Presentation on the paper titled "Using Morphological Knowledge in Open-Vocabulary Neural Language Model" by Austin Matthews, Graham Neubig, and Chris Dyer
Presentation on Using Morphological Knowledge in Open-Vocabulary Neural Language Model by Austin Matthews, Graham Neubig, and Chris Dyer
Matthews, Graham Neubig, and Chris Dyer Presented by: Tanay Kumar Saha July 6, 2018 Tanay Kumar Saha (Presentation) Neural Language Model July 6, 2018 1 / 15
Thoughts) How do we represent OOV (out of vocabulary) words? (What happens in the vision domain?) How to make the language models computationally efficient in both the training and the testing time? How to make use of all the data (labelled and unlabelled)? (Inductive vs Transductive Training) Let’s discuss the case for fasttext How morphological analysis can be used in language models? (root, antecedent, precedent, verb tense agreement, singular person agreement, and many others) Open Vocabulary Analysis: http://rainystreets.wikity.cc/open-vocabulary-analysis/ Data Driven (Open, for example, topic modeling) vs psychology theory driven (Closed, for example, giving a name to topics discovered by topic modeling approach) Tanay Kumar Saha (Presentation) Neural Language Model July 6, 2018 2 / 15
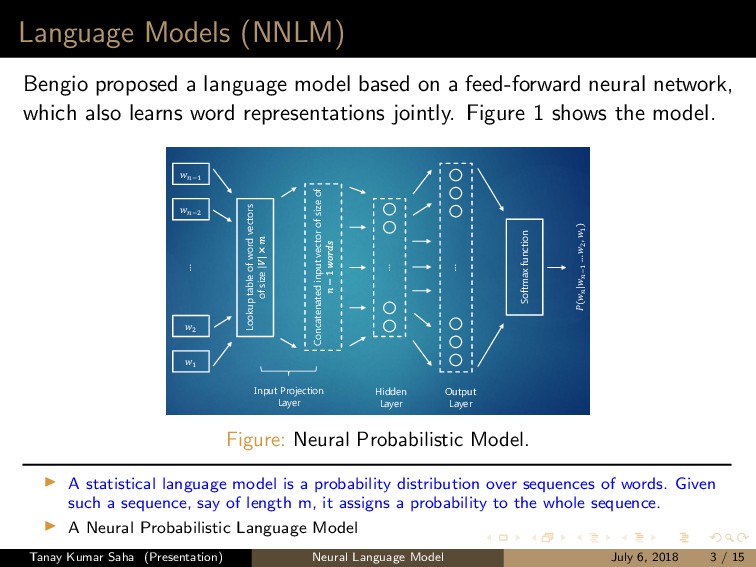
a feed-forward neural network, which also learns word representations jointly. Figure 1 shows the model. Feedforward NNLM −1 −2 2 1 ⋮ Lookup table of word vectors of size Concatenated input vector of size of ⋮ ⋮ Softmax function ( |−1 … 2 , 1 ) Input Projection Layer Output Layer Hidden Layer T R A I N I N G C O R P U S Figure: Neural Probabilistic Model. A statistical language model is a probability distribution over sequences of words. Given such a sequence, say of length m, it assigns a probability to the whole sequence. A Neural Probabilistic Language Model Tanay Kumar Saha (Presentation) Neural Language Model July 6, 2018 3 / 15
model for the same purpose as shown in Figure 2. Recurrent NNLM Lookup table of word vectors of size ⋮ ⋮ Softmax function Output Layer Hidden () T R A I N I N G C O R P U S Input Hidden Figure: Recurrent Neural Probabilistic Model. The model captures long-range dependencies. For example, the verb agreement between students and are in the sentence: ”The students who studied the hardest are getting the highest grades”. This is quiet impossible using a n-gram based model. Recurrent Neural Network Based Language Model Generating text with recurrent neural networks Tanay Kumar Saha (Presentation) Neural Language Model July 6, 2018 4 / 15
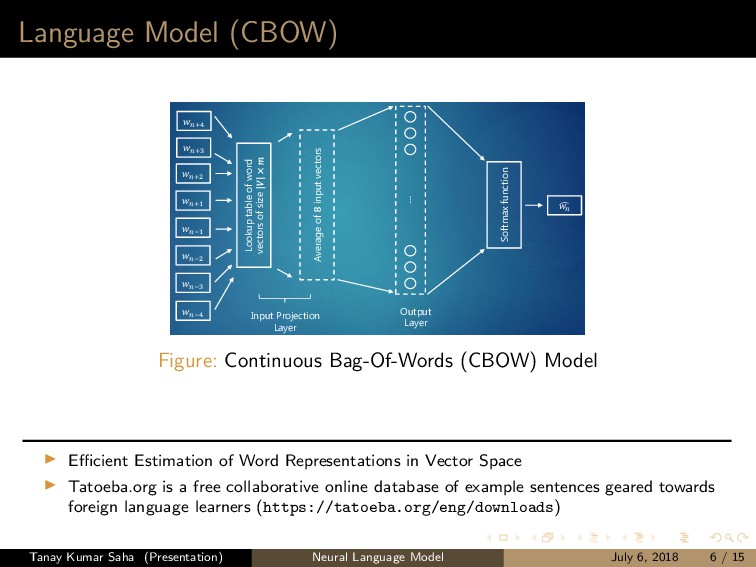
model except that: It does not have a hidden layer, which reduces the number of computations significantly; The projection layer performs an averaging of word vectors as opposed to concatenation In other words, the projection layer is shared for all input words, thus the order of words in the input context does not matter (hence the name bag-of-words Notice that it is not a language model in the sense that it predicts the current word given a context of both past and future words Efficient Estimation of Word Representations in Vector Space Tanay Kumar Saha (Presentation) Neural Language Model July 6, 2018 5 / 15
−2 Lookup table of word vectors of size Average of input vectors ⋮ Softmax function Input Projection Layer Output Layer T R A I N I N G C O R P U S +2 +1 −3 −4 Figure: Continuous Bag-Of-Words (CBOW) Model Efficient Estimation of Word Representations in Vector Space Tatoeba.org is a free collaborative online database of example sentences geared towards foreign language learners (https://tatoeba.org/eng/downloads) Tanay Kumar Saha (Presentation) Neural Language Model July 6, 2018 6 / 15
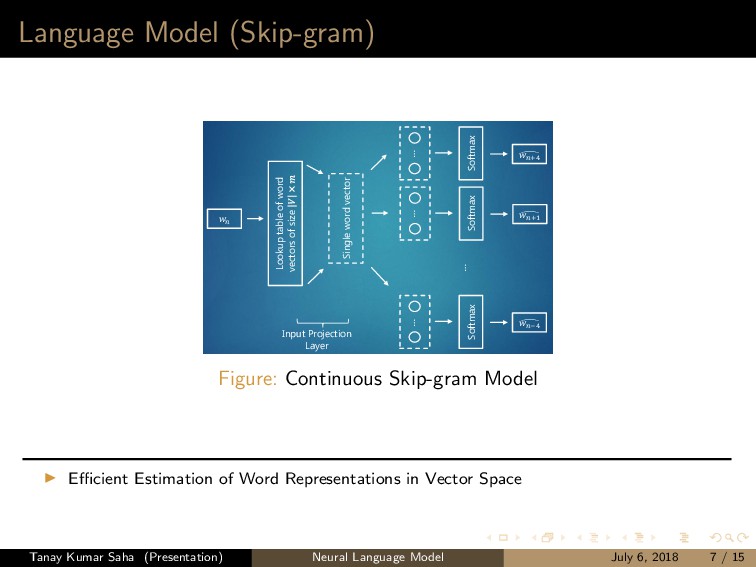
vectors of size Single word vector ⋮ Softmax Input Projection Layer Output Layer T R A I N I N G C O R P U S +4 ⋮ Softmax +1 ⋮ Softmax −4 ⋮ Figure: Continuous Skip-gram Model Efficient Estimation of Word Representations in Vector Space Tanay Kumar Saha (Presentation) Neural Language Model July 6, 2018 7 / 15
properties compared with other domains like speech and image The success of deep learning on the speech and image domains lies in its capability of discovering important signals from noisy input, the major challenge for text understanding is instead the missing information and semantic ambiguity Image understanding relies more on the information contained in the image itself than the background knowledge, while text understanding often needs to seek help from various external knowledge since text itself only reflects limited information and is sometimes ambiguous Knowledge-Powered Deep Learning for Word Embedding Tanay Kumar Saha (Presentation) Neural Language Model July 6, 2018 8 / 15
on morphological and grammatical rules It already contains well defined morphological and syntactic knowledge Morphological knowledge implies how a word is constructed, where morphological elements could be syllables, roots, or affix (prefix and suffix) Syntactic knowledge may consist of part-of-speech (POS) tagging as well as the rules of word transformation in different context, such as the comparative and superlative of an adjective, the past and participle of a verb, and the plural form of a noun. There has been a rich line of research works on mining semantic knowledge from large amounts of text data on the Web, such as WordNet, Freebase, and Probase Such semantic knowledge can indicate entity category of the word, and the relationship between words/entities, such as synonyms, antonyms, belonging-to and is-a. For example, Portland belonging-to Oregon; Portland is-a city Knowledge-Powered Deep Learning for Word Embedding Tanay Kumar Saha (Presentation) Neural Language Model July 6, 2018 9 / 15
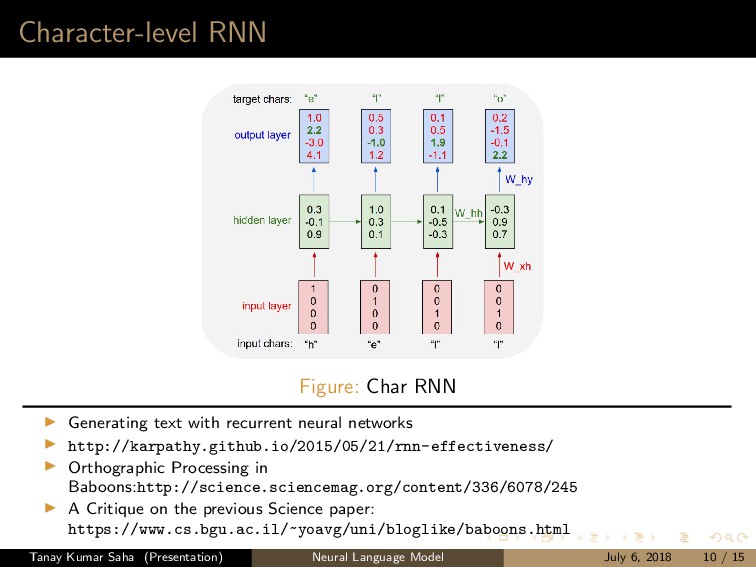
networks http://karpathy.github.io/2015/05/21/rnn-effectiveness/ Orthographic Processing in Baboons:http://science.sciencemag.org/content/336/6078/245 A Critique on the previous Science paper: https://www.cs.bgu.ac.il/~yoavg/uni/bloglike/baboons.html Tanay Kumar Saha (Presentation) Neural Language Model July 6, 2018 10 / 15
string A key advantage of using subword is that out-of-vocabulary words, such as misspelled words, can still be represented at test time by their subwords representations This make text classifiers much more robust, especially for problems with small training sets, or for morphologically rich languages As an example, when using subwords of length 3, the word skiing is represented by: skiing ski kii iin ing Modeling Inflection and Word-Formation in SMT Unsupervised Morphology Induction Using Word Embeddings Enriching Word Vectors with Subword Information Bag of Tricks for Efficient Text Classification FastText.zip: Compressing text classification models Tanay Kumar Saha (Presentation) Neural Language Model July 6, 2018 11 / 15
the verb agreement between students and are in the sentence: ”The students who studied the hardest are getting the highest grades” since it uses RNN based model It explicitly captures morphological variation, allowing sharing of information between variants of the same word The language model seamlessly handles out of vocabulary items and their morphological variants Lecture on Morphology: http://www.cs.cmu.edu/~tbergkir/11711fa16/fa16_11711_lecture23.pdf Tanay Kumar Saha (Presentation) Neural Language Model July 6, 2018 12 / 15
word in a sentence, wi given the preceding words is computed by using an RNN to encode the context followed by a softmax. p(wi |w<i ) = p(wi |hi = ΦRNN(w1, w2, . . . wi−1)) = softmax(Whi + b) In this work, the authors use a mixture model over M (M=3: 1. Word generator, 2. character sequence generator, 3. Morpheme sequence generator) different models for generating words in place of the single softmax over words p(wi |hi ) = M mi =1 p(wi , mi |hi ) = M mi =1 p(mi |hi )p(wi |hi , mi ) Tanay Kumar Saha (Presentation) Neural Language Model July 6, 2018 13 / 15
word at the word, morpheme, or character-level, and marginalize over these three options to find the total probability of a word Tanay Kumar Saha (Presentation) Neural Language Model July 6, 2018 14 / 15
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}