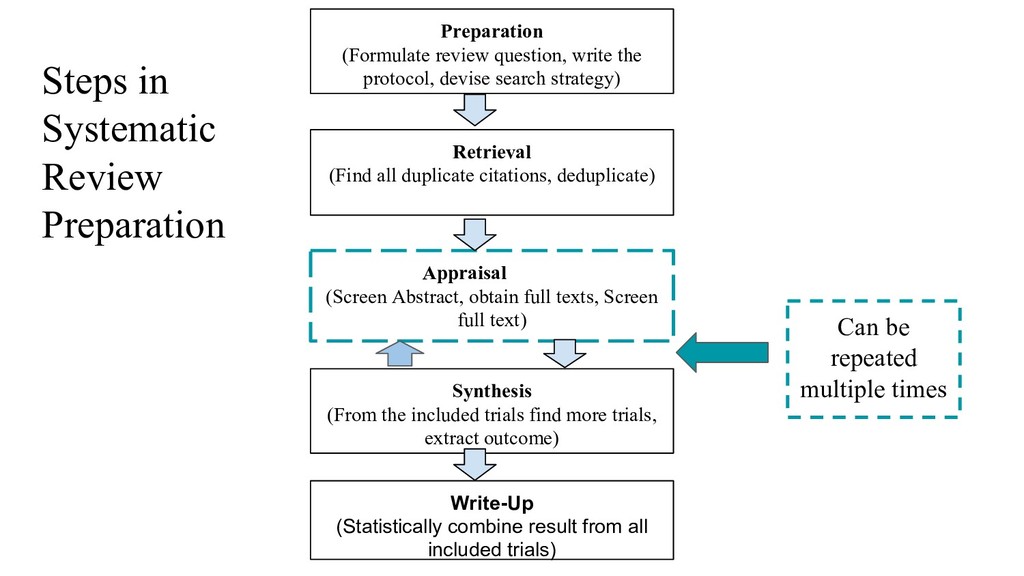
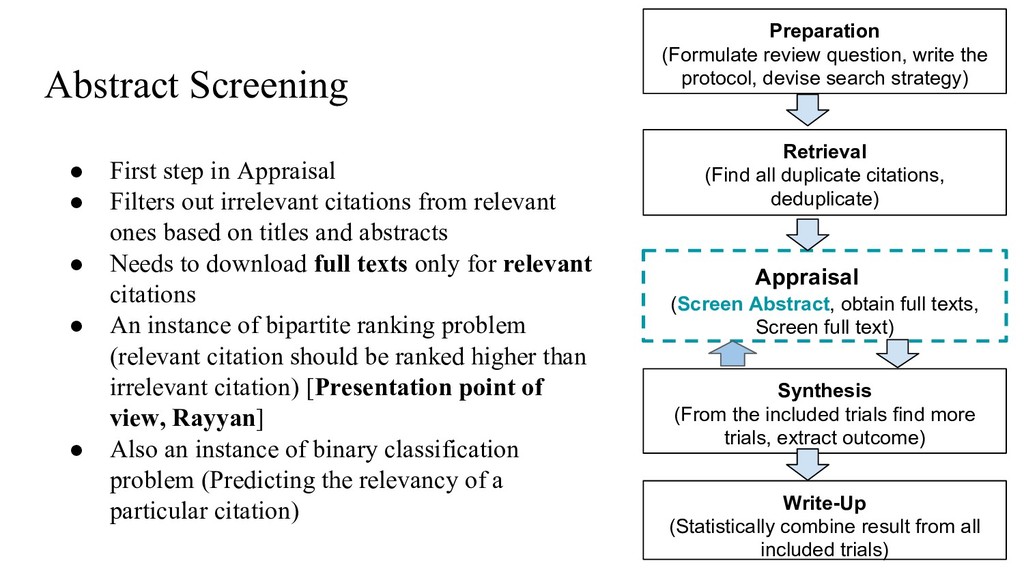
irrelevant citations from relevant ones based on titles and abstracts • Needs to download full texts only for relevant citations • An instance of bipartite ranking problem (relevant citation should be ranked higher than irrelevant citation) [Presentation point of view, Rayyan] • Also an instance of binary classification problem (Predicting the relevancy of a particular citation) Preparation (Formulate review question, write the protocol, devise search strategy) Retrieval (Find all duplicate citations, deduplicate) Appraisal (Screen Abstract, obtain full texts, Screen full text) Synthesis (From the included trials find more trials, extract outcome) Write-Up (Statistically combine result from all included trials)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}