around lucene great community clients available for all sane languages elastic team is biggest contributor to lucene by couple of past years worth learning at least in terms of DB arhitecture
atomicity per document is guaranteed ES uses WAL for all writes optimistic concurrency control by versions [1] [2] on-side scripting support global, document-level, tree locking durability is managable (OOM, split-brain)
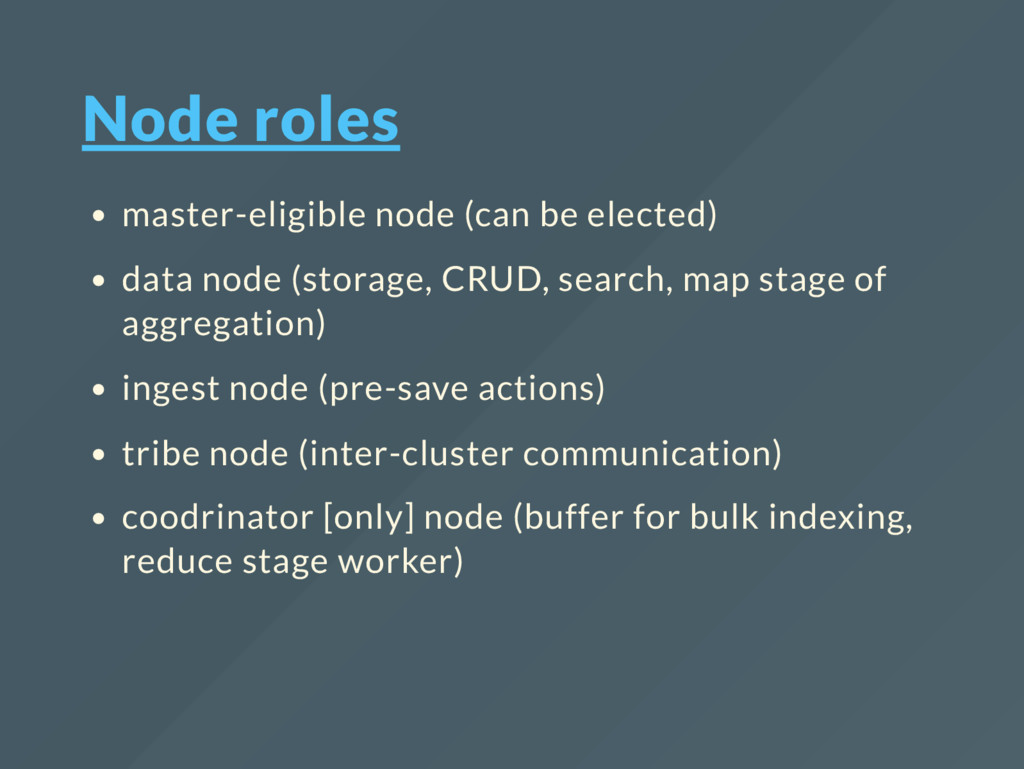
replicas (sync for all shards) replica is never allocated to same node as primary shard replicas is basically slave in master-slave replication schema searches/aggregations hits replicas each shard is lucene index should be planned ahead
shards being rebalanced to new nodes shards being synced via WAL to recovered nodes All rebalance and recovery is automatic (still controllable tho) Transport inside cluster in non-blocking
ketama-like distribution. Default seed is _id you can manually route document by providing external _routing parent-child relations restricts routing - child docs must be routed to the same shard as parent
indexed documents are being added to im- memory segment in-memory segment are being ushed to disk after reaching buffer or time limit on-disk segments being merged after reaching threshold updates held in separate index, merged with normal ones in merge stage
leads to less stress of CPU and GC updates and deletes are heavy - both in terms of search and segment merge segment merge can be forced being big part of performance, this should be monitored and tuned appropriately. Generic JVM heap + GC tuning is way to go
and requires mapping to index docs mapping can be created and altered on the y mapping can be changed in case of backward- compatible changes adding new elds is cheap
as schema-intensive. don't run by the rake-road, use explicit mapping dynamic mapping creation can be controlled dynamic eld mapping can be ~ controlled automatic index creation can be controlled
"hidden" separate docs, accessible via parent tricky to work with if you need nested-only heavy on updates, yweight on retrieve Parent-child sometimes tricky to retrieve easy on update, heavier on CPU
multi- elds - different processing for same data intensive caching with awesome invalidation custom aggregation pipelines hadoop connector stored procedures / scripting
get hands on doc values [1] [2] Basically, this is column-storage for non-analyzed data, which makes aggregations and range queries really fast. This is default storage approach starting with version 5. Can be disabled anytime, being set per eld
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ES & CAP [highly] available partition-tolerant eventually consistent C <>](https://files.speakerdeck.com/presentations/082ec50cc7f54c13a4d67c740ca4a279/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Elasticsearch is awesome [realtime] analytics engine](https://files.speakerdeck.com/presentations/082ec50cc7f54c13a4d67c740ca4a279/slide_21.jpg){kind=link}
![Indexing [optimizations] inverted index radix trees b-k-d trees offset +](https://files.speakerdeck.com/presentations/082ec50cc7f54c13a4d67c740ca4a279/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}