AVG(num_trips) AS avg_trips_per_year, payment_type FROM ( SELECT EXTRACT(YEAR FROM start_ts) AS year, payment_type, COUNT(*) AS num_trips FROM taxi_trips GROUP BY year, payment_type ) GROUP BY payment_type Pipe SQL Syntax FROM taxi_trips |> EXTEND EXTRACT(YEAR FROM start_ts) AS year |> AGGREGATE COUNT(*) AS num_trips GROUP BY year, payment_type |> AGGREGATE AVG(num_trips) AS avg_trips_per_year GROUP BY payment_type
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
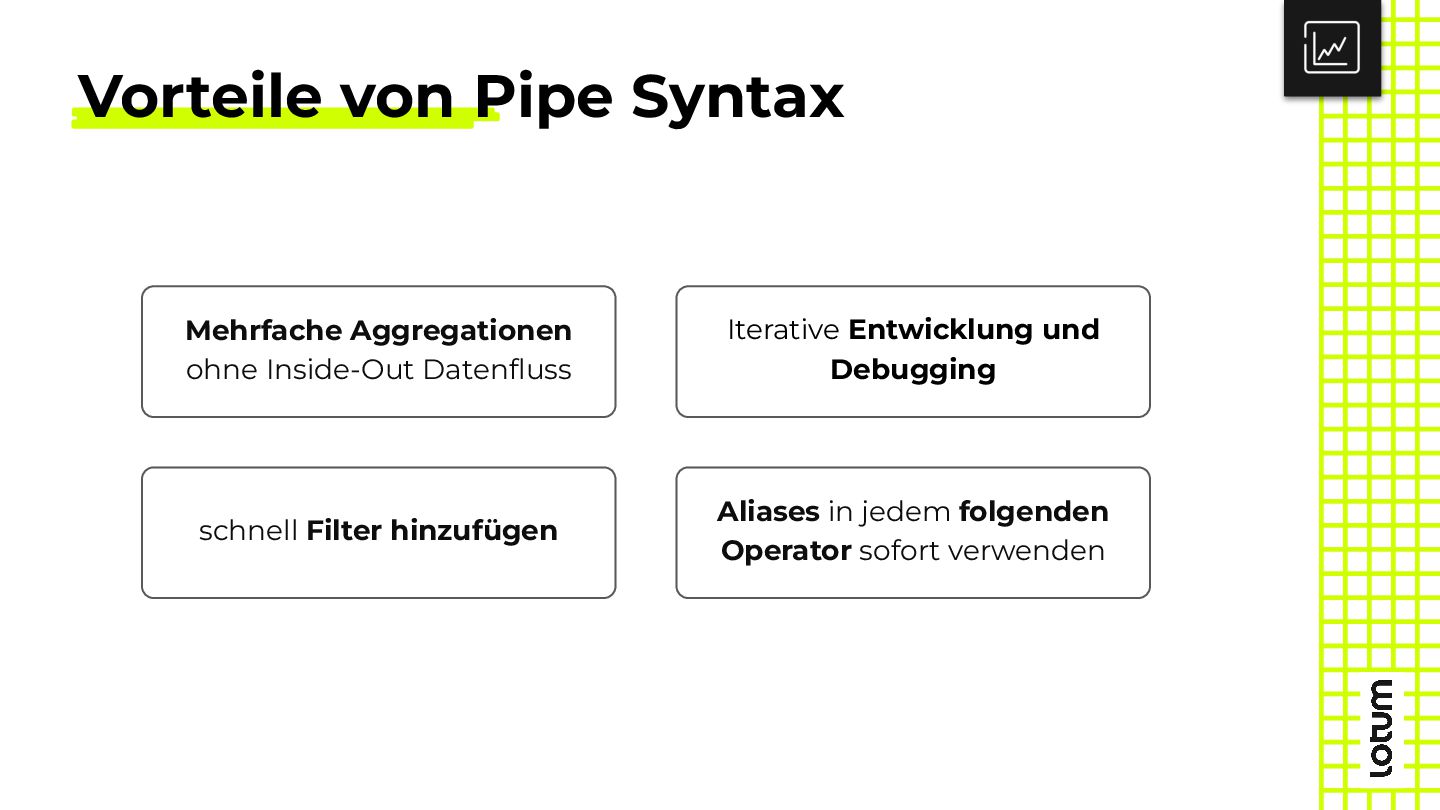{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
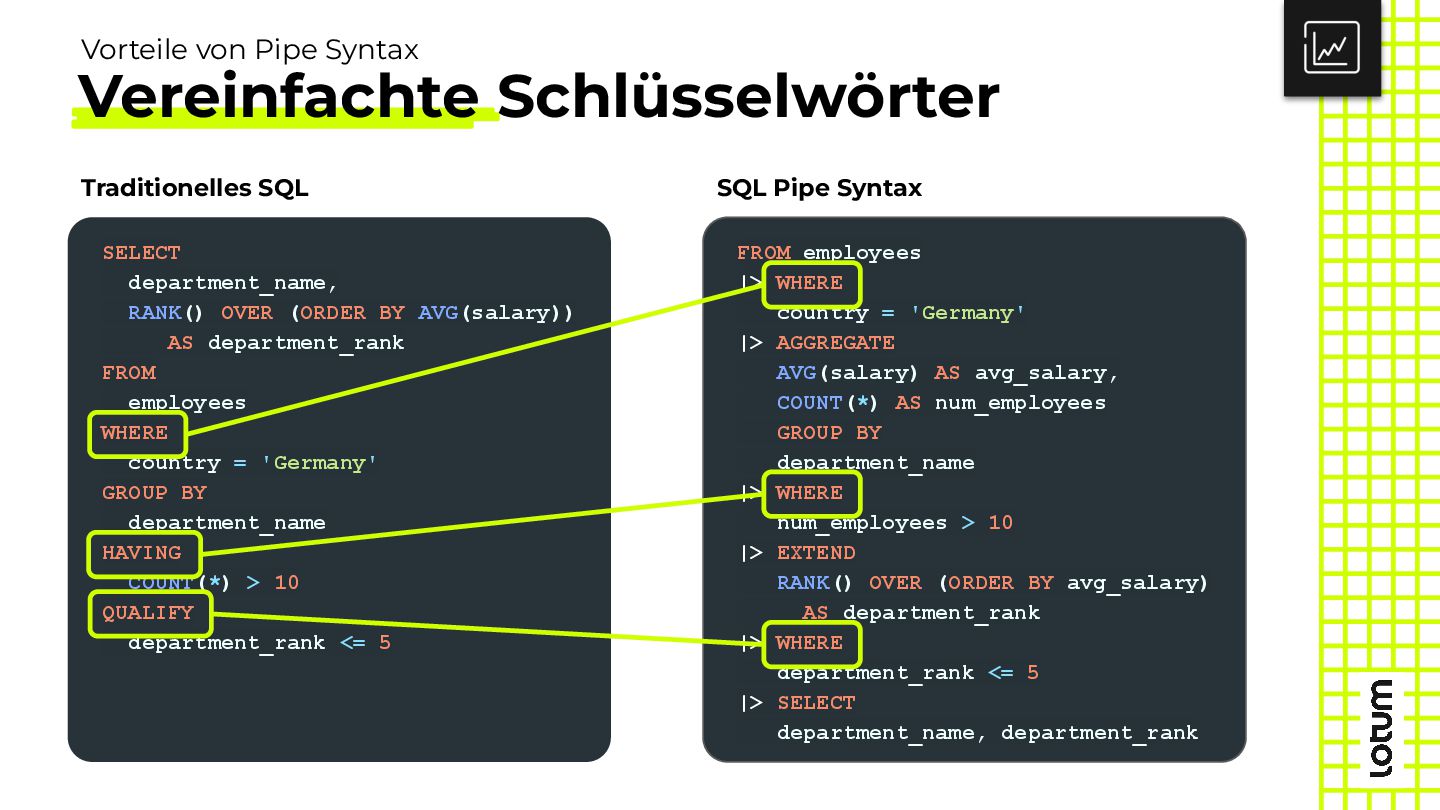{kind=link}
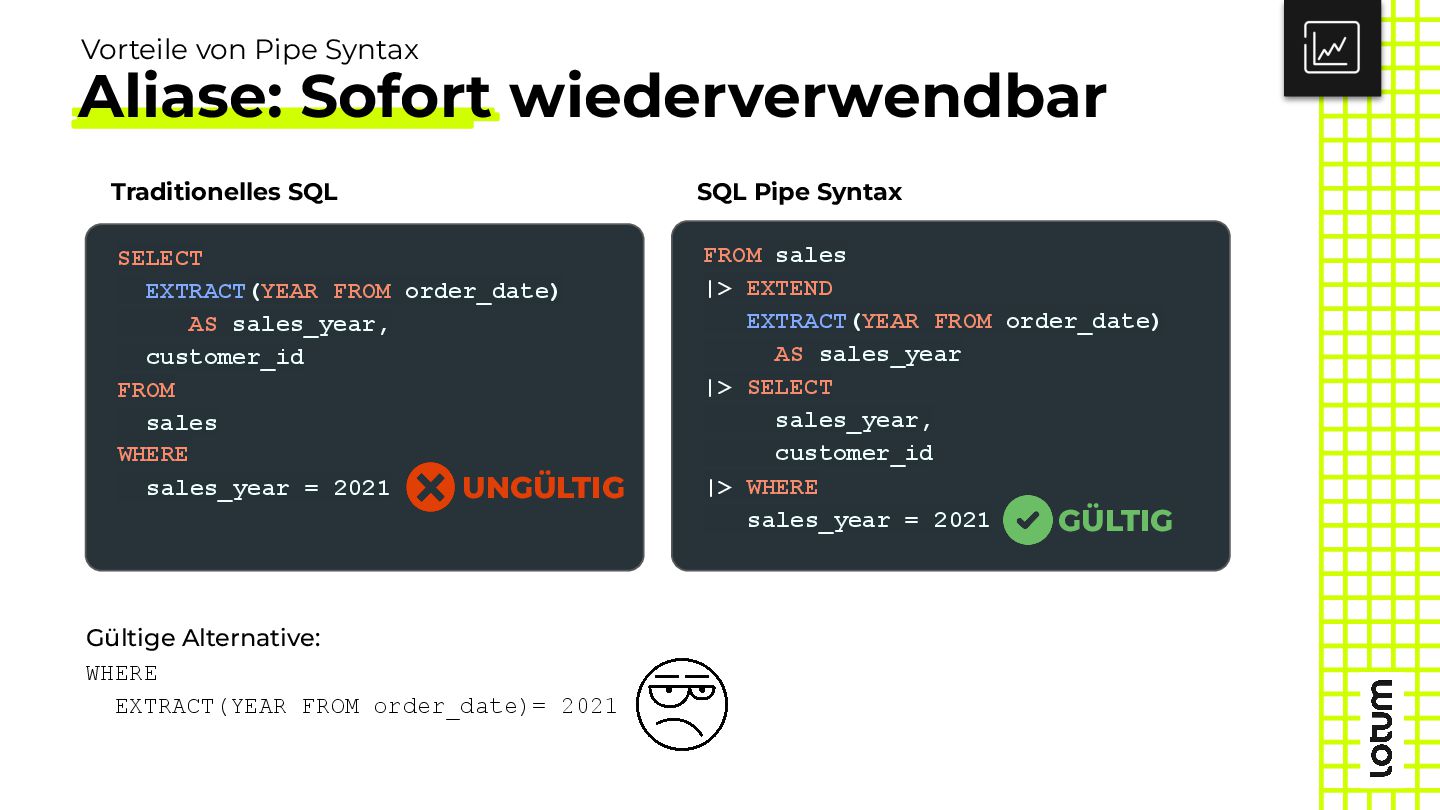{kind=link}
{kind=link}
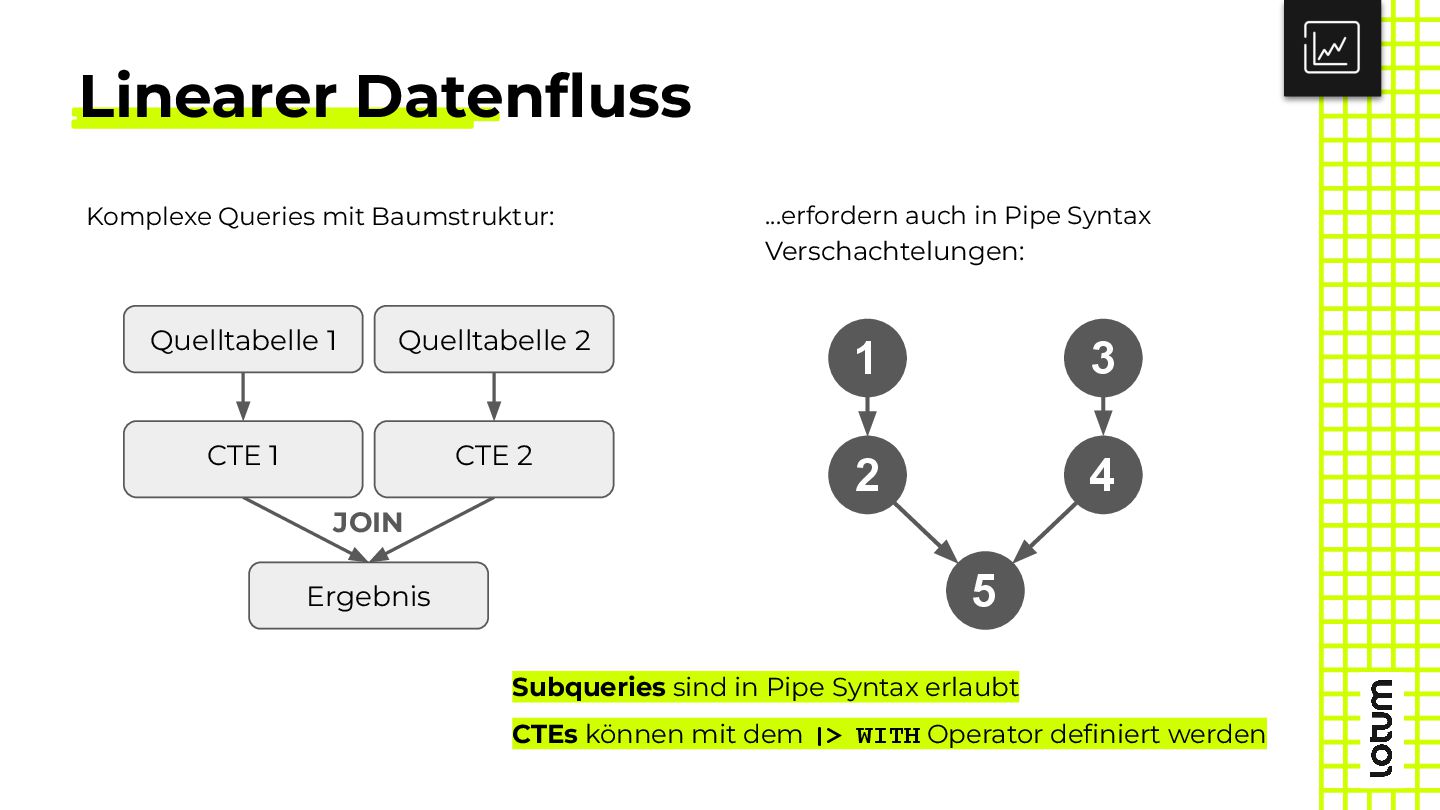{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}