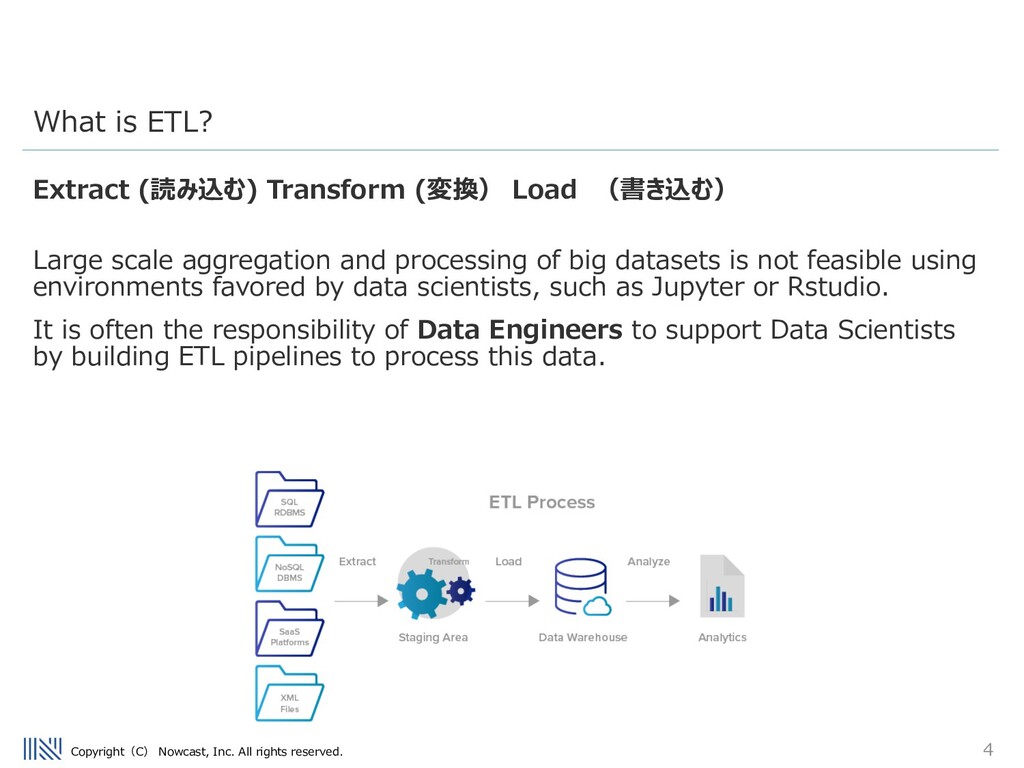
(変換) Load (書き込む) Large scale aggregation and processing of big datasets is not feasible using environments favored by data scientists, such as Jupyter or Rstudio. It is often the responsibility of Data Engineers to support Data Scientists by building ETL pipelines to process this data. What is ETL?
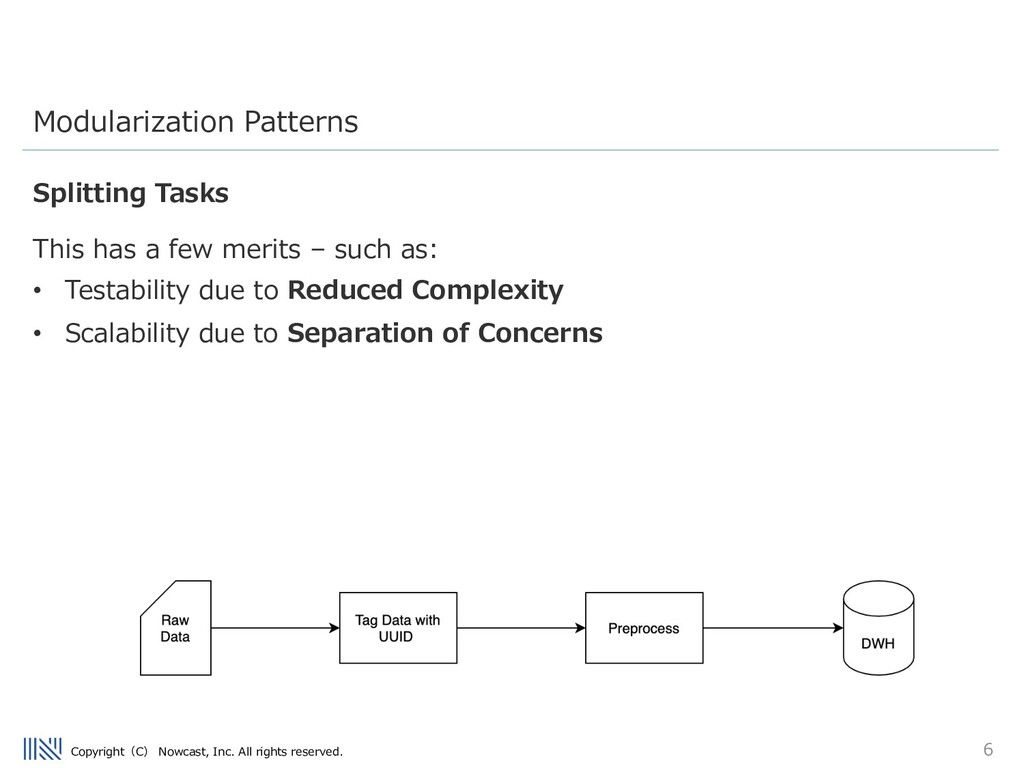
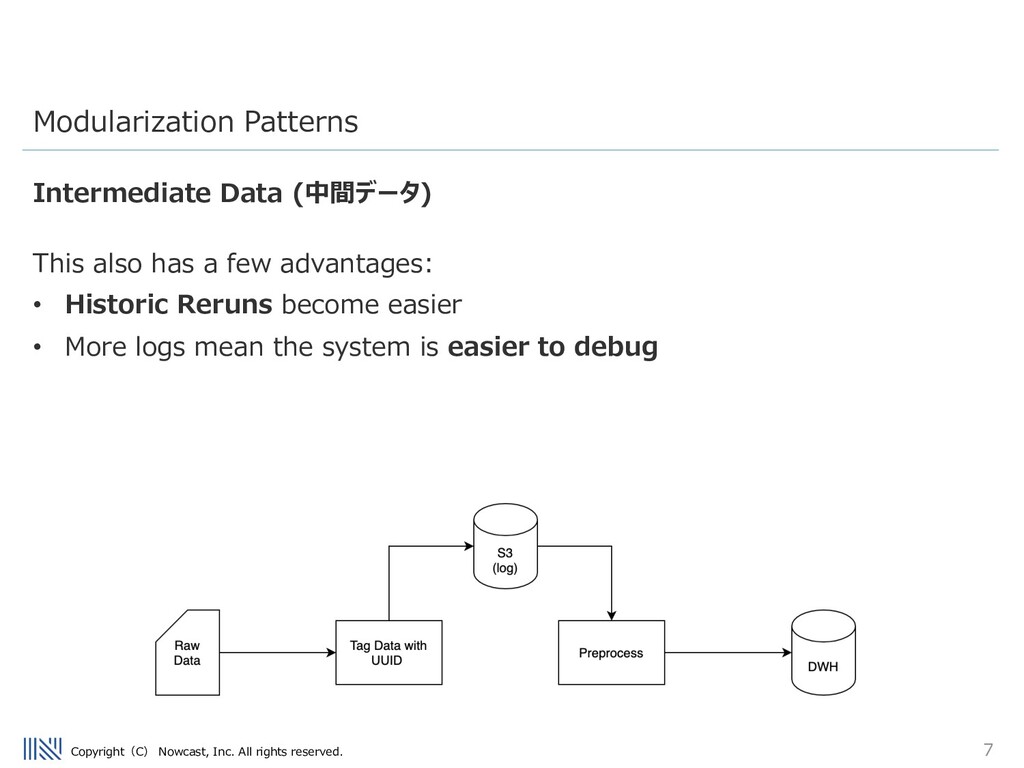
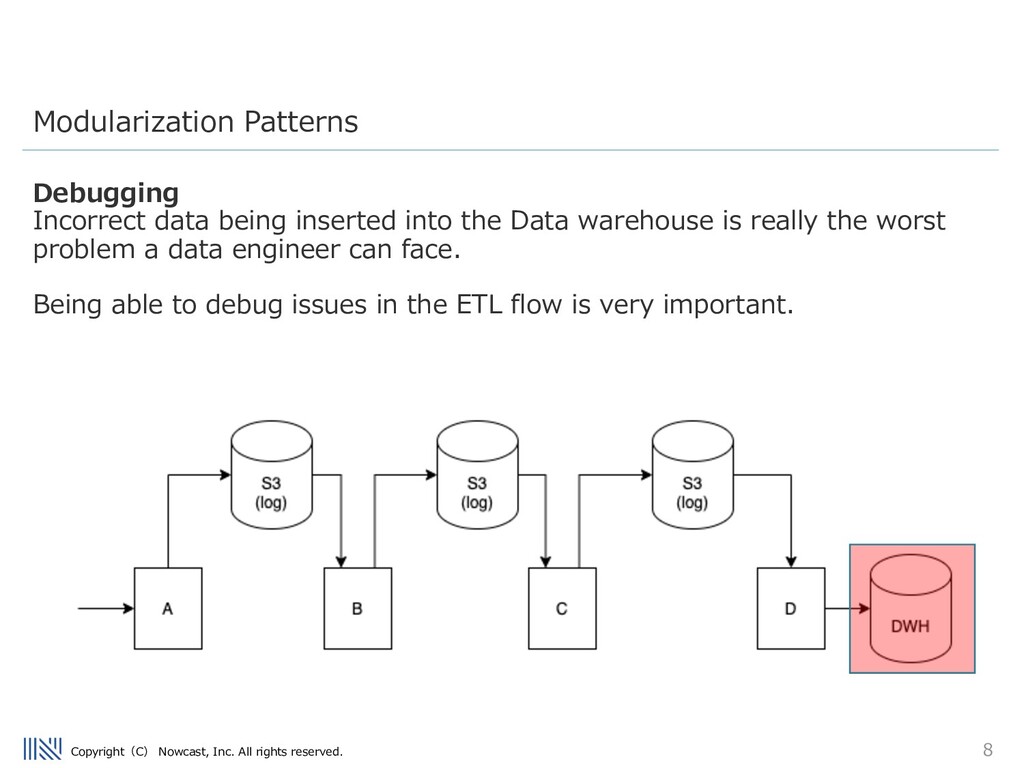
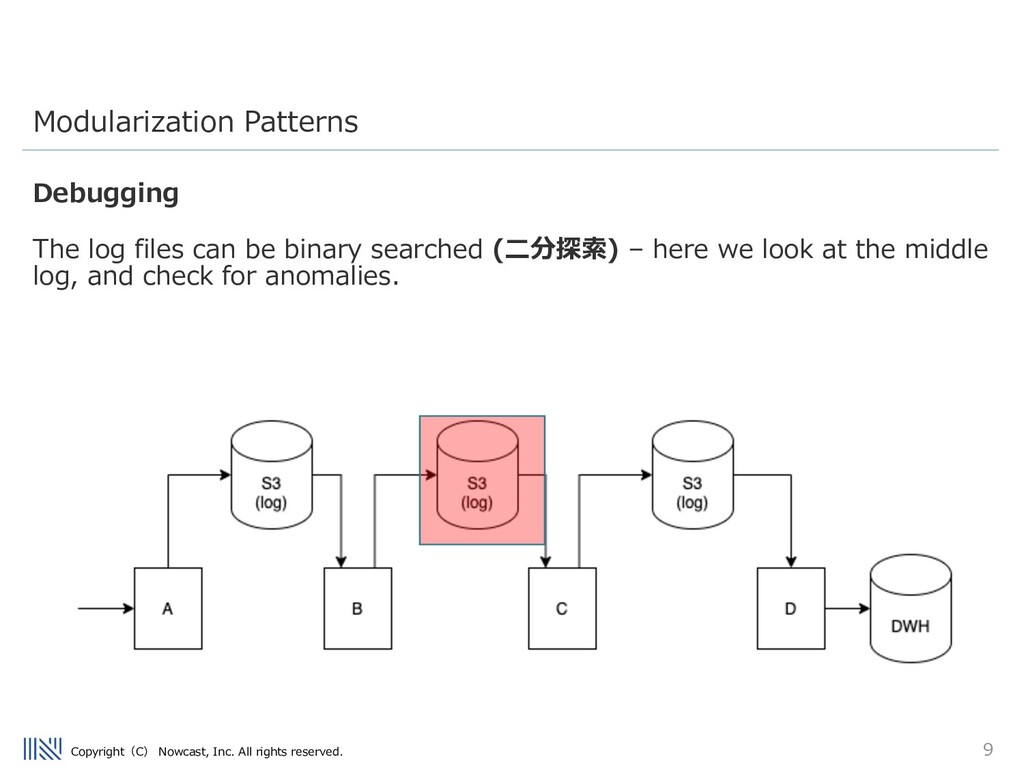
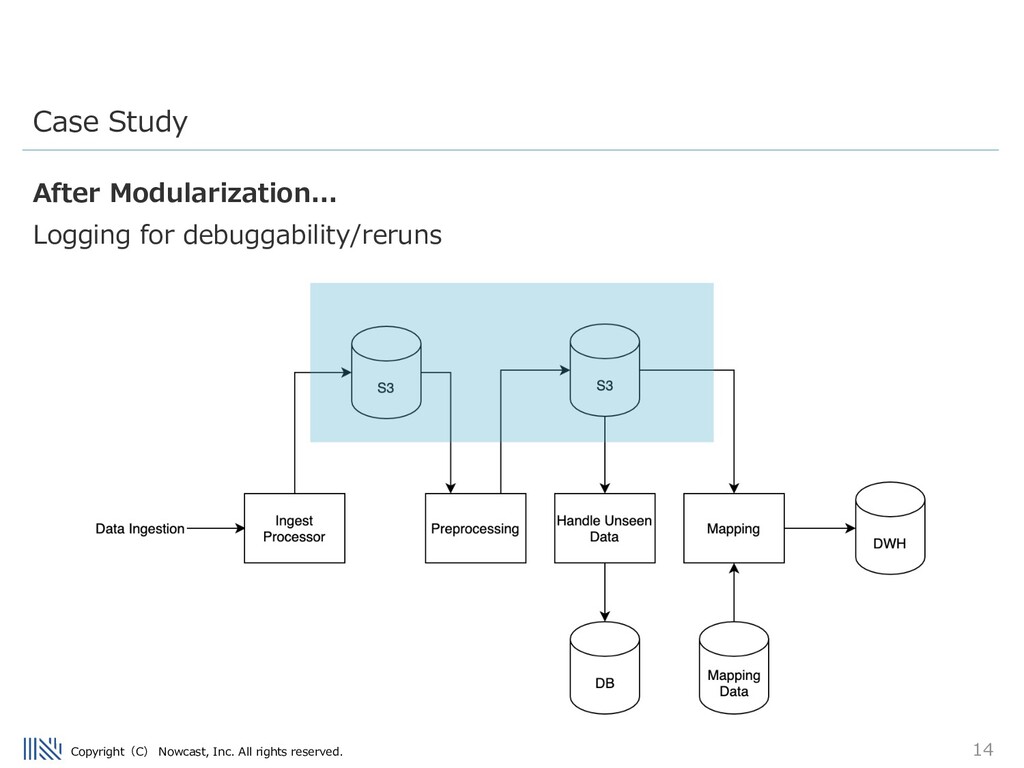
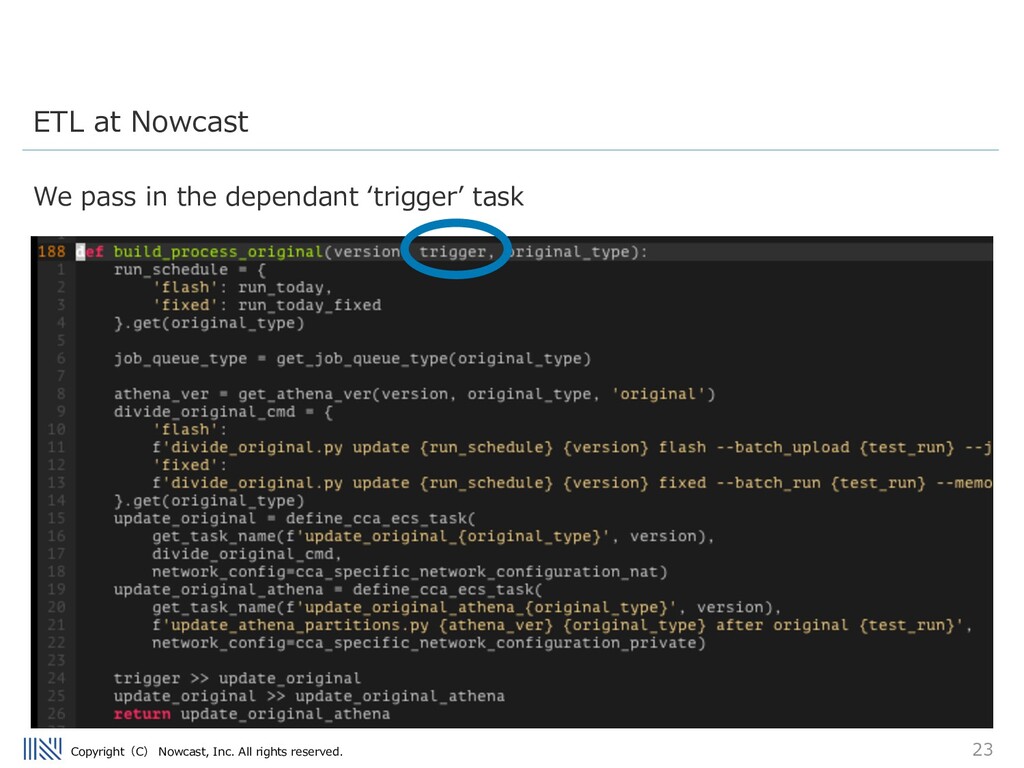
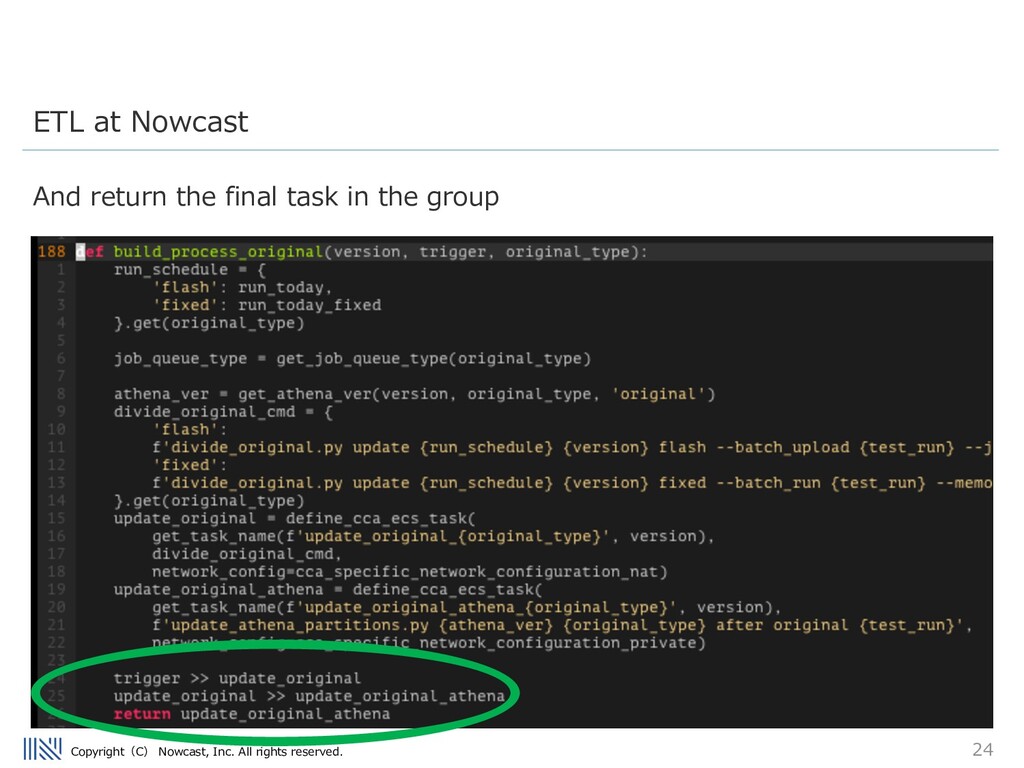
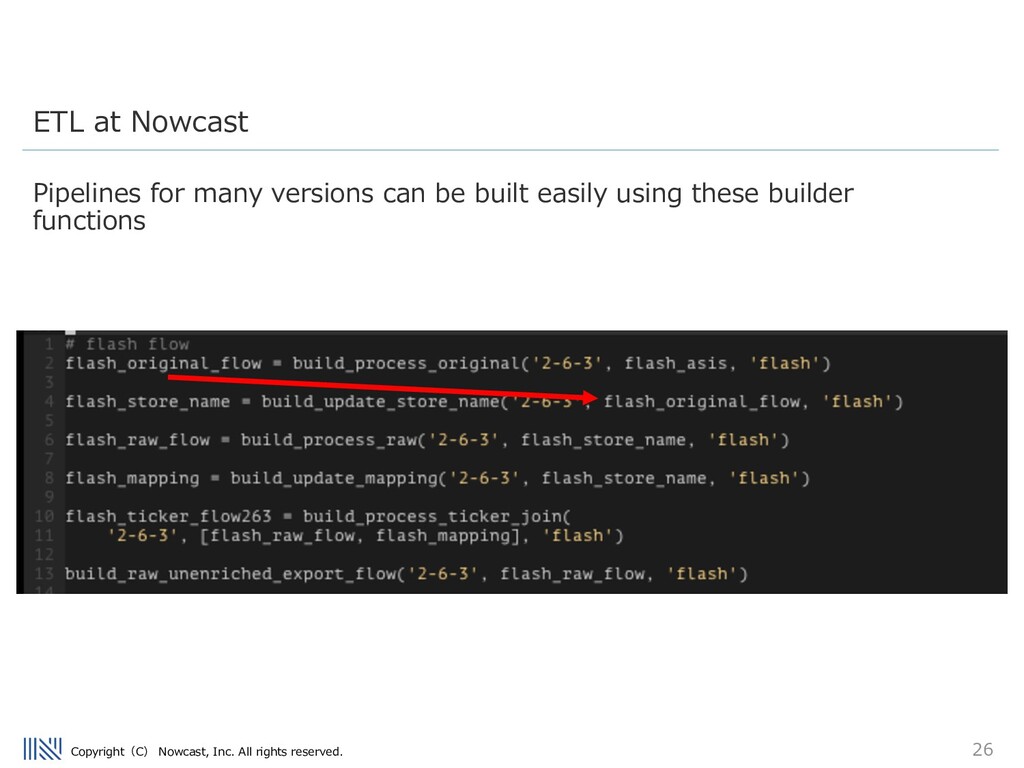
being inserted into the Data warehouse is really the worst problem a data engineer can face. Being able to debug issues in the ETL flow is very important. Modularization Patterns
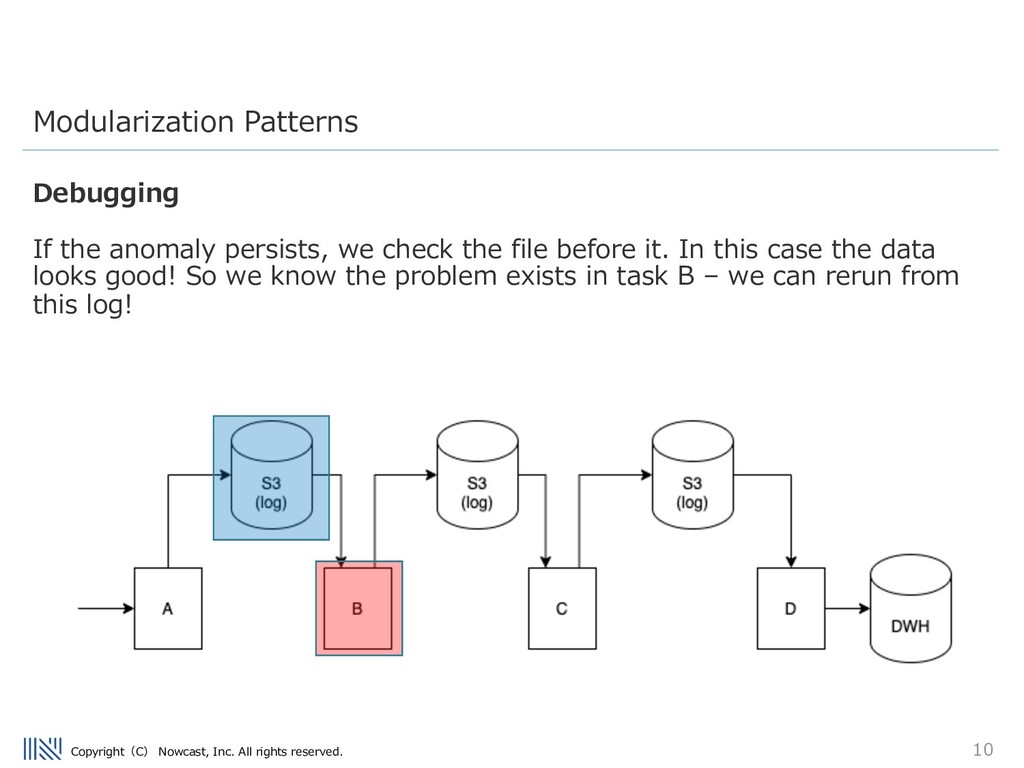
anomaly persists, we check the file before it. In this case the data looks good! So we know the problem exists in task B – we can rerun from this log! Modularization Patterns
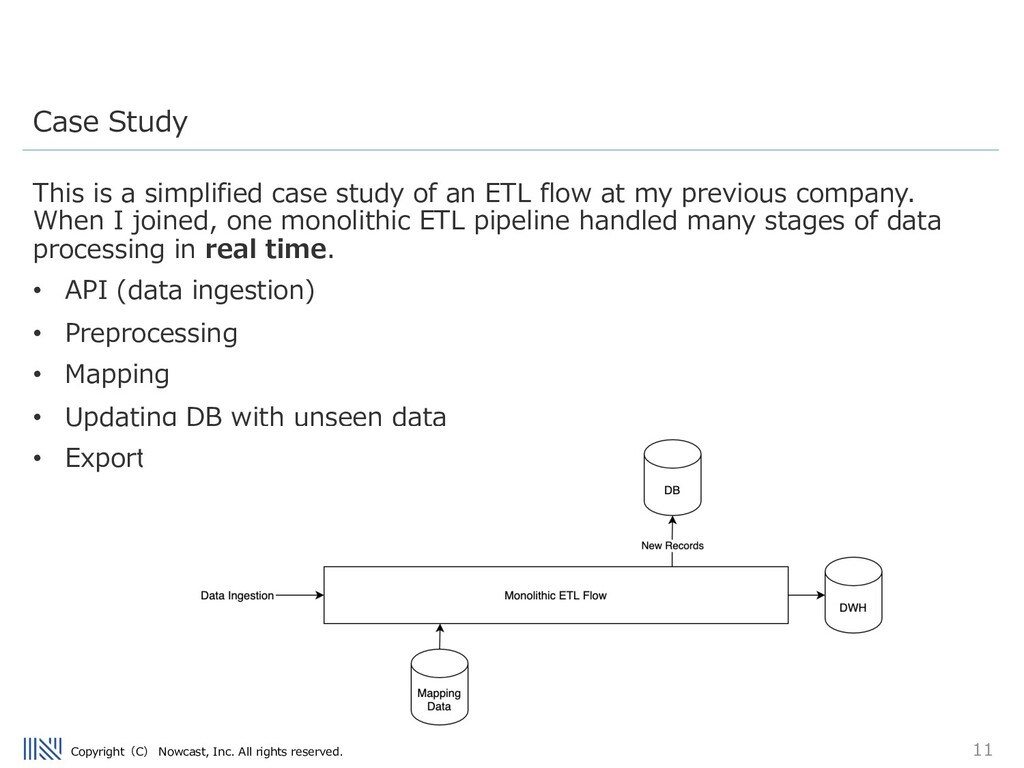
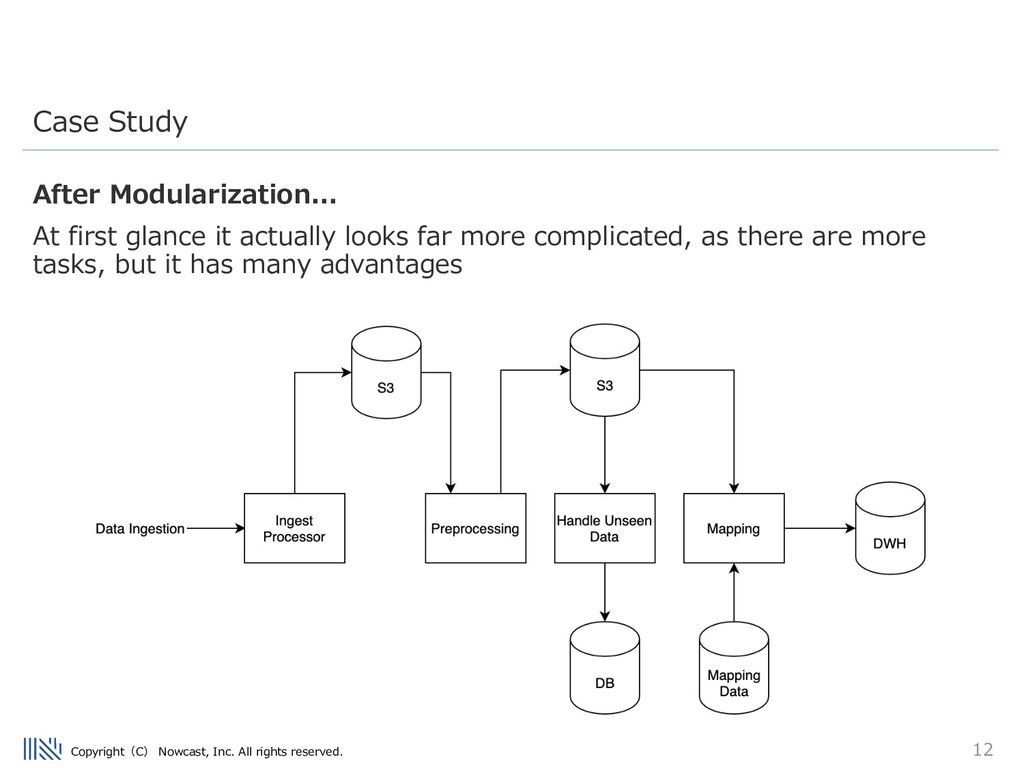
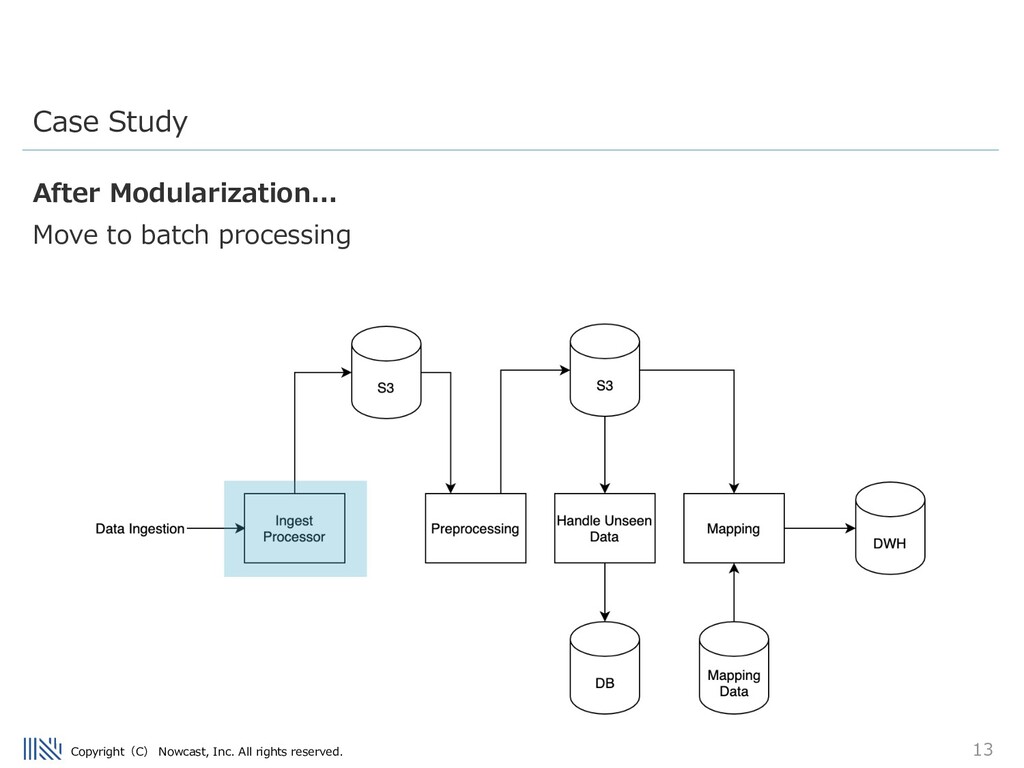
simplified case study of an ETL flow at my previous company. When I joined, one monolithic ETL pipeline handled many stages of data processing in real time. • API (data ingestion) • Preprocessing • Mapping • Updating DB with unseen data • Export to data warehouse Case Study
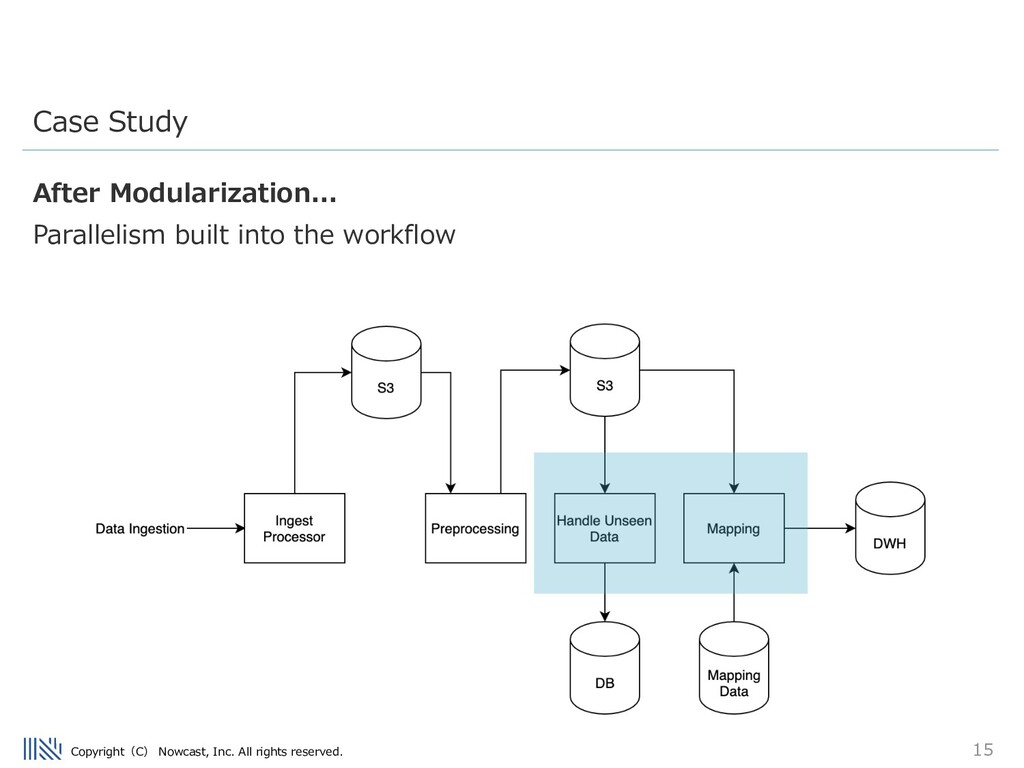
As the number of tasks increases, we need to control the flow. How does task B know when task A has finished? How does it know what data to process? There are a number of different ways to accomplish this – we will look at one in particular. Problems
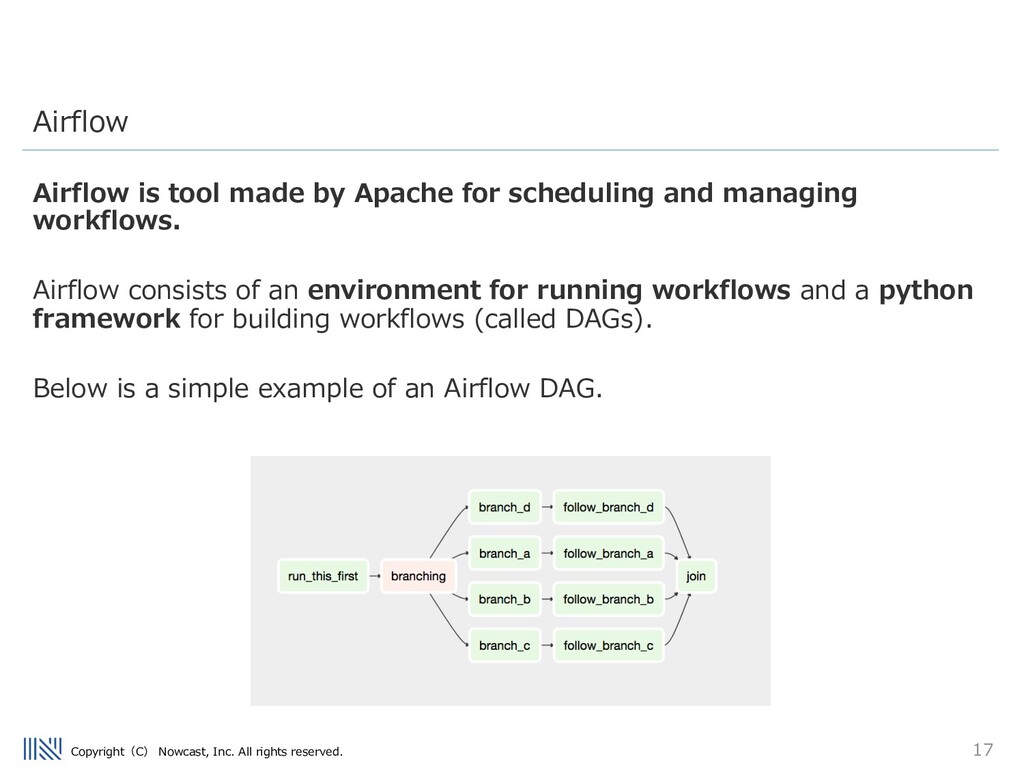
made by Apache for scheduling and managing workflows. Airflow consists of an environment for running workflows and a python framework for building workflows (called DAGs). Below is a simple example of an Airflow DAG. Airflow
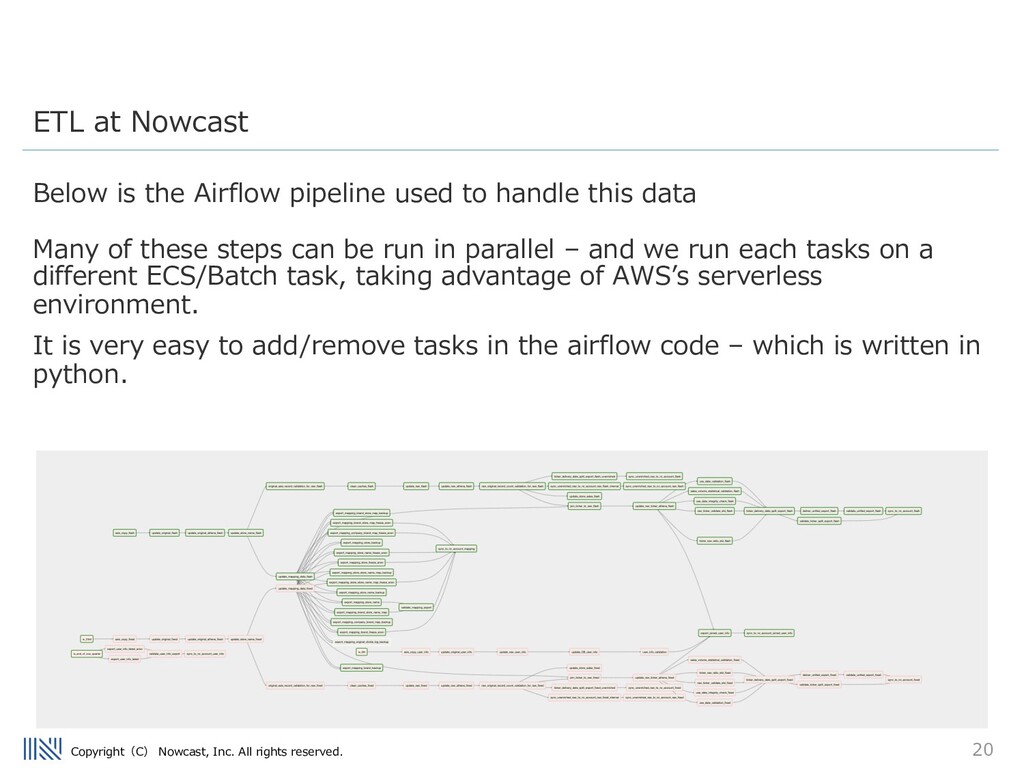
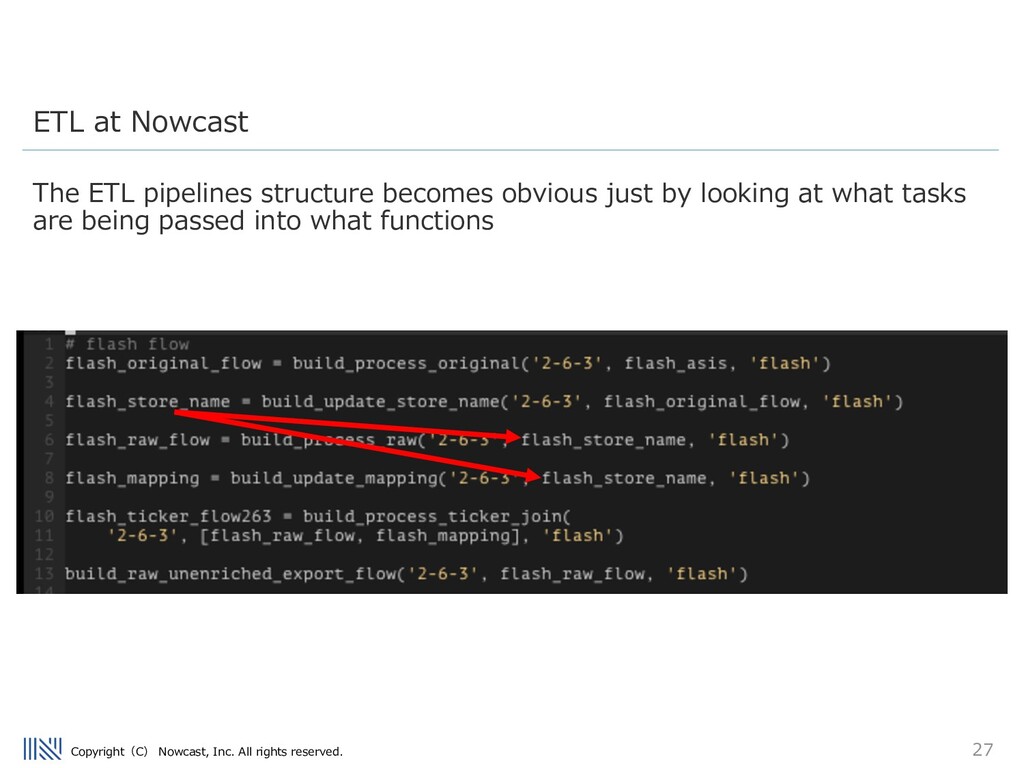
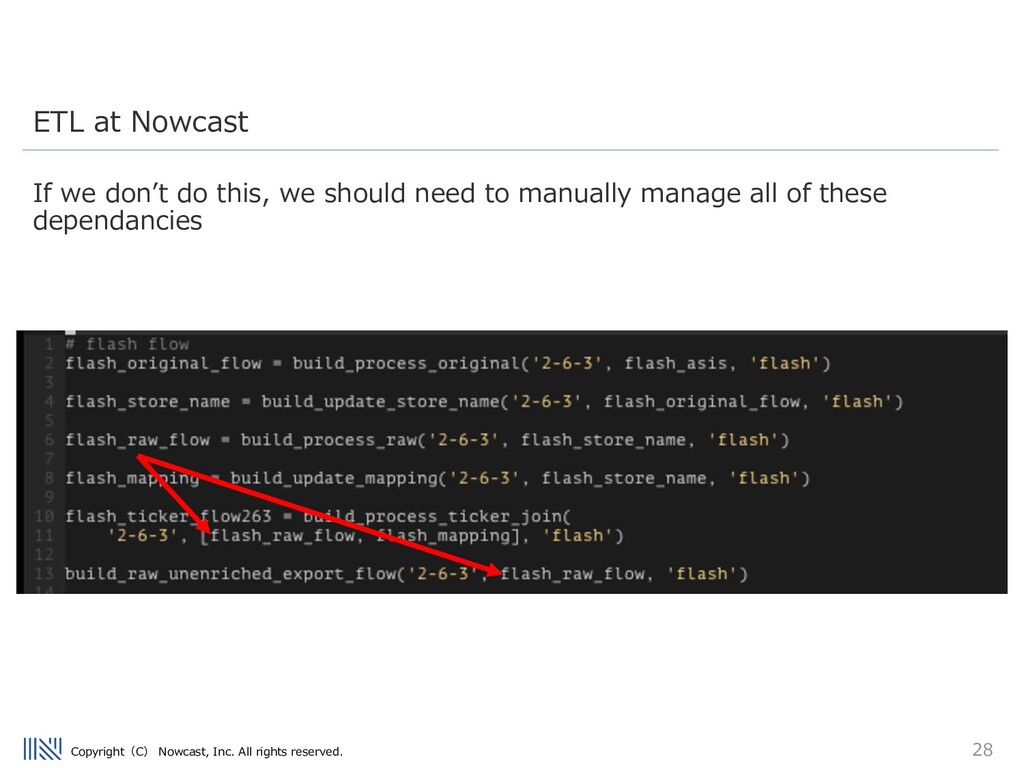
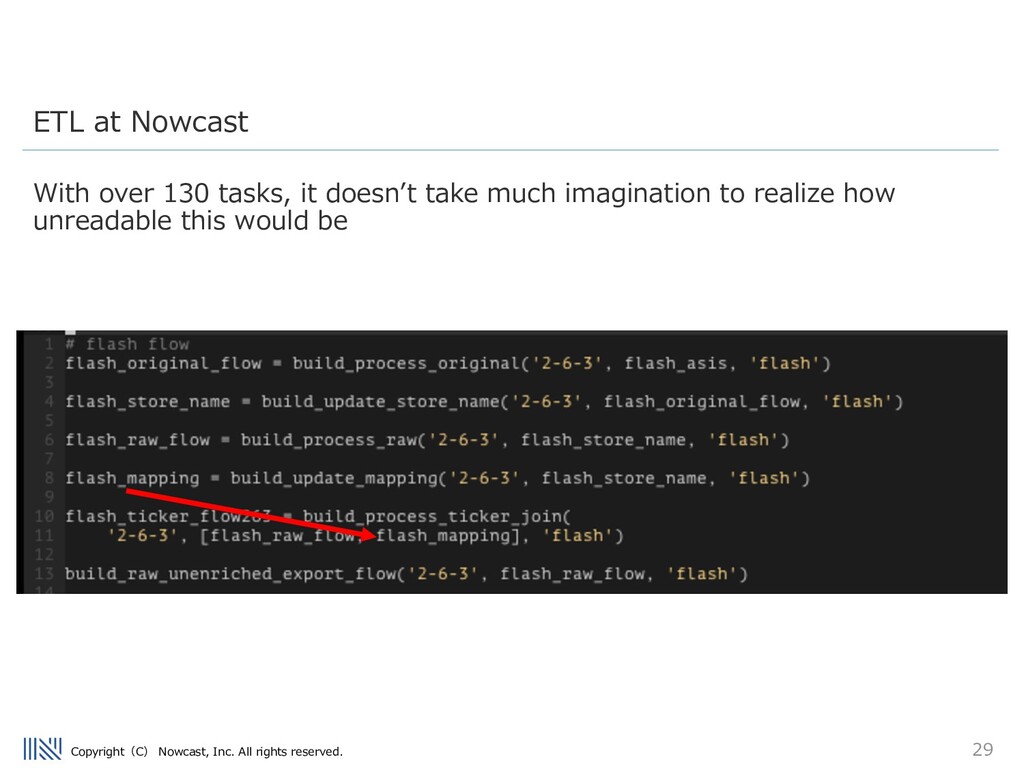
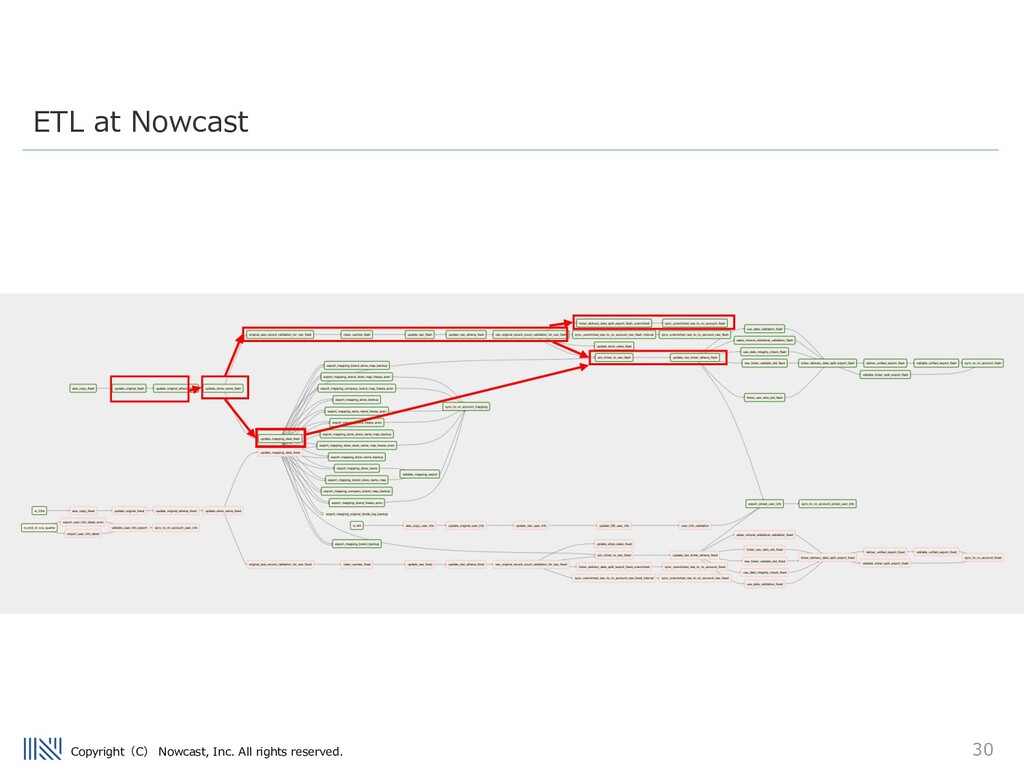
take these modular approaches to ETL design. We have many different consumer transaction datasets to process... Airflow manages many ETL pipelines that perform tasks including the preprocessing of our data, and delivery of our data to our clients. Stats: - 12 DAGs (and growing) - Longest Uptime without failure 287 days - Largest DAG: ~130 tasks running daily ETL at Nowcast
nowcast processes millions of rows of consumer transaction data on a daily basis. The pipeline contains many different steps, including: - UUID tagging - joining transaction to security codes - inserting newly seen data to an internal DB - anonymization - validation of data - loading mapped transaction data into internal Data Warehouse ETL at Nowcast
Airflow pipeline used to handle this data Many of these steps can be run in parallel – and we run each tasks on a different ECS/Batch task, taking advantage of AWSʼs serverless environment. It is very easy to add/remove tasks in the airflow code – which is written in python. ETL at Nowcast
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}