TensorFlow, malgré sa grande popularité, a souvent été perçu comme un framework relativement bas niveau pour le Deep Learning, et compliqué à appréhender et débogguer notamment avec son concept de graphe. Mais c'est maintenant de l'histoire ancienne grâce à ses récentes APIs haut niveau.
Nous allons parcourir ensemble ces APIs haut niveau que sont tf.data, tf.keras, les Estimators ainsi que le mode d'exécution impératif (eager mode), et vous verrez que vous ne pourrez plus vous en passer !
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
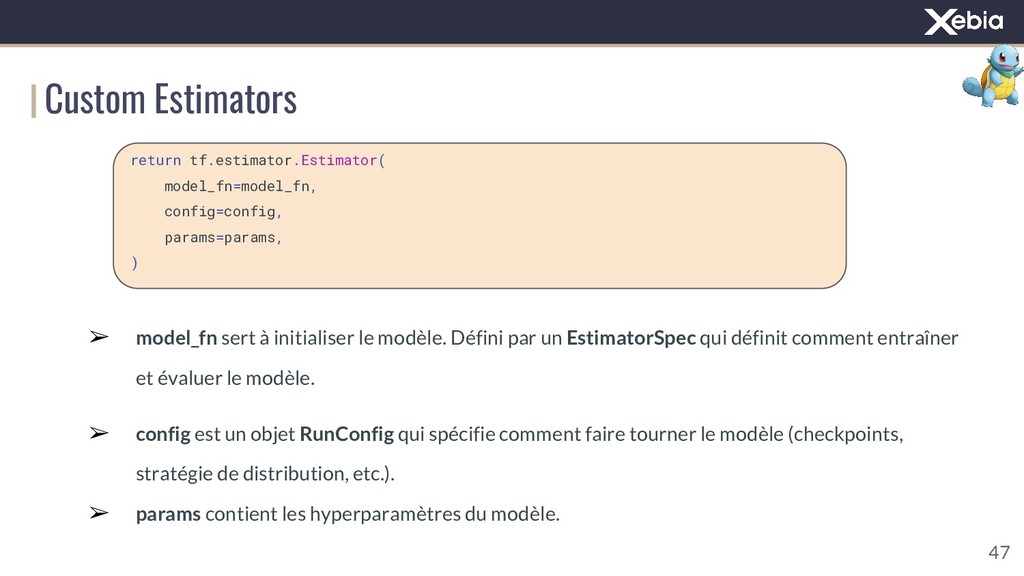{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
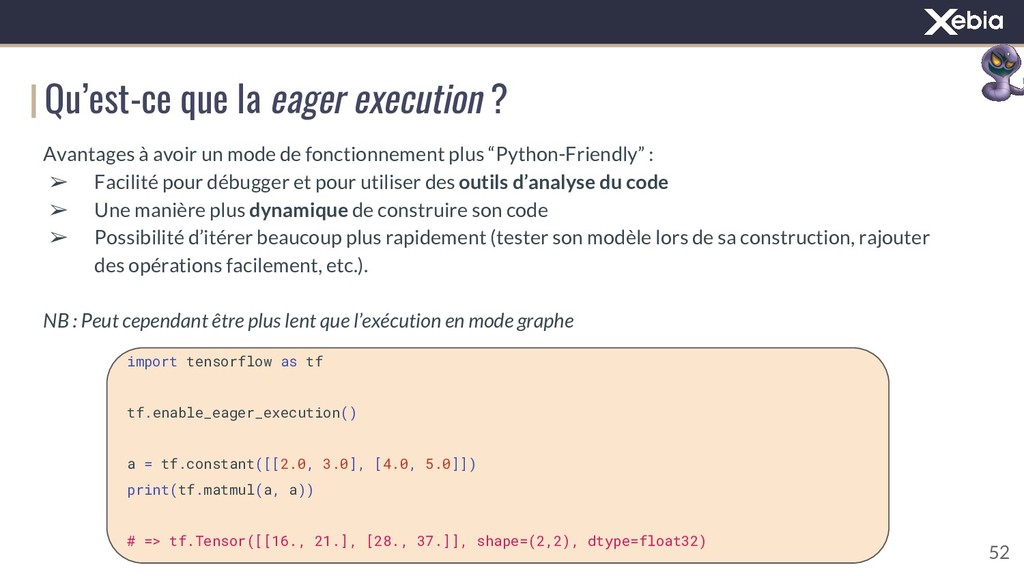{kind=link}
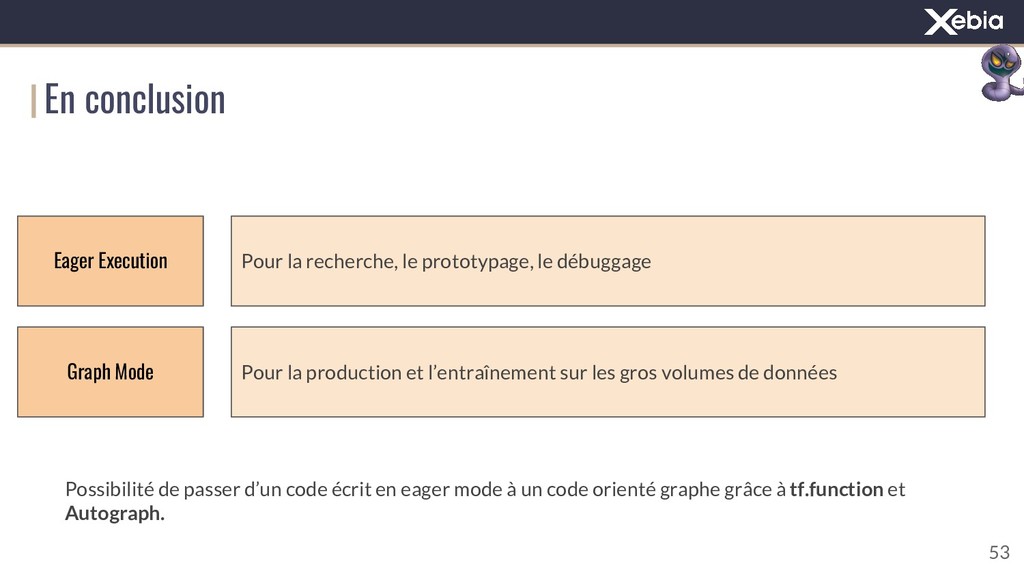{kind=link}
{kind=link}
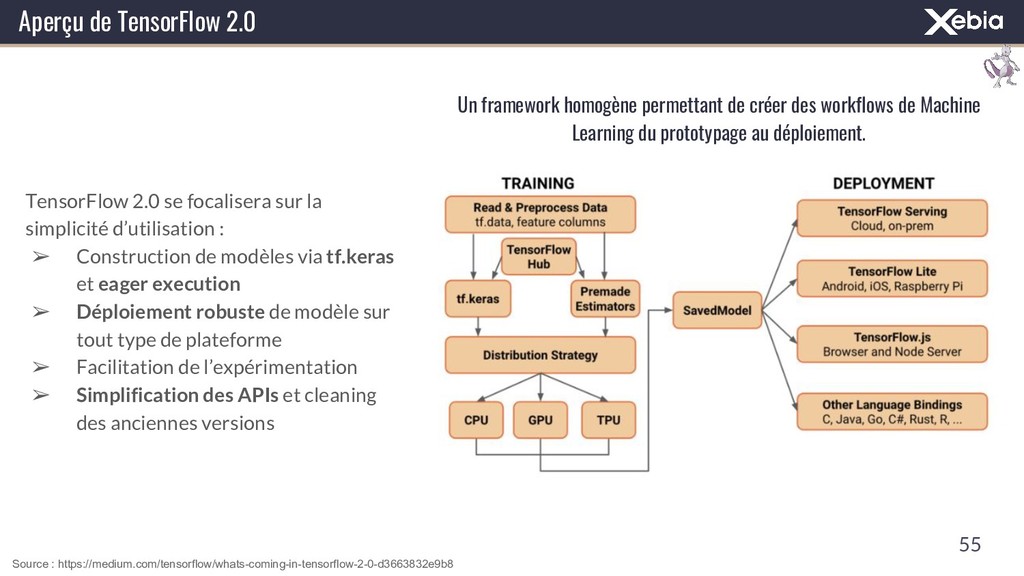{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}