It is estimated that more than 80% of today’s data is stored in unstructured form (e.g., text, audio, video) and much of its content is expressed in rich and ambiguous natural language. Traditionally, the analysis of natural language has prompted the use of qualitative data analysis approaches, such as, manual coding. Yet, the size of textual datasets available from online social networks like Twitter or rating platforms (e.g., Tripadvisor, Yelp, Amazon) exceeds the information processing capacities of human analysts. One approach to overcome these limitations is the use of text mining techniques to (semi-)automatically extract implicit, previously unknown, and potentially useful knowledge from large amounts of unstructured textual data. Although text mining and related natural language processing techniques only scratch the surface of the meaning of natural language, they have proven to be reliable tools when fed with sufficiently large datasets.
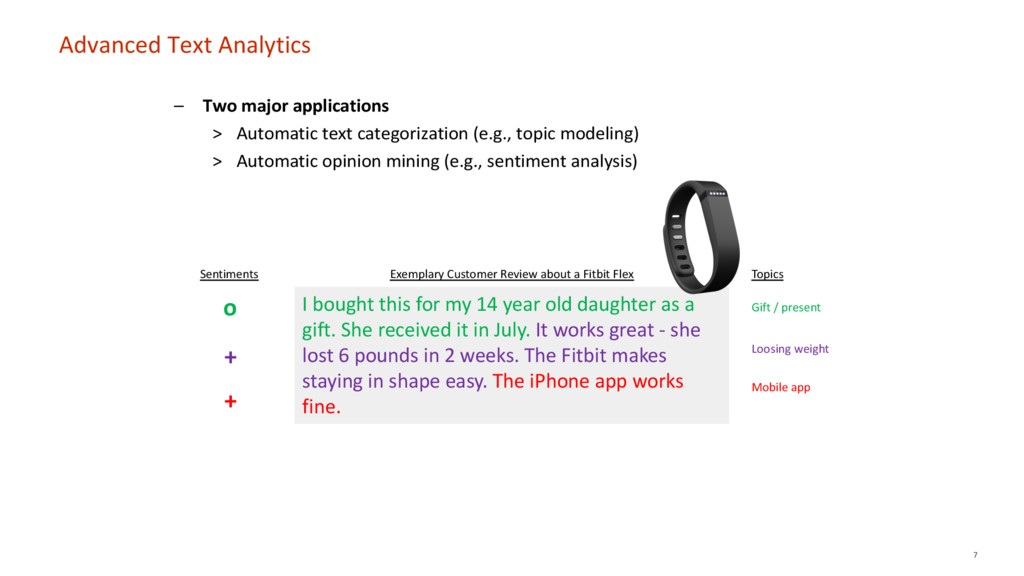
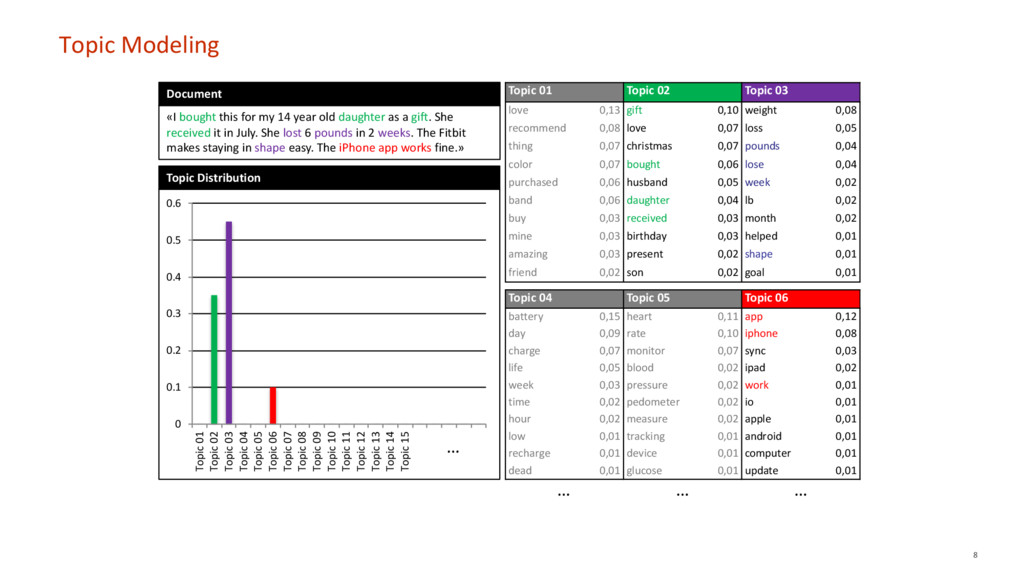
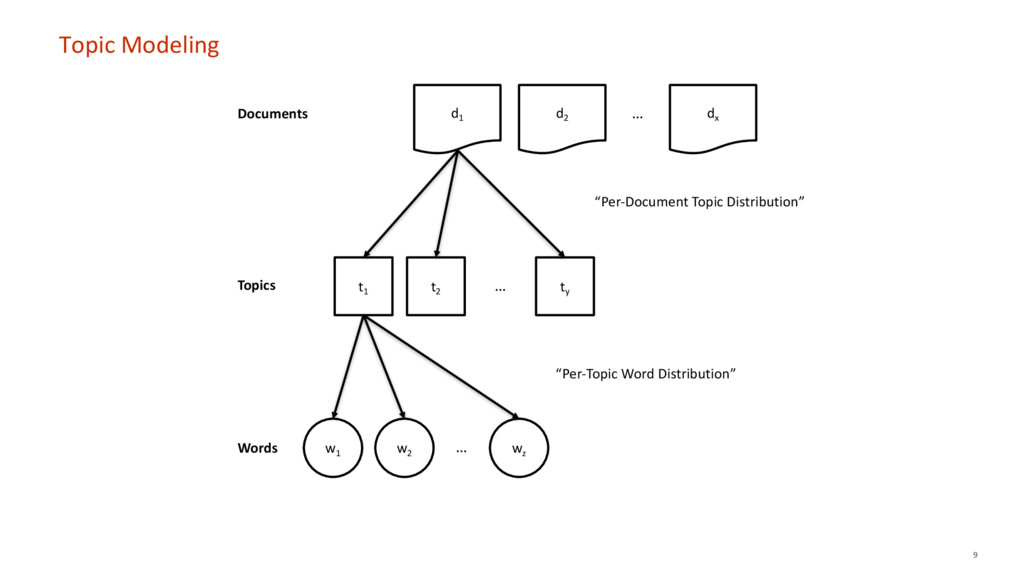
The goal of this talk is to demonstrate how to reduce the efforts needed for analyzing unstructured and textual customer feedback with topic modeling. Topic models are unsupervised machine learning algorithms for inductively discovering latent topics running through large collections of documents. Topic modeling algorithms identify topics in a purely data-driven way—neither necessitating any prior labelling of documents, the existence of predefined categorization schemes, or human input. The talk will include a live demo with real data.
Presentation given at the 4ländereck Data Science Meetup: https://www.meetup.com/4laendereck-Data-Science-Meetup/events/234041619/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![10 Sentiment Analysis I loooove [3] [+0.6 spelling emphasis] this](https://files.speakerdeck.com/presentations/9d155846fe3e467190362053ebd07c94/slide_9.jpg){kind=link}
![11 Real World Example I loooove [3] [+0.6 spelling emphasis]](https://files.speakerdeck.com/presentations/9d155846fe3e467190362053ebd07c94/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
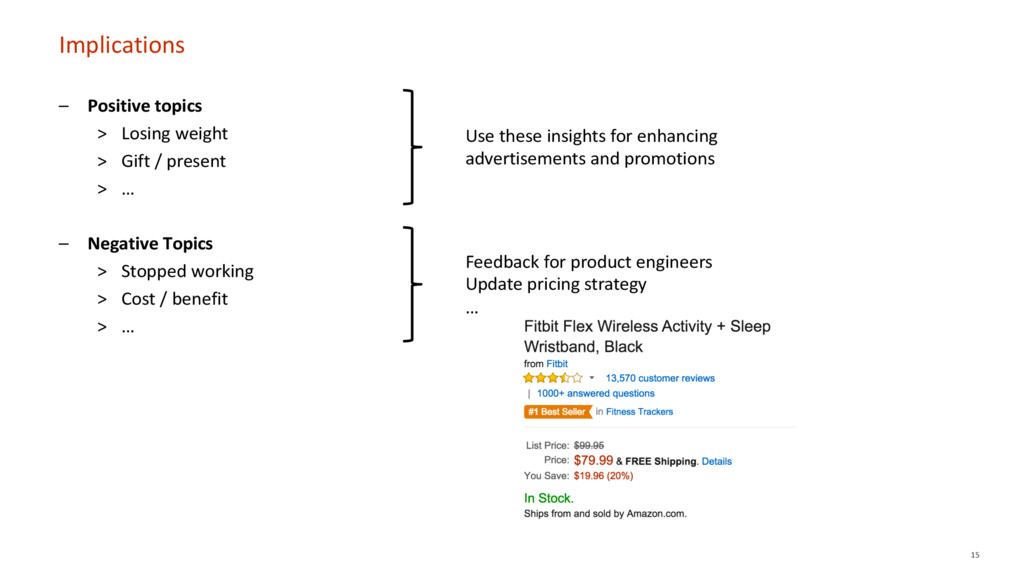{kind=link}
{kind=link}
![17 Contact Dr. Stefan Debortoli [email protected] Twitter: @sdebortoli www.MineMyText.com](https://files.speakerdeck.com/presentations/9d155846fe3e467190362053ebd07c94/slide_16.jpg){kind=link}