Compute Express Link (CXL) is a promising new interconnect specification that connects devices similar to PCI Express. It introduces many attractive features, and the Linux community is rapidly developing drivers and tools for CXL. However, its specification can be difficult to understand, making it challenging to follow the Linux community's progress. In this presentation, I would like to help you understand the overview of the CXL specification. Additionally, I'll talk about the current status of Linux development related to CXL. Basically, this talk will be based on the following presentation, which was used at NVMSA (https://nvmsa2023.github.io/). However I will update or add more information about the status of Linux community as much as possible until the deadline day.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
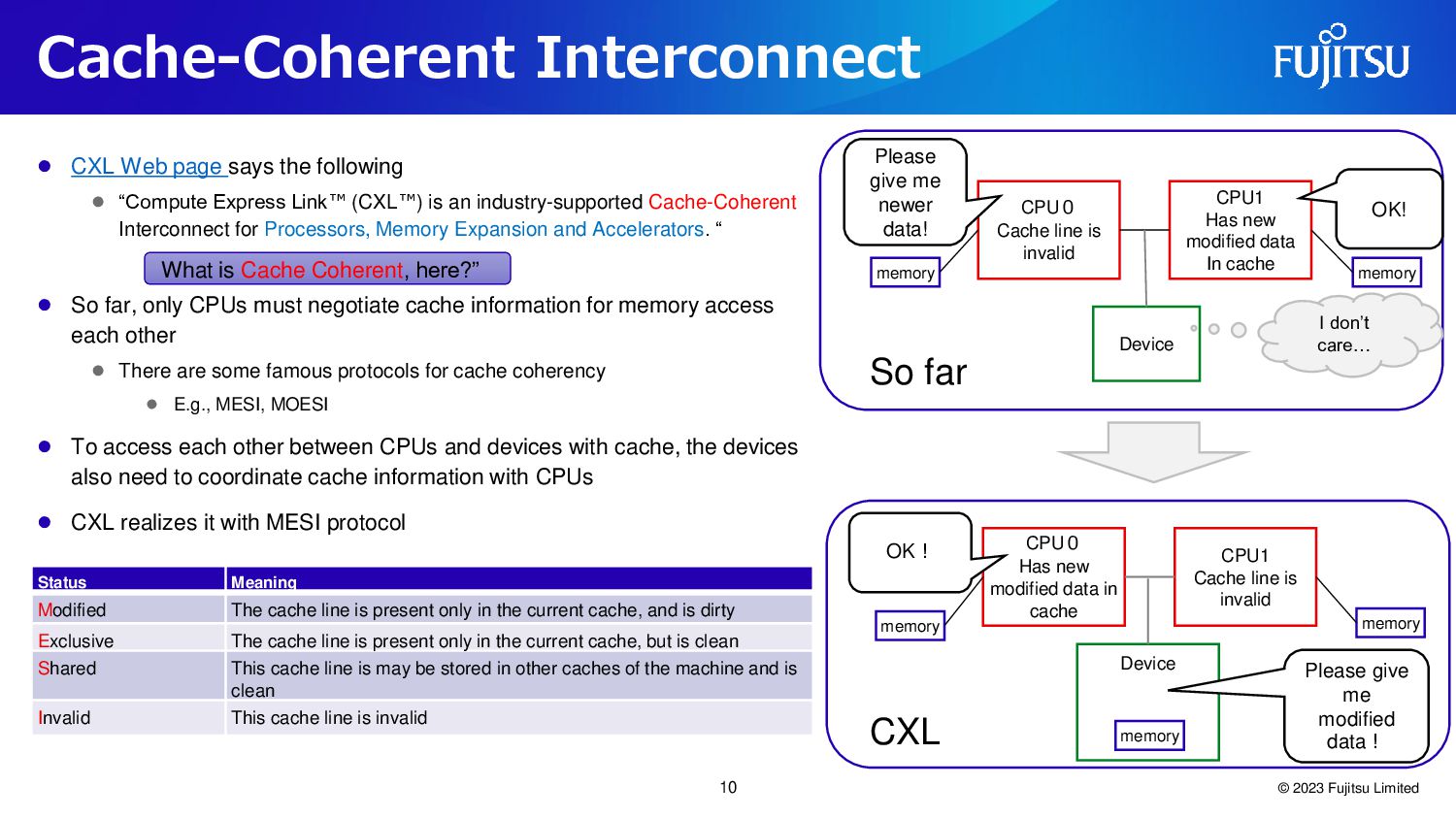{kind=link}
{kind=link}
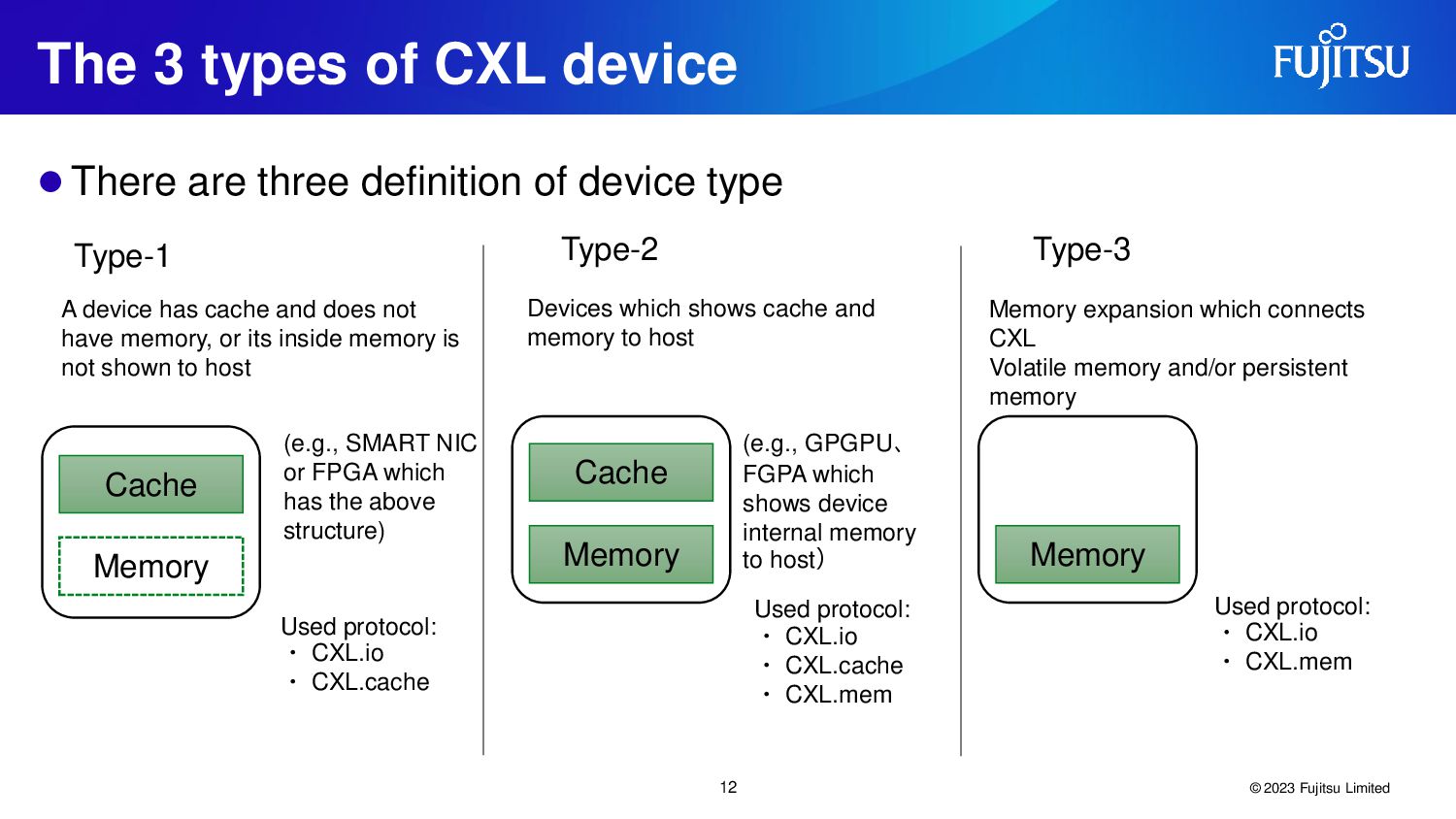{kind=link}
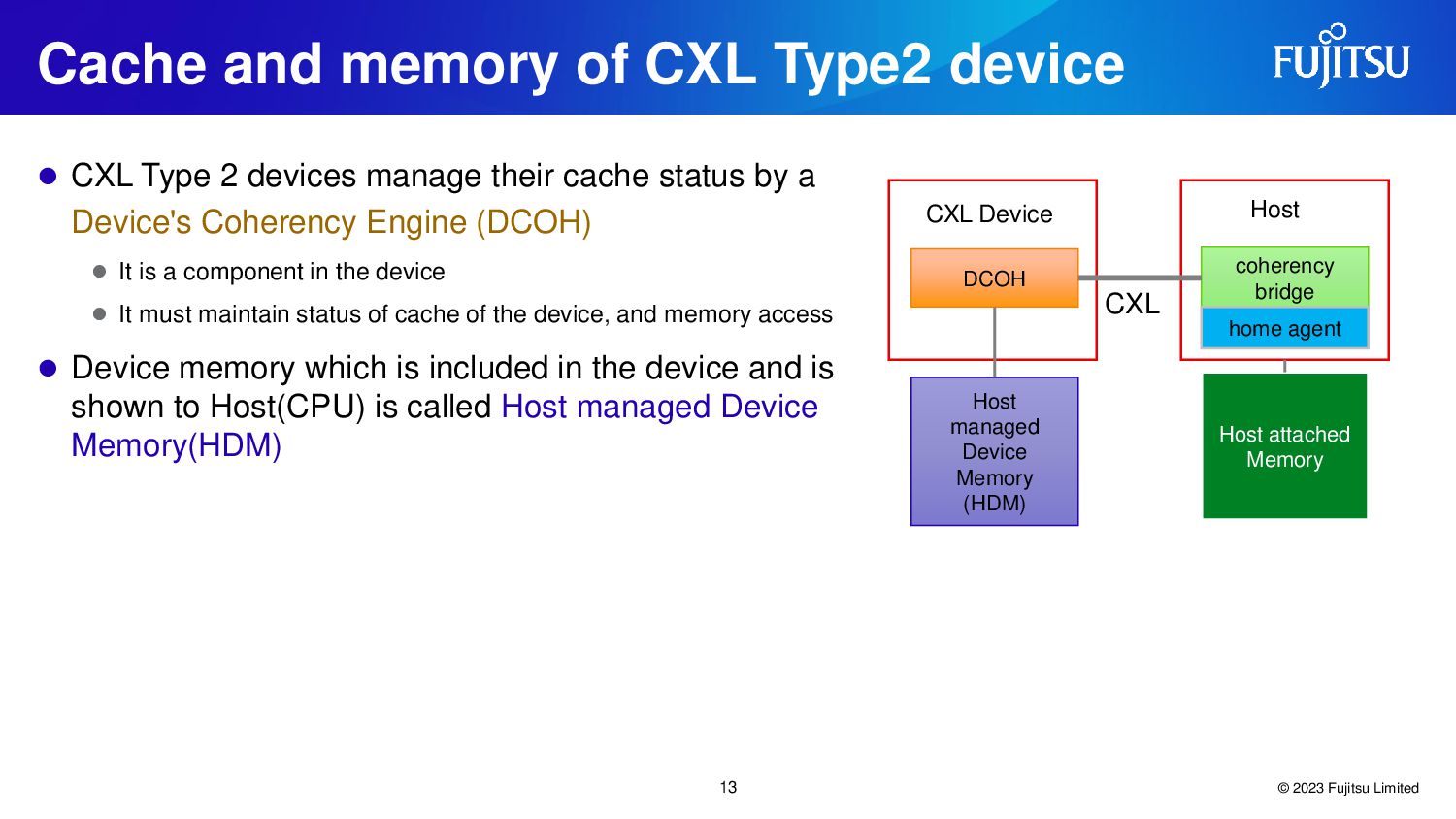{kind=link}
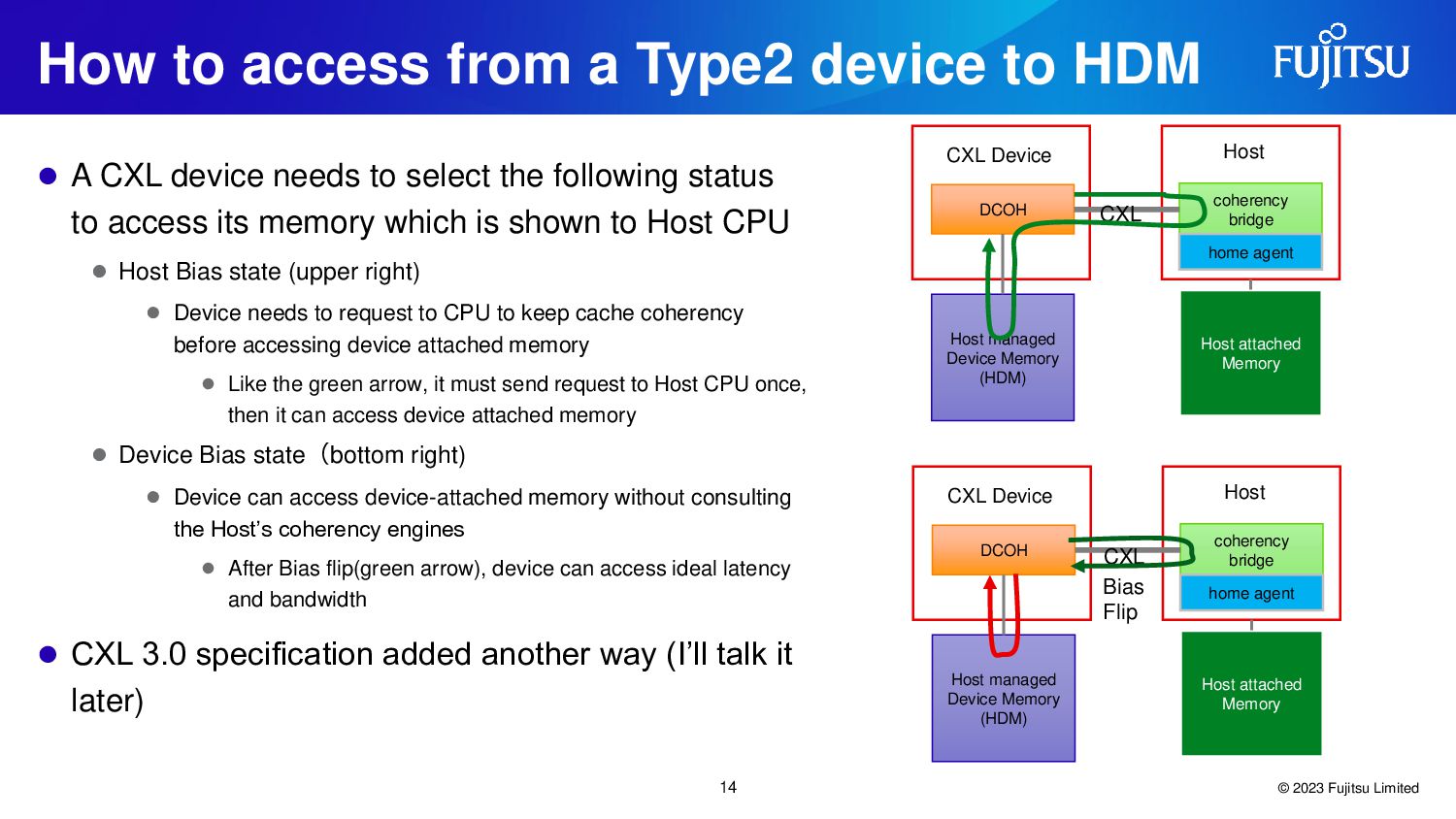{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
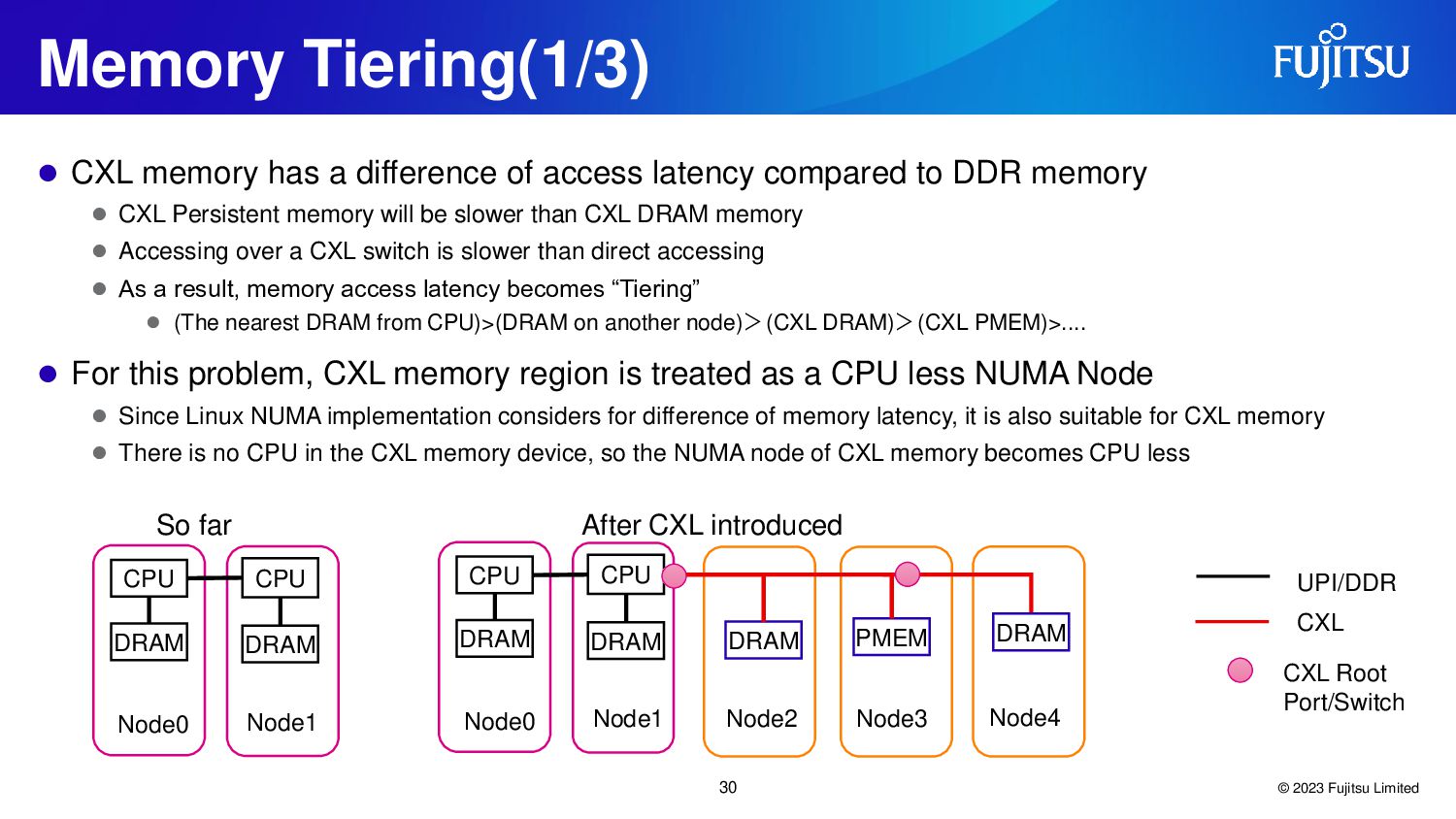{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
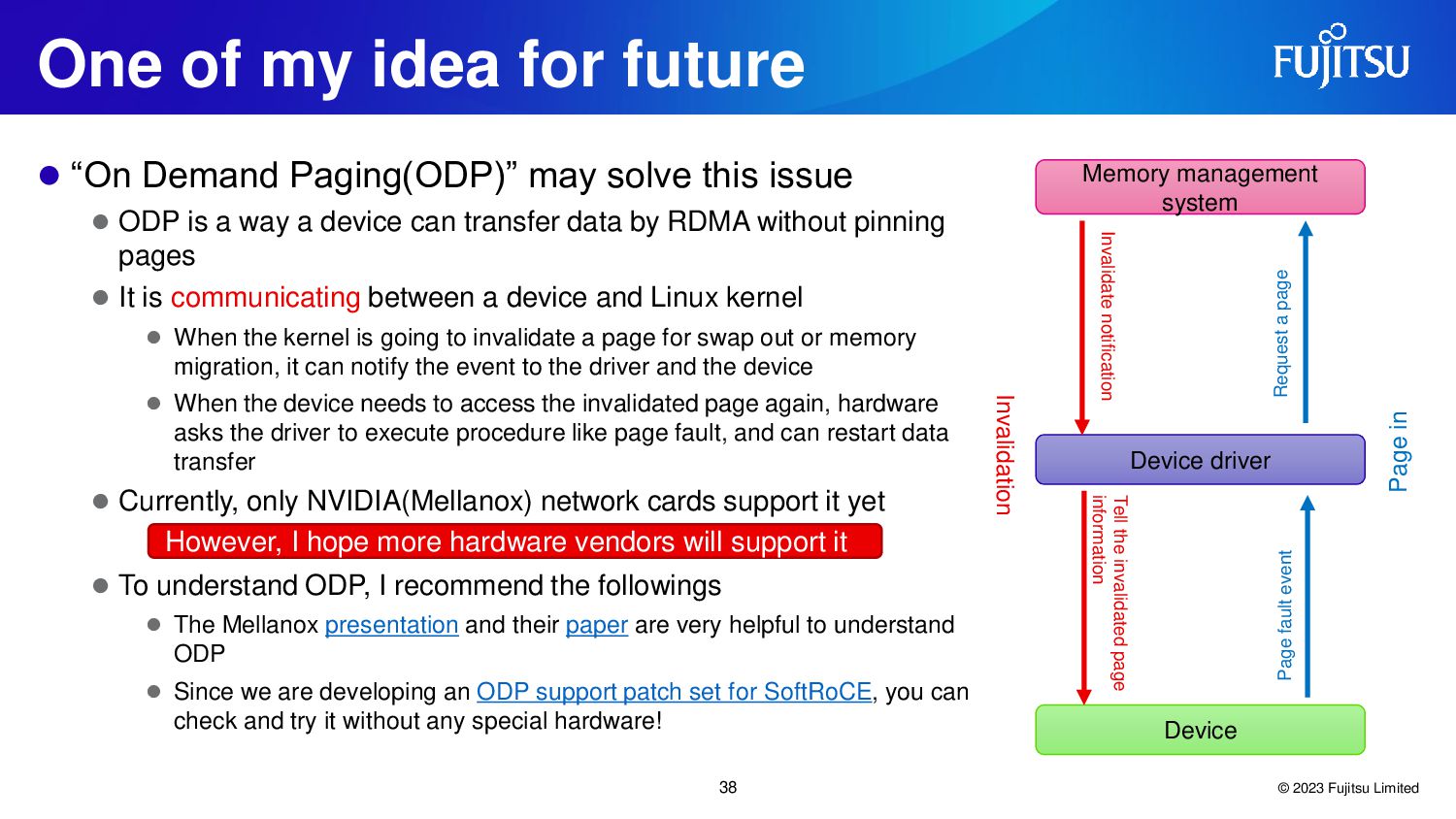{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}