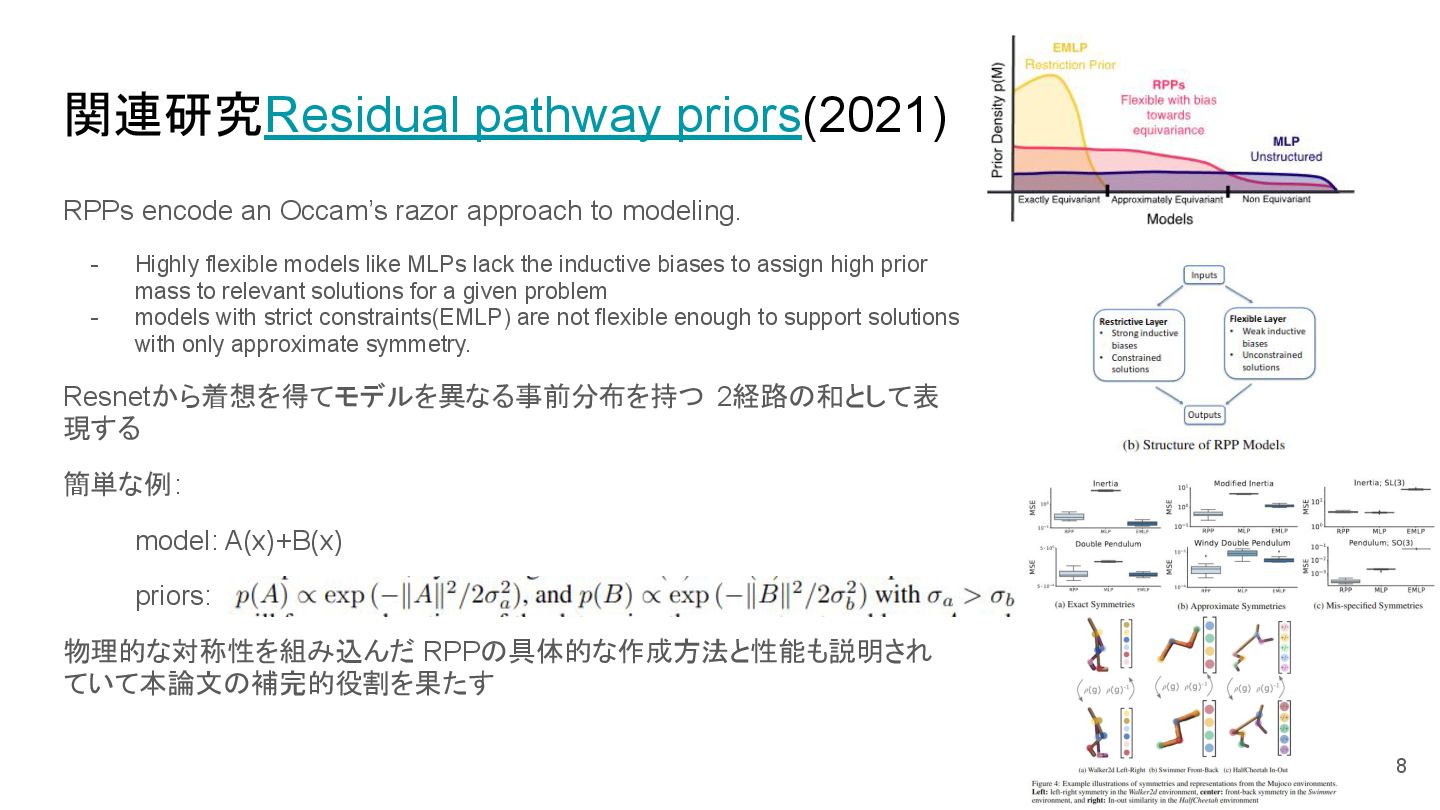
modeling. - Highly flexible models like MLPs lack the inductive biases to assign high prior mass to relevant solutions for a given problem - models with strict constraints(EMLP) are not flexible enough to support solutions with only approximate symmetry. Resnetから着想を得てモデルを異なる事前分布を持つ 2経路の和として表 現する 簡単な例: model: A(x)+B(x) priors: 物理的な対称性を組み込んだ RPPの具体的な作成方法と性能も説明され ていて本論文の補完的役割を果たす 8
Nonvacuous Generalization Bounds for Deep (Stochastic) Neural Networks with Many More Parameters than Training Data(2017) (Not) Bounding the True Error(2001) 日本語解説ブログ→ • A PAC-Bayesian Perspective on the Interpolating Information Criterion IIC(Interpolating Information Criterion) という新しい情報量基準を提唱し、 overparametrizationにおけるPAC-Bayes不等式が と書けることを示している。 • A Geometric Modeling of Occam’s Razor in Deep Learning 情報幾何(Fisher情報行列、 Jeffreys分布)を用いた情報量基準の提唱 • PAC-Bayesian Theory Meets Bayesian Inference(NIPS2016) 17 https://www.alignmentforum.org/posts/CZHwwDd7t9aYra5HN/dslt-2-wh y-neural-networks-obey-occam-s-razor そこでもし学習したネットワークが flat minimaに存在していた場合、その周囲の 誤差はネットワークのそれと近い値になることが期待できるわけだから、その flat minimaのあたりで確率的に揺れてるネットワークを事後分布とすることで 上手くいきそうな気がする さらに、flatであればあるほど事後分布が感覚的に大きくなるわけだから、事前 分布とマッチしやすくなり (つまりKLダイバージェンスが小さくなり )結果として汎 化誤差の上界が小さくなりそう、、、という話らしい https://dora119.hateblo.jp/entry/2020/05/20/032806
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}