Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
CXL_related_session_of_Linux_Plumbers_Conferenc...
Search
Yasunori Goto
June 17, 2026
21
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
CXL_related_session_of_Linux_Plumbers_Conference_2025.pdf
Yasunori Goto
June 17, 2026
More Decks by Yasunori Goto
See All by Yasunori Goto
Exploring CXL Memory: Configuration and Emulation
yasunorigoto1
0
490
Compute Express Link(CXL), the next generation interconnect -- Overview and the status of Linux -- (Open Source Summit Japan 2023 ver.)
yasunorigoto1
0
810
Compute Express Link(CXL), the next generation interconnect -- Overview and the status of Linux --
yasunorigoto1
0
1.2k
Featured
See All Featured
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Building Better People: How to give real-time feedback that sticks.
wjessup
370
20k
Test your architecture with Archunit
thirion
1
2.3k
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.6k
Embracing the Ebb and Flow
colly
88
5.1k
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
390
Noah Learner - AI + Me: how we built a GSC Bulk Export data pipeline
techseoconnect
PRO
0
210
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
200
[SF Ruby Conf 2025] Rails X
palkan
2
1.1k
sira's awesome portfolio website redesign presentation
elsirapls
0
300
My Coaching Mixtape
mlcsv
0
170
Testing 201, or: Great Expectations
jmmastey
46
8.2k
Transcript
Linux Plumbers Conference 2025 におけるCXLの動向 2026/6/17 五島
はじめに • 2025年に東京で開催されたLinux Plumbers Conferenceのうち、 主にCXLに関連する議題について取り上げます • なお、一部の解説内容が以下とかぶります • 2025年のCXLの動向について
• https://qiita.com/YasunoriGoto1/items/5510306877e465053ff2 2
Linux Plumbers Conferenceとは 3
Linux Plumbers Conference(=LPC)概要 Linux Kernelやdriverなどについて、開発してきた機能の解説の発表、今後の方向性などを議論 • メンテナーを含めた様々な開発者が質疑・議論 • 場合によっては今後の実装案について合意 •
聴講するだけでも、Linuxの今後の開発動向などが見えてくる • 会議以外でも、廊下などでF2Fでする会話も重要 • 廊下の相談で設計が決まっていくこともあるし、もちろん色々な情報交換もある • 直接面識を得ることで、その後のコミュニケーションもスムーズに なお、2026年は チェコのプラハで開催 (2026/10/5~10/7) 発表・議題に採用されるかどうかは、以下が評価される模様 • 応募(=Call For Proposal)に記載したabstractの内容 • 応募者のOSS開発活動実績があるとプラス評価 • 例)応募者が開発メーリングリストに開発物を投稿・議論済み • 査読論文の発表をするカンファレンスと異なる点 主要なLinux kernelやドライバの開発者が集まるカンファレンス 4
2025年のPlumbers conference • 東京:虎の門ヒルズで開催(2025/12/11~13) • Open Source Summit Japan(12/8~12/10)と同じ会場で開催 •
現地参加者は約500人程度だった模様 • 1週間程度で現地参加チケットは完売した模様 • 私は今回初の現地参加 • 2021年に不揮発メモリの発表で参加した時は、コロナのため 現地参加自体が存在せず、リモート参加のみ • リモート参加者も多数で、発表者もリモートのケースもあり • Day1とDay3の夜は懇親会 (それぞれ写真右上と右下) • 右下は映画”Kill Bill”で有名な権八 • 盛況で1000人ぐらいいるかと思ってた • 発表資料はすべて公式サイトに公開済み • 各セッションの状況がわかる動画もすべて公開済み • 後から議論内容を知りたいだけなら、こちらをチェックするだけでも OKなので、興味がある人は見てみると良い 5
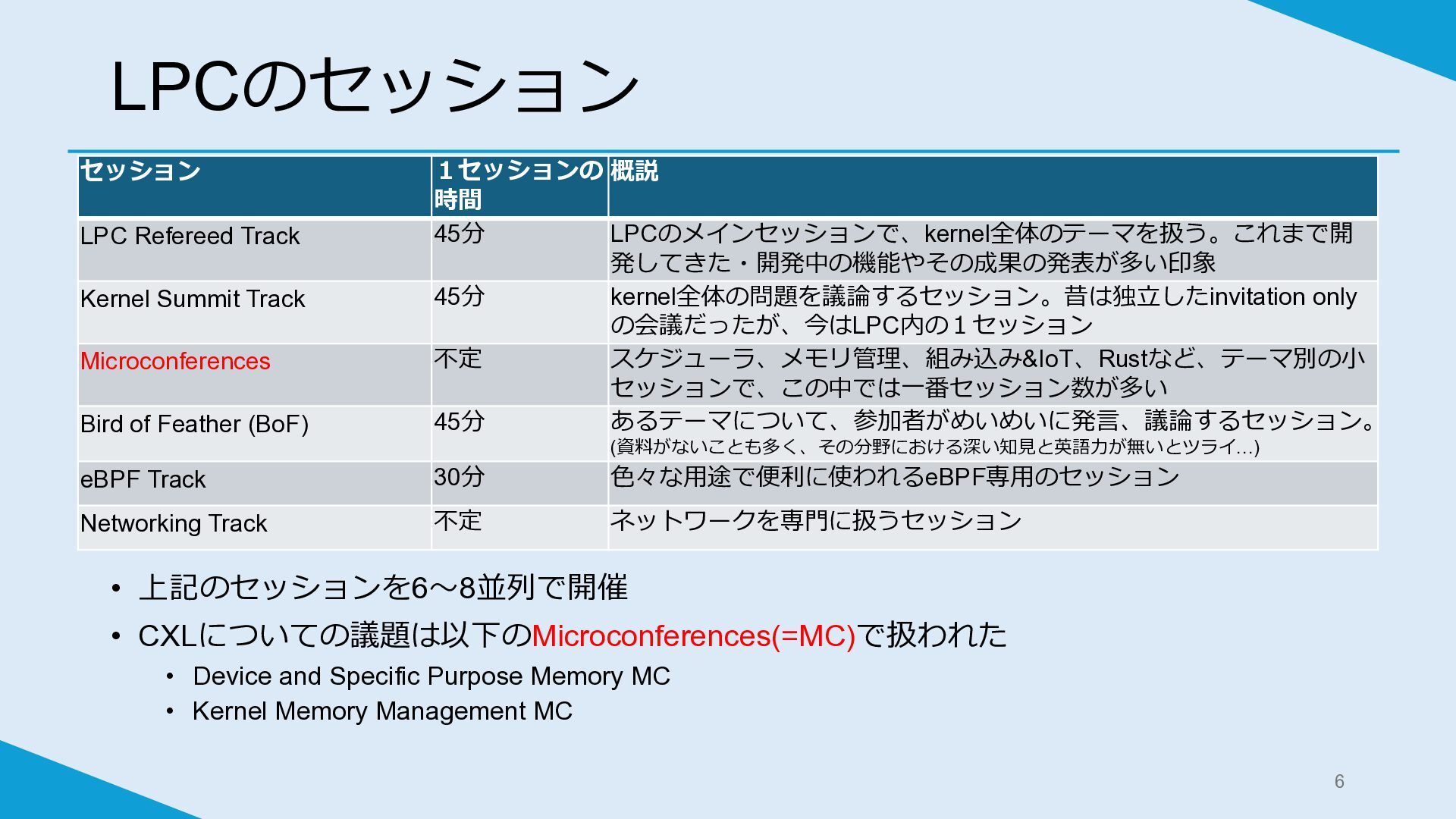
LPCのセッション セッション 1セッションの 時間 概説 LPC Refereed Track 45分 LPCのメインセッションで、kernel全体のテーマを扱う。これまで開
発してきた・開発中の機能やその成果の発表が多い印象 Kernel Summit Track 45分 kernel全体の問題を議論するセッション。昔は独立したinvitation only の会議だったが、今はLPC内の1セッション Microconferences 不定 スケジューラ、メモリ管理、組み込み&IoT、Rustなど、テーマ別の小 セッションで、この中では一番セッション数が多い Bird of Feather (BoF) 45分 あるテーマについて、参加者がめいめいに発言、議論するセッション。 (資料がないことも多く、その分野における深い知見と英語力が無いとツライ…) eBPF Track 30分 色々な用途で便利に使われるeBPF専用のセッション Networking Track 不定 ネットワークを専門に扱うセッション • 上記のセッションを6~8並列で開催 • CXLについての議題は以下のMicroconferences(=MC)で扱われた • Device and Specific Purpose Memory MC • Kernel Memory Management MC 6
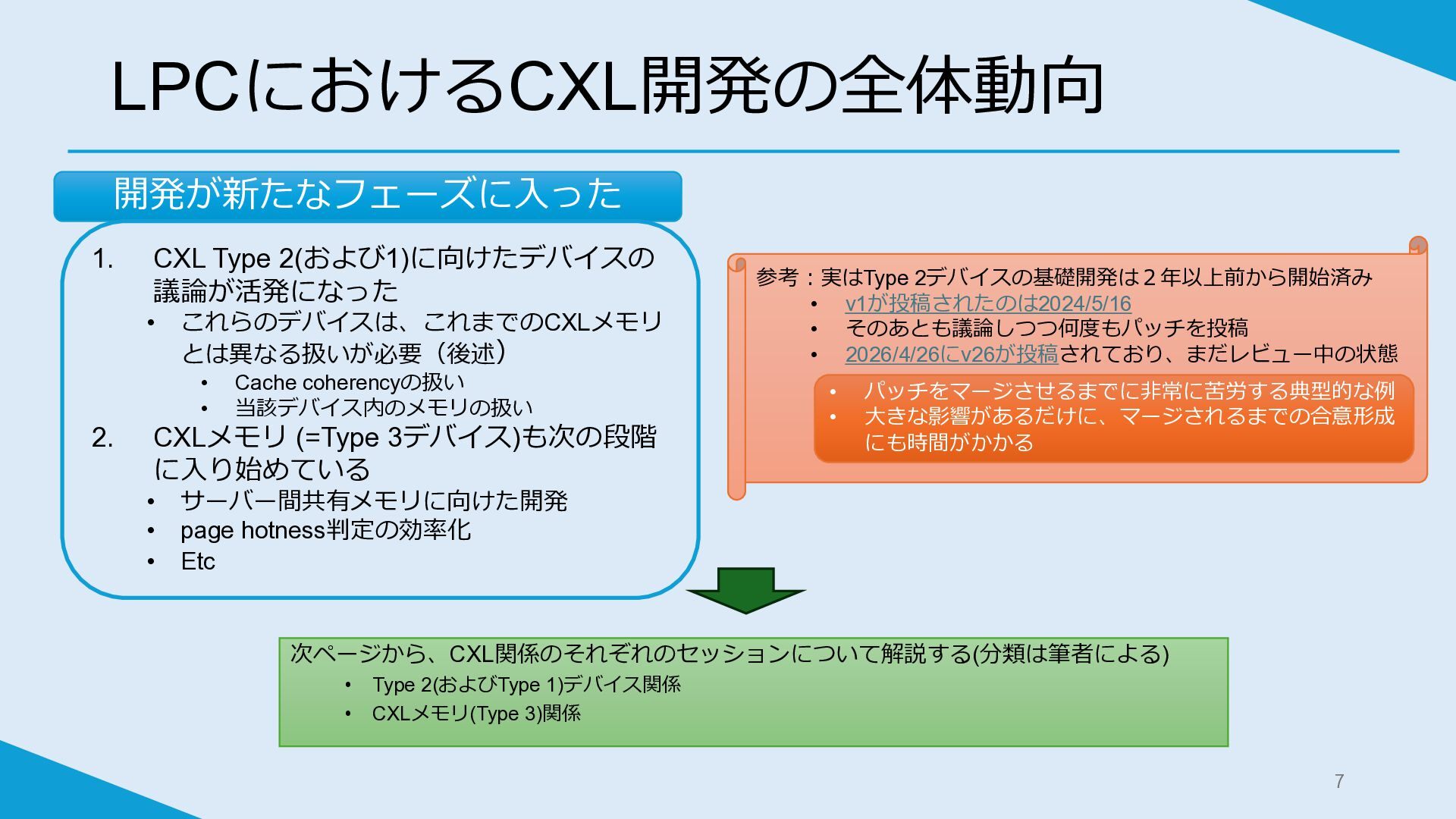
LPCにおけるCXL開発の全体動向 開発が新たなフェーズに入った 参考:実はType 2デバイスの基礎開発は2年以上前から開始済み • v1が投稿されたのは2024/5/16 • そのあとも議論しつつ何度もパッチを投稿 • 2026/4/26にv26が投稿されており、まだレビュー中の状態
次ページから、CXL関係のそれぞれのセッションについて解説する(分類は筆者による) • Type 2(およびType 1)デバイス関係 • CXLメモリ(Type 3)関係 1. CXL Type 2(および1)に向けたデバイスの 議論が活発になった • これらのデバイスは、これまでのCXLメモリ とは異なる扱いが必要(後述) • Cache coherencyの扱い • 当該デバイス内のメモリの扱い 2. CXLメモリ (=Type 3デバイス)も次の段階 に入り始めている • サーバー間共有メモリに向けた開発 • page hotness判定の効率化 • Etc • パッチをマージさせるまでに非常に苦労する典型的な例 • 大きな影響があるだけに、マージされるまでの合意形成 にも時間がかかる 7
Type 2(および Type1) device関係 なお、各スライドには、発表タイトルと発表者の所属会社を記載 説明の最後のURLは、当該発表への情報リンク(Abstract, 資料,動画など) 8
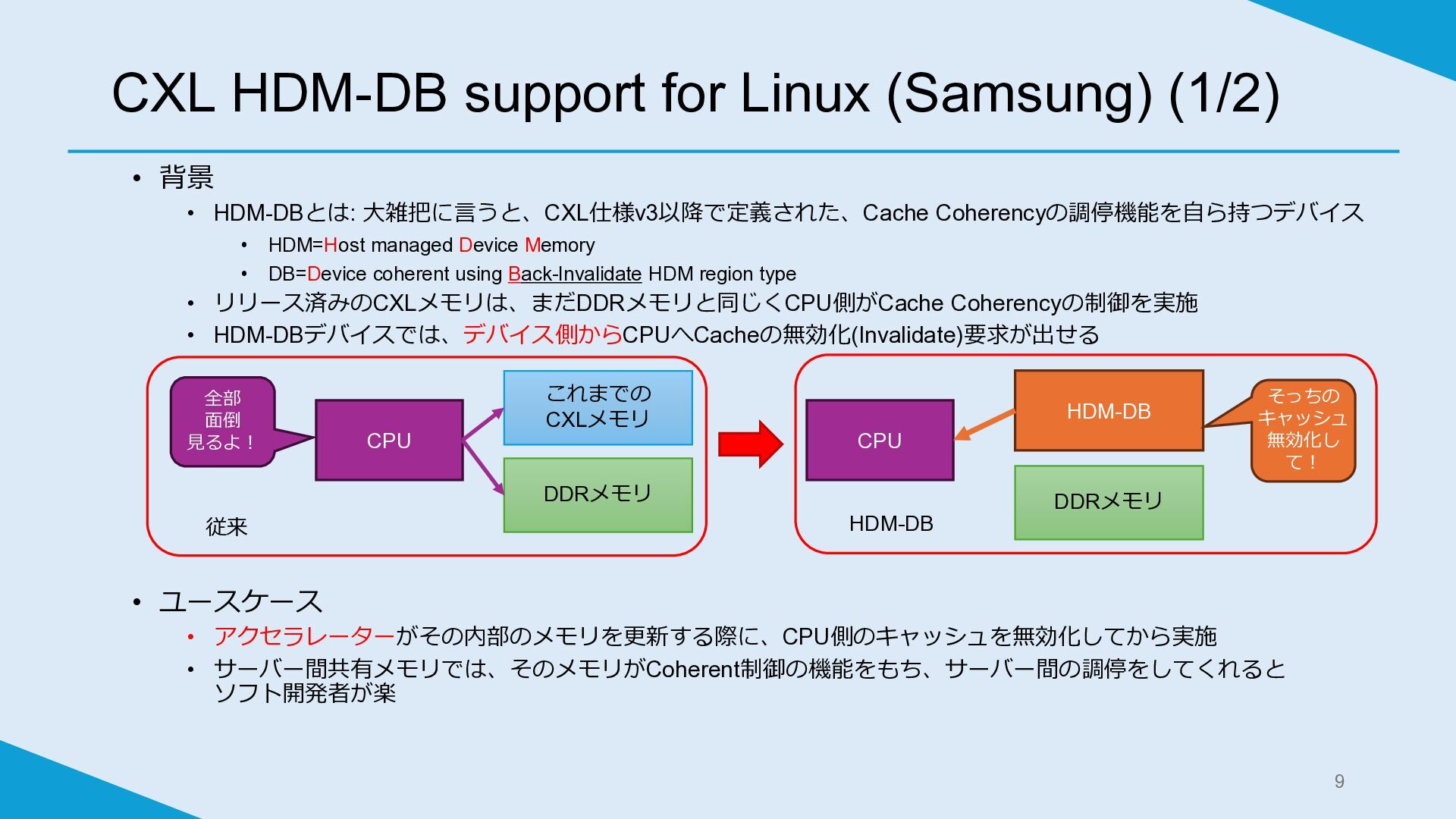
• 背景 • HDM-DBとは: 大雑把に言うと、CXL仕様v3以降で定義された、Cache Coherencyの調停機能を自ら持つデバイス • HDM=Host managed Device
Memory • DB=Device coherent using Back-Invalidate HDM region type • リリース済みのCXLメモリは、まだDDRメモリと同じくCPU側がCache Coherencyの制御を実施 • HDM-DBデバイスでは、デバイス側からCPUへCacheの無効化(Invalidate)要求が出せる • ユースケース • アクセラレーターがその内部のメモリを更新する際に、CPU側のキャッシュを無効化してから実施 • サーバー間共有メモリでは、そのメモリがCoherent制御の機能をもち、サーバー間の調停をしてくれると ソフト開発者が楽 CXL HDM-DB support for Linux (Samsung) (1/2) 9 CPU これまでの CXLメモリ DDRメモリ CPU HDM-DB DDRメモリ そっちの キャッシュ 無効化し て! 全部 面倒 見るよ! 従来 HDM-DB
• 発表 • HDM-DBデバイスのサポートについて、現状の説明 • QEMUのエミュレーションパッチ(v4)の紹介と、その使い方の説明(まだハードが無い) • CacheのInvalidate要求(Back Invalidate)サポートのための初期パッチの紹介 •
現状のCXLメモリ対応の実装に、Back Invalidationのサポートを入れる方向がわかりやすいと説明 • 今後の方針について問題提起 • Coherentをサポートする領域(region)のユーザーAPIをどうするか? • (Cache Coherenceの制御に使う)Snoop Filterは容量が必要になるが、デバイスのコストも上がってしまう ⇒ が、ハードの代わりにソフトで制御するのは難しいので、どこかで落としどころが必要か • 議論 • 実ハードのリリースも必要であり、まだまだ先は長そうな感触 • https://lpc.events/event/19/contributions/2062/ CXL HDM-DB support for Linux (Samsung) (2/2) 10 • CPUのキャッシュをinvalidatすれば、p2p通信で直接データを書き込める • データ通信にCPUを経由しないことで、CPUに近い上流のPCIeの帯域を空けることが可能なメリットがある • 2GBで1分だが、TB単位の場合数時間レベルになる ⇒ なので、このようなハードの機能に期待 CPU cacheをwrite backする命令をソフト側から実行すると、非常に時間がかかる デバイスからCXLメモリへp2pで直接書き込むケースでも、このような機能は欲しい
Parallel Paths to High-Bandwidth Memory for ML/AI: Specific Purpose Memory
vs. Driver-Managed Approaches (AMD) (1/2) • 背景 • CXLも含めた、デバイス・アクセラレーター内のメモリをどうやって扱うかの話 • CXLメモリと異なり、普通のプロセスに使わせてもメリットが無く、ドライバなど関連ソフトのみに使わせたい領域 • この発表の契機は、CXLと異なる通信路(例えば、APUとGPGPUが同じダイに乗っている)のケース • しかし、課題自体はCXLのType2デバイスもほぼ同じ • このようなデバイスの領域はプラットフォームのファームウェアが EFIの仕様を使って、 特別な目的のメモリ領域(=Specific Purpuse Memory=SPM)としてOSに通知できる • この領域は、CPUからアクセス自体はできるが、kernelが通常のメモリ管理システムに組み込まないようにできる • デバイスドライバによって当該領域の扱いを決めることができる • しかし、現在実装済みのルートでは、結局kernelのメモリ管理機構に当該領域が登録されてしまう • いやいや、このアクセラレータの内部のメモリはドライバ側が使いたいんで困るんですけど… どうすればいいの?という話 • 実際に、お客様のところでトラブルが派生したとのこと • 古いkernelだと、boot optionで、Device DAXのドライバを無効化するしかない 11 Special Purpose Memory (normal memory) 無関係の プロセス ドライバ Special Purpose Memory (normal memory) 無関係の プロセス 関連 プロセス ドライバ 理想 現実 ドライバなど関連 ソフトのみが使用 他のプロセスが占有 してドライバが利用 不可 1. Device DAXのドライバがいったんDevice DAXの領域として登録 2. (CXLメモリの領域であれば)CXLメモリのドライバが、CXLメモリとして認識・初期化 3. Linuxのmemory hotplugの機能を経由して、当該領域がkernelの通常のメモリ管理に組み込まれてしまう ⇒ これにより、プロセスなどが当該領域を利用し、ドライバが利用不可に
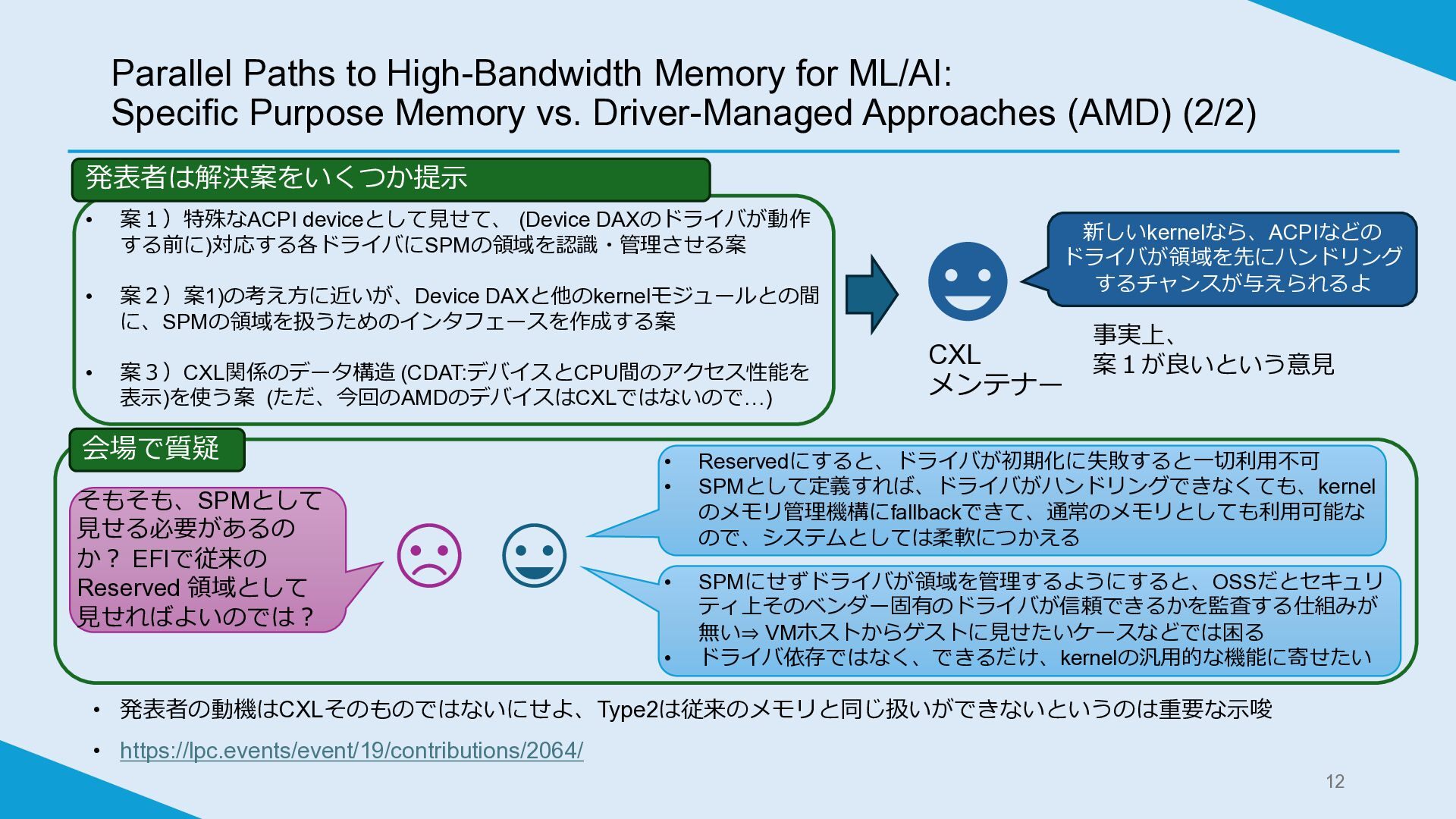
Parallel Paths to High-Bandwidth Memory for ML/AI: Specific Purpose Memory
vs. Driver-Managed Approaches (AMD) (2/2) • 発表者の動機はCXLそのものではないにせよ、Type2は従来のメモリと同じ扱いができないというのは重要な示唆 • https://lpc.events/event/19/contributions/2064/ 12 • 案1)特殊なACPI deviceとして見せて、 (Device DAXのドライバが動作 する前に)対応する各ドライバにSPMの領域を認識・管理させる案 • 案2)案1)の考え方に近いが、Device DAXと他のkernelモジュールとの間 に、SPMの領域を扱うためのインタフェースを作成する案 • 案3)CXL関係のデータ構造 (CDAT:デバイスとCPU間のアクセス性能を 表示)を使う案 (ただ、今回のAMDのデバイスはCXLではないので…) CXL メンテナー 新しいkernelなら、ACPIなどの ドライバが領域を先にハンドリング するチャンスが与えられるよ 事実上、 案1が良いという意見 発表者は解決案をいくつか提示 そもそも、SPMとして 見せる必要があるの か? EFIで従来の Reserved 領域として 見せればよいのでは? • Reservedにすると、ドライバが初期化に失敗すると一切利用不可 • SPMとして定義すれば、ドライバがハンドリングできなくても、kernel のメモリ管理機構にfallbackできて、通常のメモリとしても利用可能な ので、システムとしては柔軟につかえる • SPMにせずドライバが領域を管理するようにすると、OSSだとセキュリ ティ上そのベンダー固有のドライバが信頼できるかを監査する仕組みが 無い⇒ VMホストからゲストに見せたいケースなどでは困る • ドライバ依存ではなく、できるだけ、kernelの汎用的な機能に寄せたい 会場で質疑
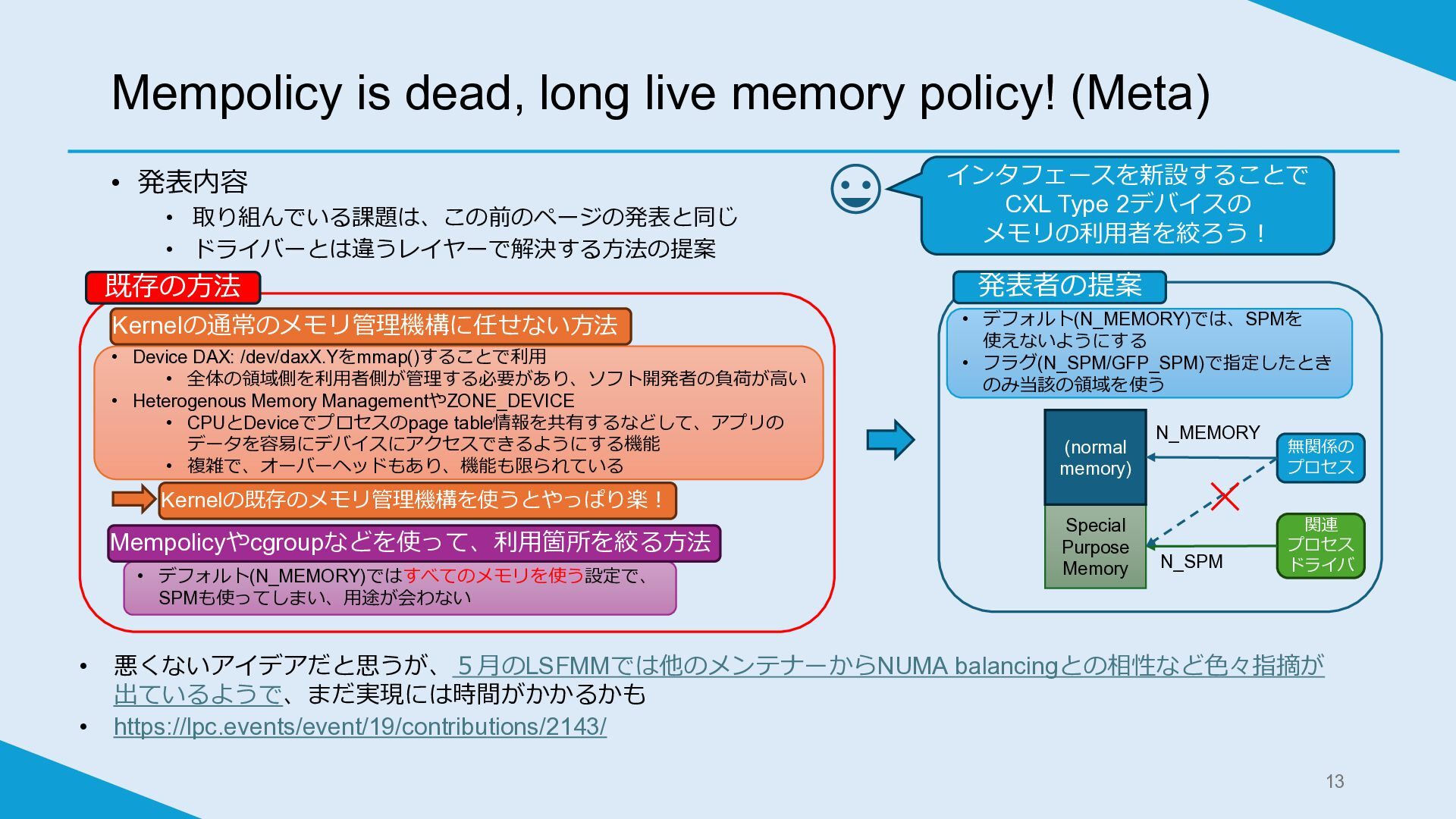
Mempolicy is dead, long live memory policy! (Meta) • 発表内容
• 取り組んでいる課題は、この前のページの発表と同じ • ドライバーとは違うレイヤーで解決する方法の提案 13 インタフェースを新設することで CXL Type 2デバイスの メモリの利用者を絞ろう! • Device DAX: /dev/daxX.Yをmmap()することで利用 • 全体の領域側を利用者側が管理する必要があり、ソフト開発者の負荷が高い • Heterogenous Memory ManagementやZONE_DEVICE • CPUとDeviceでプロセスのpage table情報を共有するなどして、アプリの データを容易にデバイスにアクセスできるようにする機能 • 複雑で、オーバーヘッドもあり、機能も限られている Kernelの通常のメモリ管理機構に任せない方法 Kernelの既存のメモリ管理機構を使うとやっぱり楽! • デフォルト(N_MEMORY)ではすべてのメモリを使う設定で、 SPMも使ってしまい、用途が会わない • 悪くないアイデアだと思うが、5月のLSFMMでは他のメンテナーからNUMA balancingとの相性など色々指摘が 出ているようで、まだ実現には時間がかかるかも • https://lpc.events/event/19/contributions/2143/ Special Purpose Memory (normal memory) 無関係の プロセス 関連 プロセス ドライバ N_MEMORY N_SPM • デフォルト(N_MEMORY)では、SPMを 使えないようにする • フラグ(N_SPM/GFP_SPM)で指定したとき のみ当該の領域を使う 発表者の提案 Mempolicyやcgroupなどを使って、利用箇所を絞る方法 既存の方法
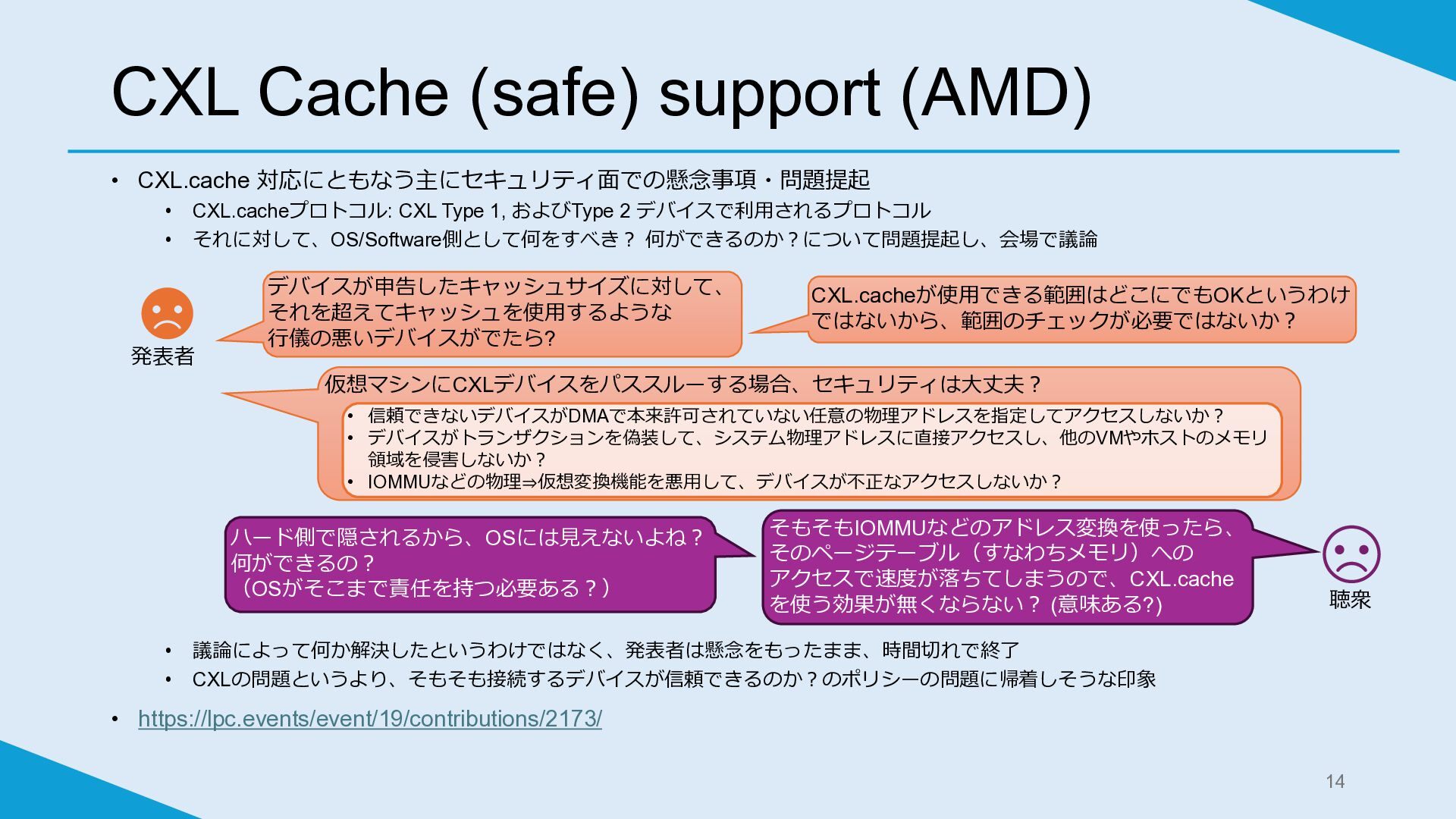
• CXL.cache 対応にともなう主にセキュリティ面での懸念事項・問題提起 • CXL.cacheプロトコル: CXL Type 1, およびType 2
デバイスで利用されるプロトコル • それに対して、OS/Software側として何をすべき? 何ができるのか?について問題提起し、会場で議論 • 議論によって何か解決したというわけではなく、発表者は懸念をもったまま、時間切れで終了 • CXLの問題というより、そもそも接続するデバイスが信頼できるのか?のポリシーの問題に帰着しそうな印象 • https://lpc.events/event/19/contributions/2173/ CXL Cache (safe) support (AMD) 14 CXL.cacheが使用できる範囲はどこにでもOKというわけ ではないから、範囲のチェックが必要ではないか? 仮想マシンにCXLデバイスをパススルーする場合、セキュリティは大丈夫? • 信頼できないデバイスがDMAで本来許可されていない任意の物理アドレスを指定してアクセスしないか? • デバイスがトランザクションを偽装して、システム物理アドレスに直接アクセスし、他のVMやホストのメモリ 領域を侵害しないか? • IOMMUなどの物理⇒仮想変換機能を悪用して、デバイスが不正なアクセスしないか? 発表者 ハード側で隠されるから、OSには見えないよね? 何ができるの? (OSがそこまで責任を持つ必要ある?) 聴衆 そもそもIOMMUなどのアドレス変換を使ったら、 そのページテーブル(すなわちメモリ)への アクセスで速度が落ちてしまうので、CXL.cache を使う効果が無くならない? (意味ある?) デバイスが申告したキャッシュサイズに対して、 それを超えてキャッシュを使用するような 行儀の悪いデバイスがでたら?
CXLメモリ(Type 3)関係 15
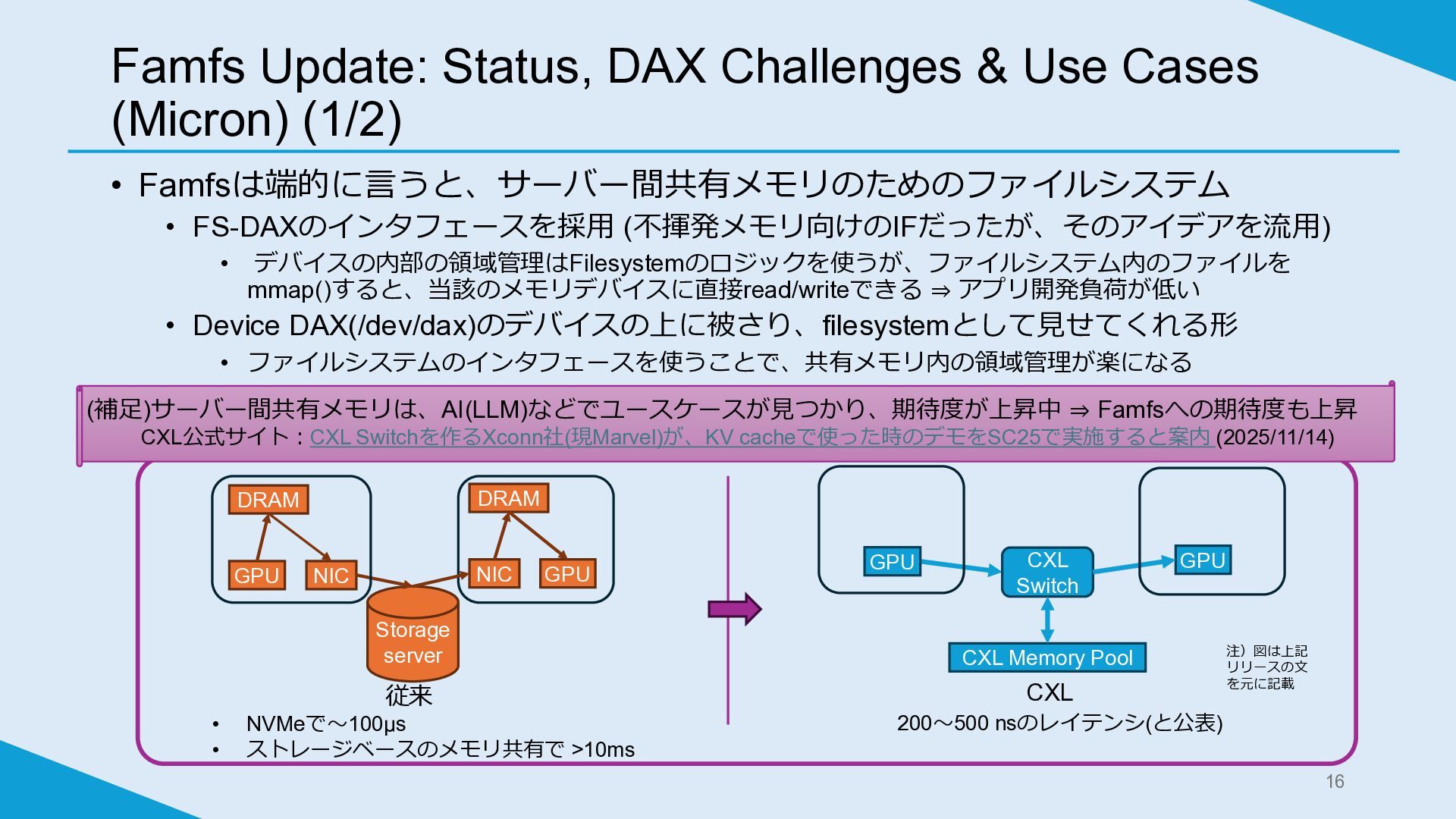
Famfs Update: Status, DAX Challenges & Use Cases (Micron) (1/2)
• Famfsは端的に言うと、サーバー間共有メモリのためのファイルシステム • FS-DAXのインタフェースを採用 (不揮発メモリ向けのIFだったが、そのアイデアを流用) • デバイスの内部の領域管理はFilesystemのロジックを使うが、ファイルシステム内のファイルを mmap()すると、当該のメモリデバイスに直接read/writeできる ⇒ アプリ開発負荷が低い • Device DAX(/dev/dax)のデバイスの上に被さり、filesystemとして見せてくれる形 • ファイルシステムのインタフェースを使うことで、共有メモリ内の領域管理が楽になる 16 GPU DRAM NIC Storage server NIC DRAM GPU 従来 • NVMeで~100μs • ストレージベースのメモリ共有で >10ms GPU GPU CXL Switch CXL Memory Pool CXL 200~500 nsのレイテンシ(と公表) (補足)サーバー間共有メモリは、AI(LLM)などでユースケースが見つかり、期待度が上昇中 ⇒ Famfsへの期待度も上昇 CXL公式サイト:CXL Switchを作るXconn社(現Marvel)が、KV cacheで使った時のデモをSC25で実施すると案内 (2025/11/14) 注)図は上記 リリースの文 を元に記載
Famfs Update: Status, DAX Challenges & Use Cases (Micron) (2/2)
• 主にユースケースや(うまくいったときの)性能測定、現在の開発状況、ロードマップについて解説する発表 • 4ノード(サーバー)からアクセスできるCXLメモリ(XconnのCXL Switchの背後に22個存在)をFamfsがinterleaveして使用 ⇒ 互いにのサーバーに性能影響が出ないことや従来技術より速いことをアピール(7時間⇒3分に短縮) • 最初の版(2024/2)と比べ、現在の実装はFUSE(kernel側ではなくユーザーランドで実装するFilesystem)で実装 • Kernel 6.18で完全に動くとされており、2026年初頭のUpstream kernelへのmergeを目指していた • …が、2026/5/21現在まだマージされていない。注)どんな機能もmergeされるまで、非常に苦労する(経験談) 17 • Famfsって(CXLによる)Scale outを目指しているけど、Scale upは? • (UALinkのように) アクセラレータ間で接続されていたら、対応できる? • 特にCXLだけに特化しているわけではない • Famfsはメモリ領域内の割り当てマッピングを整理するもので、UALink(によってメモリが可視化 されて)Device Daxにマップできるなら対応できる • 個人的にはfamfsには共有メモリのIFとして期待している • が、(特にFilesystemは)完成するまでの間に、細かいところで色々と苦労するから…。 • https://lpc.events/event/19/contributions/2178/ 質疑:
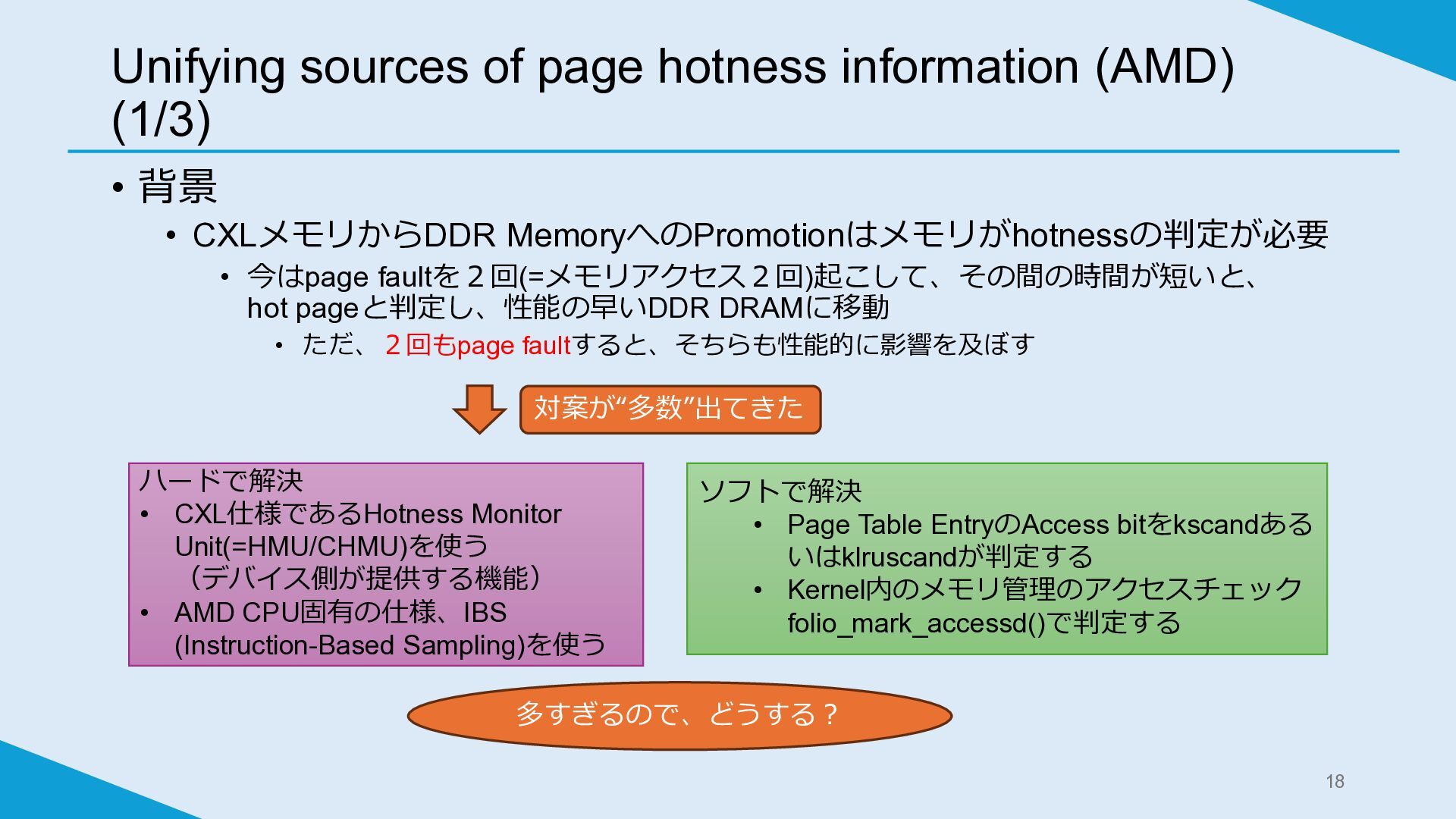
Unifying sources of page hotness information (AMD) (1/3) • 背景
• CXLメモリからDDR MemoryへのPromotionはメモリがhotnessの判定が必要 • 今はpage faultを2回(=メモリアクセス2回)起こして、その間の時間が短いと、 hot pageと判定し、性能の早いDDR DRAMに移動 • ただ、2回もpage faultすると、そちらも性能的に影響を及ぼす 対案が“多数”出てきた ハードで解決 • CXL仕様であるHotness Monitor Unit(=HMU/CHMU)を使う (デバイス側が提供する機能) • AMD CPU固有の仕様、IBS (Instruction-Based Sampling)を使う ソフトで解決 • Page Table EntryのAccess bitをkscandある いはklruscandが判定する • Kernel内のメモリ管理のアクセスチェック folio_mark_accessd()で判定する 多すぎるので、どうする? 18
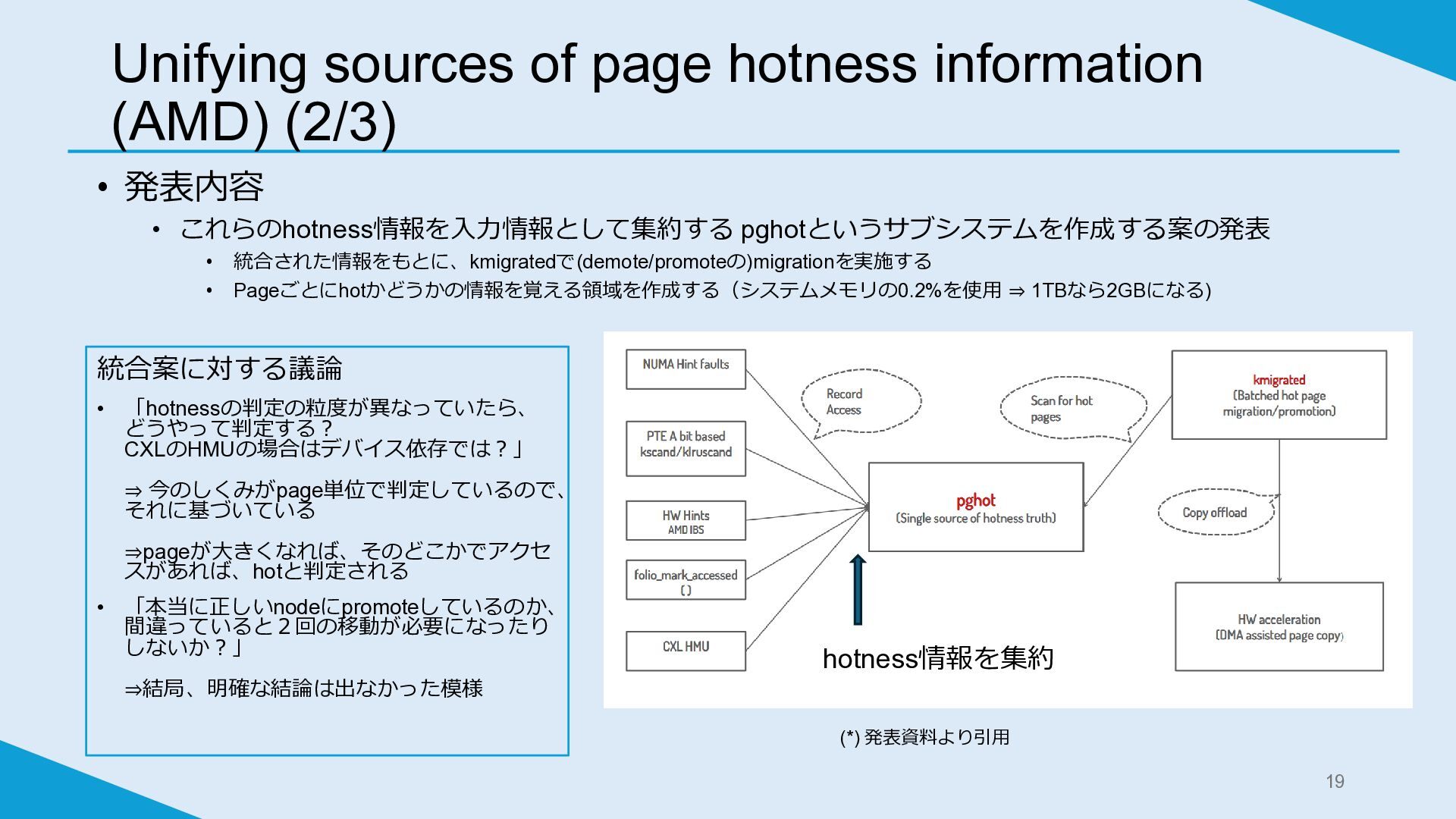
Unifying sources of page hotness information (AMD) (2/3) • 発表内容
• これらのhotness情報を入力情報として集約する pghotというサブシステムを作成する案の発表 • 統合された情報をもとに、kmigratedで(demote/promoteの)migrationを実施する • Pageごとにhotかどうかの情報を覚える領域を作成する(システムメモリの0.2%を使用 ⇒ 1TBなら2GBになる) 統合案に対する議論 • 「hotnessの判定の粒度が異なっていたら、 どうやって判定する? CXLのHMUの場合はデバイス依存では?」 ⇒ 今のしくみがpage単位で判定しているので、 それに基づいている ⇒pageが大きくなれば、そのどこかでアクセ スがあれば、hotと判定される • 「本当に正しいnodeにpromoteしているのか、 間違っていると2回の移動が必要になったり しないか?」 ⇒結局、明確な結論は出なかった模様 hotness情報を集約 (*) 発表資料より引用 19
Unifying sources of page hotness information (AMD) (3/3) • Pghotサブシステムを採用した場合の性能も評価
• 発表者の意図 • ベンチマークでpghotサブシステムの効果を説明。Hotness判定の ソースが違っても大体同じ結果になるということを示したい • hotness判定については、以下の4種のケースを用意 • NUMAB0: migration(promote/demote)しない設定 • NUMAB2: page faultによるpromotionを使った場合(今の実装) • Pgtscan: PTE access bitを使う方法(開発中でexperimental、 まだkernelにはマージされていない) • Hwhints: AMDのIBSを利用(発表者が独自に開発) • 表の縦軸は、Base(2列目)となるkernelソースに対して、pghotサ ブシステムでデータを集約したときの値(3列目)を比較している • PgtscanとHwhintはベースkernelにないので測定できない(=NA) • 右の表では、demote/promote両方動作させた比較 • 他にもいろいろ比較結果を表示 • 発表者の意図はともかく、hwhintsの性能が良いように見えている • 正直、色々データは示されているんだけど、値の増減の原因 について、もう少し詳細な説明・調査・分析が必要な印象 • https://lpc.events/event/19/contributions/2063/ 20 (*) 発表資料より引用
DAMON-based Pages Migration for {C,G,X}PU [un]attached NUMA nodes (crusoe.ai) (1/2)
• 発表内容 • これもhotnessの実装改善だが、アプローチが少し違う 21 • コマンドのパラメタで、どのような条件で promote/demoteを行うのかや監視頻度など の様々なチューニングが可能な点が特徴(右) • (現在は)Page tableのaccess bitをチェックし てmonitoring • こちらも従来のpage fault形式やAMDのIBS など、複数のhotness情報をまとめること自 体は可能としている DAMON(=Data Access Monitoring) とは: メモリアクセスを監視するkernelのsubsystem Kernelの代わりに、DAMONの観測結果を使ってpromote/demoteしよう!
DAMON-based Pages Migration for {C,G,X}PU [un]attached NUMA nodes (crusoe.ai) (2/2)
• 良くも悪くもユーザーの設定次第な模様だが、今後pghotなどとの連携が期待される • https://lpc.events/event/19/contributions/2066/ 22 • Per CPU page(CPUごとに保持されているpage)の扱いなど、細かい点ではまだ課題もある模様 • PoCにはよいが、Upstreamにマージしてもらうにはメンテナンス性で課題があるため、そのためのコードの改善 を実施中 • damon_report_access(): 他のあらゆるkernelのコンポーネントが、アクセス情報についてreportする関数を定 義(これを使って欲しいということ) • ユーザーからその希望に応じたフィルタリングができるように指定 開発状況 質疑 &コメント DAMONのオーバーヘッドは? メモリサイズに関係なく、ユーザーがオーバーヘッドを設定可能 精度は? DAMONでpghotのようにpage 単位での きめ細かい監視ができるのか? 設定次第でできるが、オーバーヘッドが大きくなる (先ほどの)pghotと連携することを期待
To online or not to online CXL memory (SUSE Labs/meta)
(1/2) • このセッションは1セッションの中に議題が二つ (発表者も二人で、二人目は”Mempolicy is dead, long live memory policy!”の発表をした方と同じ) • 1つ目の議題は (CXLも使う)Memory hotplugにのインタフェースに対する問題提起 • Linuxのmemory hotplugのインタフェースについては、以下を参照してほしい • 「意外と知られていない、Linuxのメモリホットプラグのインタフェースについて」 • Memory hotplugの単位(memory block)サイズは、その開発初期に実装上の都合で、アーキごとに決められた経緯がある • X86-64アーキでは当初は256Mbyteだったが、今は物理サーバーでは1GB単位だったりする 背景 23 CXLメモリデバイスは下手するとTB級になるのに、まだ1GB単位なの? そのサイズに対応するmemory blockを全部online/offlineの操作するのは面倒すぎる! CXLデバイスで扱う領域(region)単位で 操作できるようにしたい! 既存のインタフェースは互換性のための残しつつ、 新たなインタフェースを作る必要があるよね! • CXLv3ではDynamic Capacity Deviceという、デバイス単位よりも細かい単位でhotplugが可能になる ⇒その時はどうなるかがまだよくわからず • 操作の際にhotremove可能な領域以下を指定することになる • ZONE_MOVABLE:kernelやドライバが使うことができない領域(=hotremove可能) • ZONE_NORMAL:kernelやドライバが使えるようにする (=hotremove不可) • なお、この指定はsysfsのほか、Kernelのビルド時の設定や、起動時のブートパラメタ、あるいは udev.rulesなどでもZONEの種別を調整できることが複雑さに拍車をかけている 大きな 反対は 無し
To online or not to online CXL memory (SUSE Labs/meta)
(2/2) • 2つめの発表は、主にMemory Tieringのv2版の効果の説明 • そのうえで性能や信頼性の劣るCXLメモリを如何に賢く、隔離、活用するか?の議論 • 基本、今の実装を肯定する内容で、大きな議論とはならなかった模様) • https://lpc.events/event/19/contributions/2016/ 24 • CXLメモリが直接つながっている場合、 (Memory Tieringの実装も初版より更新されたため) 今のmemory tieringの仕組みは大体うまく動作している ⇒コンテナ間で割り当てバランスが異なるということが無くなり、性能やpromoteの効率も改善された • CXL Switchを介する場合、さらにレイテンシーがかかるので別の問題が見えてくるが、調査中 ⇒ 「できれば2026年中に論文を出したい」とも • (GPGPU内臓のHBMなどの) CXLデバイスでは、hotplugで自動的にonline(有効化)にしないほうが良い 局面がある • アクセス頻度の低いpageをCXLメモリに追い出すのは合理的だし、性能向上しているケースもある • ZONE_MOVABLEの設定を遅いCXLメモリに使うことは、hotplugだけでなく、kernelやドライバの 性能を落とさずに済む • CXLmemoryの故障時にpanicに陥らず、process killだけで済むという意味でも重要
まとめ・感想 • (相変わらず)議論の内容が濃い • Kernel/driverの実装に関わるメンツが集うだけのことはあり、内容についていくのもハード • あの場で議論に交われることが重要と痛感 • Samsung, Micron,
AMDなどのハードベンダーのほかは、Metaのようなサービスプロバイ ダーが開発の主役に • CXL以外の他のセッションもサービスプロバイダーが目立つ • 自分たちのサービスに必要なkernelの機能を研究して開発しているということ • 懇親会では中国出身の方も目立った • いっぽう、日本企業は残念ながら少々影が薄い感 ⇒ もっと参加しても良いのでは? • CXL対応のLinuxの開発は、説明の通り次のフェーズに入ってきたことを痛感 • LinuxのMemory Hotplug機能も最初の実装から20年がたち、新たな課題が見えてきたことは、 元開発者としてちょっと感慨深い 25
Thank you! 26
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![DAMON-based Pages Migration for {C,G,X}PU [un]attached NUMA nodes (crusoe.ai) (1/2)](https://files.speakerdeck.com/presentations/062bc7f34c4149d6b7a5116f16f6455f/slide_20.jpg){kind=link}
![DAMON-based Pages Migration for {C,G,X}PU [un]attached NUMA nodes (crusoe.ai) (2/2)](https://files.speakerdeck.com/presentations/062bc7f34c4149d6b7a5116f16f6455f/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}