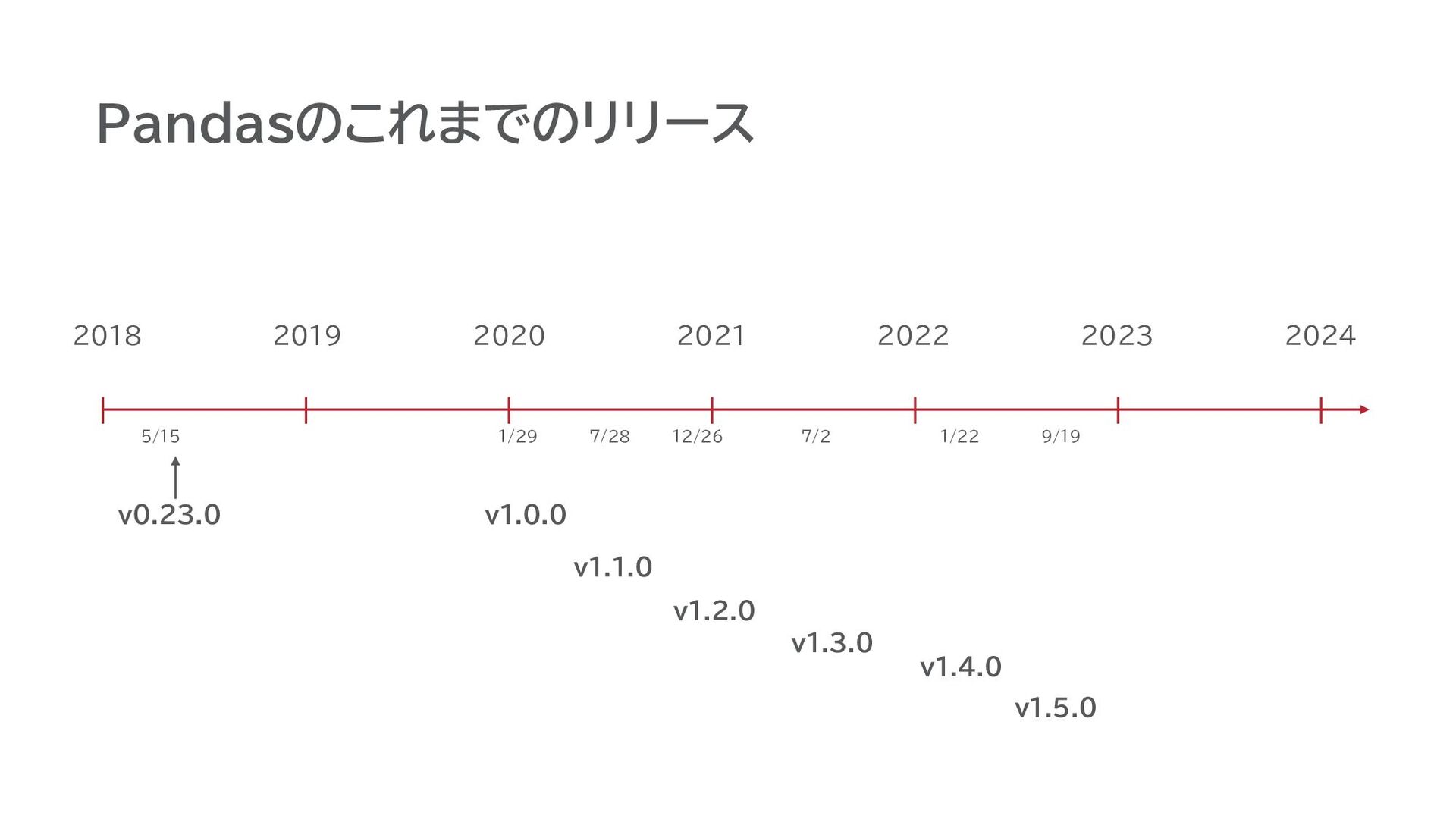
Pandasのこれまでのリリース v0.23.0 2018 5/15 2019 2020 2021 2022 2023 2024
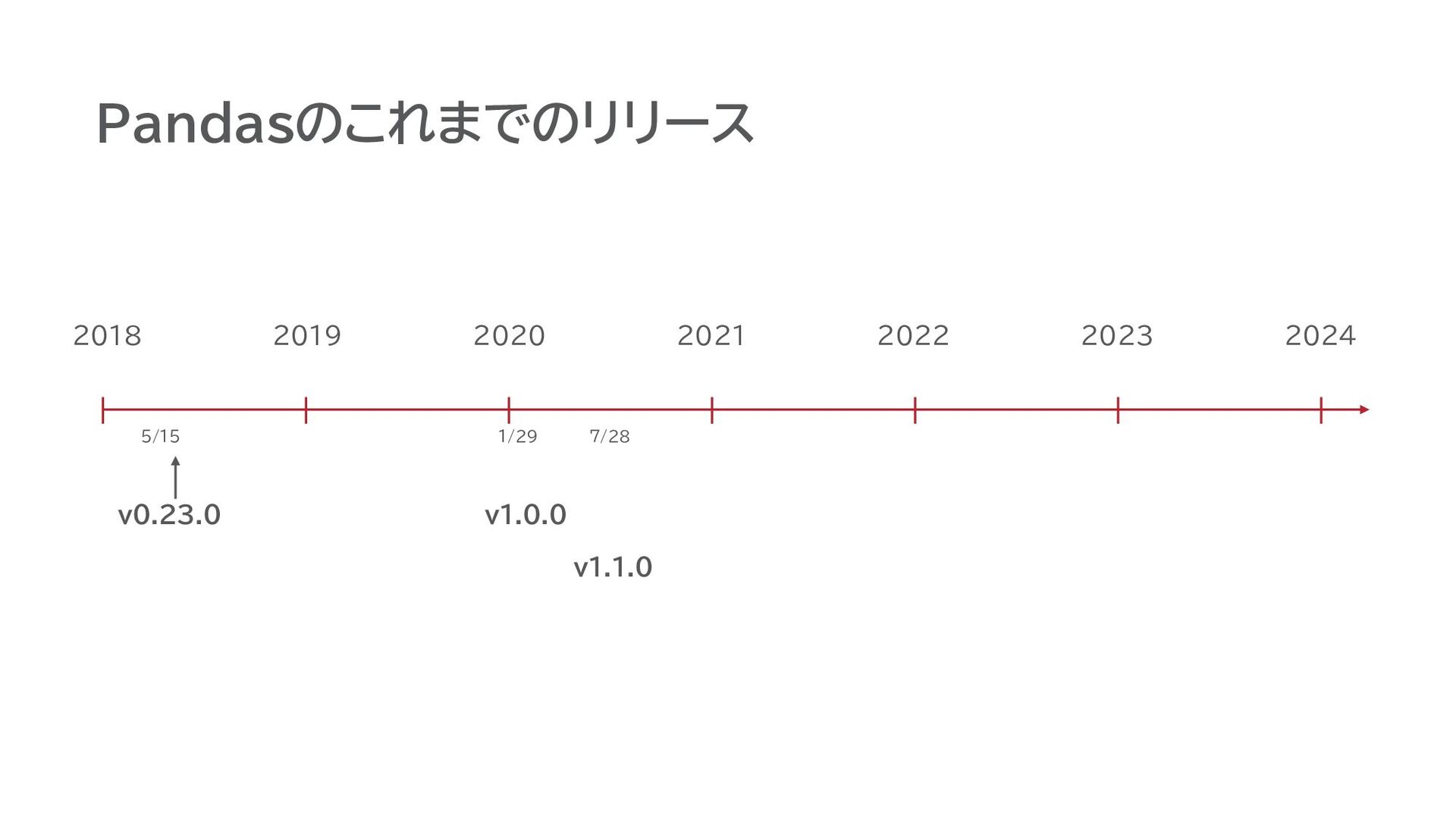
Pandasのこれまでのリリース v0.23.0 2018 v1.0.0 5/15 2019 2020 2021 2022 2023
2024 v1.1.0 1/29 7/28
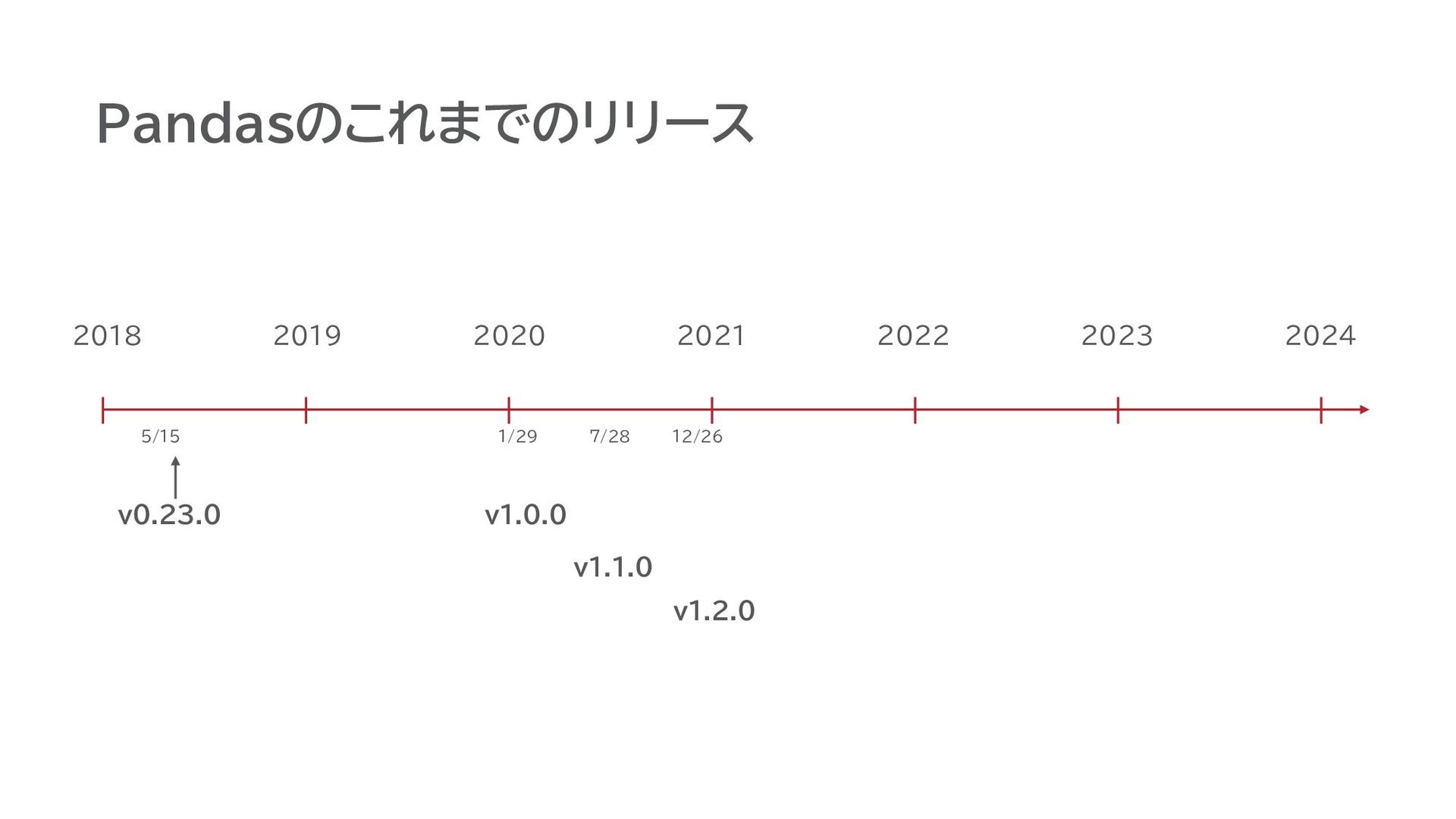
Pandasのこれまでのリリース v0.23.0 2018 v1.0.0 5/15 2019 2020 2021 2022 2023
2024 v1.1.0 v1.2.0 1/29 7/28 12/26
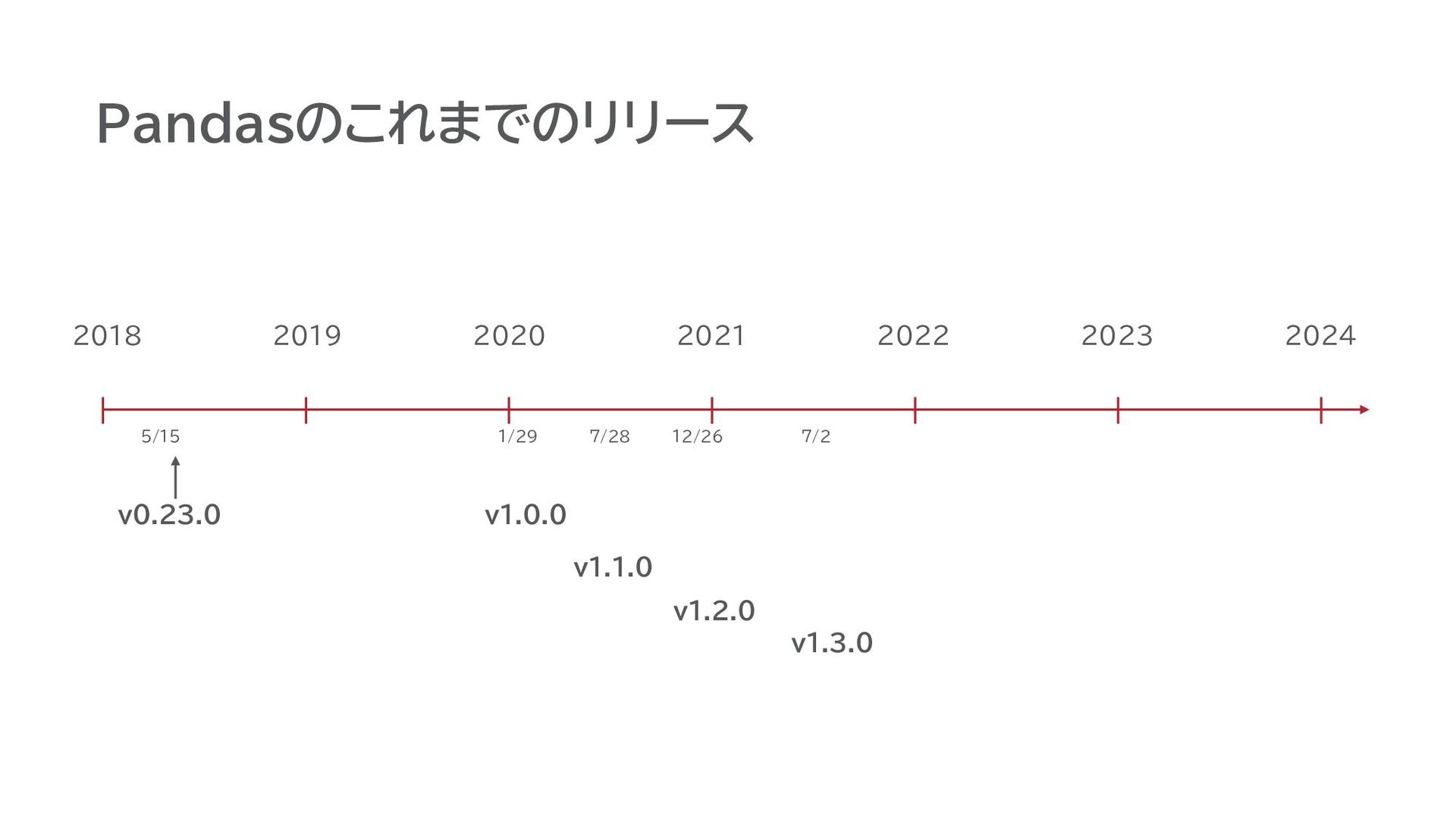
Pandasのこれまでのリリース v0.23.0 2018 v1.0.0 5/15 2019 2020 2021 2022 2023
2024 v1.1.0 v1.2.0 v1.3.0 1/29 7/28 12/26 7/2
Pandasのこれまでのリリース v0.23.0 2018 v1.0.0 5/15 2019 2020 2021 2022 2023
2024 v1.1.0 v1.2.0 v1.3.0 v1.4.0 v1.5.0 1/29 7/28 12/26 7/2 1/22 9/19
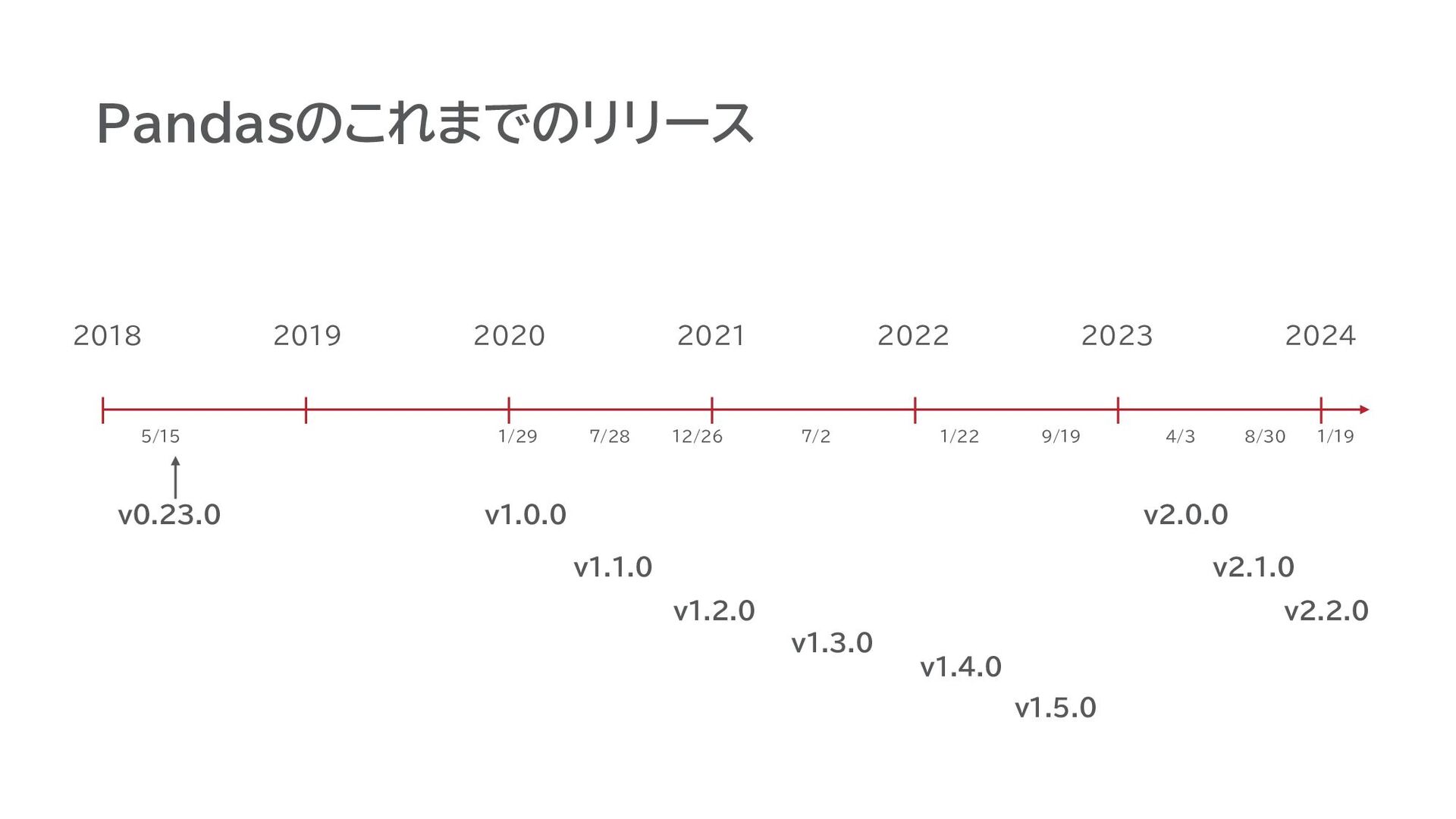
Pandasのこれまでのリリース v0.23.0 2018 v1.0.0 5/15 2019 2020 2021 2022 2023
2024 v1.1.0 v1.2.0 v1.3.0 v1.4.0 v1.5.0 v2.0.0 v2.1.0 v2.2.0 1/29 7/28 12/26 7/2 1/22 9/19 4/3 8/30 1/19
Pandasのこれまでのリリース v0.23.0 2018 v1.0.0 5/15 2019 2020 2021 2022 2023
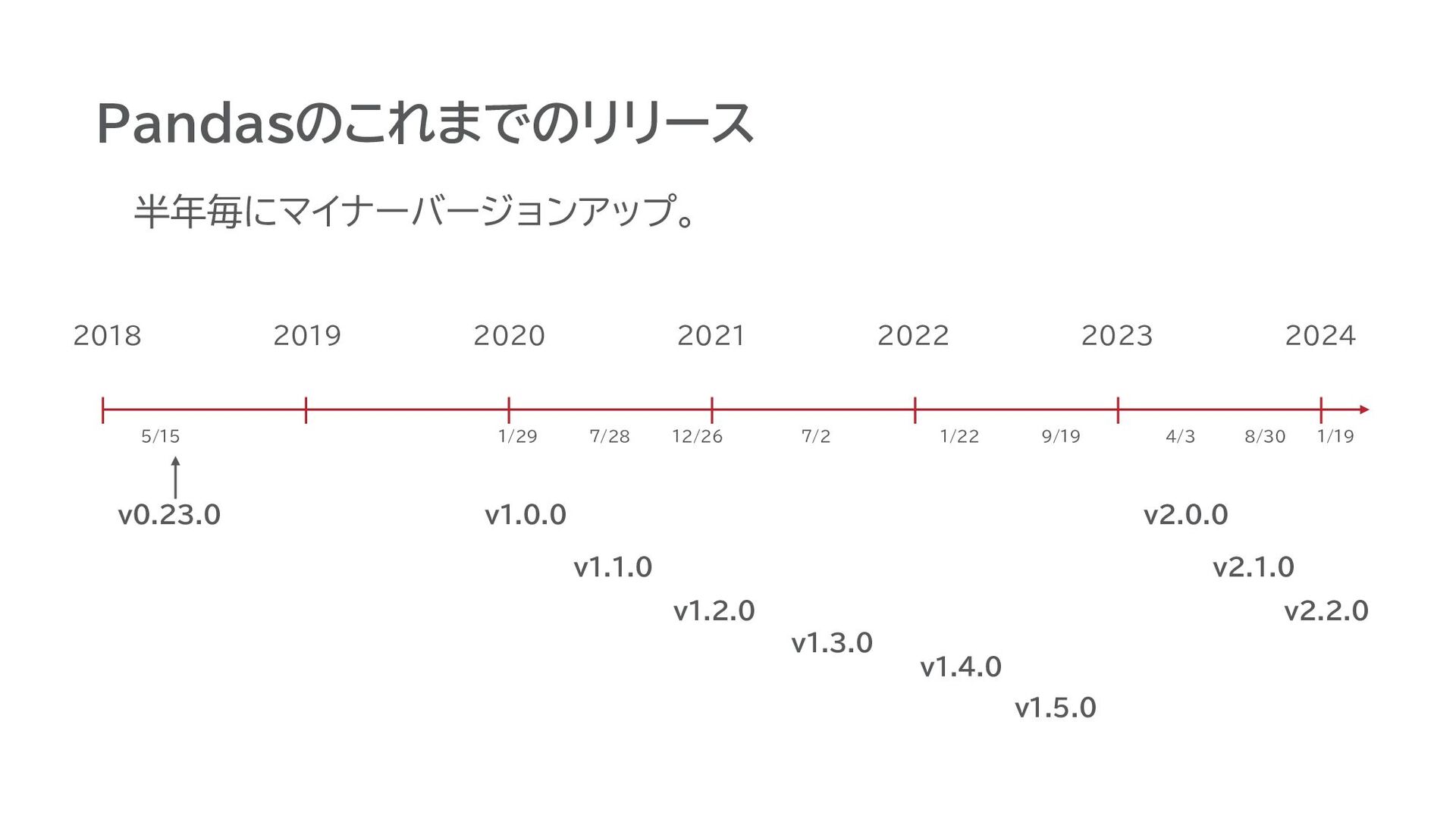
2024 v1.1.0 v1.2.0 v1.3.0 v1.4.0 v1.5.0 v2.0.0 v2.1.0 v2.2.0 1/29 7/28 12/26 7/2 1/22 9/19 4/3 8/30 1/19 半年毎にマイナーバージョンアップ。
Pandasのこれまでのリリース v0.23.0 2018 v1.0.0 5/15 2019 2020 2021 2022 2023
2024 v1.1.0 v1.2.0 v1.3.0 v1.4.0 v1.5.0 v2.0.0 v2.1.0 v2.2.0 1/29 7/28 12/26 7/2 1/22 9/19 4/3 8/30 1/19 半年毎にマイナーバージョンアップ。 この間は後方互換は保たれる
Pandas3の状況
Pandas3の状況 1.5.3 → 2.0.0 の時も同様だったので おそらく今年中にリリースされる見込み
Pandas3の依存関係 PyArrow が必須になります。
Pandas3の依存関係 PyArrow が必須になります。 いかんのか?
Pandas と PyArrow(Arrow)の関係 2.2.X 系でもライブラリ入れてたら使える。
Pandas と PyArrow(Arrow)の関係 2.2.X 系でもライブラリ入れてたら使える。 集計周りのパフォーマンスは大して向上しない。 が、文字列の扱いに関してはメモリの利用量が大幅に低減され、 処理においても2倍近くパフォーマンスが向上する。
Pandas と PyArrow(Arrow)の関係 2.2.X 系でもライブラリ入れてたら使える。 3.0.0からは 文字列はデフォルトで pyarrow の文字列型になります。 集計周りのパフォーマンスは大して向上しない。
が、文字列の扱いに関してはメモリの利用量が大幅に低減され、 処理においても2倍近くパフォーマンスが向上する。
そもそもPythonって文字列遅いの? Pythonは文字列をNULL文字で終端するので ASCIIで23byte、Unicodeで48Byteが必ず付与される。 (加えてポインタの8Byte) 100文字が100万あるテキストファイルは、およそ100MB。 だけど、56Byteが100万追加されてるので、メモリ上では156MB以上 を必要とする。 短い文字列が大量に存在するときは絶望
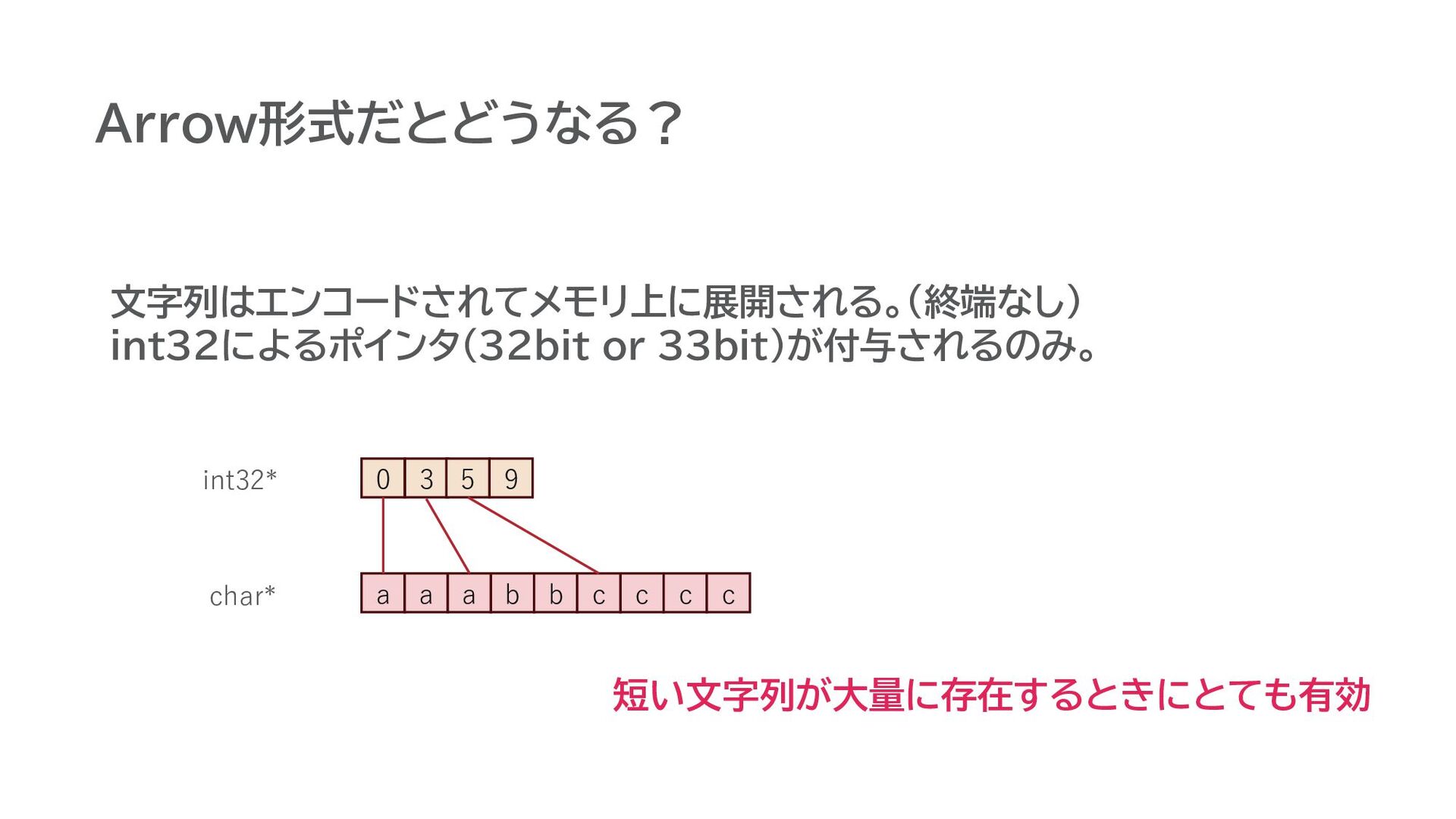
Arrow形式だとどうなる? 文字列はエンコードされてメモリ上に展開される。(終端なし) int32によるポインタ(32bit or 33bit)が付与されるのみ。 短い文字列が大量に存在するときにとても有効 a a a b
b c c c c 0 3 5 9 int32* char*
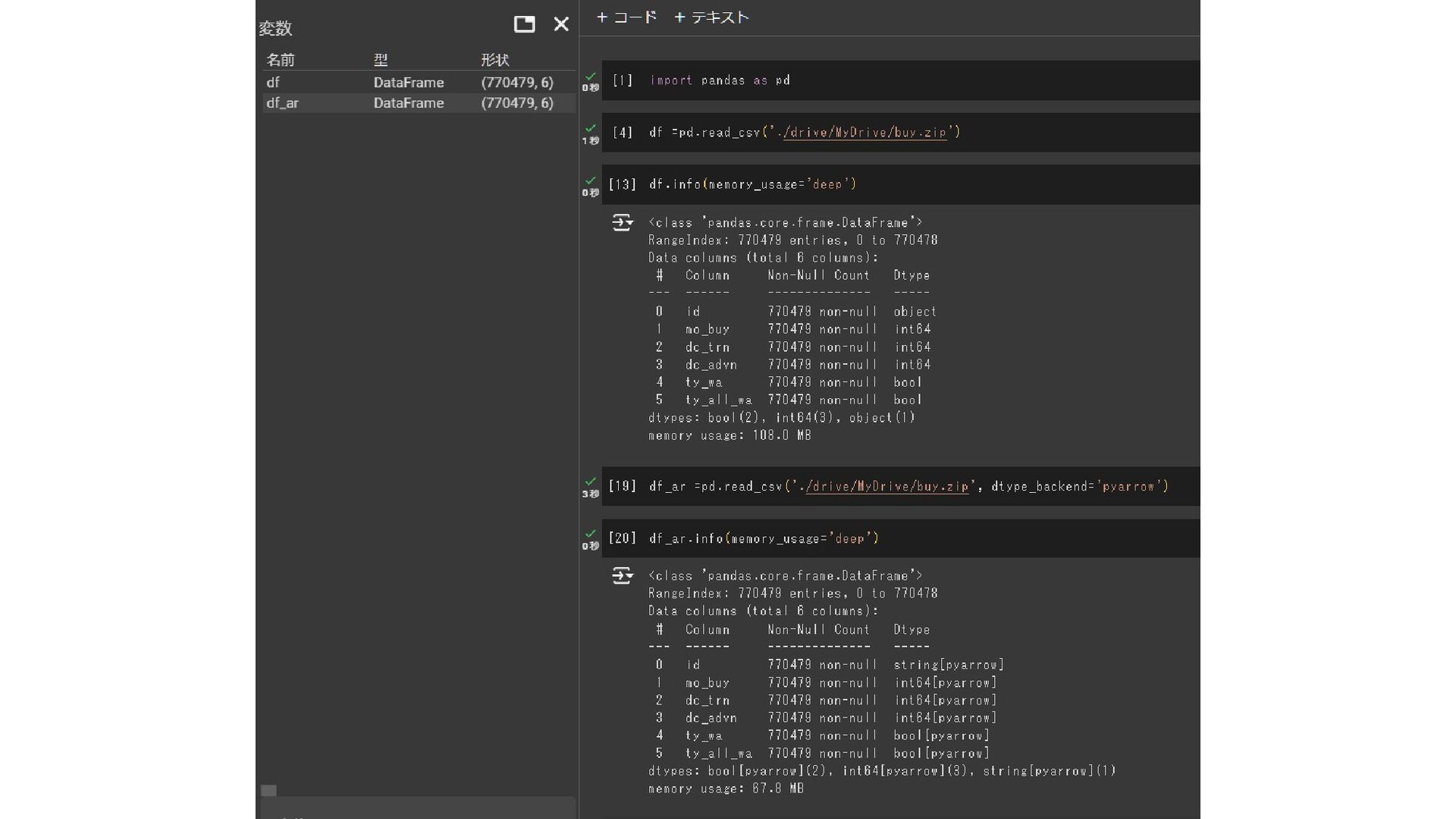
いつ効く? read_csvのタイミング。 2.X.X系だとdtype_backend=‘pyarrow’で実現。 ※ engine=‘pyarrow’ だけだとパースがpyarrowになるだけ。
None
None
わりと効く object pyarrow 60万件くらいで、文字列多め
Pandas3の依存関係 PyArrow が必須になります。 ええやん?
Pandas3の依存関係 PyArrow のライブラリがそんな小さくない 134MB pyarrow
Pandas3の依存関係 PyArrow のライブラリがそんな小さくない 76MB pandas 39MB numpy 37MB numpy.libs 25MB
botocore 16MB pip AWSに使うツール
Pandas3の依存関係 PyArrow のライブラリがそんな小さくない 76MB pandas 39MB numpy 37MB numpy.libs 25MB
botocore 16MB pip AWSに使うツール Serverless環境で動かそうとするとちょっと辛い。 ※ 素のLambdaでは200MBの制限あり。 ここに134MB載せるの?
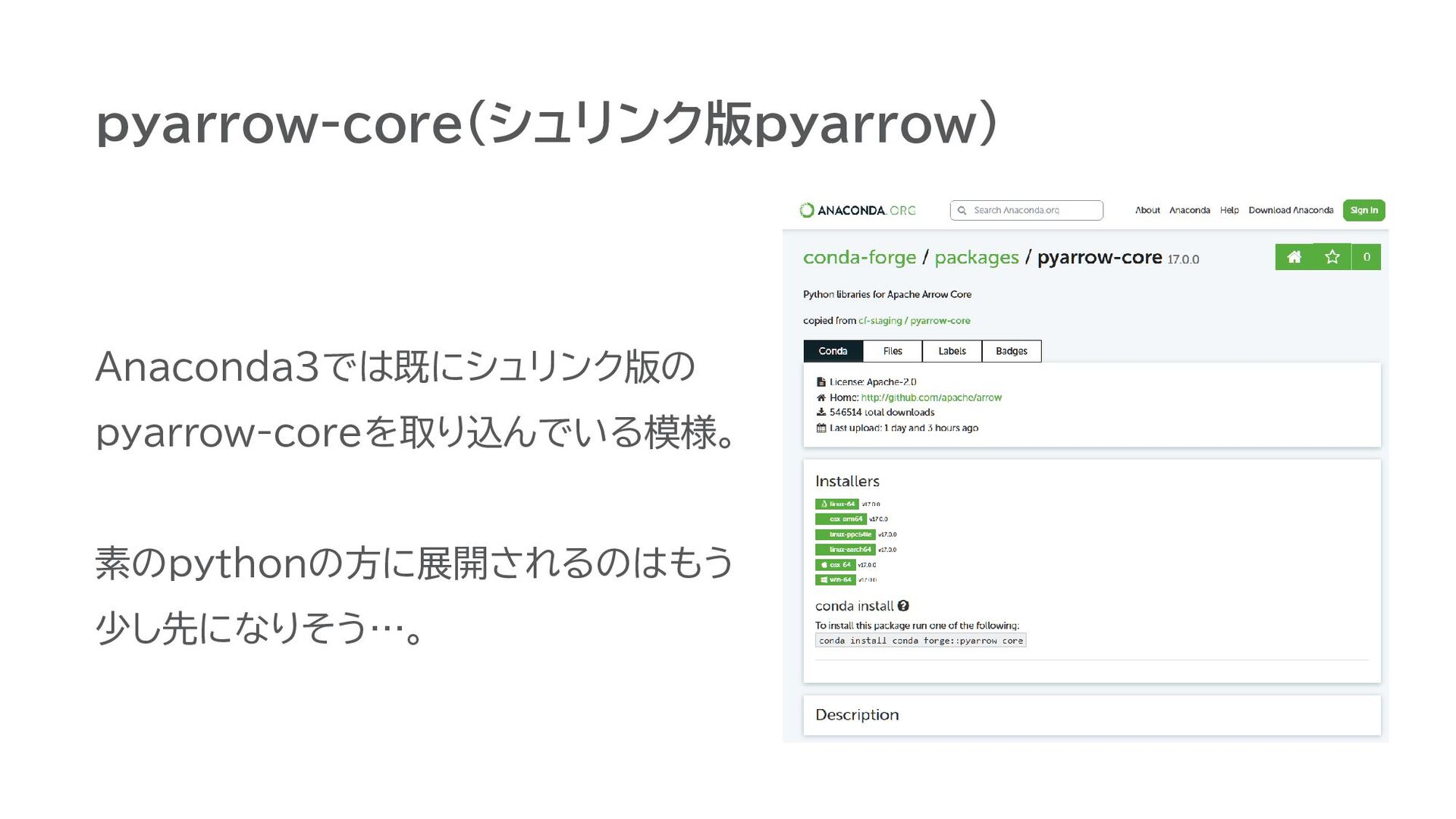
pyarrow-core(シュリンク版pyarrow) Anaconda3では既にシュリンク版の pyarrow-coreを取り込んでいる模様。 素のpythonの方に展開されるのはもう 少し先になりそう…。
Pandas3の依存関係 PyArrow が必須になります。 まあよさげ。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}