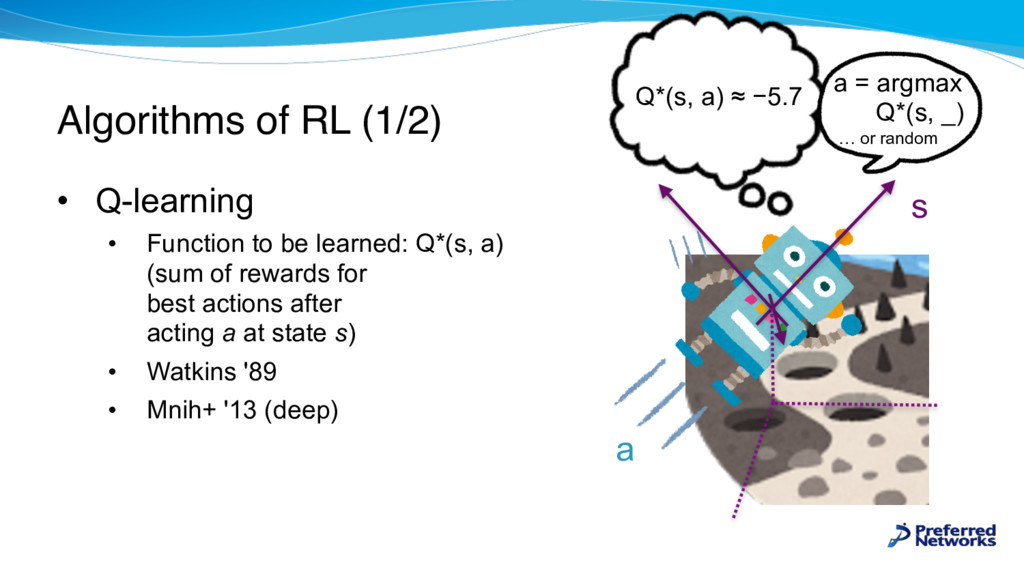
learned: Q*(s, a) (sum of rewards for best actions after acting a at state s) • Watkins '89 • Mnih+ '13 (deep) s a Q*(s, a) ≈ −5.7 a = argmax Q*(s, _) … or random
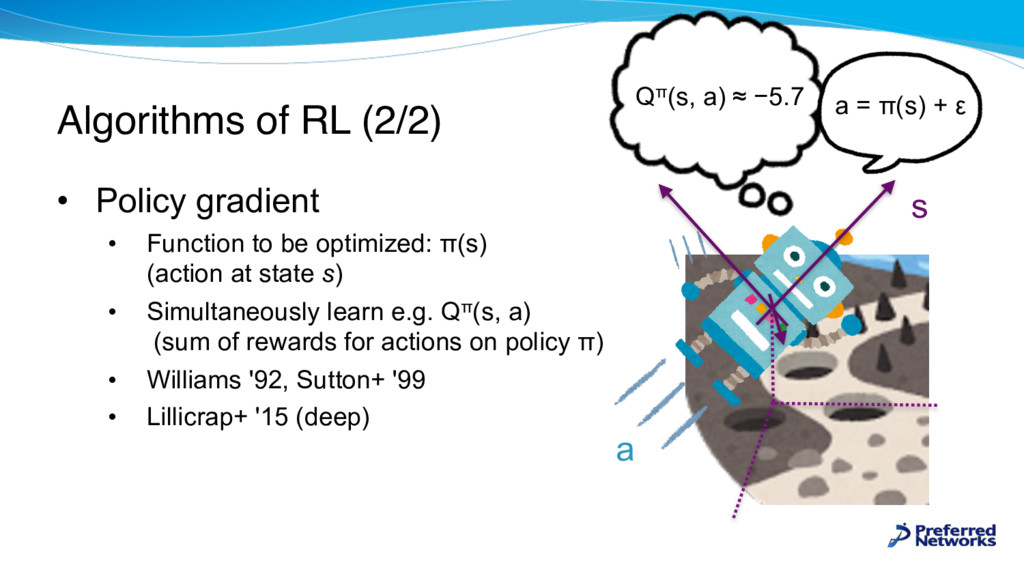
be optimized: π(s) (action at state s) • Simultaneously learn e.g. Qπ(s, a) (sum of rewards for actions on policy π) • Williams '92, Sutton+ '99 • Lillicrap+ '15 (deep) s a Qπ(s, a) ≈ −5.7 a = π(s) + ε
states; outputs = Q-values for each action • Use models available at ChainerRL model = chainerrl.q_functions.FCStateQFunctionWithDiscreteAction( dim_obs, n_action, n_hidden_channels, n_hidden_layers) • Convert your Chain for ChainerRL model = chainerrl.q_functions.SingleModelStateQFunctionWithDiscreteAction( MyChain(dim_obs, n_action)) model s Q(s, a1) Q(s, a2) … …
model = chainerrl.q_functions.FCQuadraticStateQFunction( dim_obs, dim_action, n_hidden_channels, n_hidden_layers, action_space) • (BTW, explorer with Ornstein-Uhlenbeck process is better, as it's used in DDPG) explorer = chainerrl.explorers.AdditiveOU(...)
a minibatch by sampling from (saved) memories • One can choose size of buffer, and algorithm of sampling rbuf = chainerrl.replay_buffer.ReplayBuffer(5 * 10**5) rbuf = chainerrl.replay_buffer.EpisodicReplayBuffer(10**4) rbuf = chainerrl.replay_buffer.PrioritizedReplayBuffer(5 * 10**5)
just change the line agent = chainerrl.agents.DQN(...) to the line agent = chainerrl.agents.DoubleDQN(...) • Replay buffer & explorer can be unchanged for algorithms (e.g. DDPG) with different types of models
evaluate with test environment for some interval of iterations (to draw learning curves) • to save models automatically • This is not Trainer in Chainer :( • TBD
algorithms (including newest ones) are implemented • Many parts of algorithms are reusable • Give me feedbacks • Features/algorithms to be implemented • Interfaces github.com/chainer/chainerrl
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}