(1803.07246) • assume factorized policy: π(a|s) = π1(a1|s)…πd(ad|s) • “very common” for action space {a = (a1, …, ad)} • e.g. Gaussian with diagonal covariance • baseline b(s, a) = b1 + … + bd • use all the other dims' values a−i = (a1, …, ai−1, ai+1 …, ad) in baseline for i-th dim, because unbiased:
(1803.07246) • [Appendix A] optimal action-independent baseline b*(s) • weighted mean of Q(s, a) • but not V(s) = Ea~π[Q(s, a)] • depends on parameterization of policy
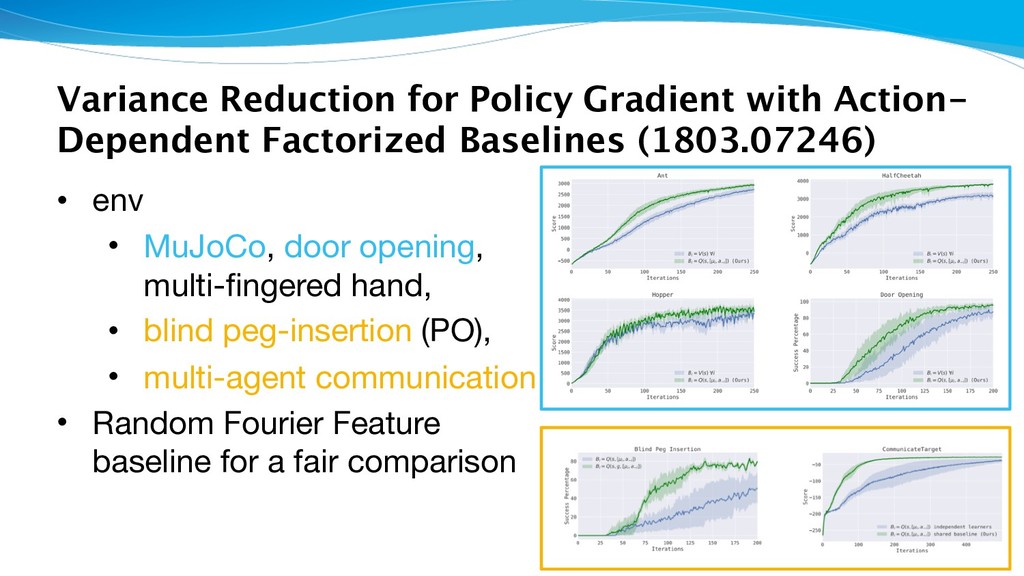
(1803.07246) • env • MuJoCo, door opening, multi-fingered hand, • blind peg-insertion (PO), • multi-agent communication • Random Fourier Feature baseline for a fair comparison
• assume re-parameterizable policy • baseline φ(s, a): any dependency in action a • cf. ∇a,aφ(s, a) = 0 in Q-Prop • Gaussian policy. θ1: mean param., θℓ: variance param.
action space • method • learn guide actor (for each state) using second-order • learn parameterized actor πθ based on guide actor • assume Gaussian policy • Authors recommend state-independent covariance
• “surrogate” TR: • where • automatic tune λ to aim • KL(π*||π ~ ) is expressed analytically • with expectation over trajectory of π ~ • last 100 episodes to approx.
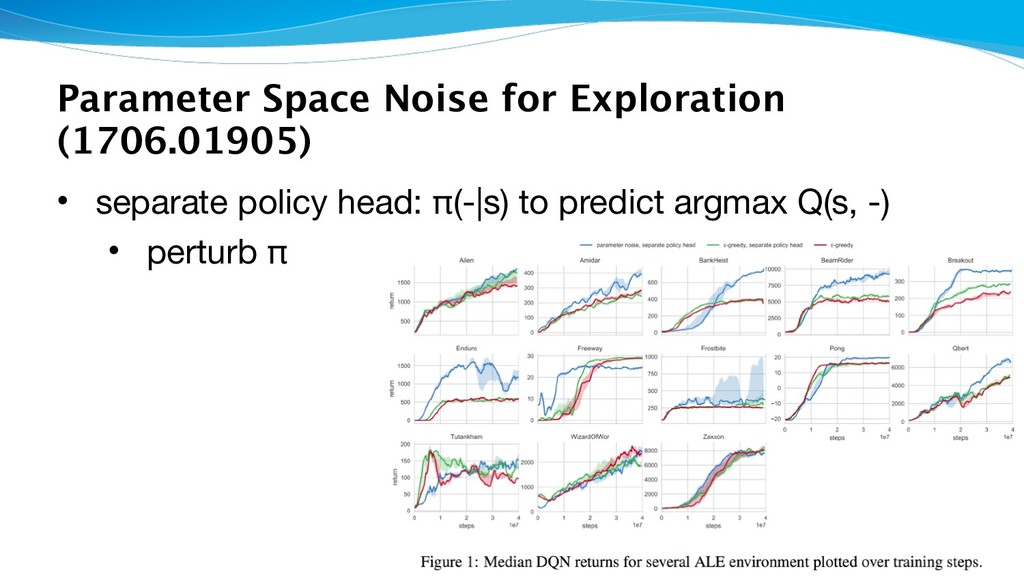
exploration, we sample from a set of policies by applying additive Gaussian noise to the parameter vector of the current policy” • sample per episode • adaptive noise scaling • re-param'n trick for on-policy
“This ensures consistency in actions” • experiments • DQN/ALE, DDPG/MuJoCo, TRPO/MuJoCo • to test sample efficiency • toy discrete env • continuous control env with sparse rewards
x: state pseudo-count N ^ n(x) and pseudo-count total n ^ • from density model ρ(x) • ρ'(x): density after observing new x • experiments: ALE • improved much in Montezuma's Revenge
E(s, a) = 1. Update: • “The logarithm of E-Values can be thought of as a generalization of visit counters” • choose argmax((policy using Q)/counter) • experiment • grid bridge, Freeway (Atari) ※ʰυʔϥͱ͍ͬ͠ΐʹେݥʱ
• “A nonstationary environment can be seen as a sequence of stationary tasks, and hence we propose to tackle it as a multi-task learning problem” • method • meta-learning at training time • adaptation at execution time
meta-loss on a pair of consecutive tasks • train with (K trajectories of) Ti ; test with Ti+1 • start with θ (not φi) “due to stability considerations” Continuous Adaptation via Meta-Learning in Nonstationary and Competitive Environments (1710.03641)
adaptation update from θ • available: trajectory of Ti-1 using φi-1 Continuous Adaptation via Meta-Learning in Nonstationary and Competitive Environments (1710.03641)
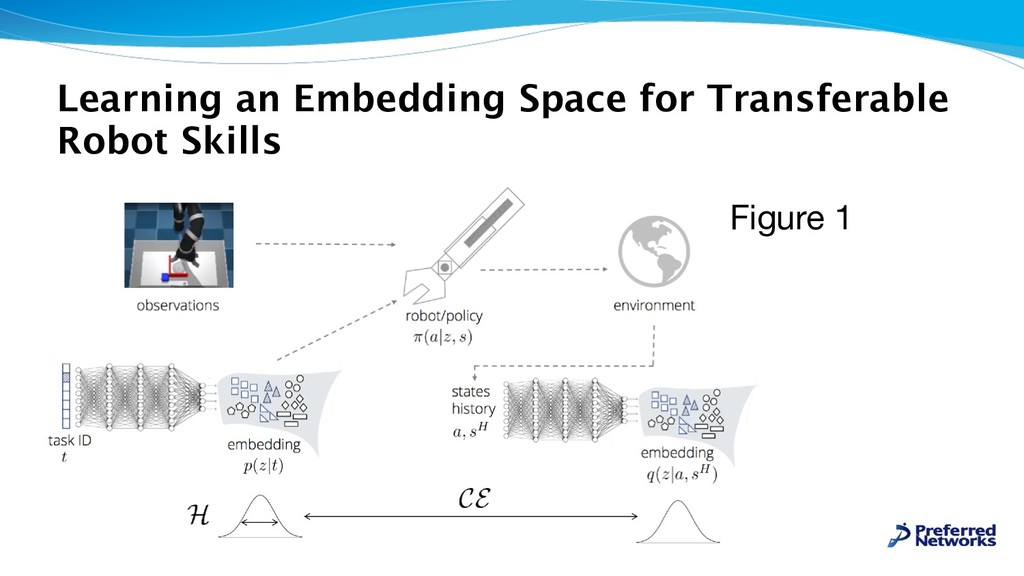
Experimental Results “Our experiments aim to the following questions:” 1. Can our method learn versatile skills? 2. Can it determine how many distinct skills are necessary to accomplish a set of tasks? 3. Can we use the learned skill embedding for control in an unseen scenario? 4. Is it important for the skills to be versatile to use their embedding for control? 5. Is it more efficient to use the learned embedding rather than to learn to solve a task from scratch?
{kind=link}
{kind=link}
![Notation • π: policy ํࡦ • V(s) ~ E[R|s0=s]: state](https://files.speakerdeck.com/presentations/6965eddf3a154dc4af765f6055b33d35/slide_2.jpg){kind=link}
![Q-learning, policy gradient method • V(s) = Ea~π(-|s)[Q(s, a)] •](https://files.speakerdeck.com/presentations/6965eddf3a154dc4af765f6055b33d35/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}