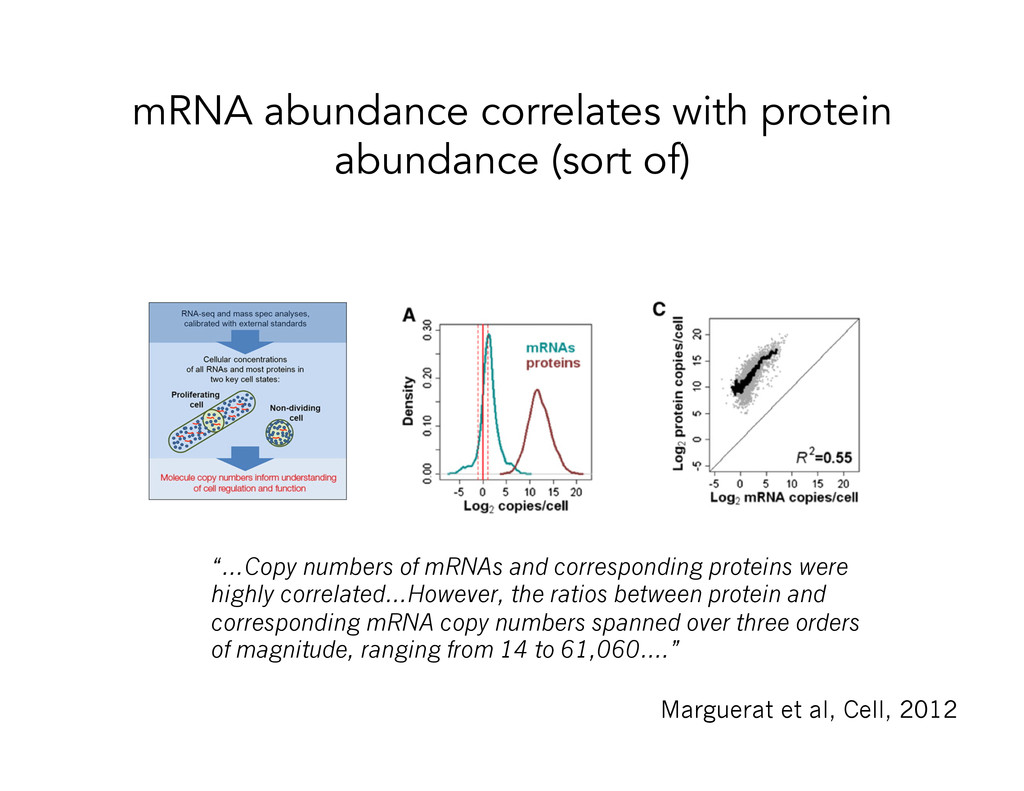
al, Cell, 2012 “…Copy numbers of mRNAs and corresponding proteins were highly correlated…However, the ratios between protein and corresponding mRNA copy numbers spanned over three orders of magnitude, ranging from 14 to 61,060….”
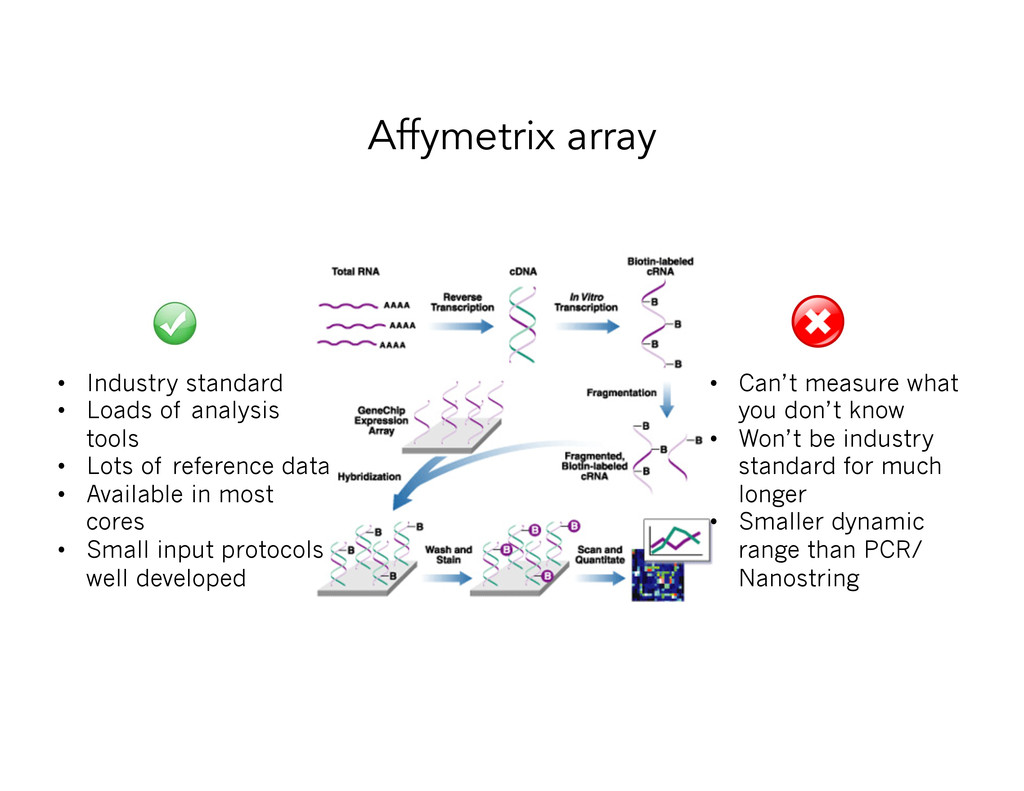
• Lots of reference data • Available in most cores • Small input protocols well developed • Can’t measure what you don’t know • Won’t be industry standard for much longer • Smaller dynamic range than PCR/ Nanostring
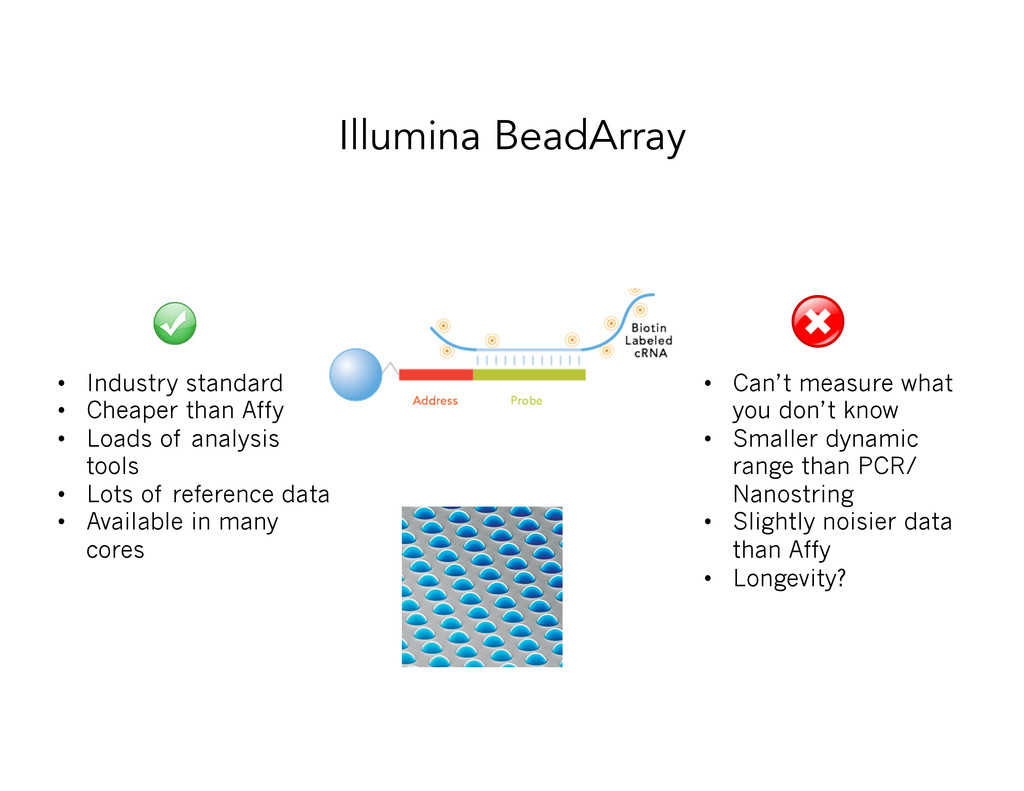
Loads of analysis tools • Lots of reference data • Available in many cores • Can’t measure what you don’t know • Smaller dynamic range than PCR/ Nanostring • Slightly noisier data than Affy • Longevity?
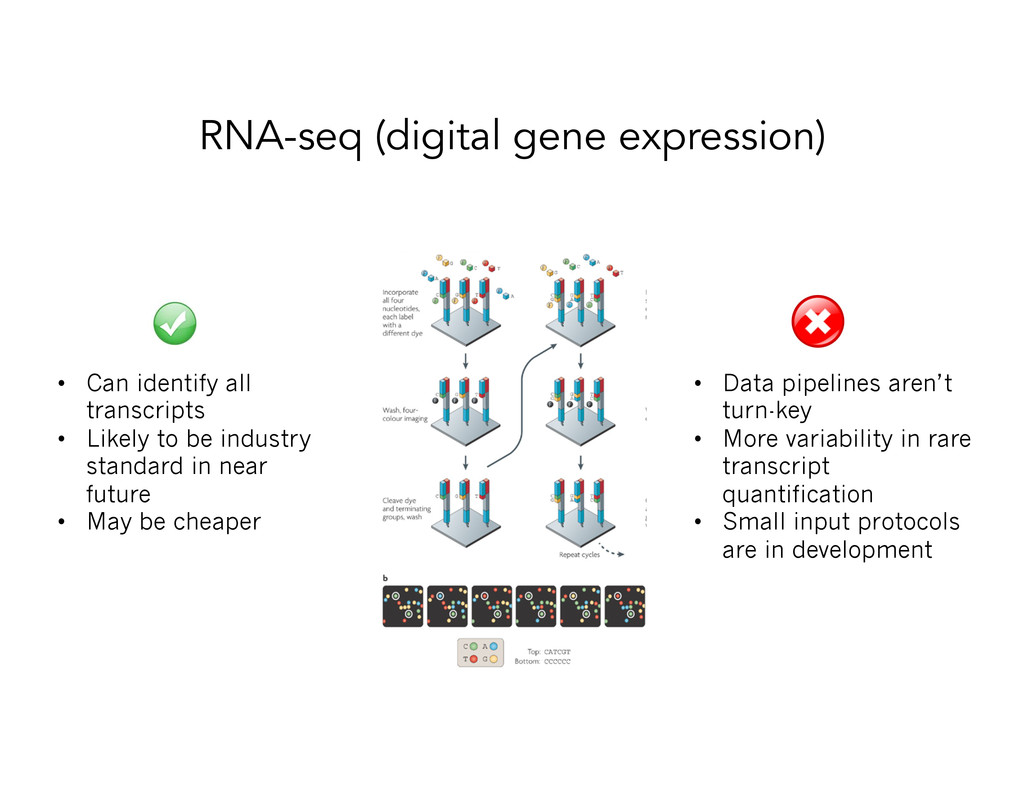
Likely to be industry standard in near future • May be cheaper • Data pipelines aren’t turn-key • More variability in rare transcript quantification • Small input protocols are in development
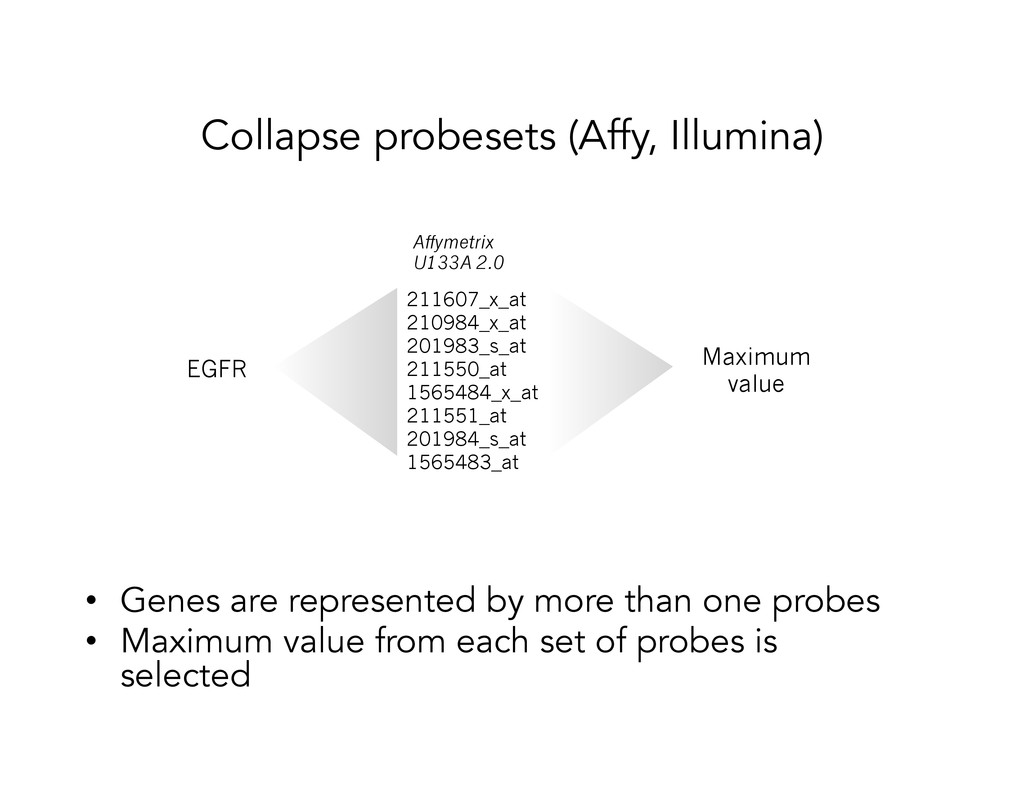
than one probes • Maximum value from each set of probes is selected 211607_x_at 210984_x_at 201983_s_at 211550_at 1565484_x_at 211551_at 201984_s_at 1565483_at EGFR Maximum value Affymetrix U133A 2.0
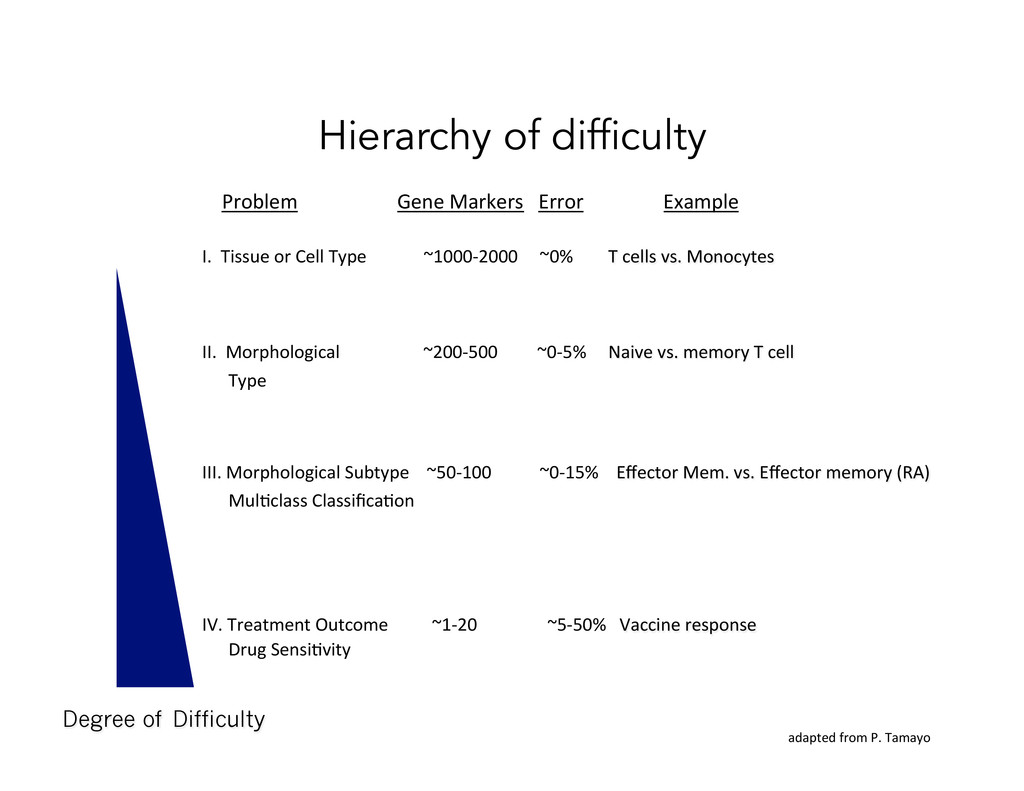
Gene Markers Error Example I. Tissue or Cell Type ~1000-‐2000 ~0% T cells vs. Monocytes II. Morphological ~200-‐500 ~0-‐5% Naive vs. memory T cell Type III. Morphological Subtype ~50-‐100 ~0-‐15% Effector Mem. vs. Effector memory (RA) MulOclass ClassificaOon IV. Treatment Outcome ~1-‐20 ~5-‐50% Vaccine response Drug SensiOvity Degree of Difficulty adapted from P. Tamayo Hierarchy of difficulty
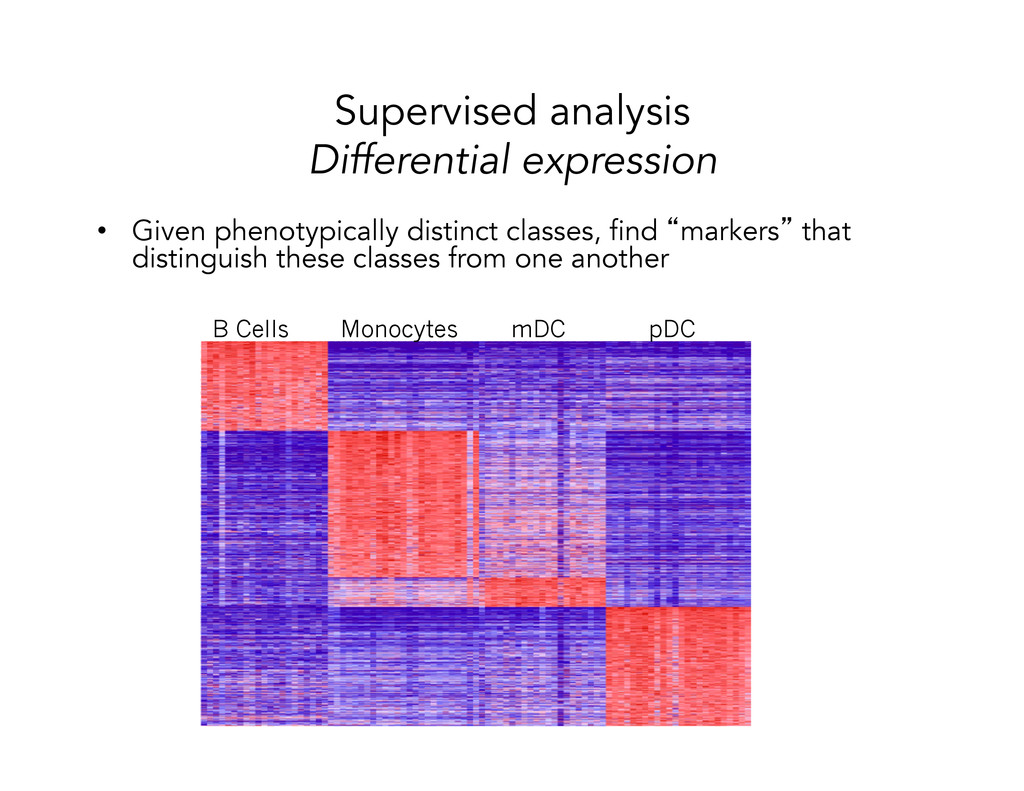
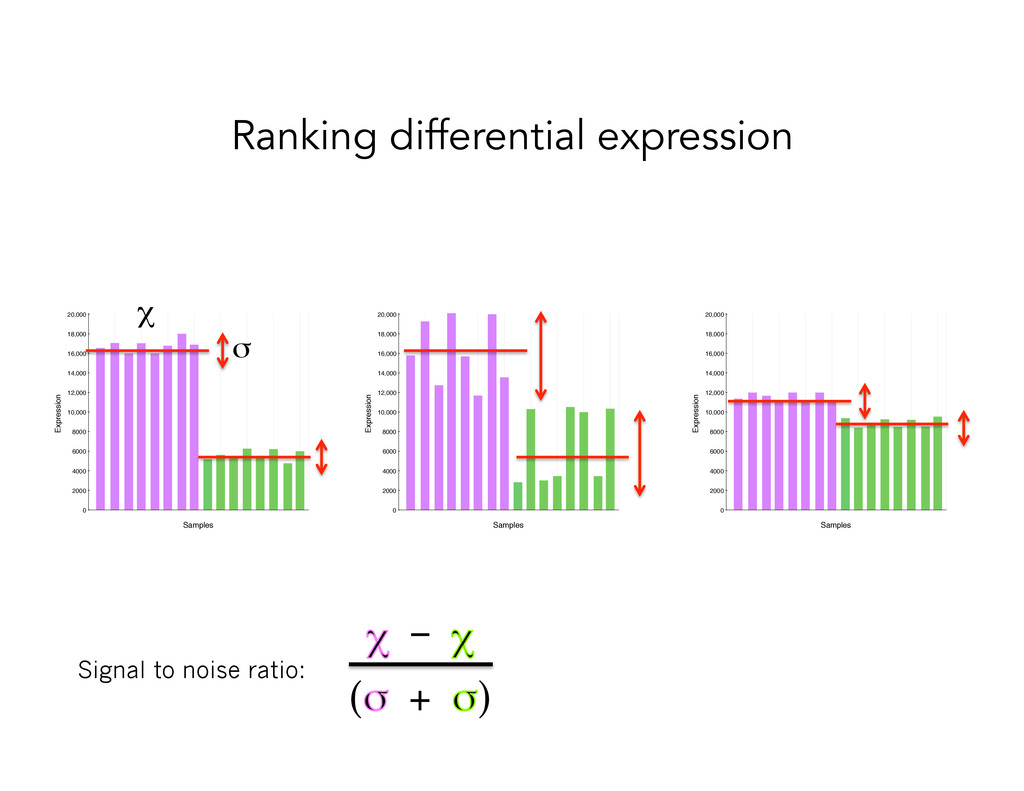
of false positives among all genes called differentially expressed • Multiple testing can only correct for false positives (type 1 error); need more samples to correctly identify false negatives (type 2 error)
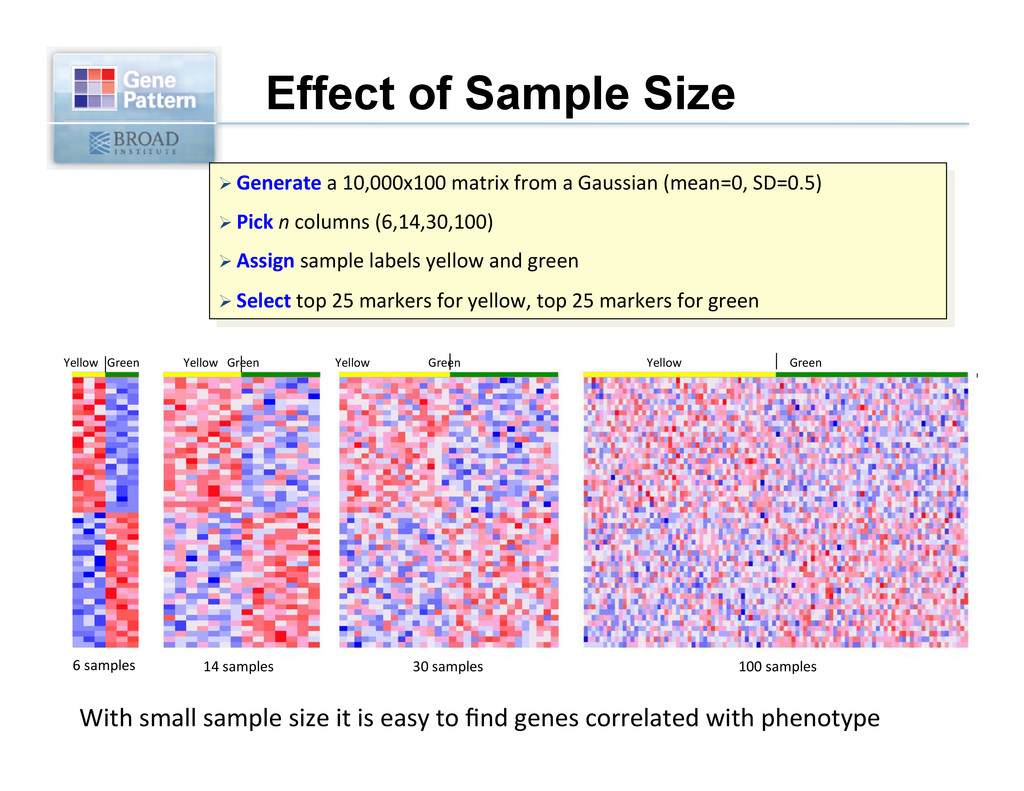
Gaussian (mean=0, SD=0.5) Ø Pick n columns (6,14,30,100) Ø Assign sample labels yellow and green Ø Select top 25 markers for yellow, top 25 markers for green With small sample size it is easy to find genes correlated with phenotype Yellow Green 6 samples Yellow Green 14 samples Yellow Green 30 samples Yellow Green 100 samples
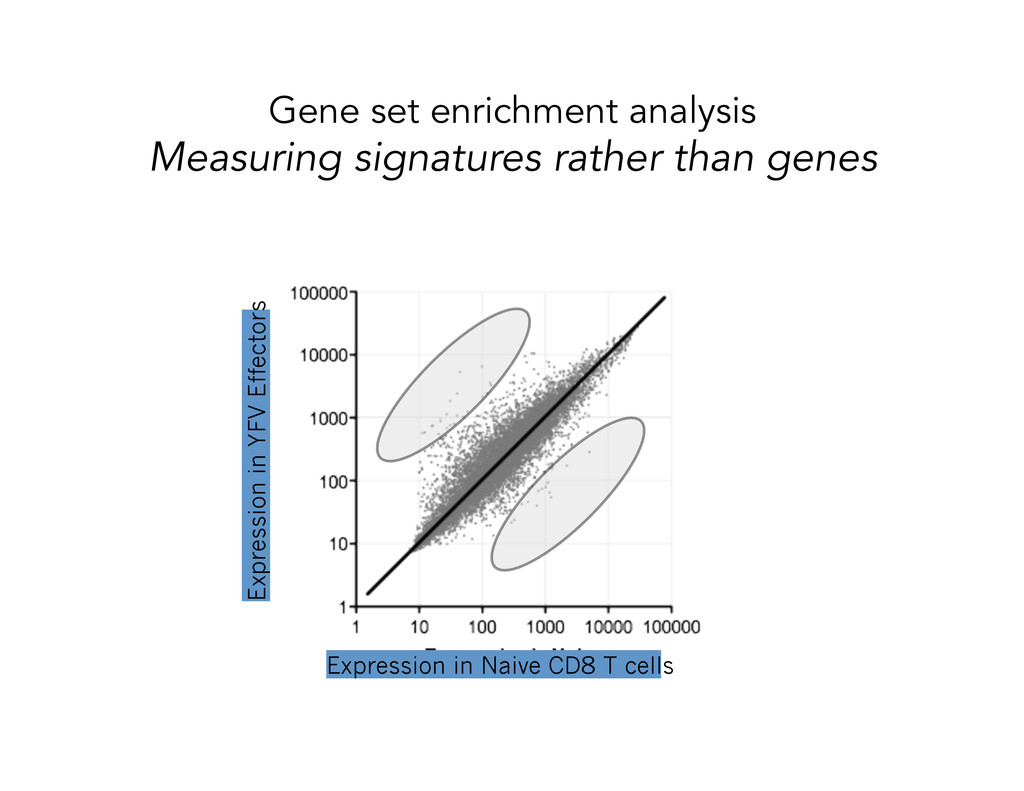
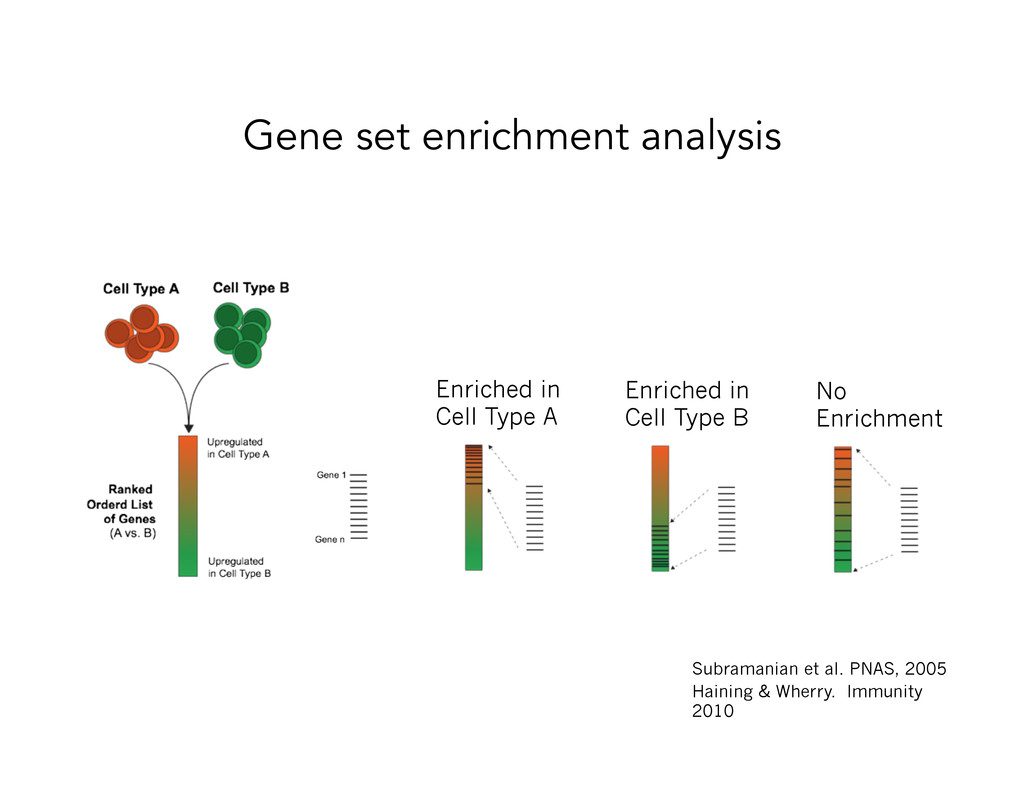
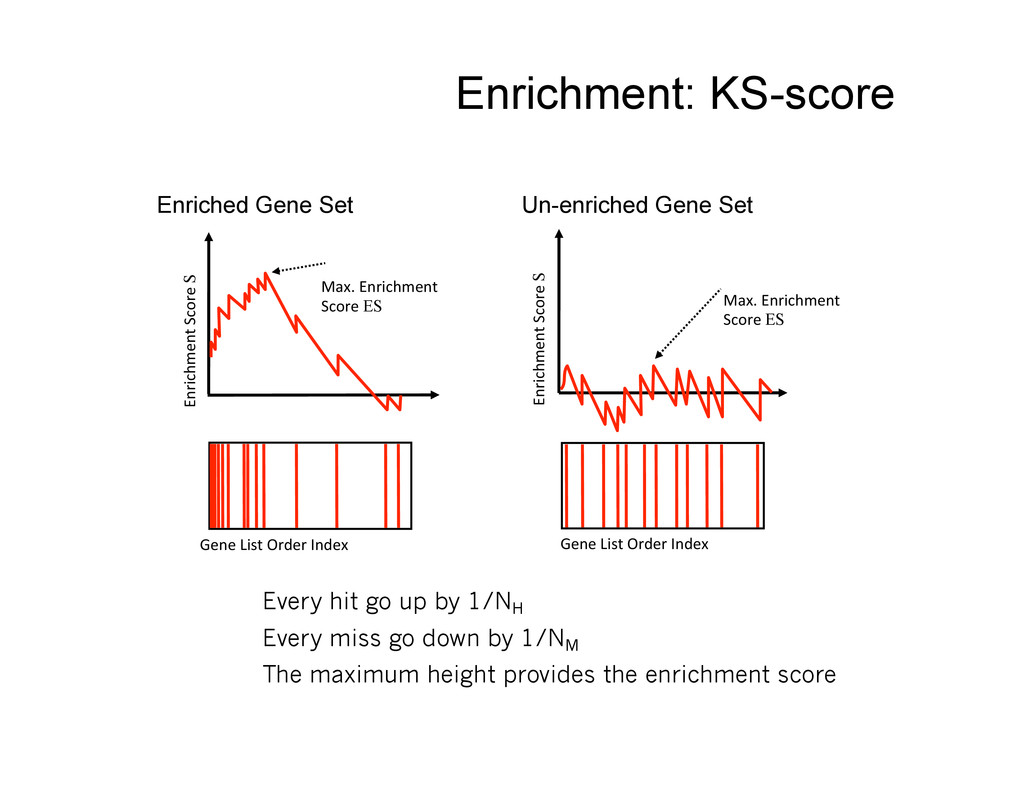
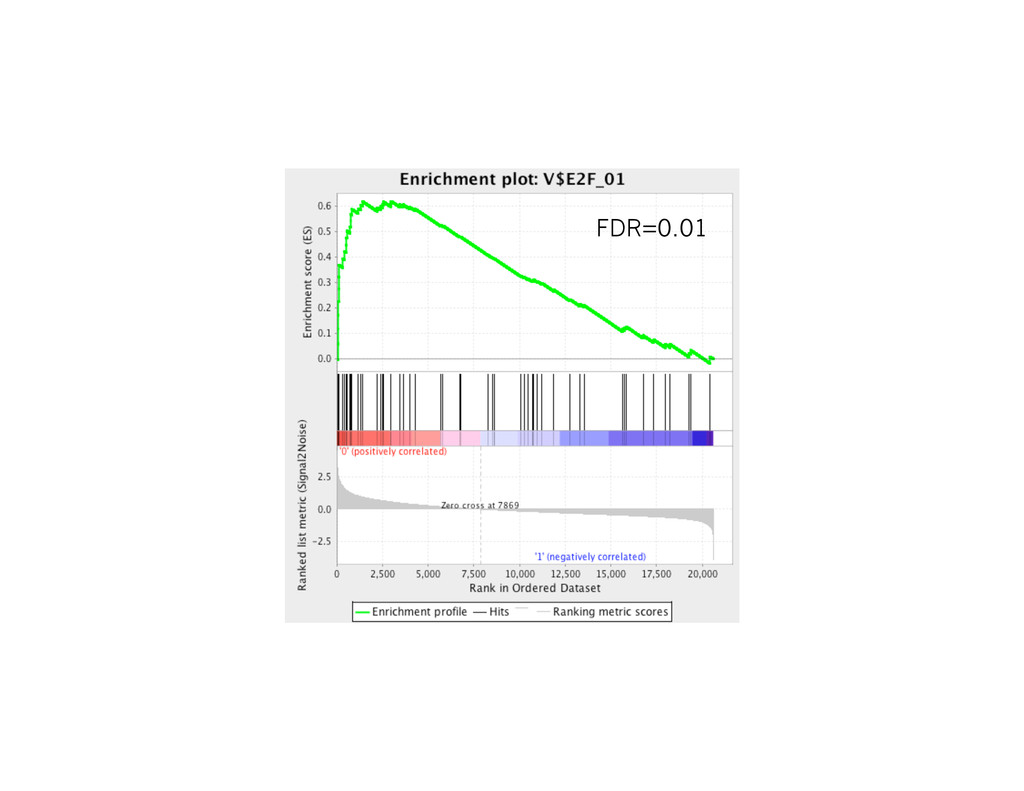
Enrichment Score ES Gene List Order Index Enrichment Score S Max. Enrichment Score ES Gene List Order Index Every hit go up by 1/NH Every miss go down by 1/NM The maximum height provides the enrichment score Enrichment: KS-score
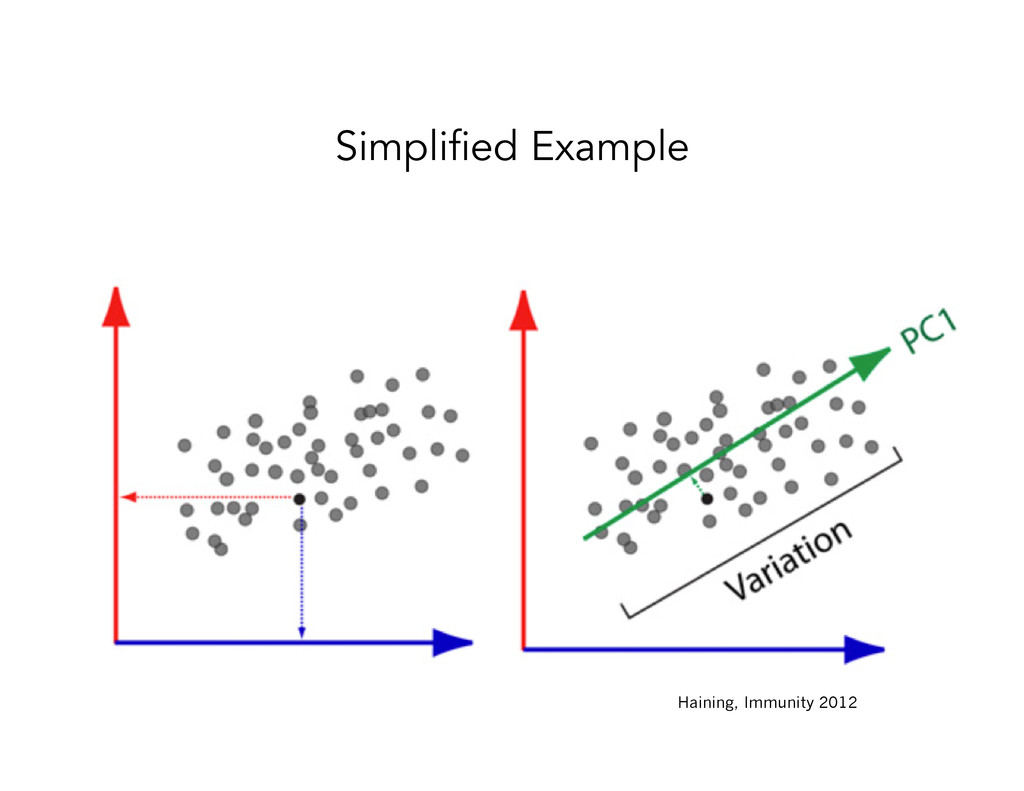
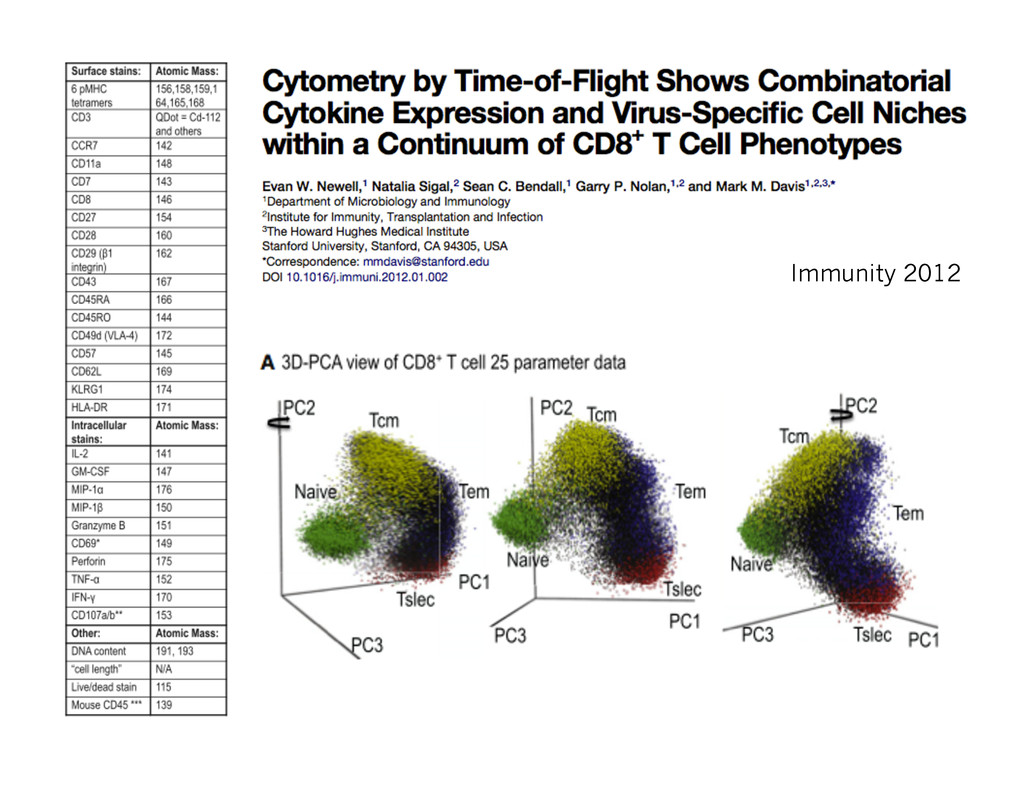
to artificial dimensions of greatest variation • Useful since phenotypic differences often are captured along a PC • Allows objects (samples) to be clustered together in small number of dimensions
and are staining a population of T cells from a well characterized mouse model for flow cytometry. You accidentally grab the wrong vial of antibody for your stains. When you flow the cells, you discover that a subset of your population of interest stains with this novel marker. Subsequent experiments confirm the finding and show that this novel subset has unique functional properties. You want to use gene expression profiling to characterize this novel subset of cells.
new vaccine in samples from a clinical trial. A well-characterized cohort of human subjects is vaccinated with the same vaccine, but unexpectedly the antibody response to the vaccine varies enormously across the cohort. Your project is to identify novel correlates of the antibody response using gene expression profiling of PBMC samples.
A into cell-type B. In a small-molecule screen, you have identified a compound that appears to induce the differentiation of cell-type A. The readout of the screen was upregulation of a cell-surface molecule characteristic of cell- type B. You now want to use gene expression profiling to determine whether the compound induces broader transcriptional changes associated with cell-type B.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}