II Winner, Coupon Purchase Prediction 3rd) • author of “Data Analysis Techniques to Win Kaggle” (book written in Japanese) • organizer of Kaggle Meetup Tokyo • freelance engineer(?), used to be an actuary
to Win Kaggle” Some feature engineering techniques • II. Gradient Boosting Decision Tree Implementation Algorithm overview Implementation (in Kaggle Kernel) Algorithm variations and computational complexity
Japanese, published in Oct. 2019. (https://www.amazon.co.jp/dp/4297108437) • authors are threecourse (me), jack, hskksk, maxwell • table of contents in English is here (my blog). • sold much more than expected (more than 10,000 copies in the first month, possibly one of the best-selling IT Development book of the year)
- covering intermediate level contents books for beginners are too many, but for intermediates are few. - Kaggle is catchy many data scientists know and are interested in Kaggle, even though might not want to participate. - insights from Kaggle are useful not only for competition, also for business especially, evaluation metrics and validation methods are well received.
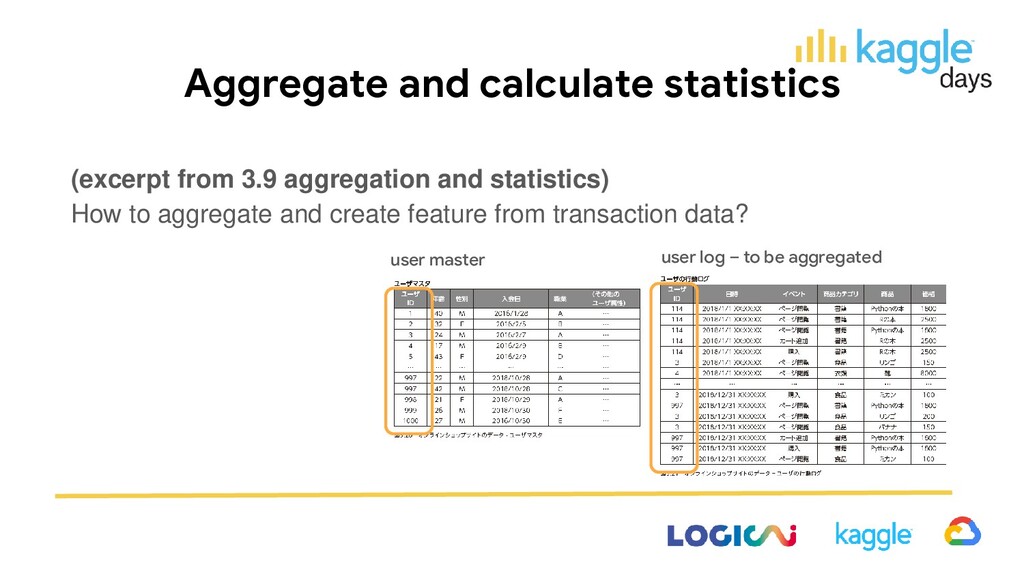
• a. transform variable (ex. onehot-encoding, rankgauss) • b. merge tables • c. aggregate and calculate statistics (see following slides) • d. time-series (ex. lag/lead feature) • e. dimension reduction and unsupervised (ex. UMAP, clustering) • f. other techniques and ideas (see following slides)
count, exist or not - sum, average, ratio - max, min, std, median, quantile, kurtosis, skewness b. statistics using temporal information (ex. for log data) - first, most recent - interval, frequency - interval and record just after key events - focusing on order, transition, cooccurrence, repetition
of logs (ex. types of events or purchased products) - filter by time or period (ex. within a week, only holidays) d. change unit for aggregation - for example, aggregate not only by user, but also by same gender/ages/occupation/location users e. focus not only users, but also items - aggregate by items - group items in the same category - focus special types of products (ex. organic, Asian food)
techniques) 3.12.1 focus on mechanisms underlying • consider user's behavior • consider service provider’s behavior • check common practice in the industry (ex. disease diagnostic criteria) • combining variables to create an index (ex. Body Mass Index from height and weight) • consider mechanism of natural phenomena • try out the service of competition host by yourself
example: Caterpillar Tube Pricing • Task was to predict the price for combination of Tube and Quantity (=amount purchased). • There were multiple Quantity records for each tube. Quantity combination had some patterns. (ex. some tubes has 4 records where Quantity is [1, 2, 10, 20] others have 3 records where Quantity is [1, 5, 10]) • Here, feature that which Quantity pattern the Tube belong to was effective. (cf. https://www.kaggle.com/c/caterpillar-tube-pricing/discussion/16264#91207) tube-id quantity target tube-001 1 2 tube-001 2 4 tube-001 10 20 tube-001 20 40 tube-002 1 2 tube-002 5 4 tube-002 10 6 tube-003 1 3 tube-003 5 6 tube-003 10 9 tube-004 1 3 tube-004 2 6 tube-004 10 30 tube-004 20 60
example: Quora Question Pairs • Task was classification whether question pair has the same content or not. • A question often appeared in another question pair. Here, when questions (A, B) are the same, and (B, C) are the same, it can be deduced question (A, C) are the same. • Also, #vertex of maximum clique that contains a question was used as a feature. (cf. https://www.slideshare.net/tkm2261/quora-76995457) https://qard.is.tohoku.ac.jp/T-Wave/?p=434
example: Bosch Production Line Performance • Task was classification whether product was good or bad. • Products pass through multiple sensors, when and which sensors product passed was offered. Features below were used (cf. https://www.slideshare.net/hskksk/kaggle-bosch): • Patterns based on which sensors they passed. It was visible that there were several sensor-passing patterns. • other products that have just passed the sensor.
difference and ratio of price compared to average of same product/category/user/location (ex. Avito Demand Prediction Challenge, 9th solution) • loan amount compared to average of same occupation users. (ex. Home Credit Default Risk) • relative return compared to market average return (ex. Two Sigma Financial Modeling Challenge)
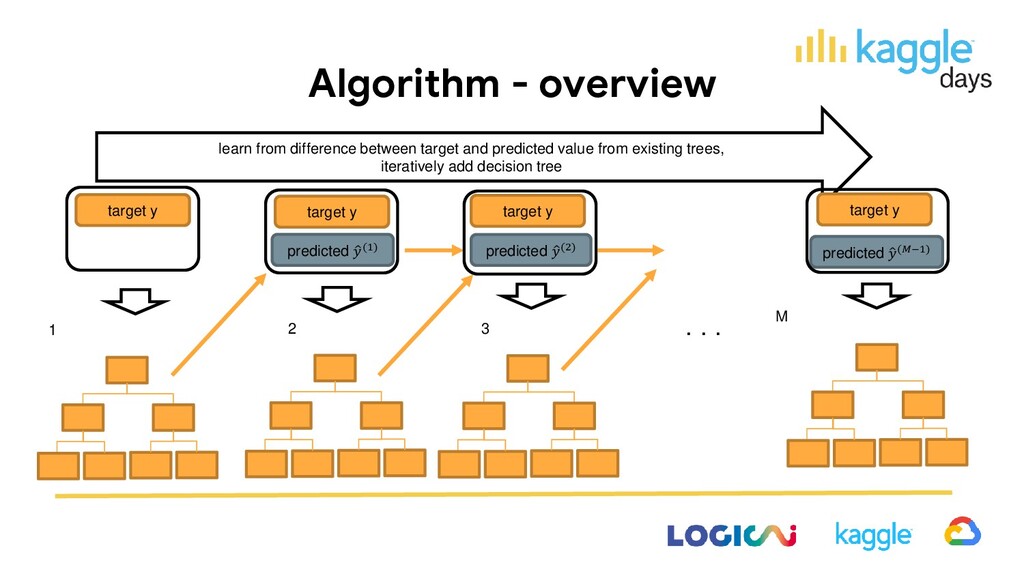
value from existing trees, iteratively add decision tree ・・・ 1 2 M target y predicted ො (1) target y 3 predicted ො (2) target y predicted ො (−1) target y
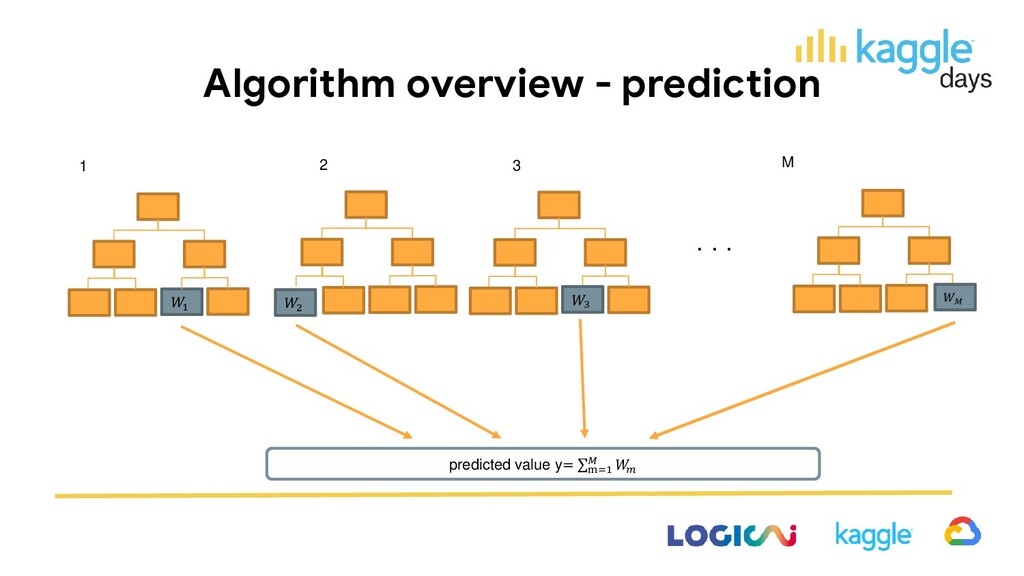
algorithm as below (It’s simplified, some optimization techniques are omitted.) 1. Pre-sort data for each feature: pre-sort data to efficiently iterate over split values. 2. Construct trees for each tree construction: i. update prediction with existing trees ii. calculate gradient and hessian of each record for each depth and for each node iii-a. find best split – iterate over features and possible split values iii-b. update node and create new child nodes iii-c. assign records to child nodes
the key of the algorithm. How to decide the best split? • Best weight and loss of the group can be approximately calculated with sum of gradient and hessian of the group. (note: constant term and regularization omitted) • Thus, when the split is decided and divide groups into two nodes, the best weight and loss of the new two nodes can be calculated. • Find iteratively over features and possible split values, efficiently with pre-sorted data. • The best split which yields the minimum sum loss of the new two groups is chosen. (cf. XGBoost: A Scalable Tree Boosting System 2.2 Gradient Tree Boosting) best weight and loss: objective function:
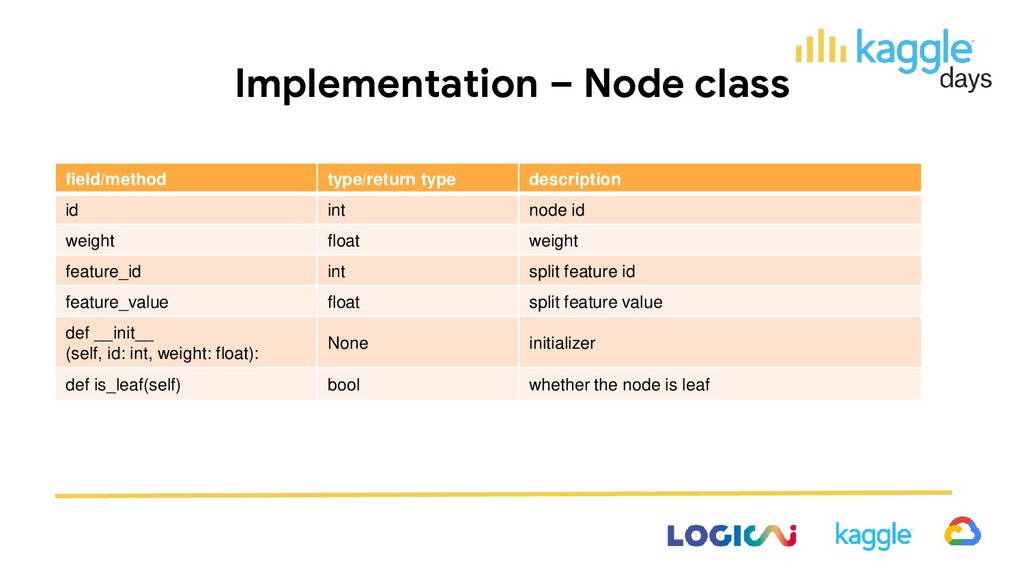
type description def left_child_id(cls, id: int) int id of left child node def right_child_id(cls, id: int) int id of right child node def loss(cls, sum_grad: float, sum_hess: float) float best loss of the group with sum gradient and hessian def weight(cls, sum_grad: float, sum_hess: float) float best weight of the group with sum gradient and hessian def node_ids_depth(self, d: int) List[int] node ids belong to the depth
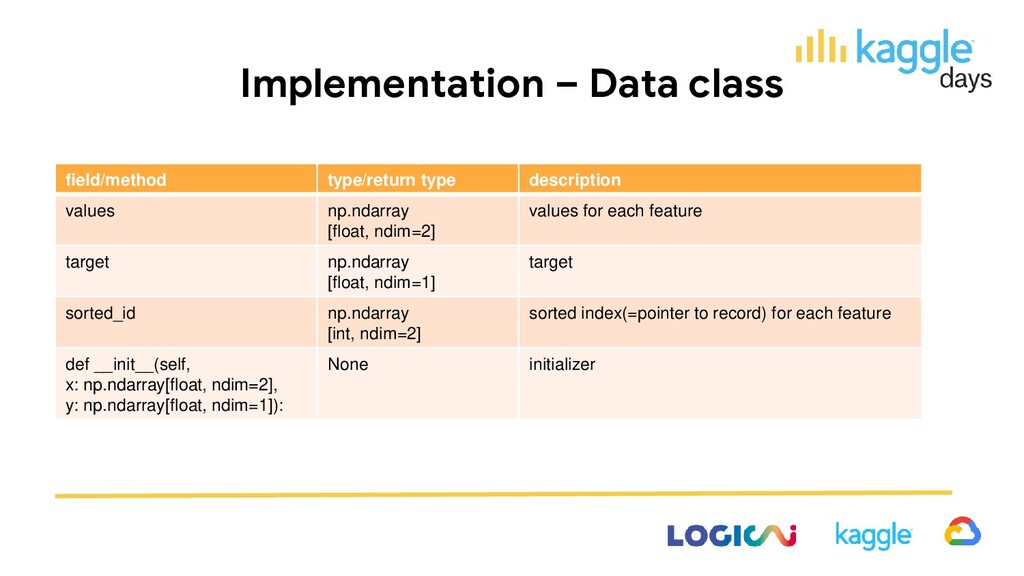
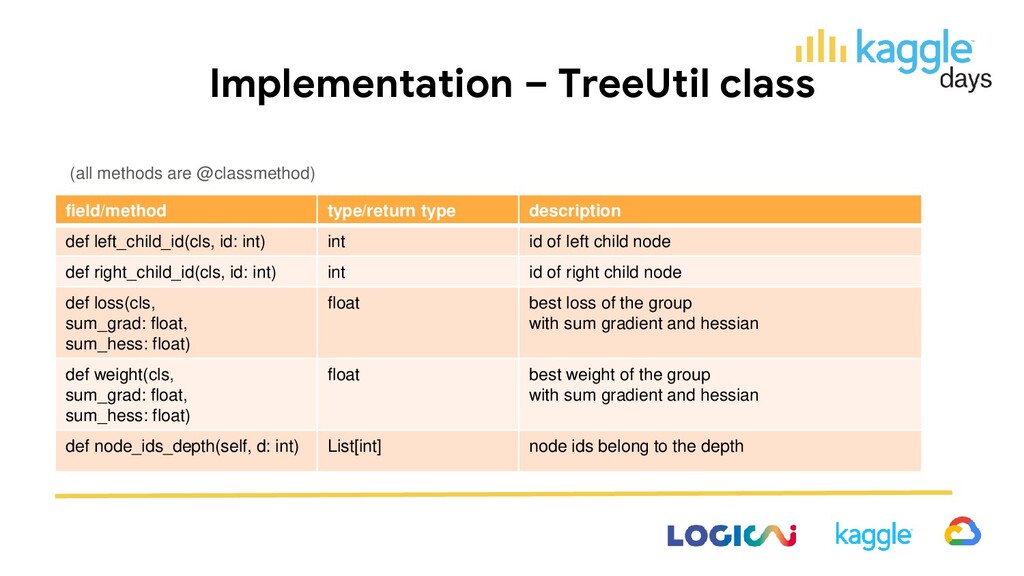
params: dict): None initializer def construct(self, data: Data, grad: np.ndarray[float, ndim=1], hess: np.ndarray[float, ndim=1]) None for each depth, for each node 1. find best split 2. update nodes and create new nodes 3. update node ids records belong to def predict(self, x: np.ndarray[float, ndim=2]) np.ndarray [float, ndim=1] predict with constructed tree
can be used for fast calculation. Tips are: • focus on inner loops • make function called frequently into c-function • designate variable used frequently with c-type • make foreach loop into simple range loop
of things to improve. • efficient calculation • handle of missing value • sparse data • regularization, pruning • monitoring, early stopping • multi-class classification • histogram-based algorithm • LightGBM features – leaf-wise, categorical feature, exclusive feature bundling
algorithm is used in xgboost with “exact” tree_method (usually default option). 1. for each feature, presort records 2. for each tree construction for each depth (for each node) a. find best split – iterate over records for each feature b. create new nodes and assign records to them Finding best split is dominant in computational complexity, Complexity is O(#trees x #depths x #records x #features)
is used in lightgbm and xgboost with “hist” tree_method. 1. for each feature assign records to histogram bins based on their values of the feature. 2. for each tree construction 1. for each depth (for each node) 1. make histogram for each feature. histogram contains gradient and hessian. 2. find split based on histograms Making histogram is dominant in computational complexity, complexity is O(#trees x #depths x #records x #feature) same as presorted algorithm. Making histogram is less costly to finding split, that is why histogram-based is faster than presorted method. (cf. https://lightgbm.readthedocs.io/en/latest/Features.html)
reduce computational complexity. “exclusive features” are features which don’t have values other than 0 at the same time. with EFB, • complexity of making histogram O(#feature x #records) -> O(#bundles x #records) • when finding splits, bundled features are unbundled and original features are used. Algorithm variations and computational complexity – EFB(Exclusive Feature Bundling)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}