Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
堅牢な留守電 検出システムの構築
Search
森本タカヒロ
August 31, 2025
0
25
堅牢な留守電 検出システムの構築
wav2vec2を使用した留守電検知モデルを作成しました。
トレーニングデータは自社データを活用しています。
2025/08/30に行われた「ML 15min」の登壇資料です。
森本タカヒロ
August 31, 2025
Tweet
Share
More Decks by 森本タカヒロ
See All by 森本タカヒロ
nocall株式会社 採用プレゼン資料(2025/07更新)
1mono2prod
0
150
実践! AIエージェント導入記
1mono2prod
0
420
AIネイティブスタートアップが実践するAI駆動開発
1mono2prod
0
1.4k
Featured
See All Featured
How to Grow Your eCommerce with AI & Automation
katarinadahlin
PRO
1
110
The Language of Interfaces
destraynor
162
26k
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
96
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
53
Abbi's Birthday
coloredviolet
1
4.8k
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
1.7k
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
0
160
The Limits of Empathy - UXLibs8
cassininazir
1
220
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.6k
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
196
71k
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
SEO for Brand Visibility & Recognition
aleyda
0
4.2k
Transcript
nocall.aiによる 堅牢な留守電 検出システムの構築 nocall株式会社 CTO 森本タカヒロ
自己紹介 森本 尊礼 Morimoto Takahiro 経歴 明治大学商学部卒。ベイズ統計を中心とした機械学習研究に従事。ColBERTの 日本語評価に関する論文を執筆 個人開発者としてハイパーカジュアルゲームを開発。1年間で8本のカジュアル ゲームを開発・リリース
2023年10月よりnocall.aiにCTOとして参画し、2ヶ月でnocall.aiをリリース 現在はプロダクトマネージャー兼エンジニアとして開発をリードし、自然な会 話が可能なAI電話ソリューションの開発に注力 前職は女装コンカフェ嬢 SNS 取締役CTO nocall株式会社 @1MoNo2Prod
None
None
→自分たちでより精度の高い解決策を開発する必要性 背景・課題 Twilioの自動判定機能の精度 ❌ デフォルトで60%程度の精度 AI架電では 「リアルタイムの留守電検出」が 大きな課題 課題の本質 「人間か?留守電か?」の素早い
判定がの鍵 文字起こし→LLMによる判定は 高コスト。リアルタイム性にも 欠ける 会話中に判断して、留守電だったら 専用メッセージを吹き込みたい
留守電サンプル 対話型音声応答 (IVR) 人間と区別のつかない合成音声 実際の人間の声の留守電 これらを実際の人間による応答と区 別することが難しい
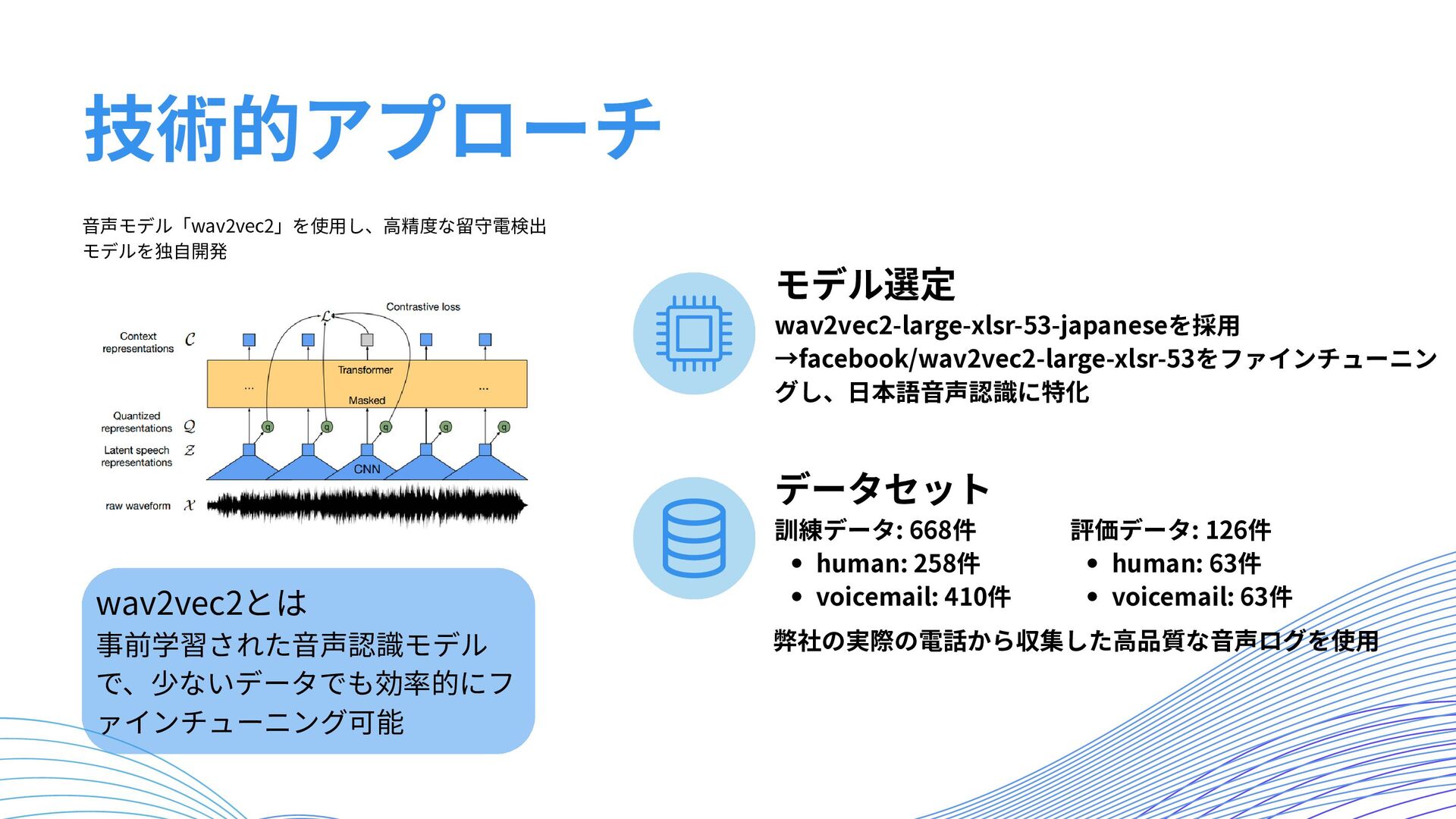
技術的アプローチ モデル選定 wav2vec2-large-xlsr-53-japaneseを採用 →facebook/wav2vec2-large-xlsr-53をファインチューニン グし、日本語音声認識に特化 データセット 訓練データ: 668件 human: 258件
voicemail: 410件 評価データ: 126件 human: 63件 voicemail: 63件 弊社の実際の電話から収集した高品質な音声ログを使用 音声モデル「wav2vec2」を使用し、高精度な留守電検出 モデルを独自開発 wav2vec2とは 事前学習された音声認識モデル で、少ないデータでも効率的にフ ァインチューニング可能
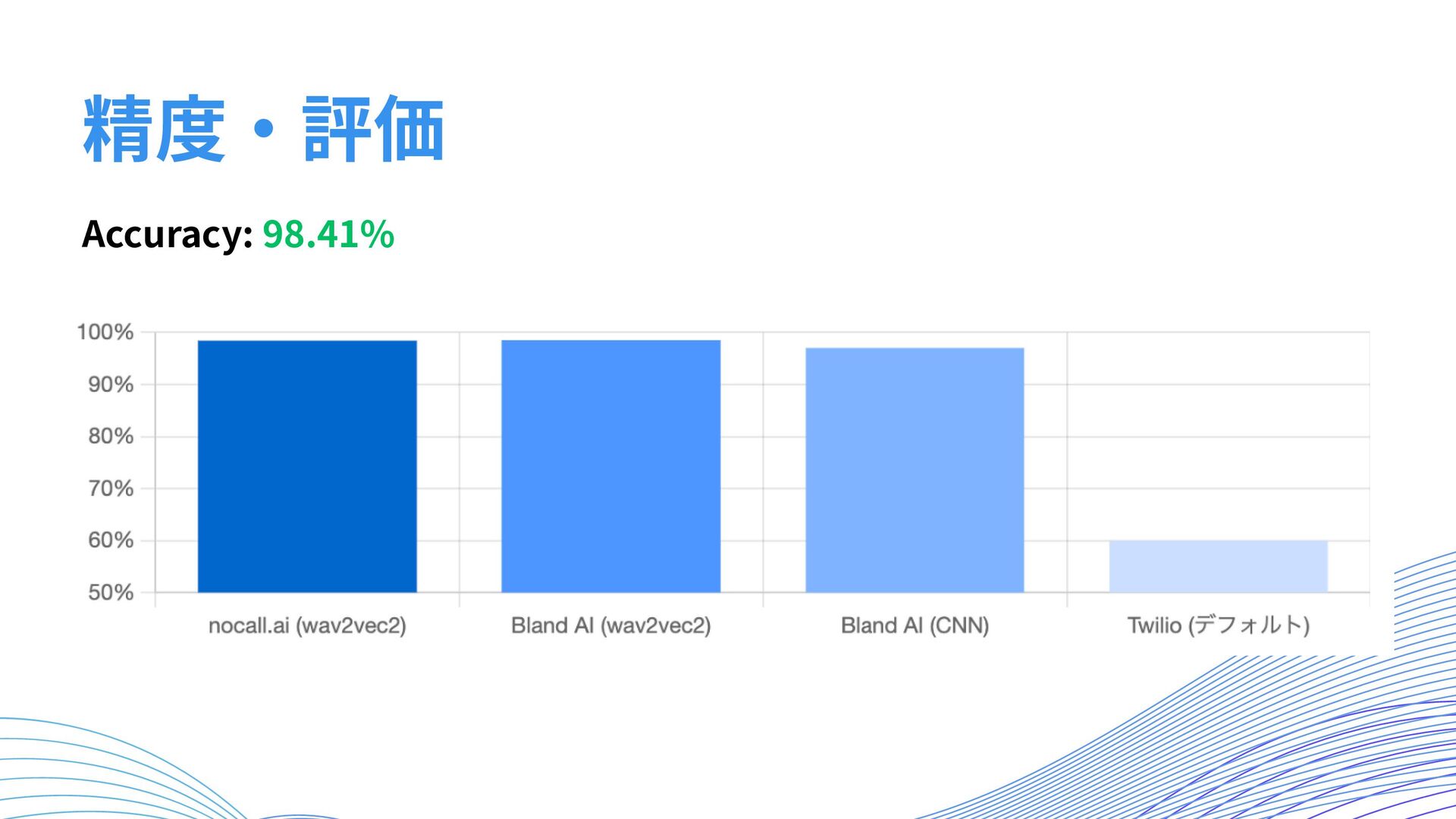
Accuracy: 98.41% 精度・評価
実際の音声サンプルとモデルに よる判定をデモしてみます デモ・実例
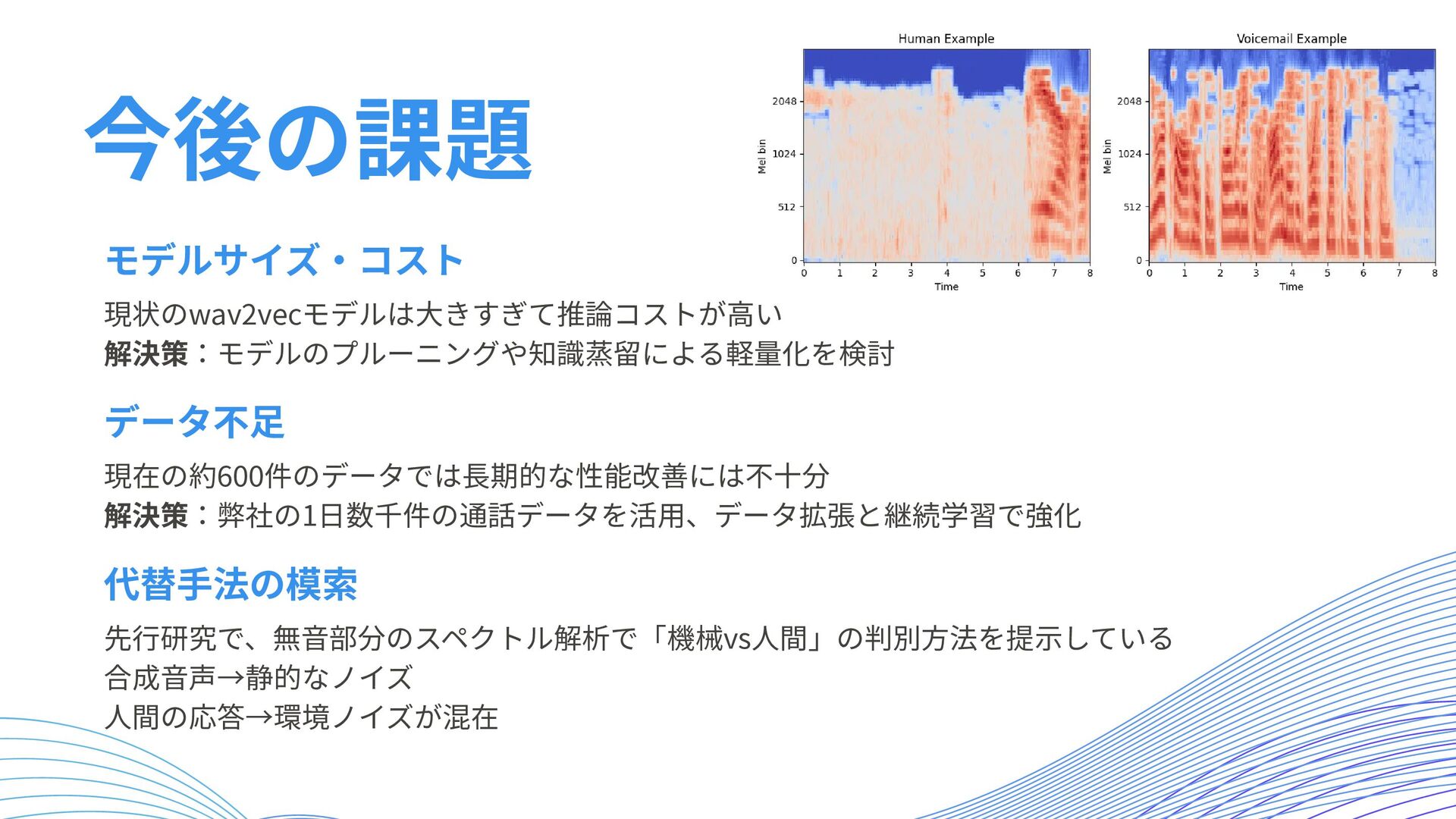
今後の課題 現状のwav2vecモデルは大きすぎて推論コストが高い 解決策:モデルのプルーニングや知識蒸留による軽量化を検討 モデルサイズ・コスト 先行研究で、無音部分のスペクトル解析で「機械vs人間」の判別方法を提示している 合成音声→静的なノイズ 人間の応答→環境ノイズが混在 代替手法の模索 現在の約600件のデータでは長期的な性能改善には不十分 解決策:弊社の1日数千件の通話データを活用、データ拡張と継続学習で強化
データ不足
03 コンピューターと 人間が 会話する未来を作る 会話
03 ヒューマノイドにキーボードで タイピングして指示を出す未来はありえない 人と同じ形を持つ存在に対しては、 自然な会話で指示を出すのが当たり前になるはずです。 そこで私たちが目指しているのは、 チューリングテストを突破するほど自然な音声会話モデル ローカルデバイスで動作するほど小さなモデル これが実現すれば、インターネット接続に依存せず、 低レイテンシーでリアルタイムに会話が可能になります。
私たちは、 「人と機械が自然に会話する未来」をつくっていきます。
MoshiやSesameを超えたくないですか?
採用 Typescript / Next.js / node.js フルスタックエンジニア Speech-to-Text / LLM
/ 合成音声 / E2E 機械学習エンジニア
ポッドキャスト
@1MoNo2Prod
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}