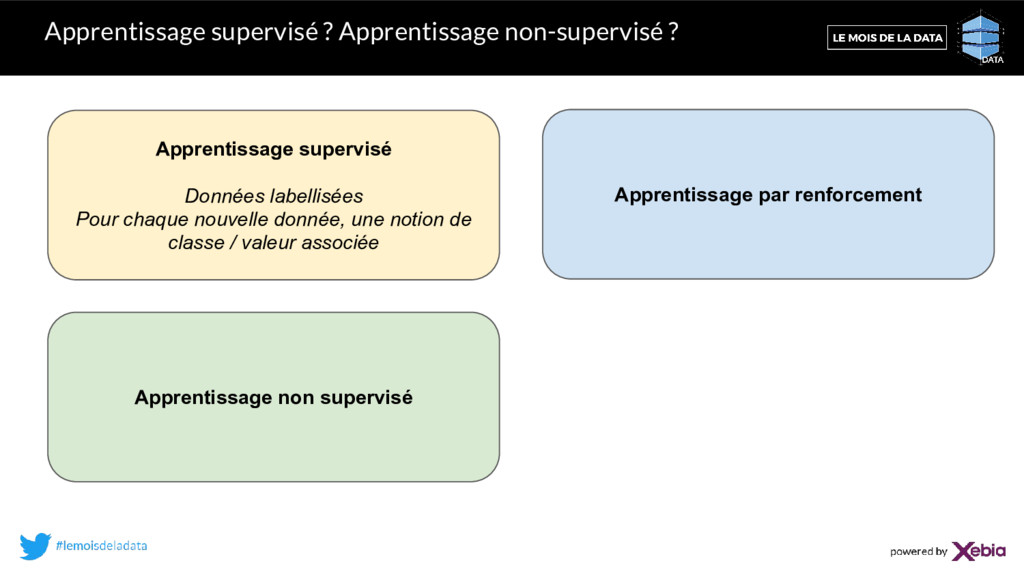
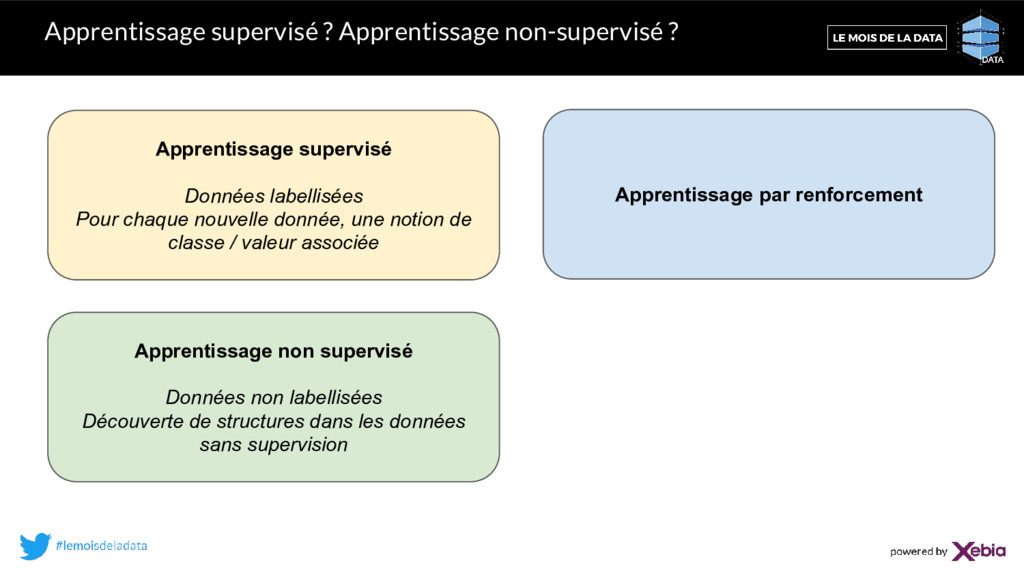
Pour chaque nouvelle donnée, une notion de classe / valeur associée Apprentissage non supervisé Données non labellisées Découverte de structures dans les données sans supervision Apprentissage par renforcement
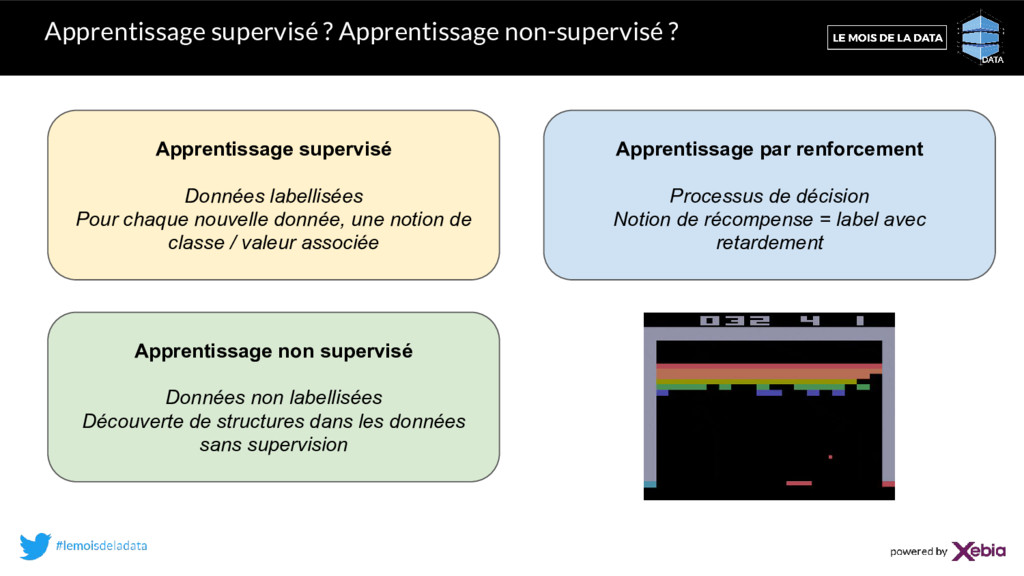
Pour chaque nouvelle donnée, une notion de classe / valeur associée Apprentissage non supervisé Données non labellisées Découverte de structures dans les données sans supervision Apprentissage par renforcement Processus de décision Notion de récompense = label avec retardement
Pour chaque nouvelle donnée, une notion de classe / valeur associée Apprentissage non supervisé Données non labellisées Découverte de structures dans les données sans supervision Apprentissage par renforcement Processus de décision Notion de récompense = label avec retardement
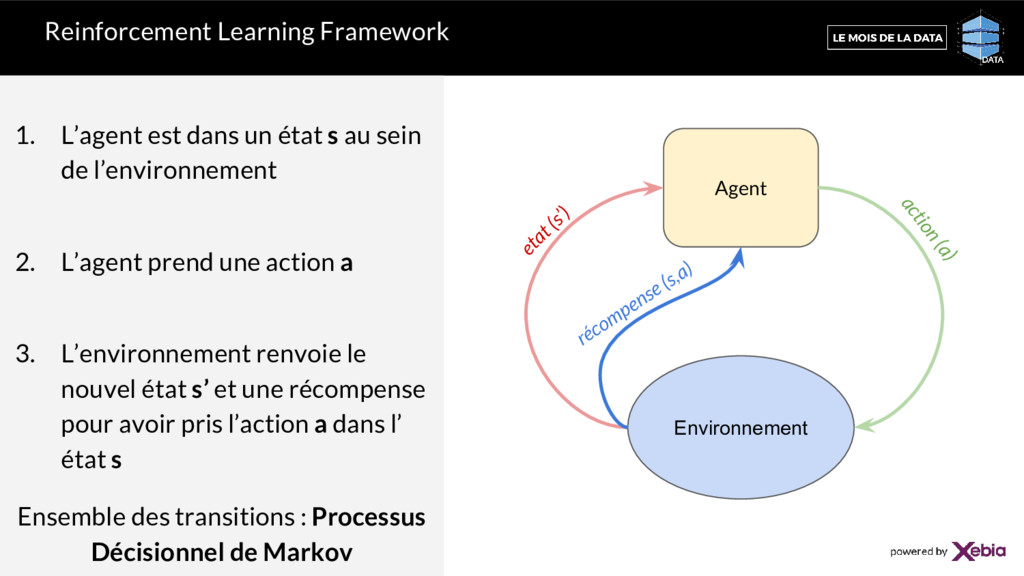
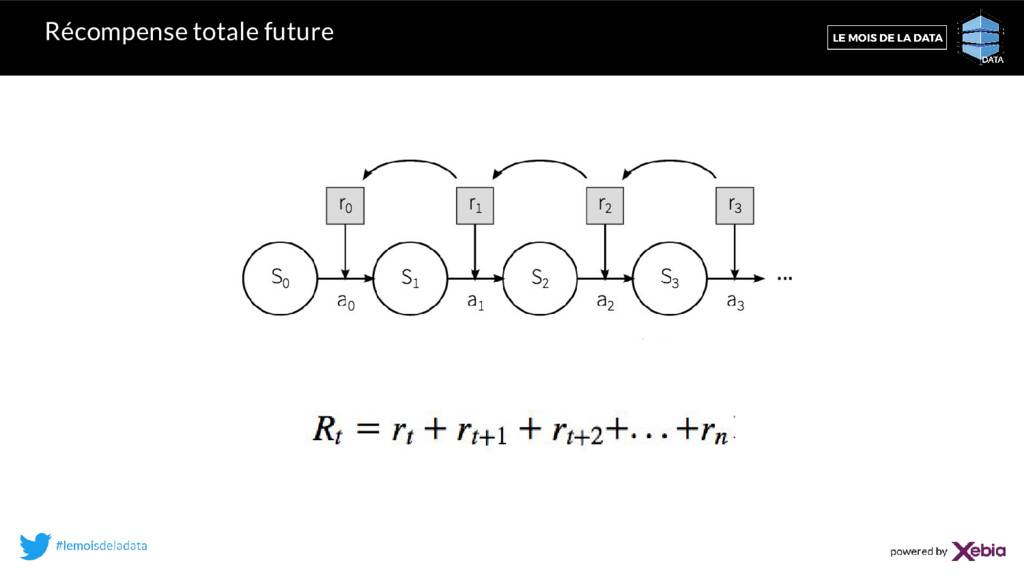
au sein de l’environnement 2. L’agent prend une action a 3. L’environnement renvoie le nouvel état s’ et une récompense pour avoir pris l’action a dans l’ état s Ensemble des transitions : Processus Décisionnel de Markov Agent Environnement etat (s’) récompense (s,a) action (a)
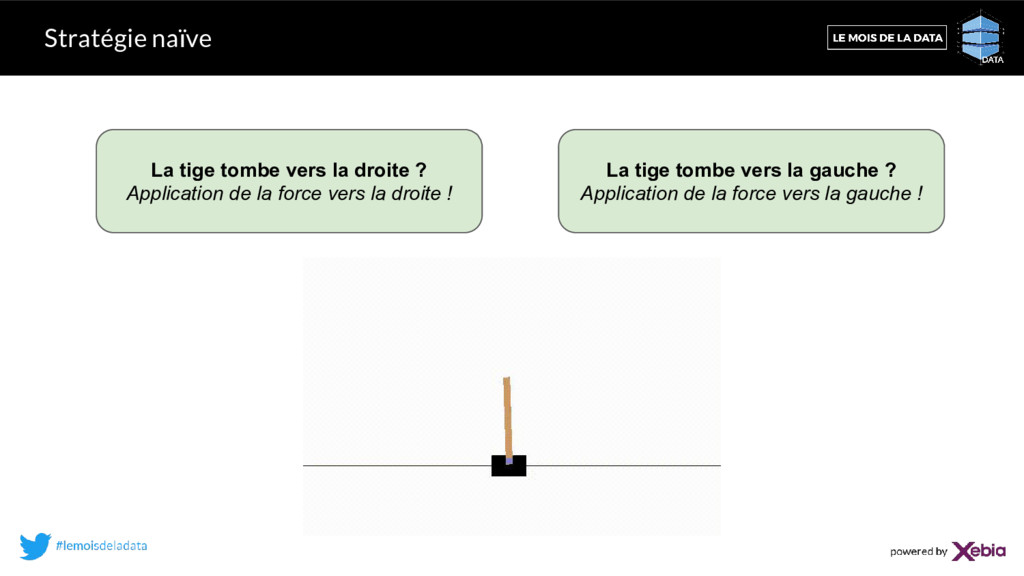
: • : distance parcourue par le chariot • ẋ: vitesse de déplacement de le chariot • : l’angle entre la tige et la verticale • : vitesse angulaire de la tige 2 actions possibles : • Aller vers la droite: F • Aller vers la gauche: -F Échec si: • x >2.4 unité du centre ou x<-2.4 • > 15° par rapport à la verticale .
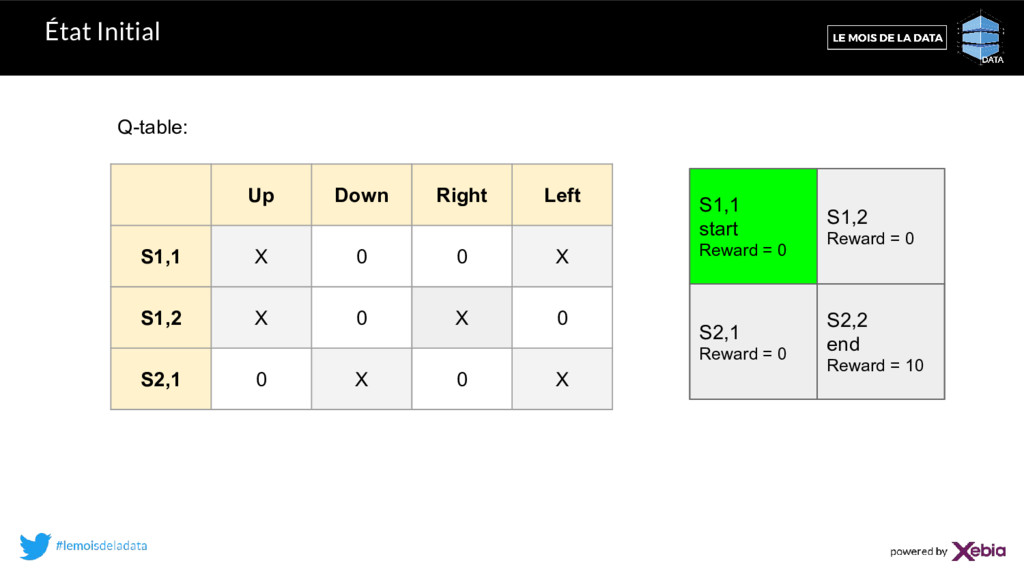
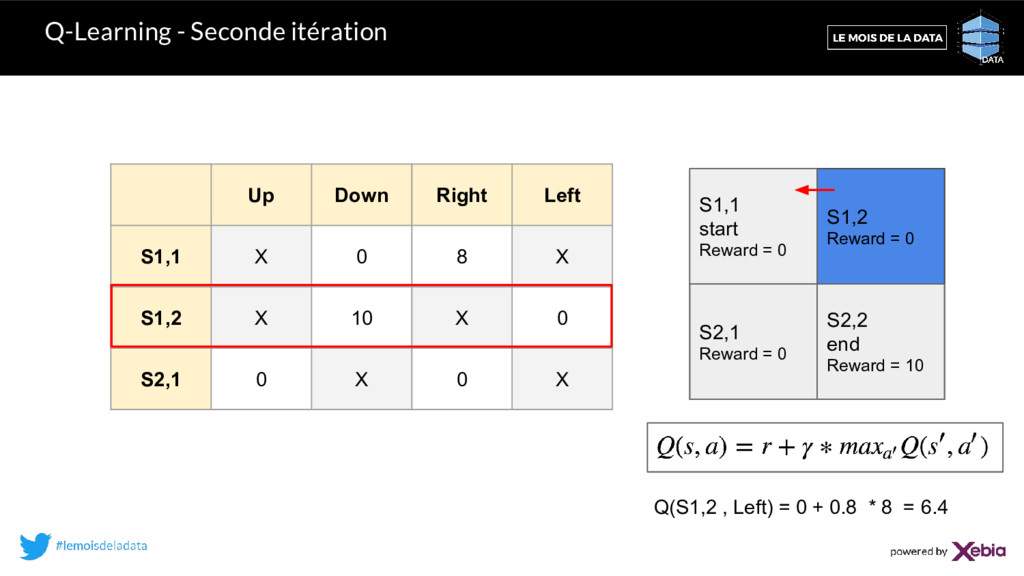
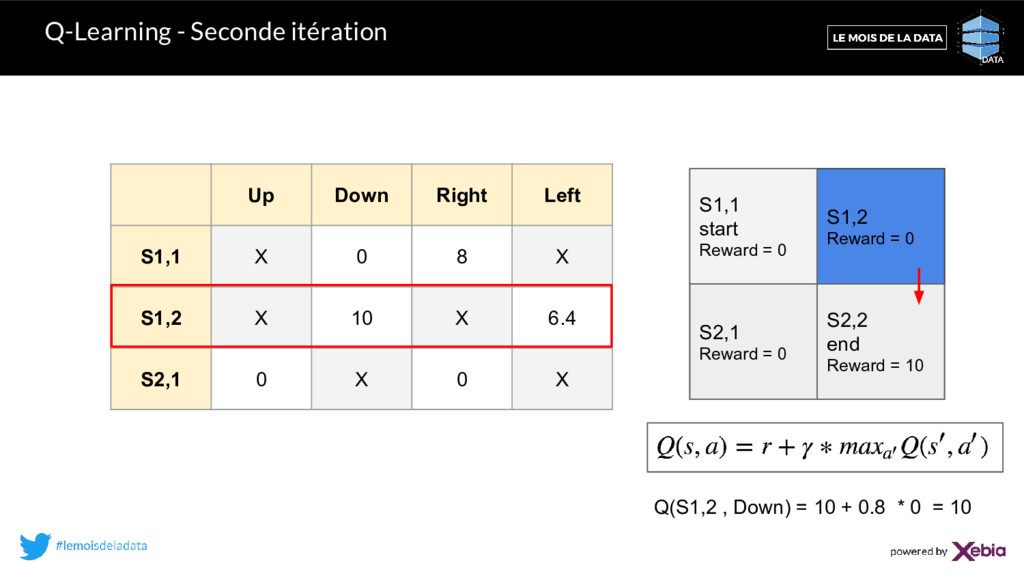
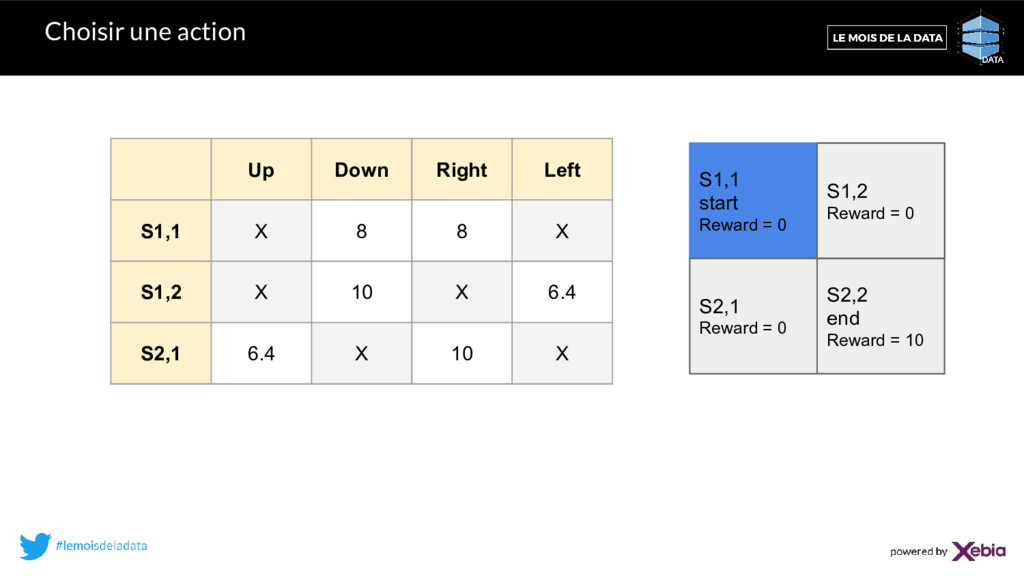
8 X S1,2 X 10 X 6.4 S2,1 0 X 0 X S1,1 start Reward = 0 S1,2 Reward = 0 S2,1 Reward = 0 S2,2 end Reward = 10 tirage = un nombre aléatoire entre 0 et 1. Si (tirage < ) alors action aléatoire Sinon action ayant la Q-value maximale. Stratégie -greedy
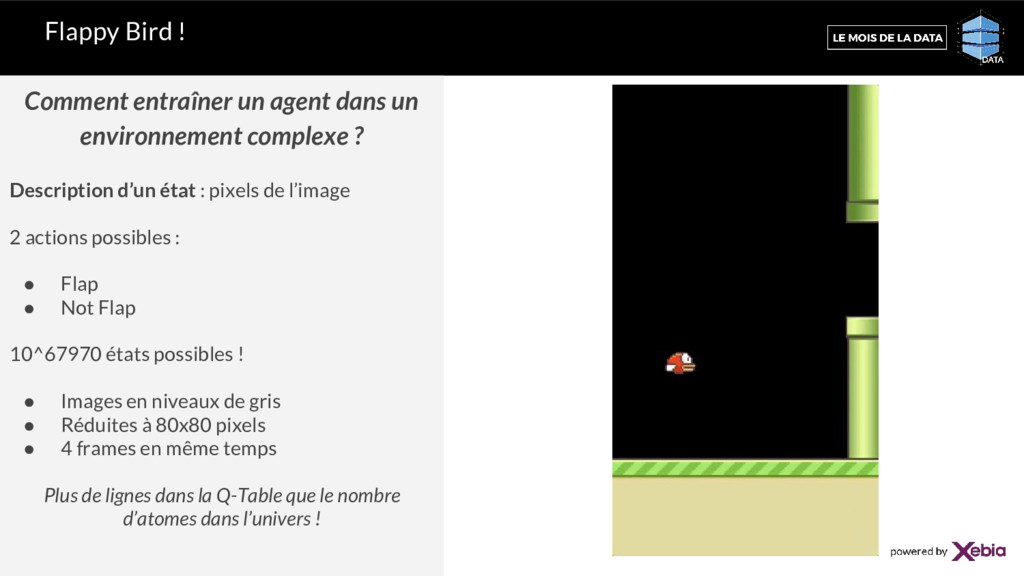
complexe ? Description d’un état : pixels de l’image 2 actions possibles : • Flap • Not Flap 10^67970 états possibles ! • Images en niveaux de gris • Réduites à 80x80 pixels • 4 frames en même temps Plus de lignes dans la Q-Table que le nombre d’atomes dans l’univers !
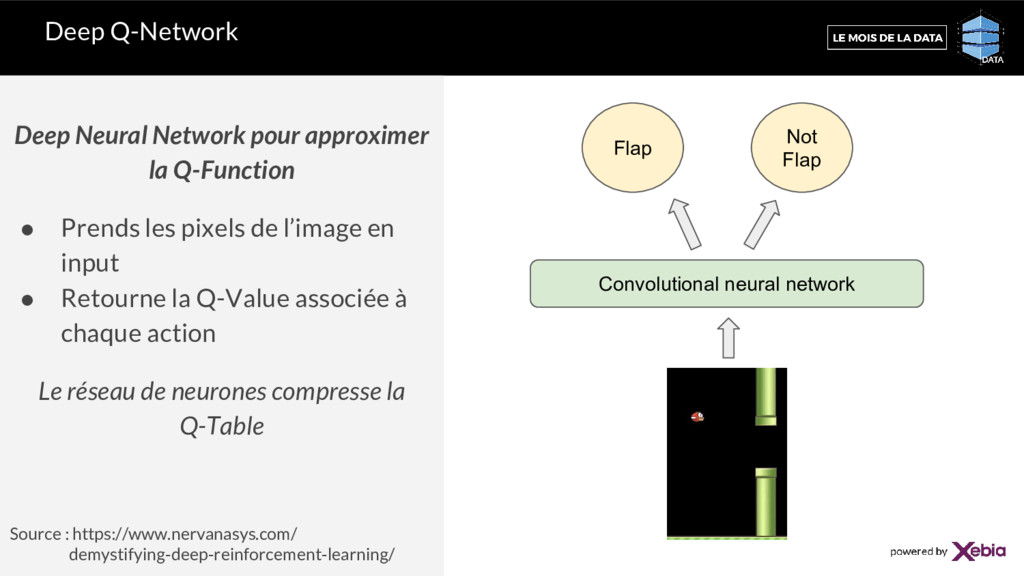
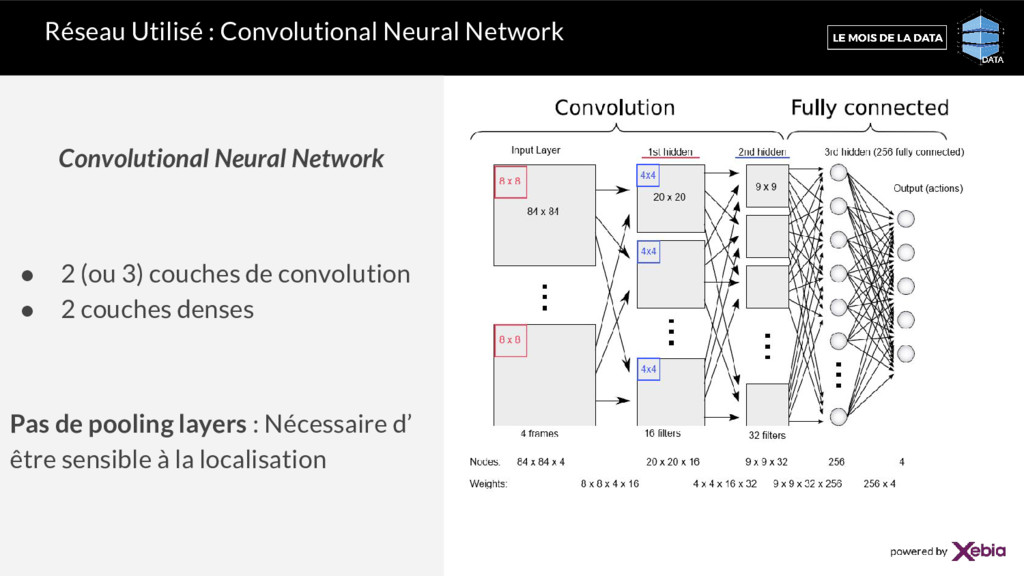
Prends les pixels de l’image en input • Retourne la Q-Value associée à chaque action Le réseau de neurones compresse la Q-Table Source : https://www.nervanasys.com/ demystifying-deep-reinforcement-learning/ Convolutional neural network Not Flap Flap
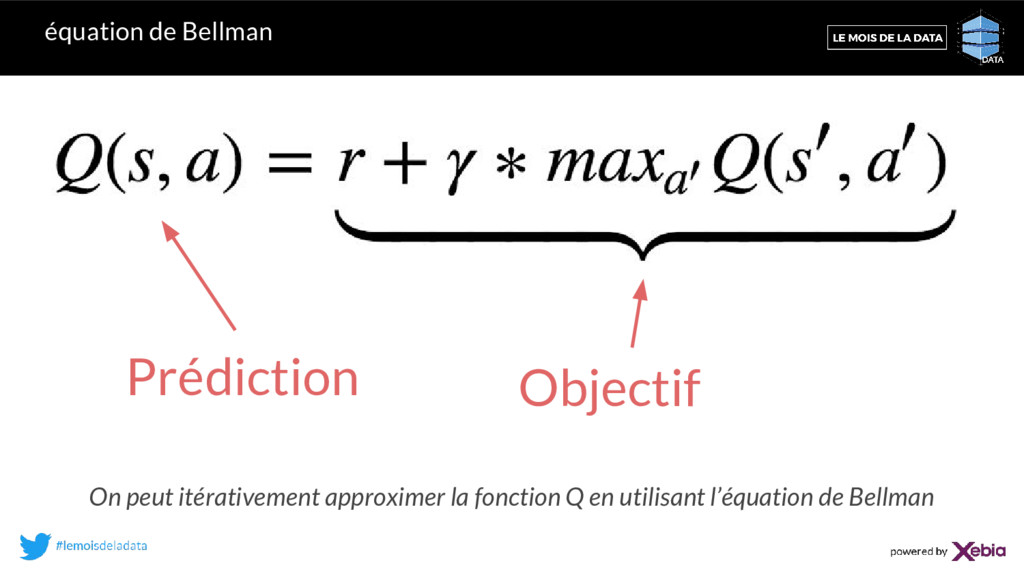
a, r, s’> : 1. Inférence pour l’état courant s 2. Inférence pour le nouvel état s’ 3. Mise à jour de la Q-Value cible pour l’action a via l’équation de Bellman Q-Value laissée à l’identique pour les autres actions 4. Mise à jour des poids via la backpropagation Q-Values state s state s’
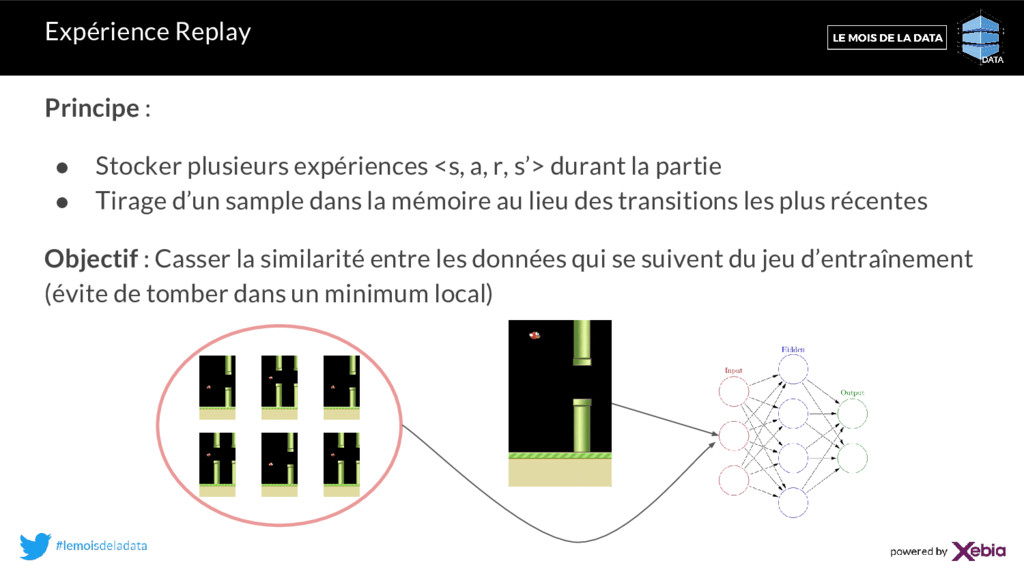
r, s’> durant la partie • Tirage d’un sample dans la mémoire au lieu des transitions les plus récentes Objectif : Casser la similarité entre les données qui se suivent du jeu d’entraînement (évite de tomber dans un minimum local)
la récompense finale espérée ? Exploration ε-greedy : • Action aléatoirement avec une probabilité ε, sinon meilleure solution calculée • Décroître ε avec le temps alors que la Q-function converge Flap Not Flap p = 0.12 p = 0.88
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![#BeXebian [email protected]](https://files.speakerdeck.com/presentations/2e8253c383844158b0f723ec6eacee5c/slide_66.jpg){kind=link}