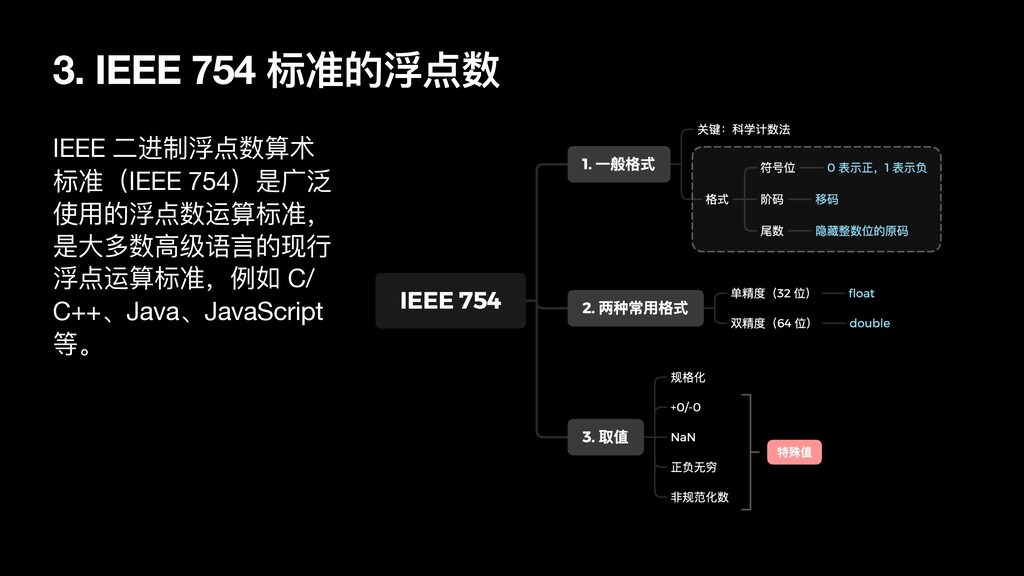
为特殊值,具体如下: • ⾮规范化数(Denormalized Number) 定义:指数域全 0,尾数域不为 0(去掉隐含整数域为 1 的约定) 意义:可以保存绝对值更⼩的数,所有可表示的浮点数的差值都可以表示 • +0/-0 定义:指数域全 0,尾数域全 0(去掉隐含整数域为 1 的约定)。IEEE 754 未要求具体的尾数域,意味着 NaN 不是⼀个⽽是⼀族。 意义:符号位为 0 是 +0,符号位为 1 是 -0,在涉及⽆穷的运算中避免丢失符号信息,例如 ,如果 0 不区分正负,在 时不成⽴ • 正负⽆穷(Infinity) 定义:指数域全 1,尾数全 0 意义:⽤于表达计算中产⽣的上溢(overflow),使得计算中出现上溢不⾄于终⽌计算 产⽣:除了 NaN 外的⾮零值除以 0,其结果为正负⽆穷 • NaN(Not a Number) 定义:指数域全 1,尾数域不为 0 意义:表示计算中的错误情况,例如 、 ,使得计算中出现错误不⾄于终⽌计算 特点:NaN 是⽆序的,⽐较操作符在任⼀操作数为 NaN 是为 false,!= 在任⼀操作数为 NaN 时为 true,这意味着 NaN != NaN。 1 1/x = x x = ± ∞ 0.0 0.0 −2
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![2.1 n 位⼆进制可以表示的信息量 对于整数来说,⼤家都知道 8 位有符号整数可以表示 [-128,127] ,8 位⽆符号整数 可以表示](https://files.speakerdeck.com/presentations/c83a17a1a6ea4c0097a9b8e7a455148c/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}