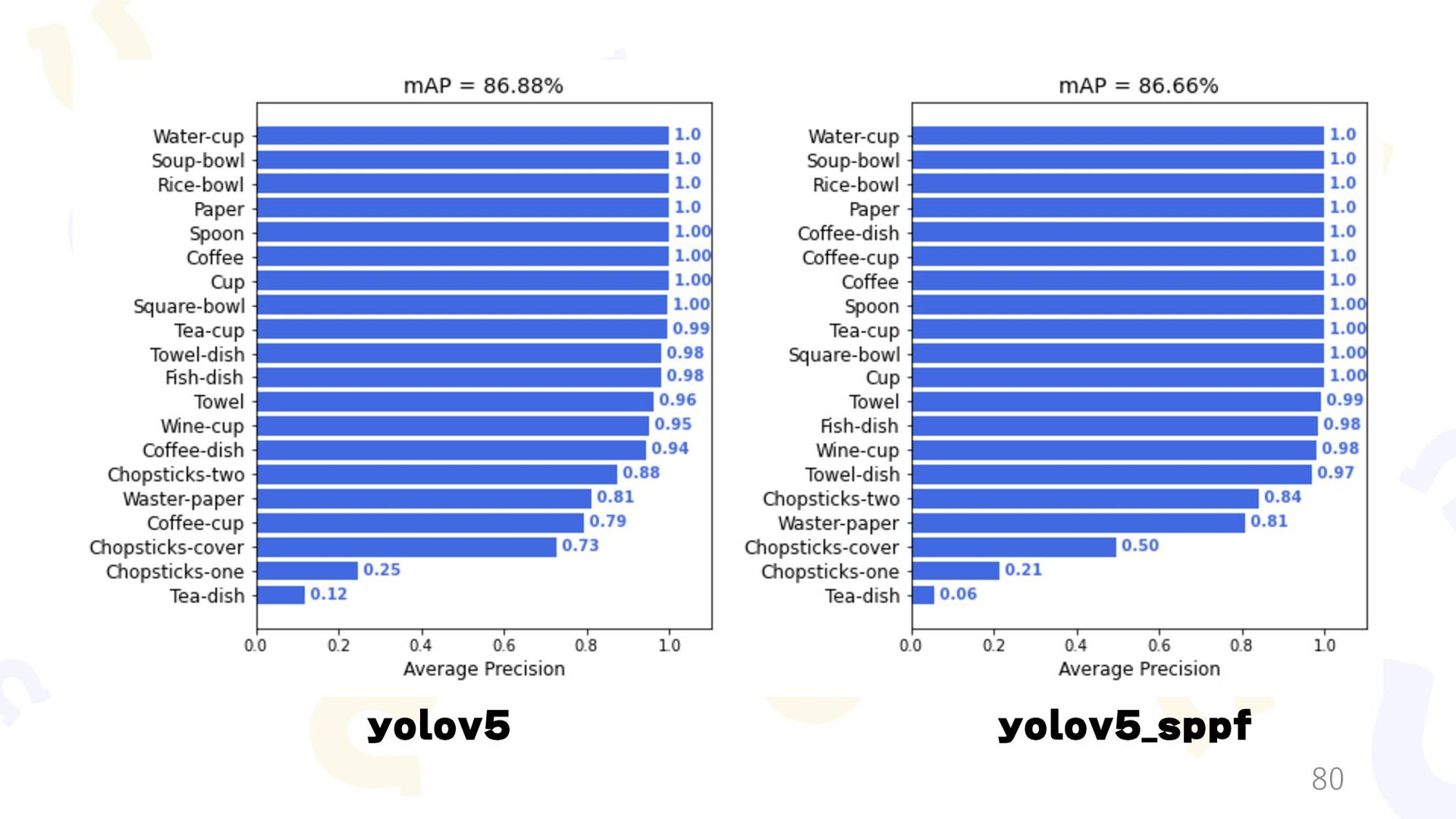
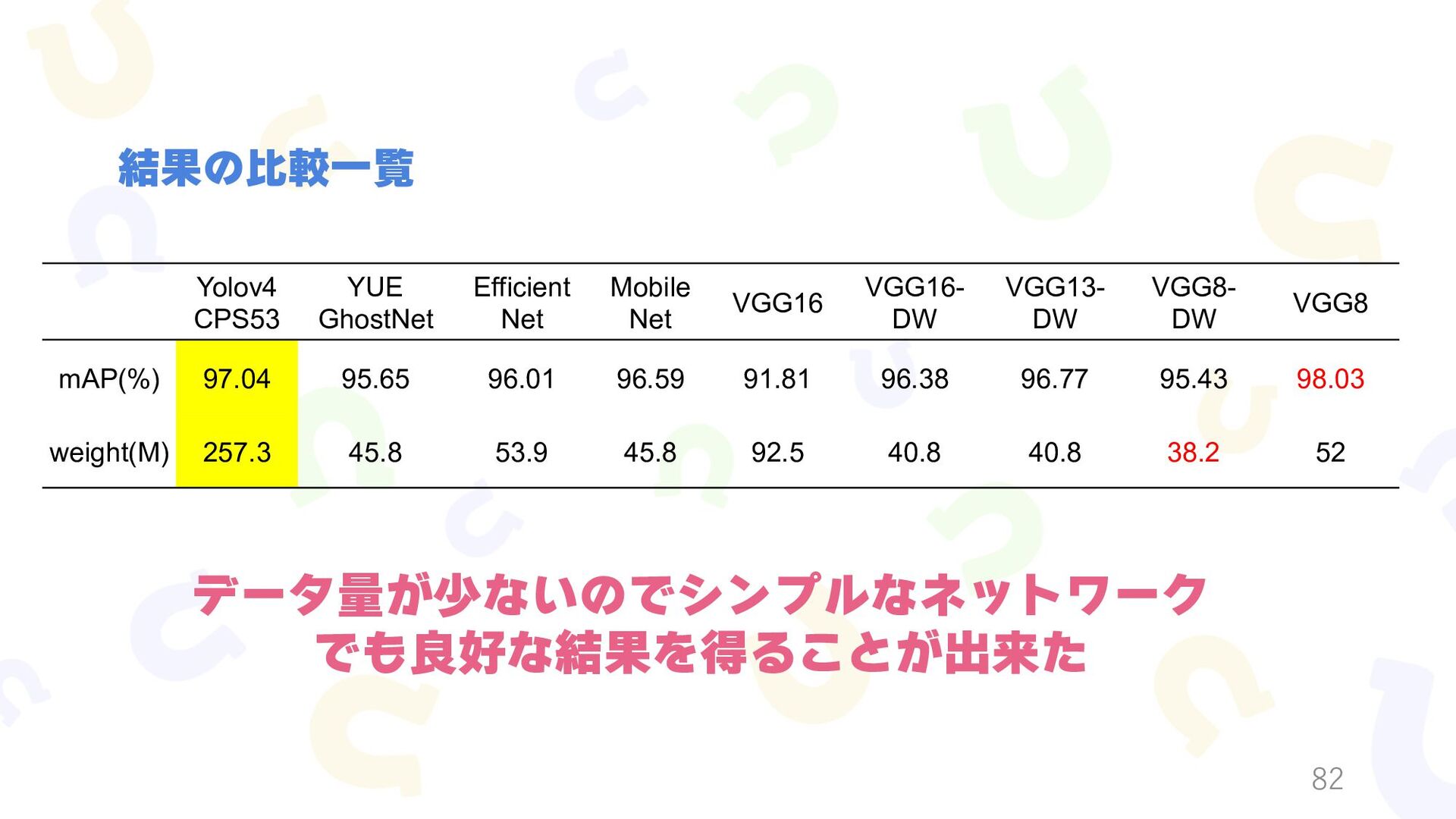
yolov7_v7backbone,mAP:93.2%,flops:0.262721614G,model_size:150.126088MB,FPS:25.20116813428497,Parameters:37.346753M, yolov7_v4CSPdarknet53,mAP:93.2%,flops:0.29979451G,model_size:202.75124MB,FPS:18.02773895714467,Parameters:50.443585M, yolov5_v5CSPdarknet,mAP:87.2%,flops:0.232378318G,model_size:154.303304MB,FPS:24.313955865774663,Parameters:38.357737M, yolov5_xCSPdarknet,mAP:85.4%,flops:0.232378318G,model_size:154.306808MB,FPS:29.451885644243497,Parameters:38.357737M, yolov5_v3darknet,mAP:86.8%,flops:0.333942734G,model_size:208.223072MB,FPS:20.756551659258147,Parameters:51.866953M, yolov5_v7backbone,mAP:86.3%,flops:0.211431374G,model_size:100.07604MB,FPS:45.17792878841556,Parameters:24.853193M, yolov5_v4CSPdarknet53,mAP:88.0%,flops:0.24784891G,model_size:152.497128MB,FPS:28.897781129573318,Parameters:37.898825M, yolov3_v5CSPdarknet,mAP:80.0%,flops:0.28694587G,model_size:193.377224MB,FPS:21.945551351170344,Parameters:48.169441M, yolov3_xCSPdarknet,mAP:74.6%,flops:0.28694587G,model_size:193.385488MB,FPS:21.715122896668202,Parameters:48.169441M, yolov3_v3darknet,mAP:77.4%,flops:0.388510286G,model_size:247.291248MB,FPS:17.55582086893424,Parameters:61.678657M, yolov3_v7backbone,mAP:72.3%,flops:0.265343566G,model_size:138.944872MB,FPS:29.82171052299465,Parameters:34.613697M, yolov3_v4CSPdarknet53,mAP:75.9%,flops:0.302416462G,model_size:191.576568MB,FPS:21.516757871989906,Parameters:47.710529M, ↓学習の監査ログです
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
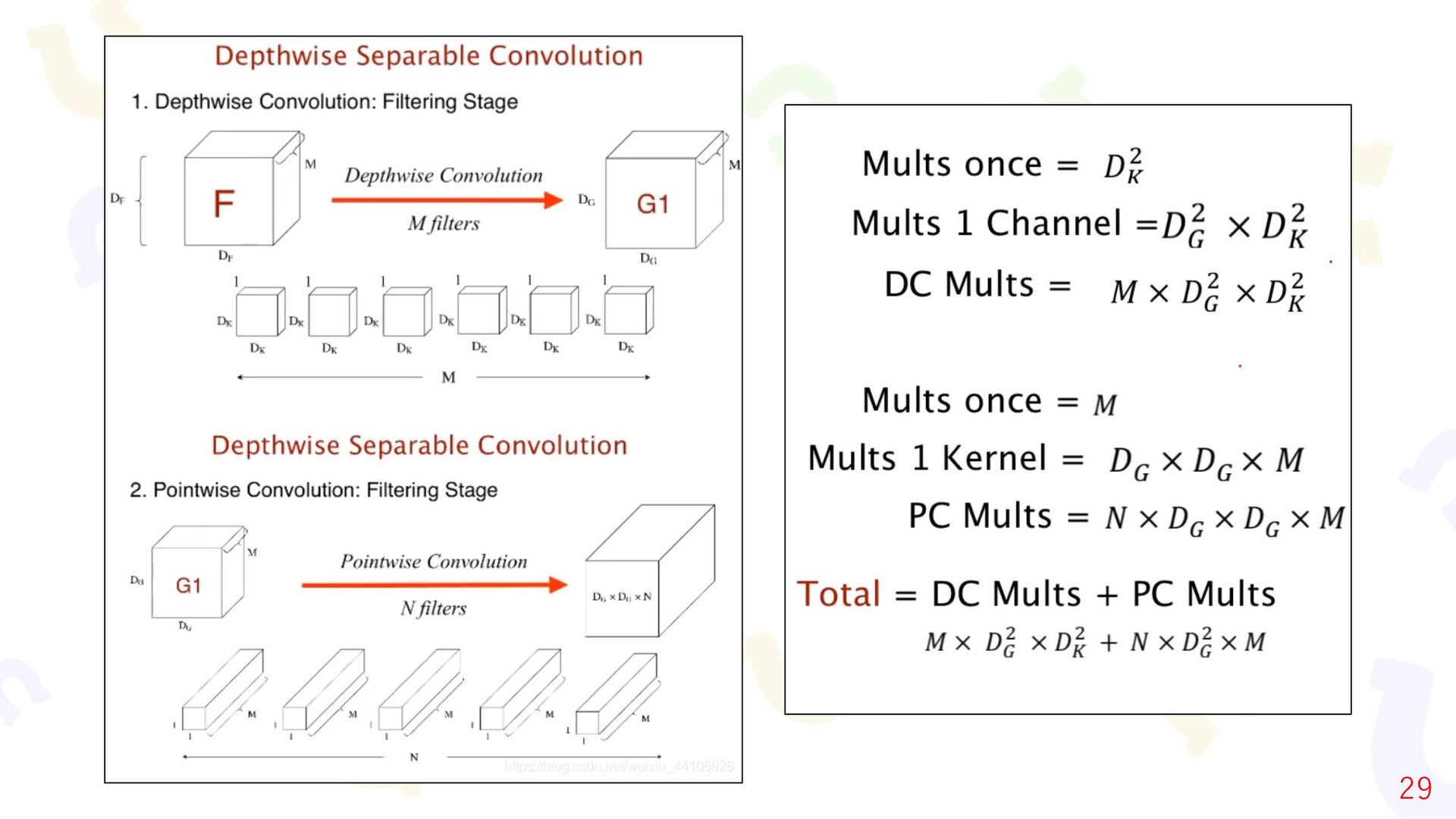{kind=link}
{kind=link}
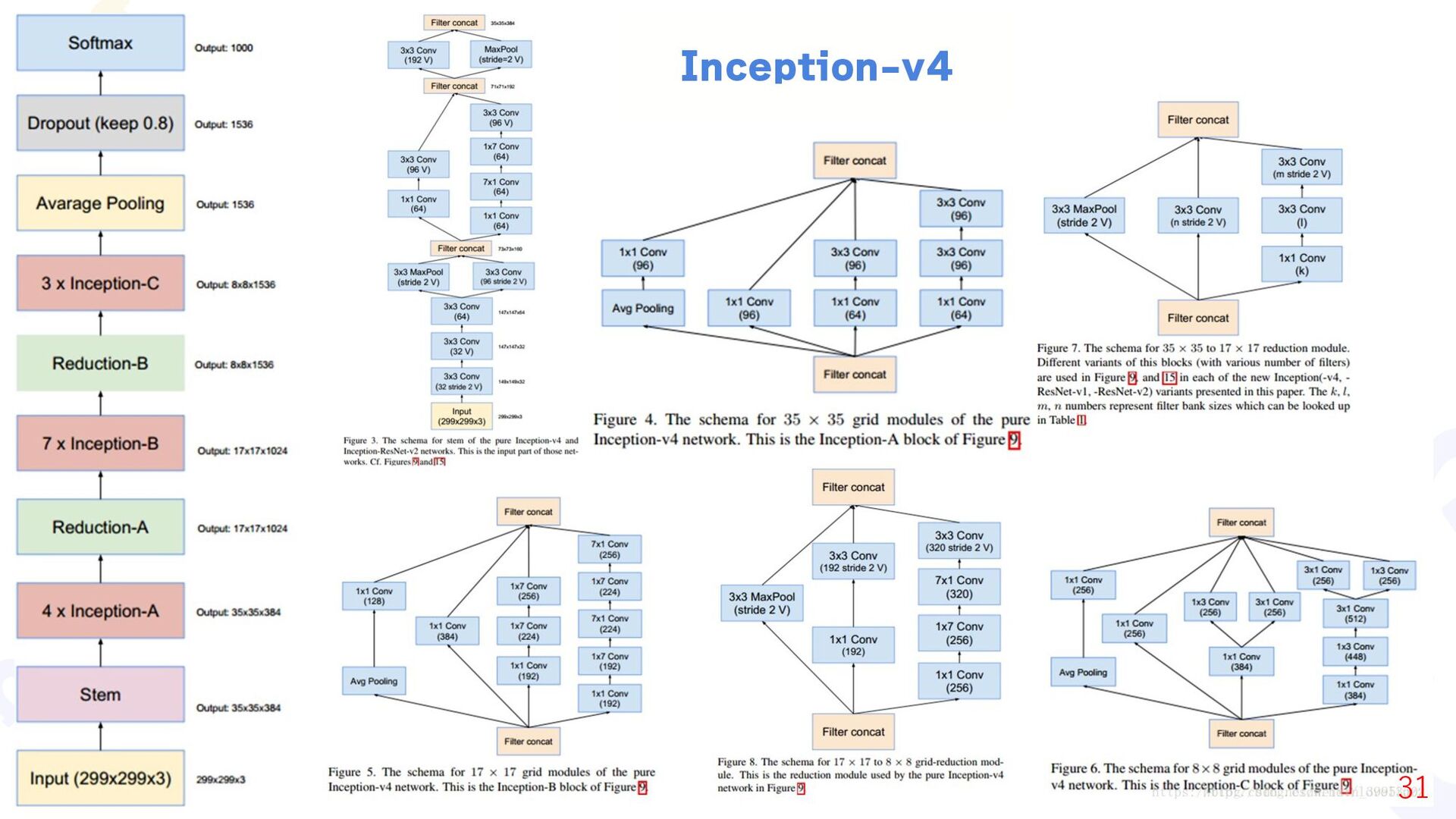{kind=link}
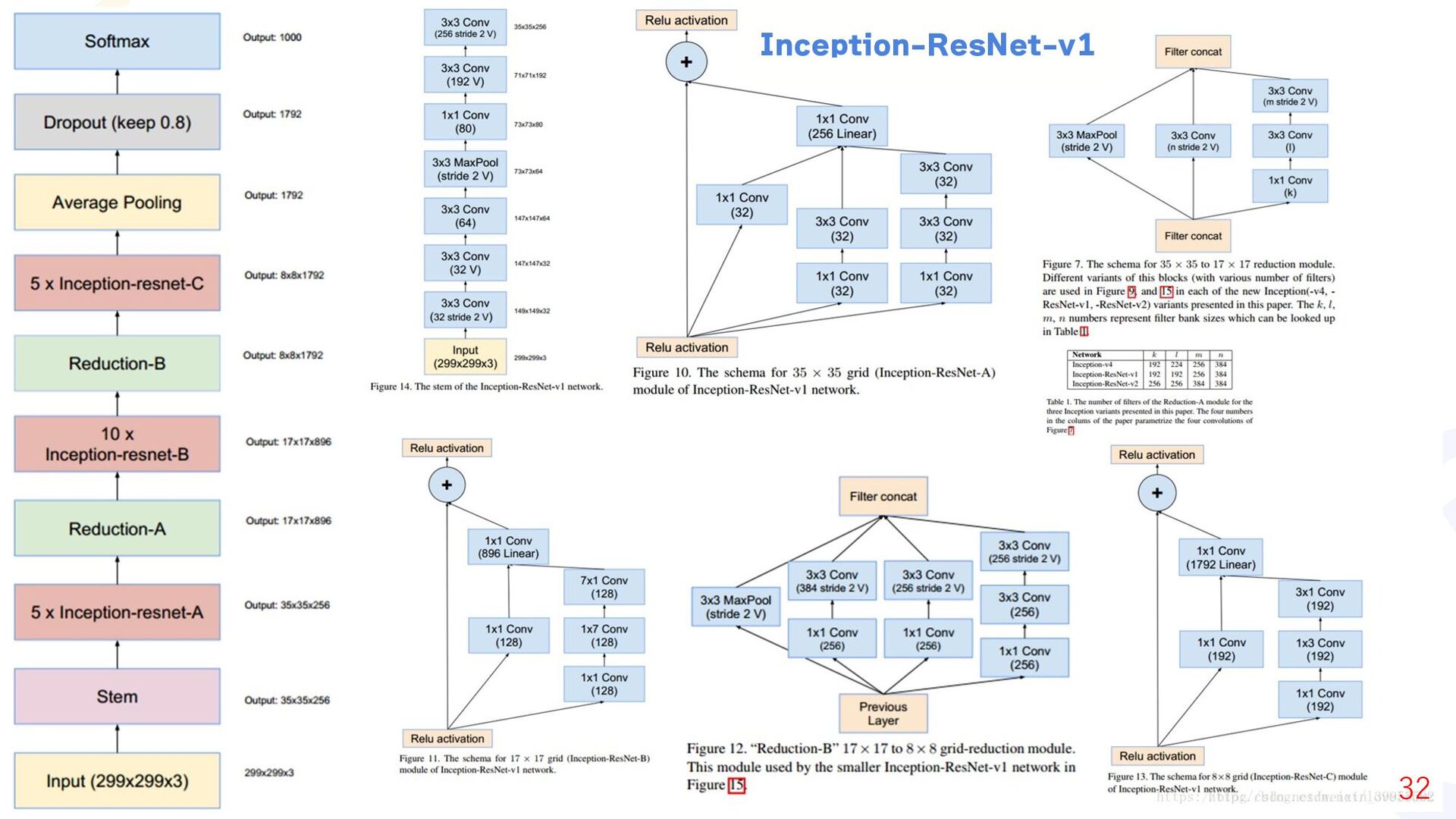{kind=link}
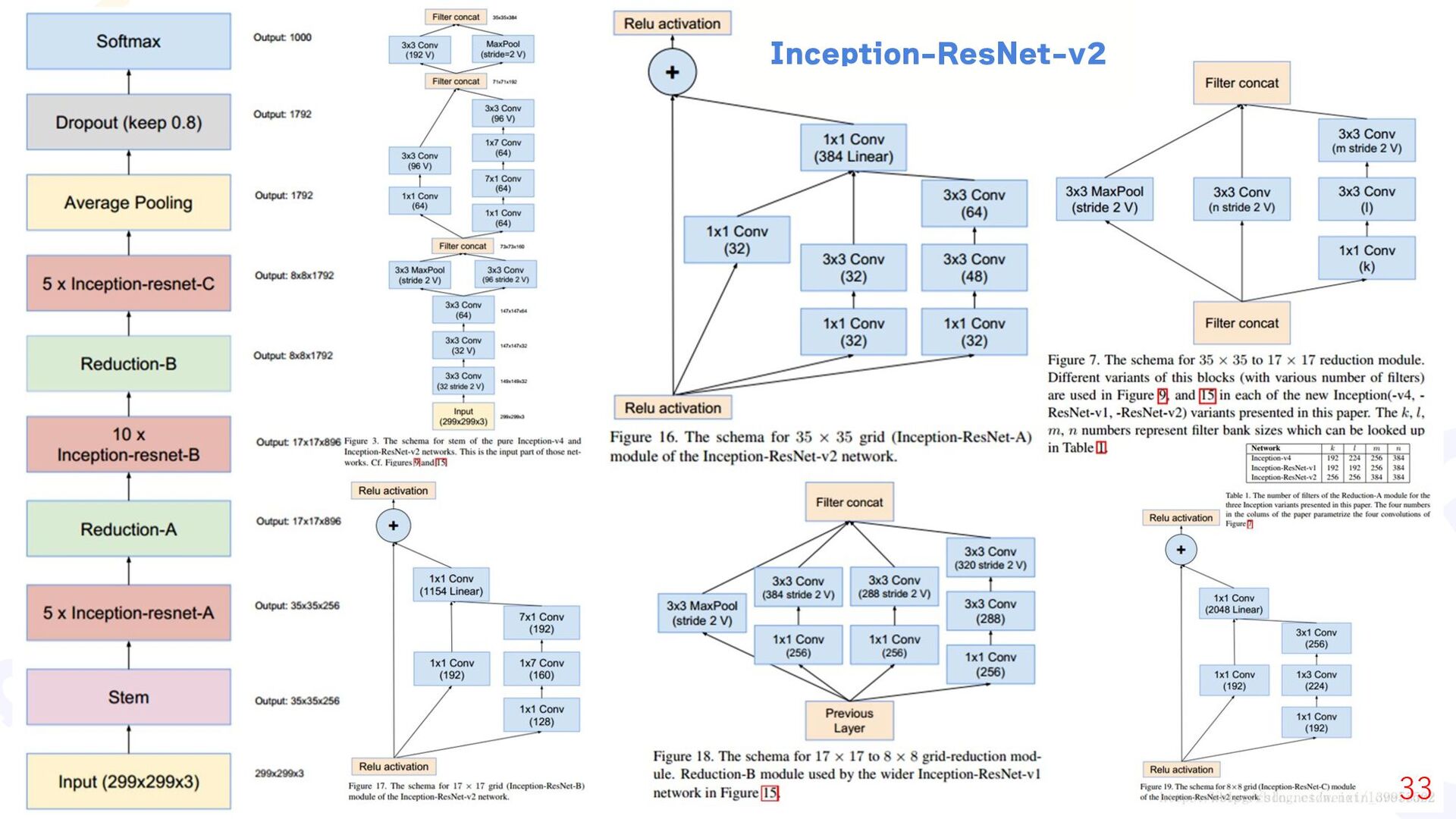{kind=link}
{kind=link}
{kind=link}
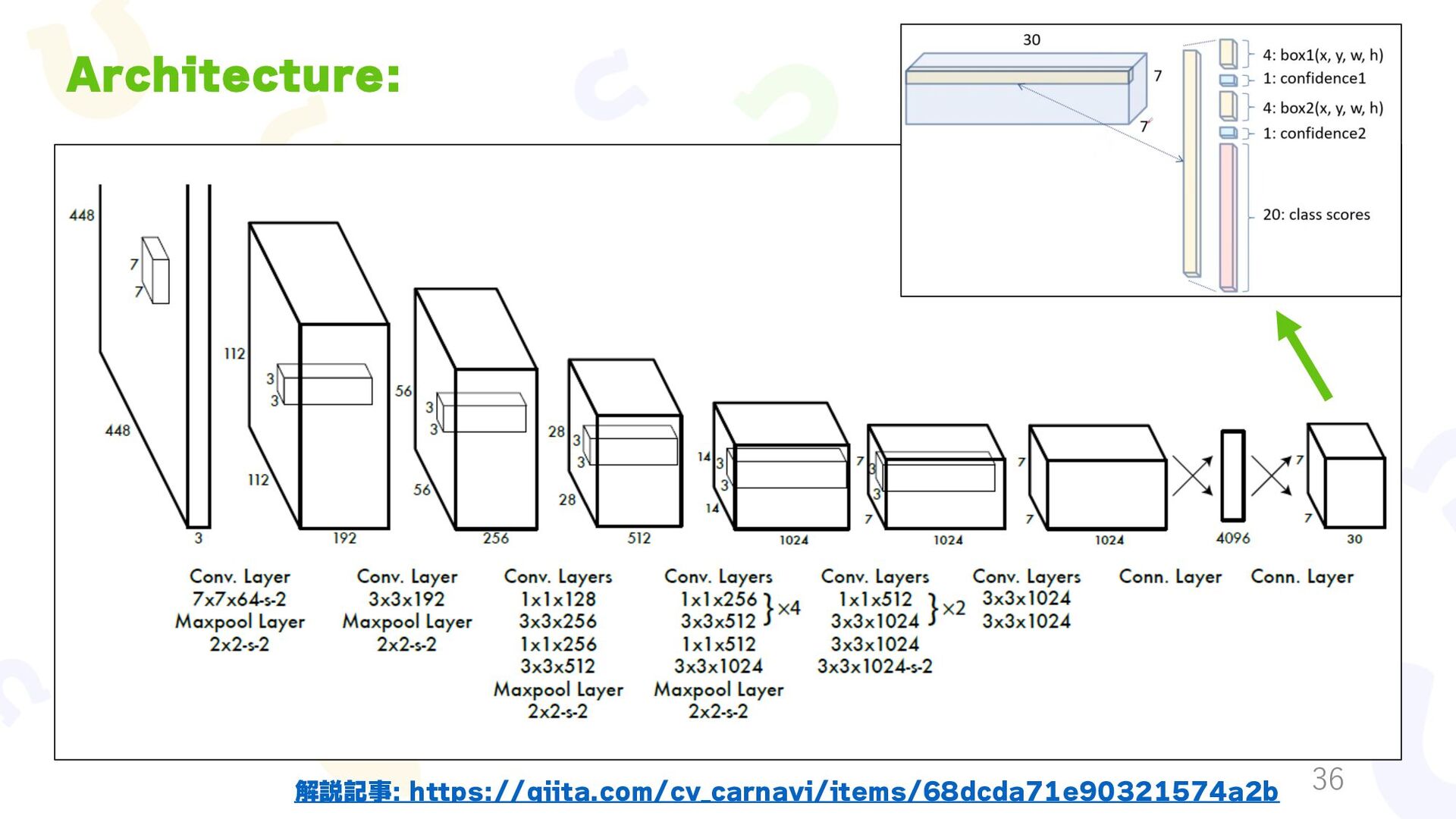{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
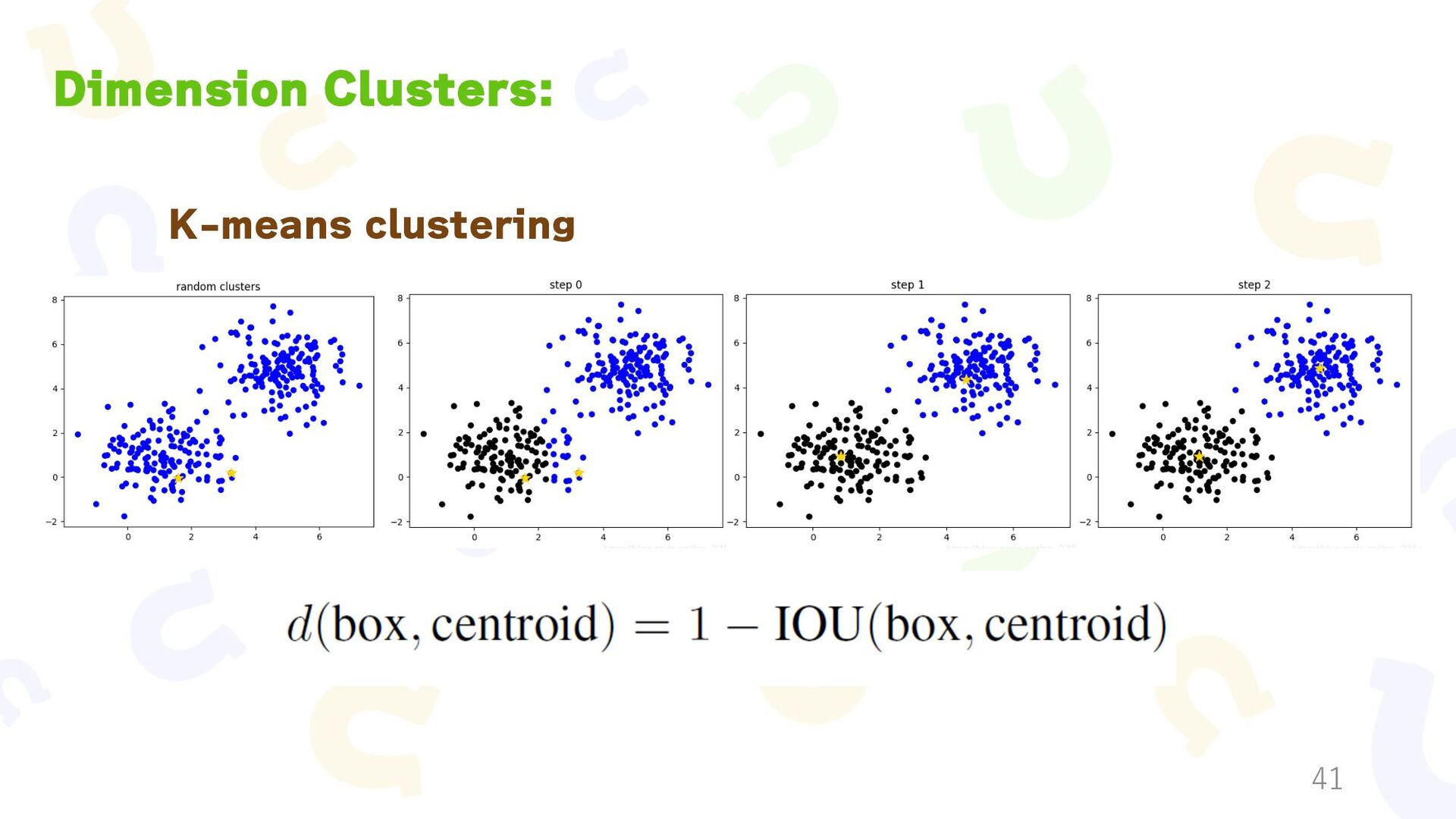{kind=link}
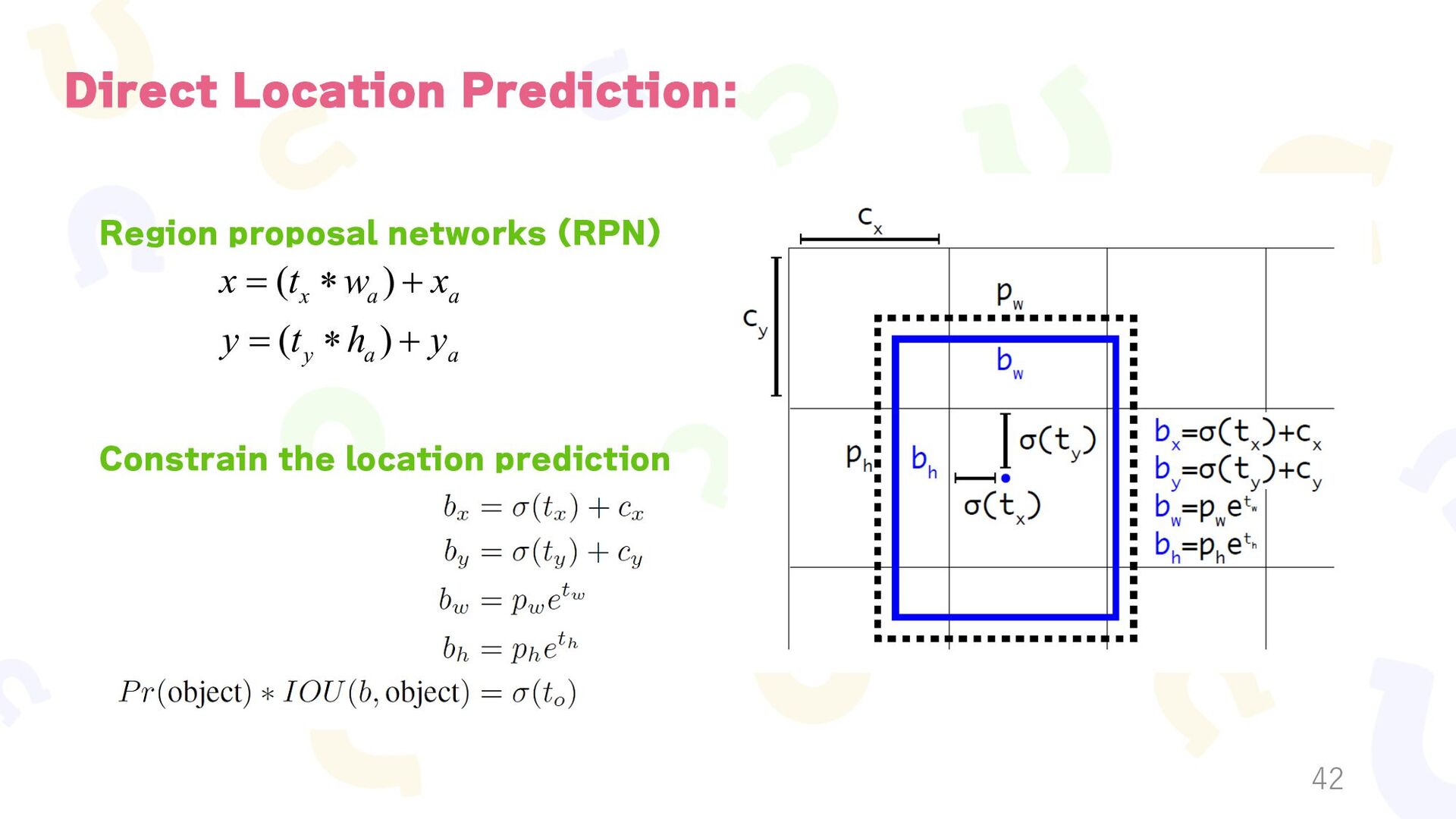{kind=link}
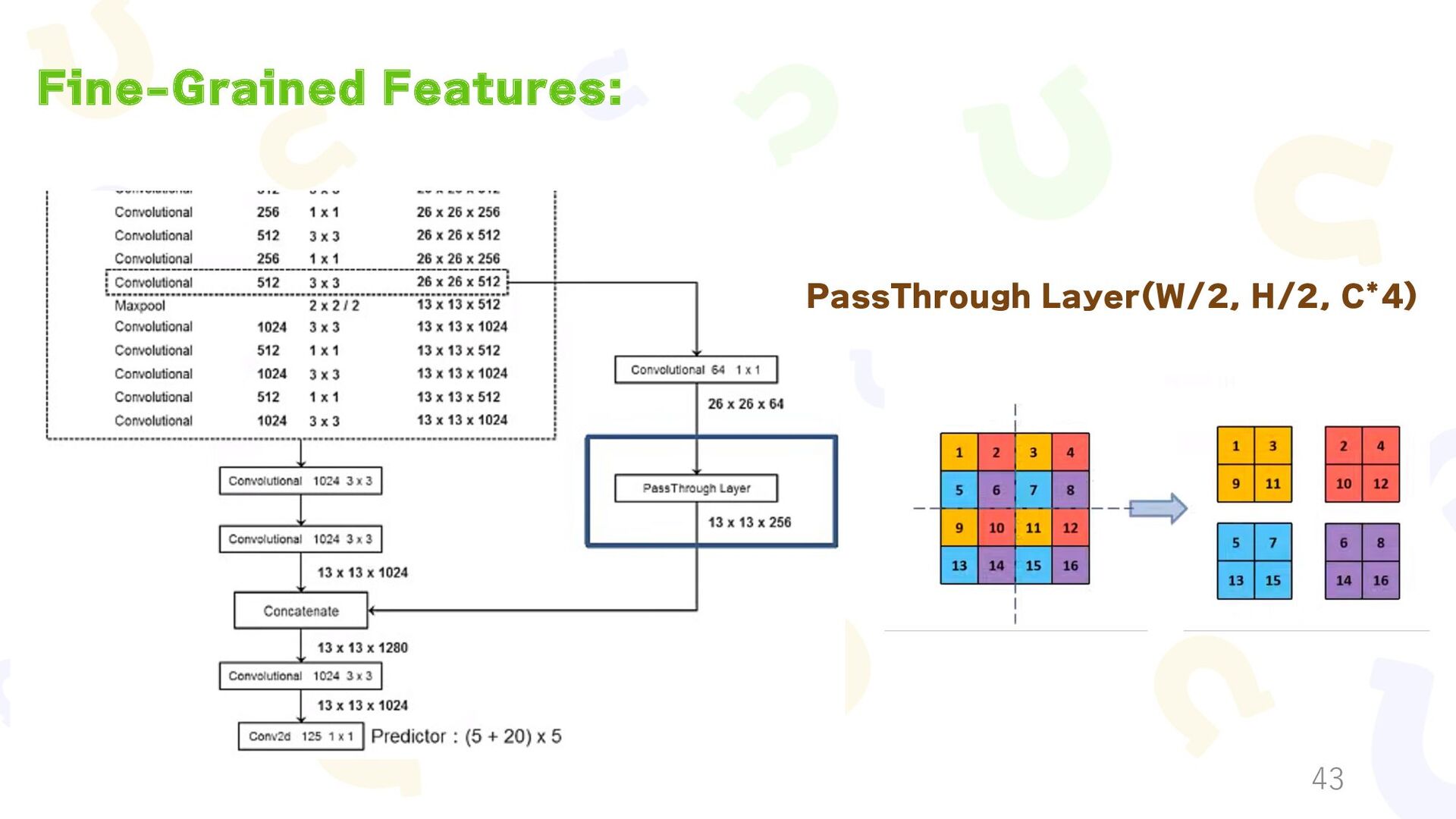{kind=link}
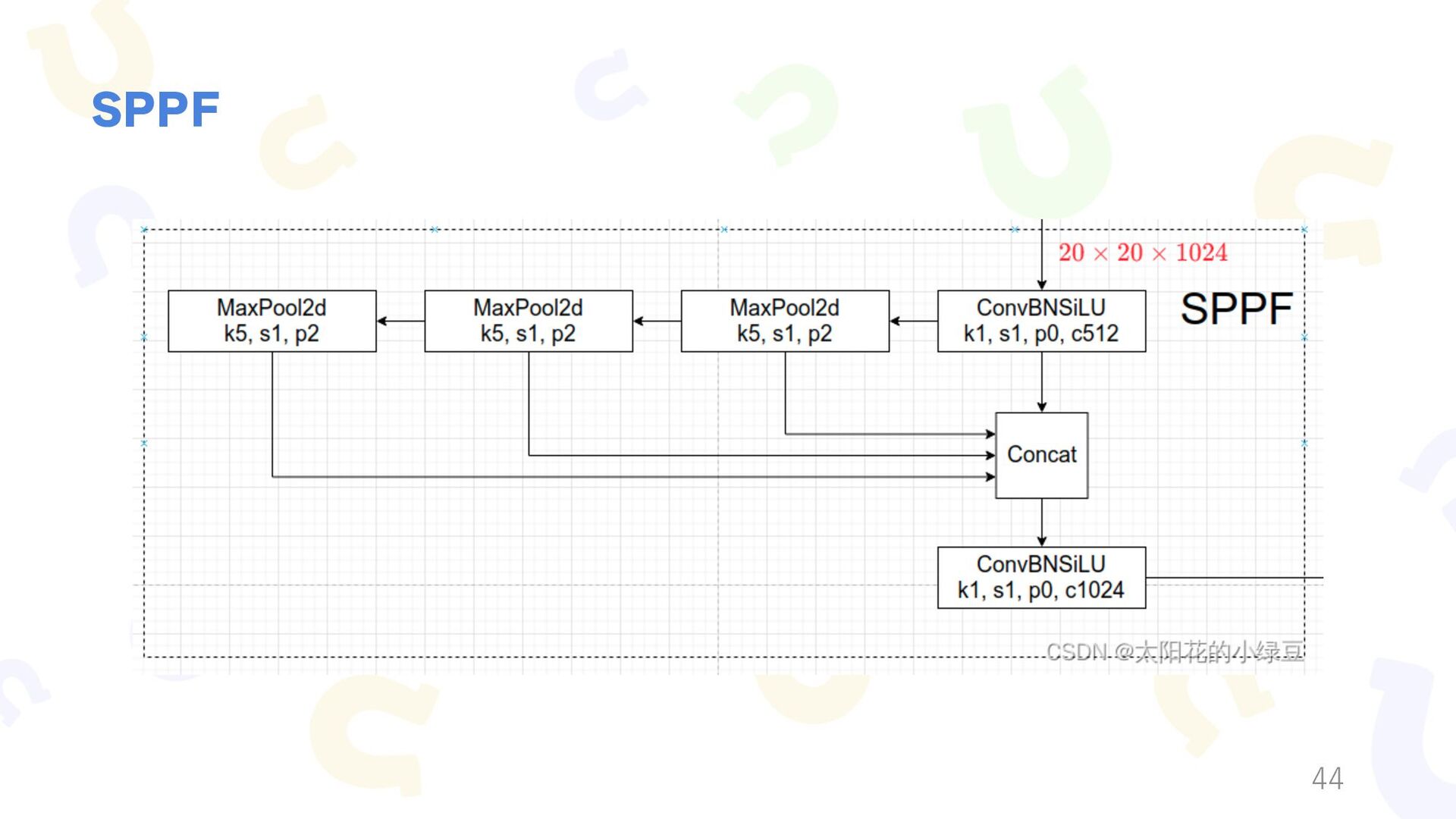{kind=link}
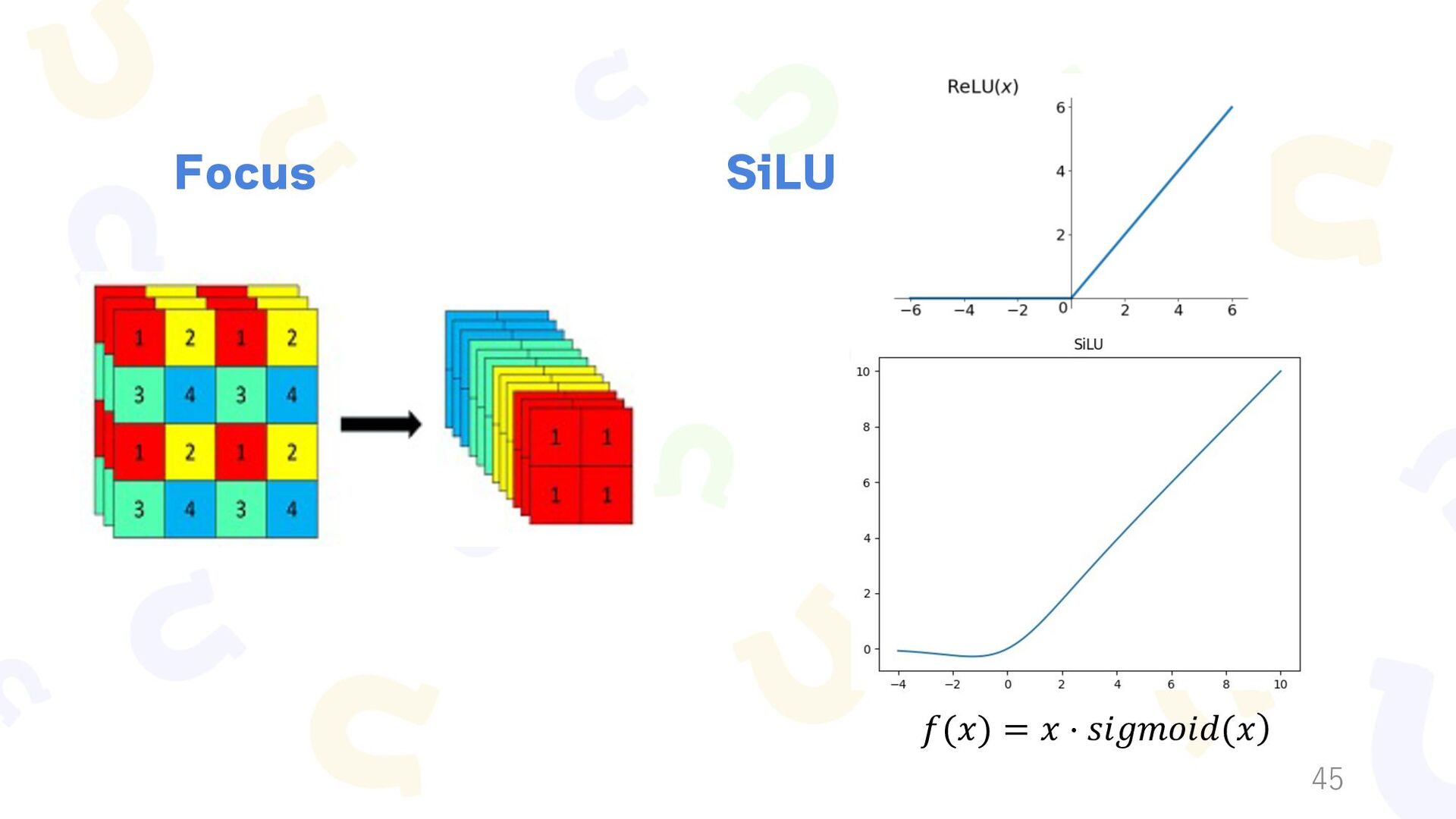{kind=link}
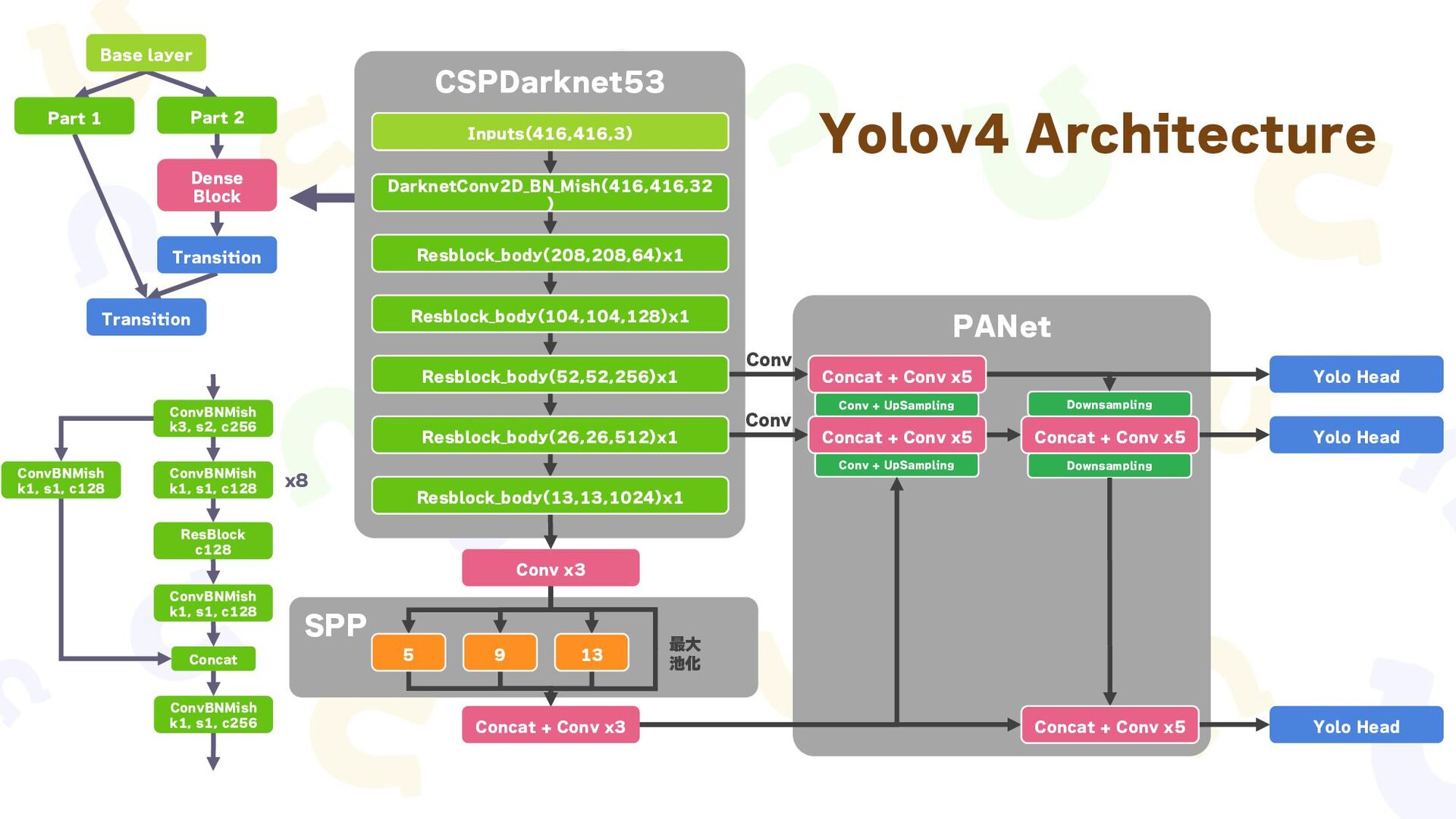{kind=link}
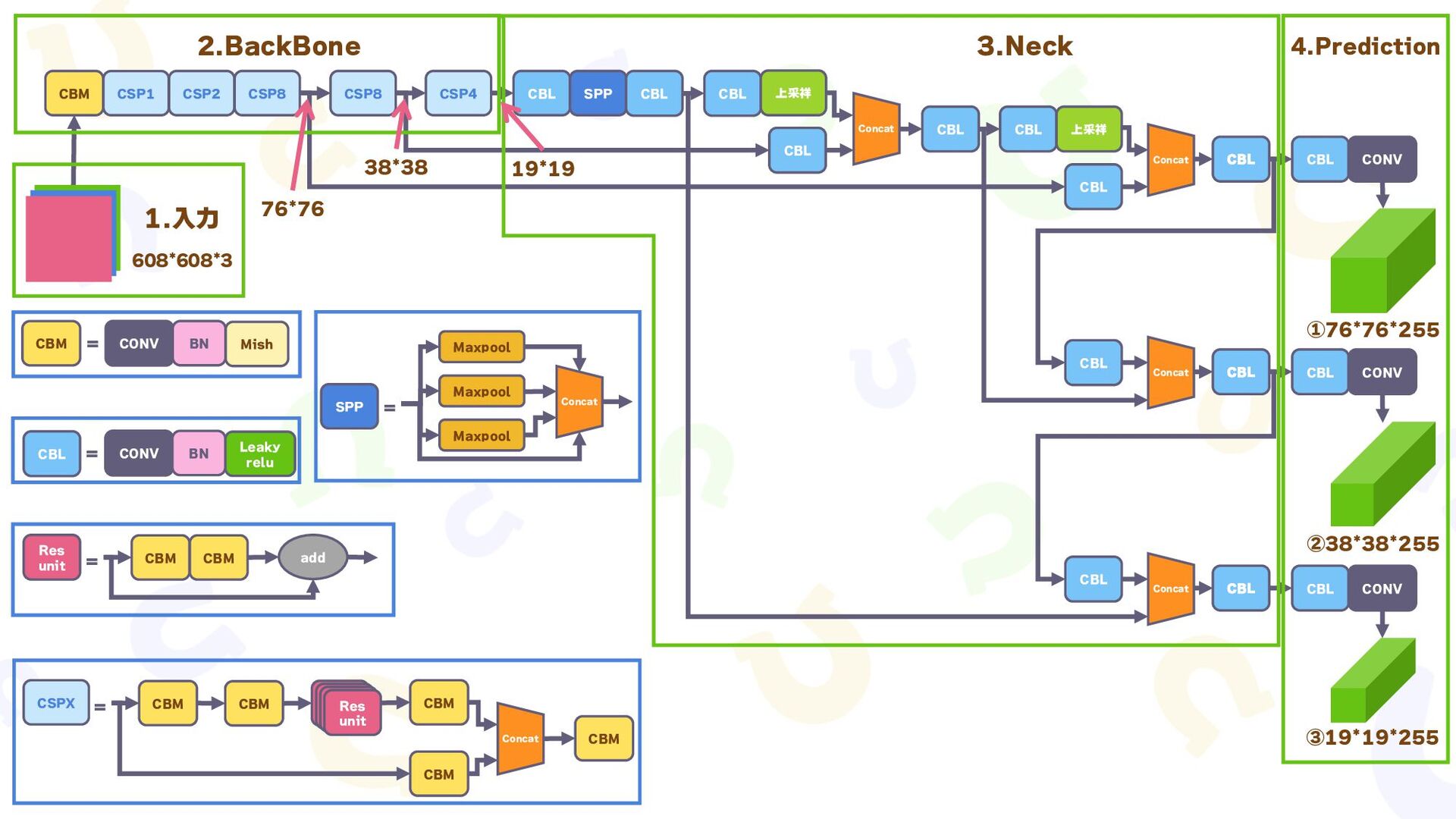{kind=link}
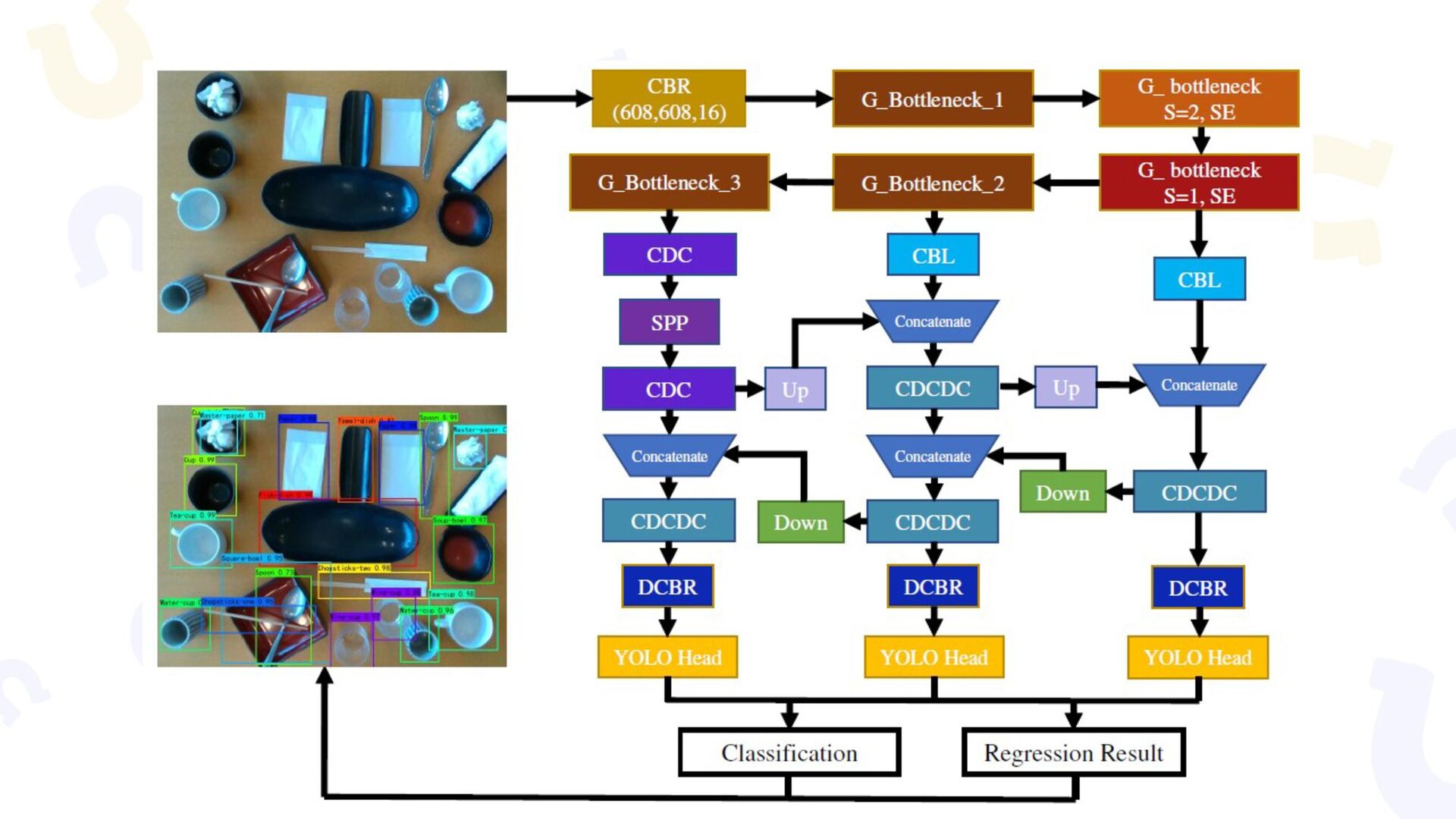{kind=link}
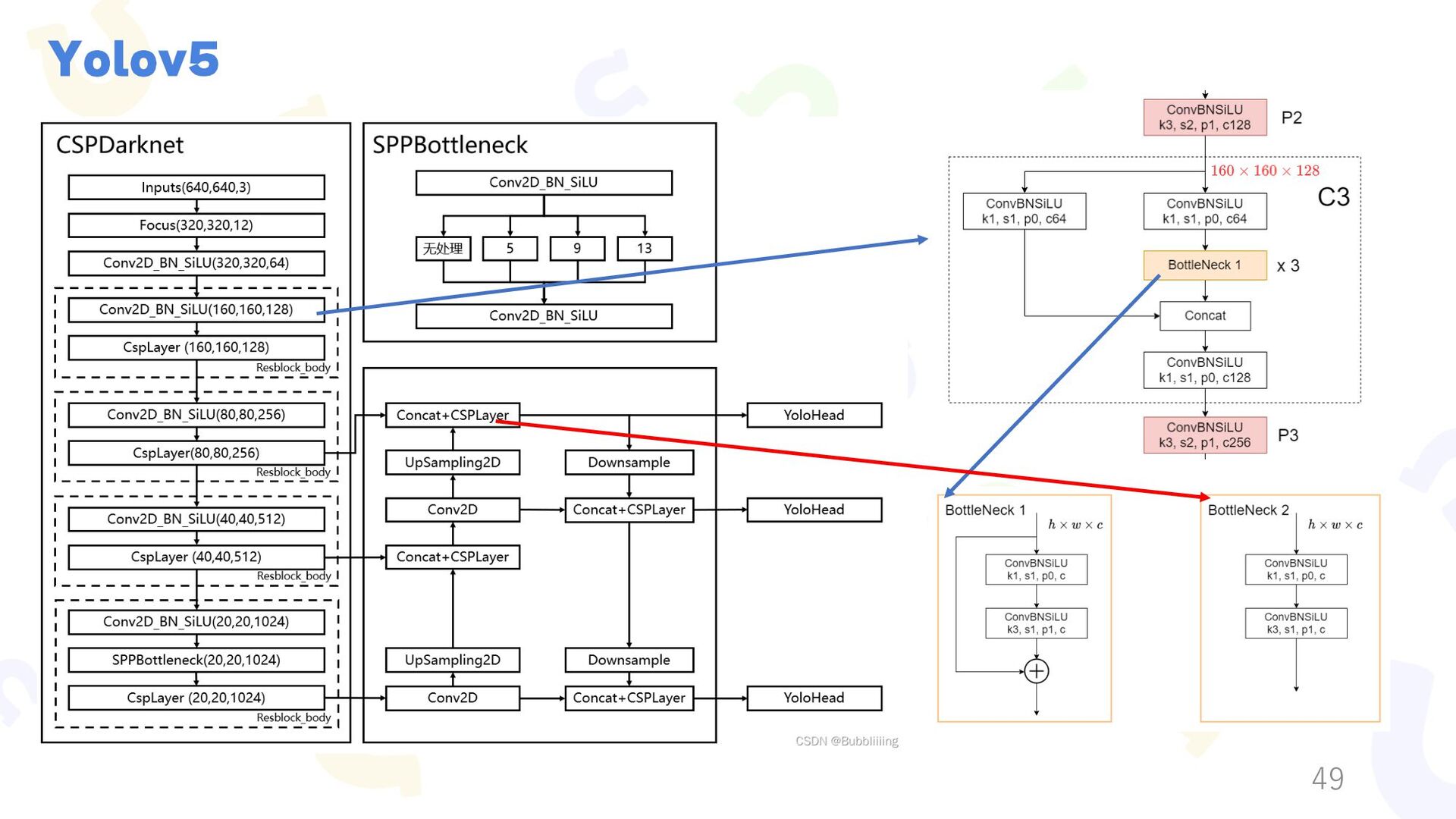{kind=link}
{kind=link}
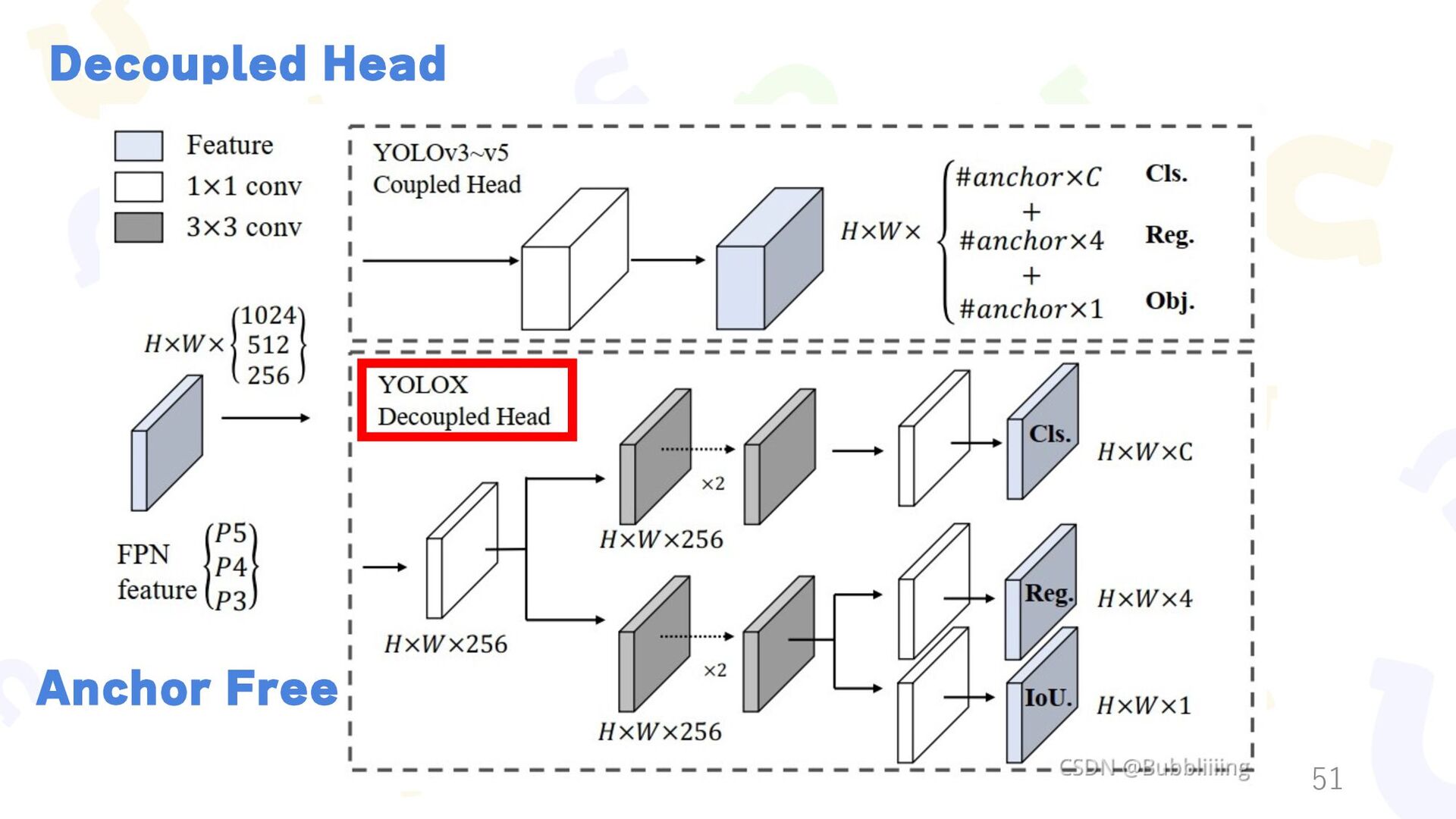{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
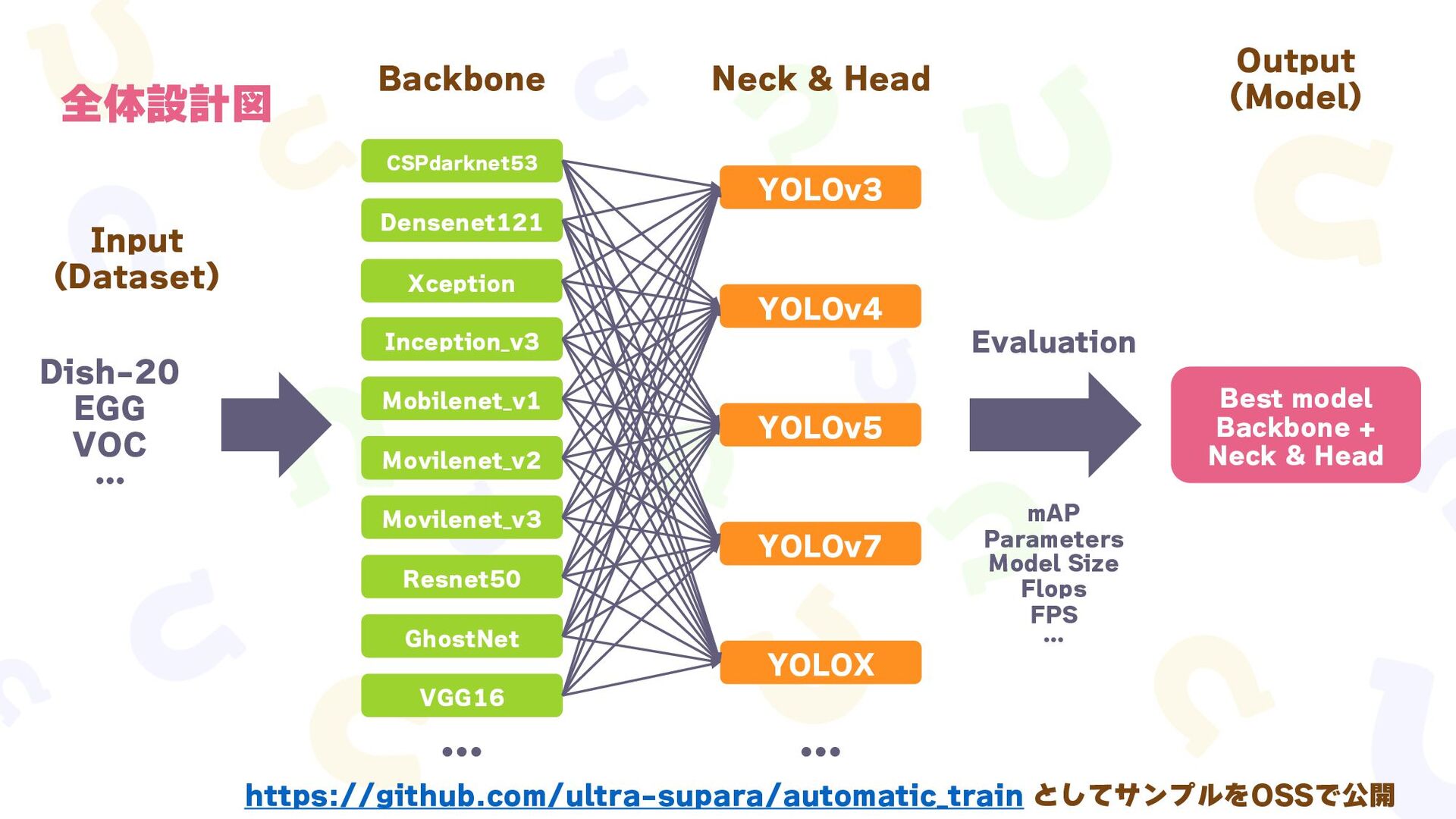{kind=link}
{kind=link}
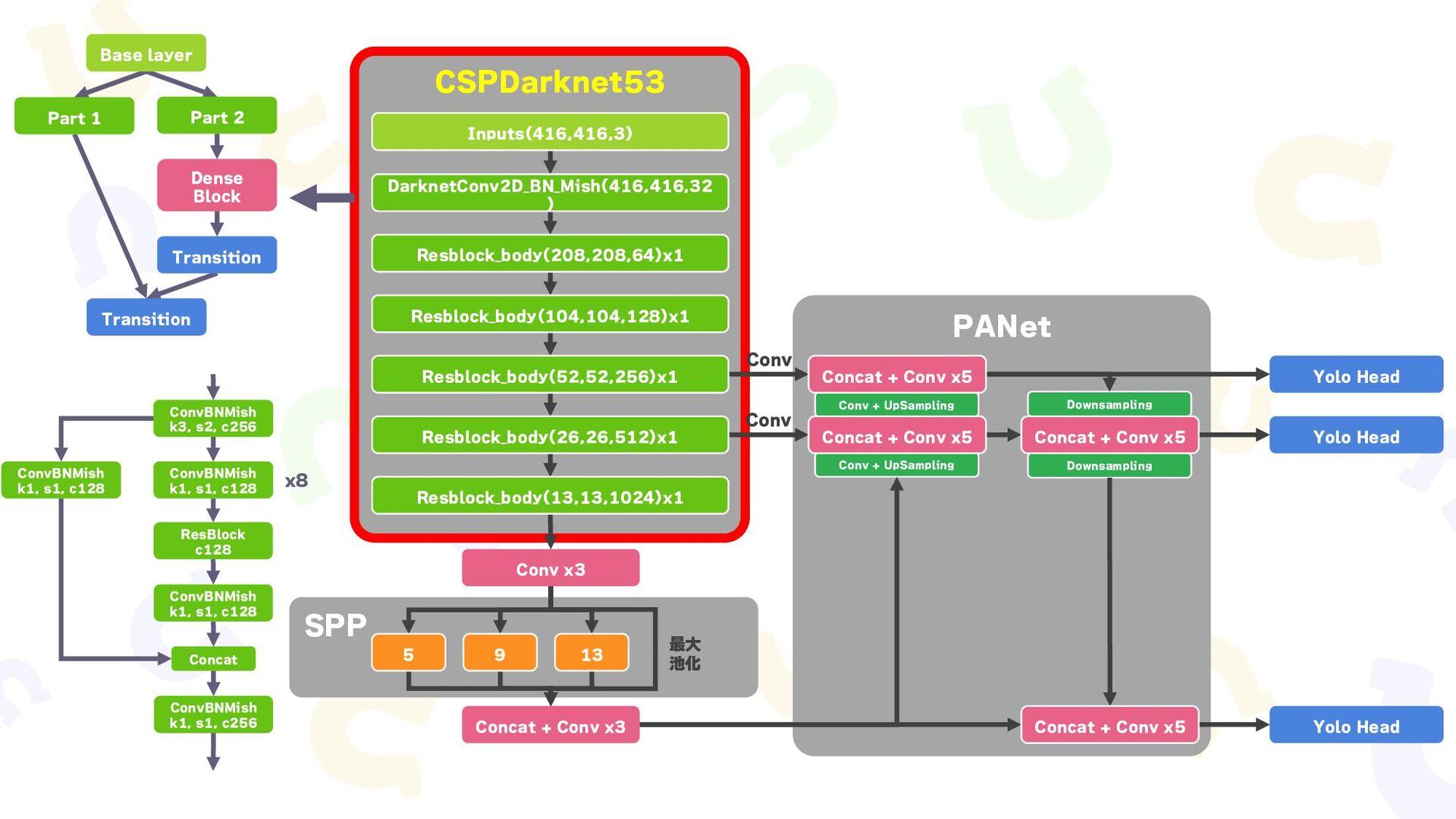{kind=link}
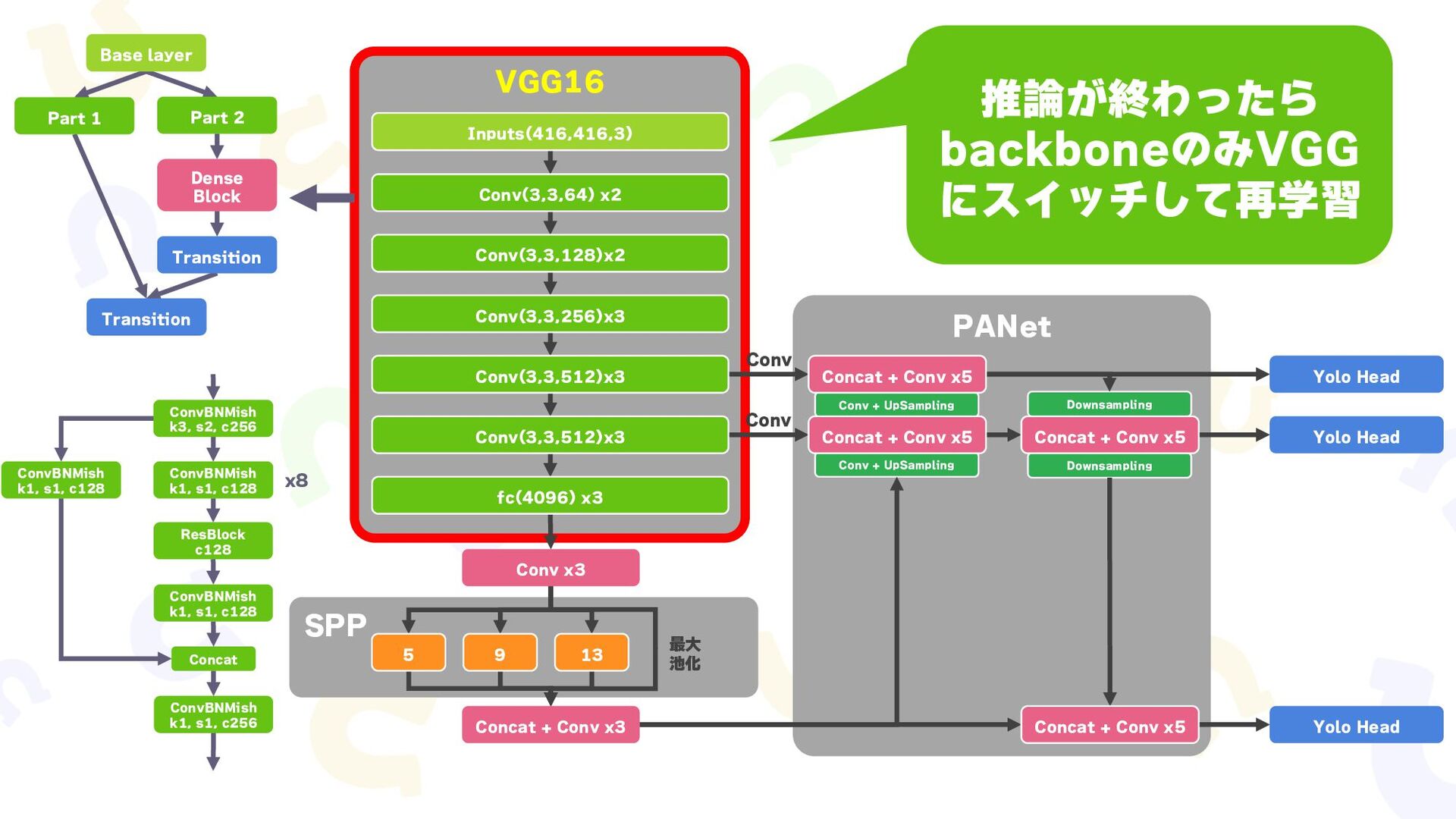{kind=link}
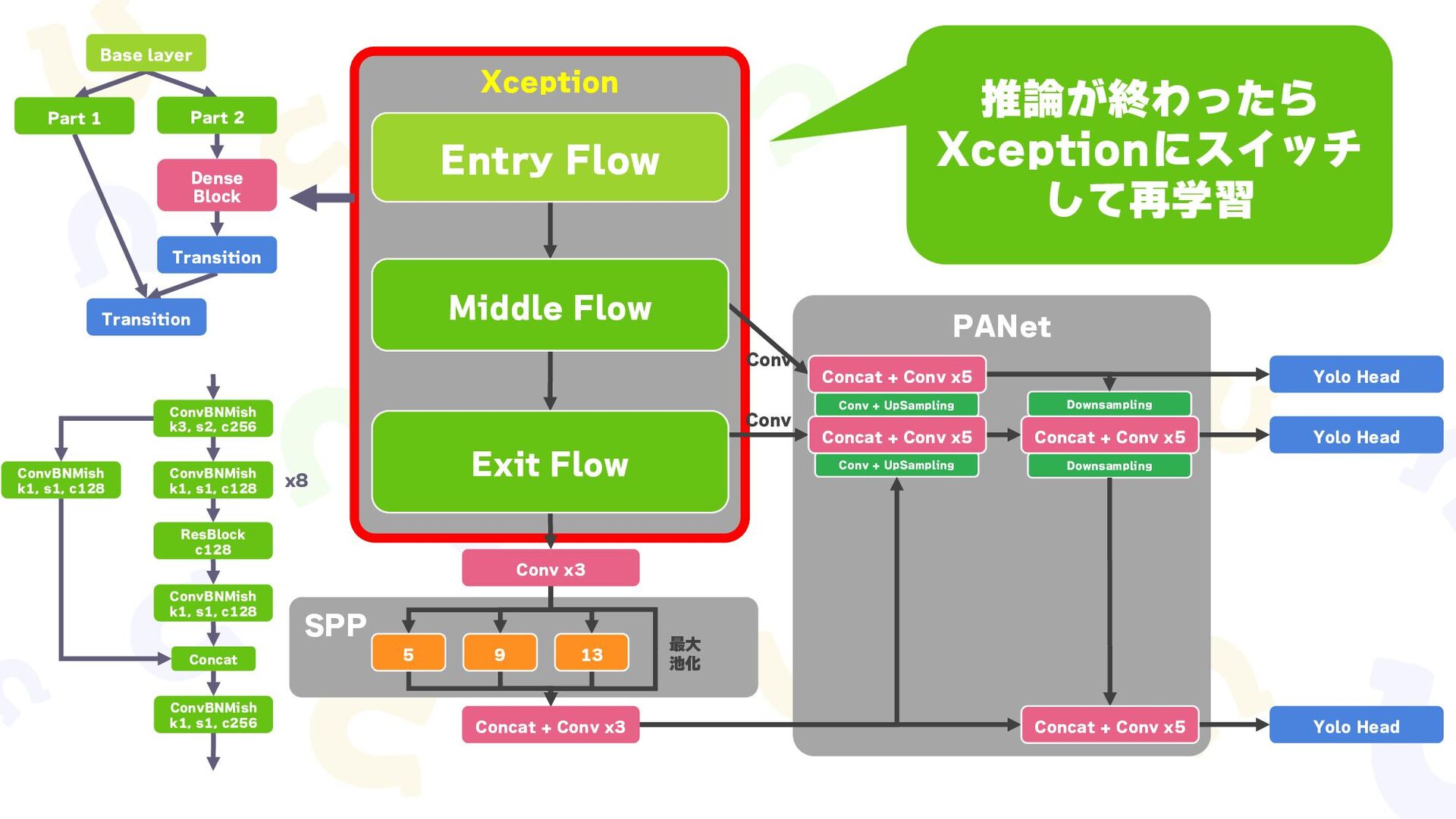{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
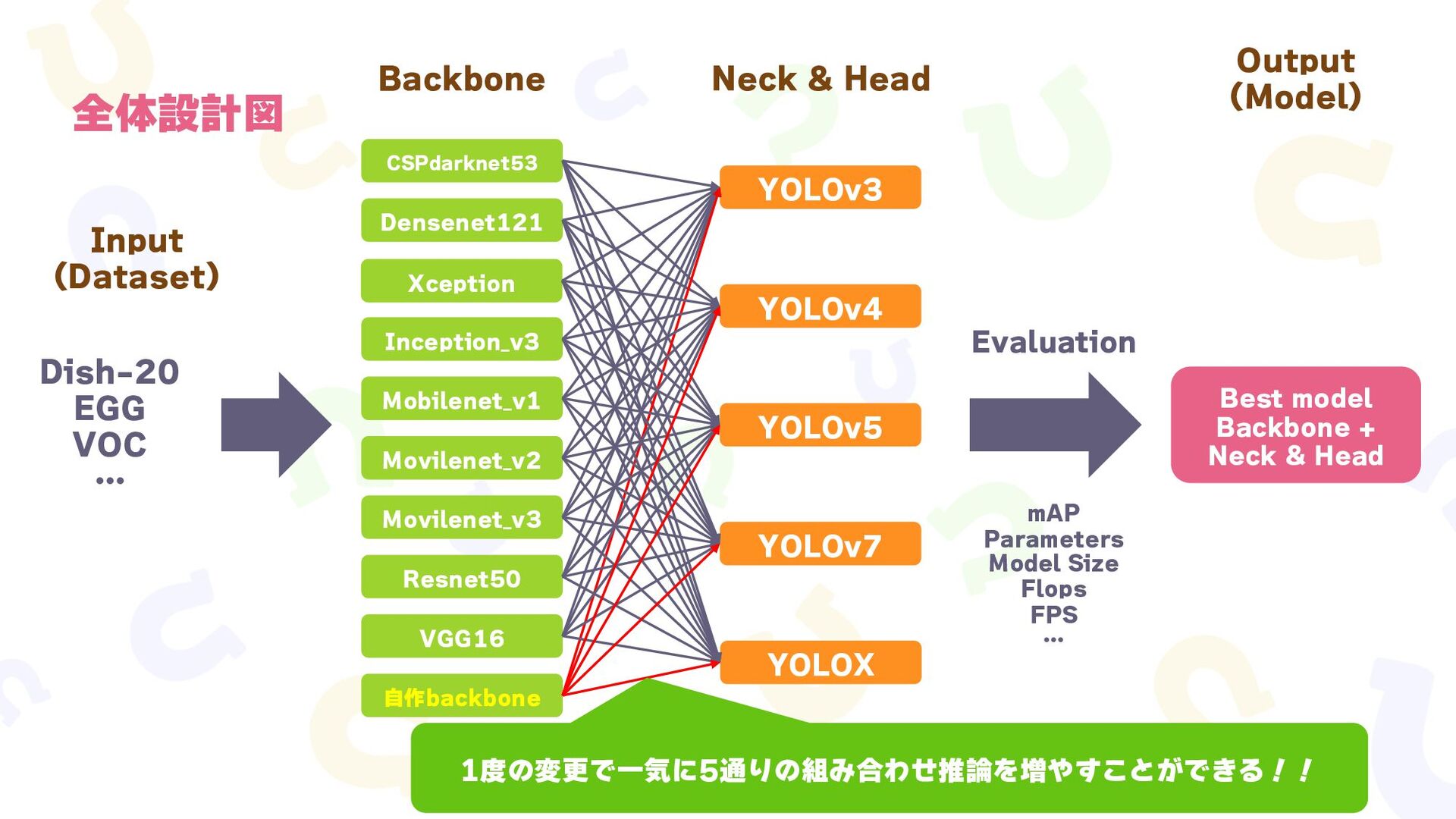{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
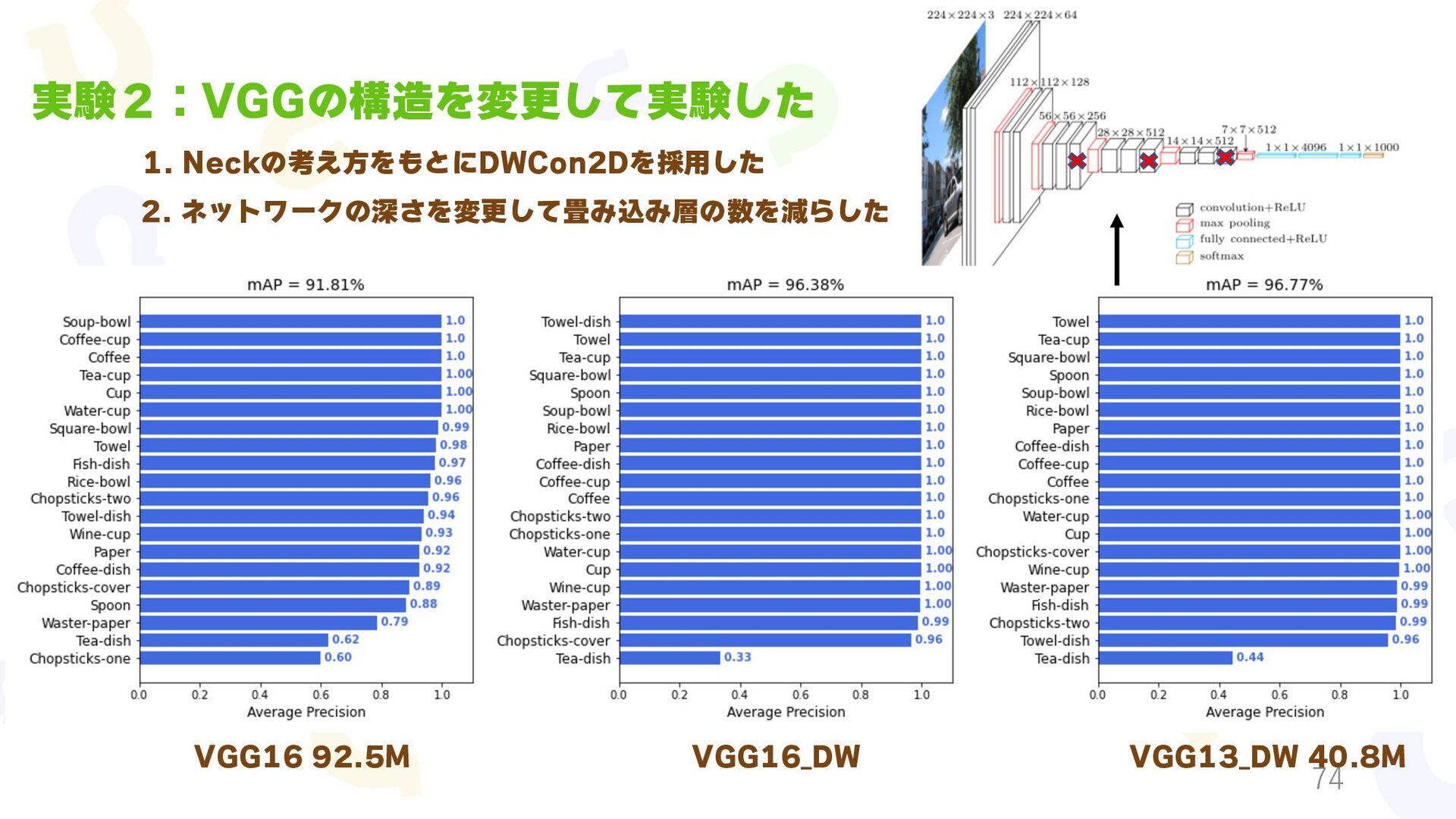{kind=link}
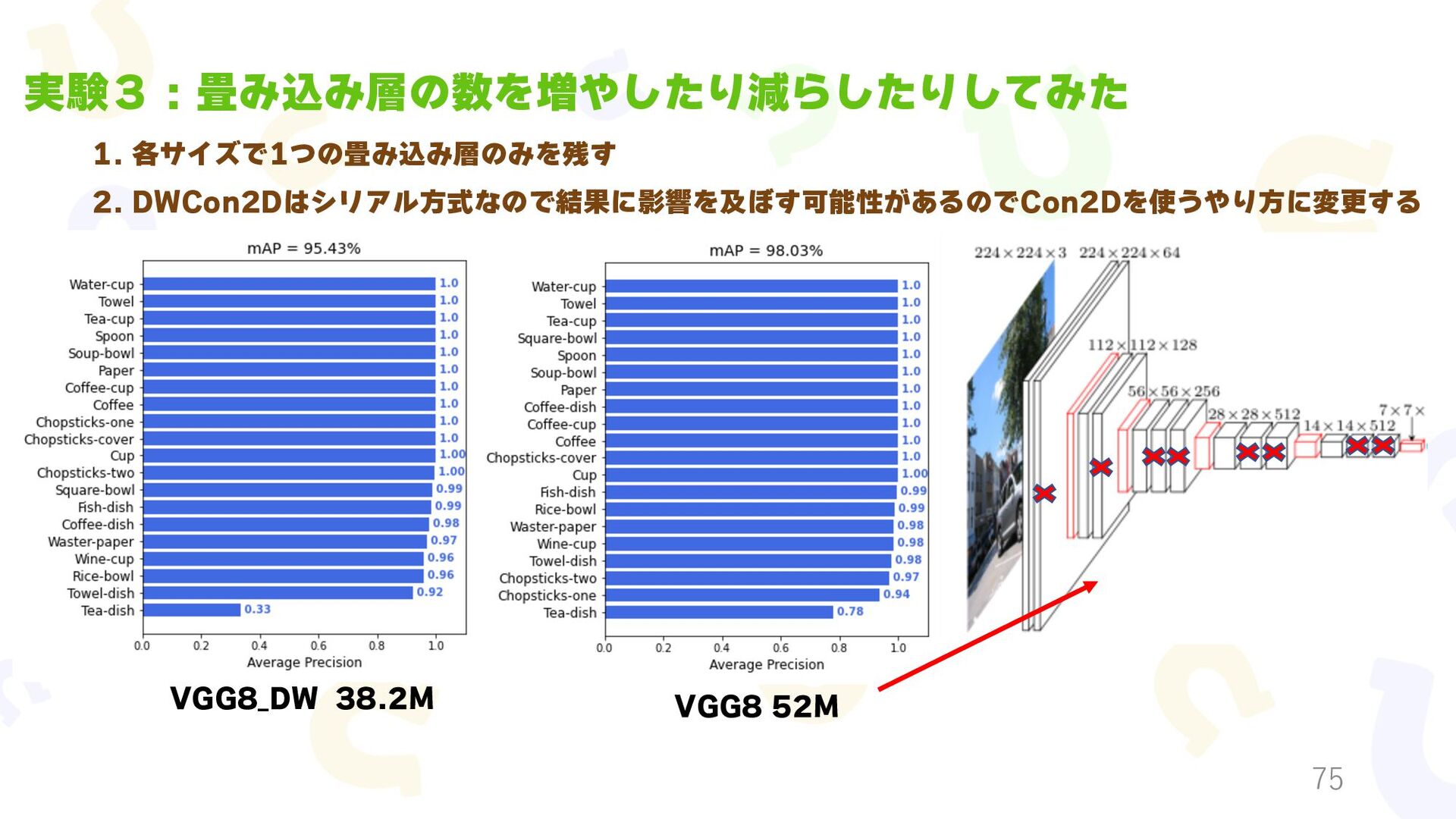{kind=link}
{kind=link}
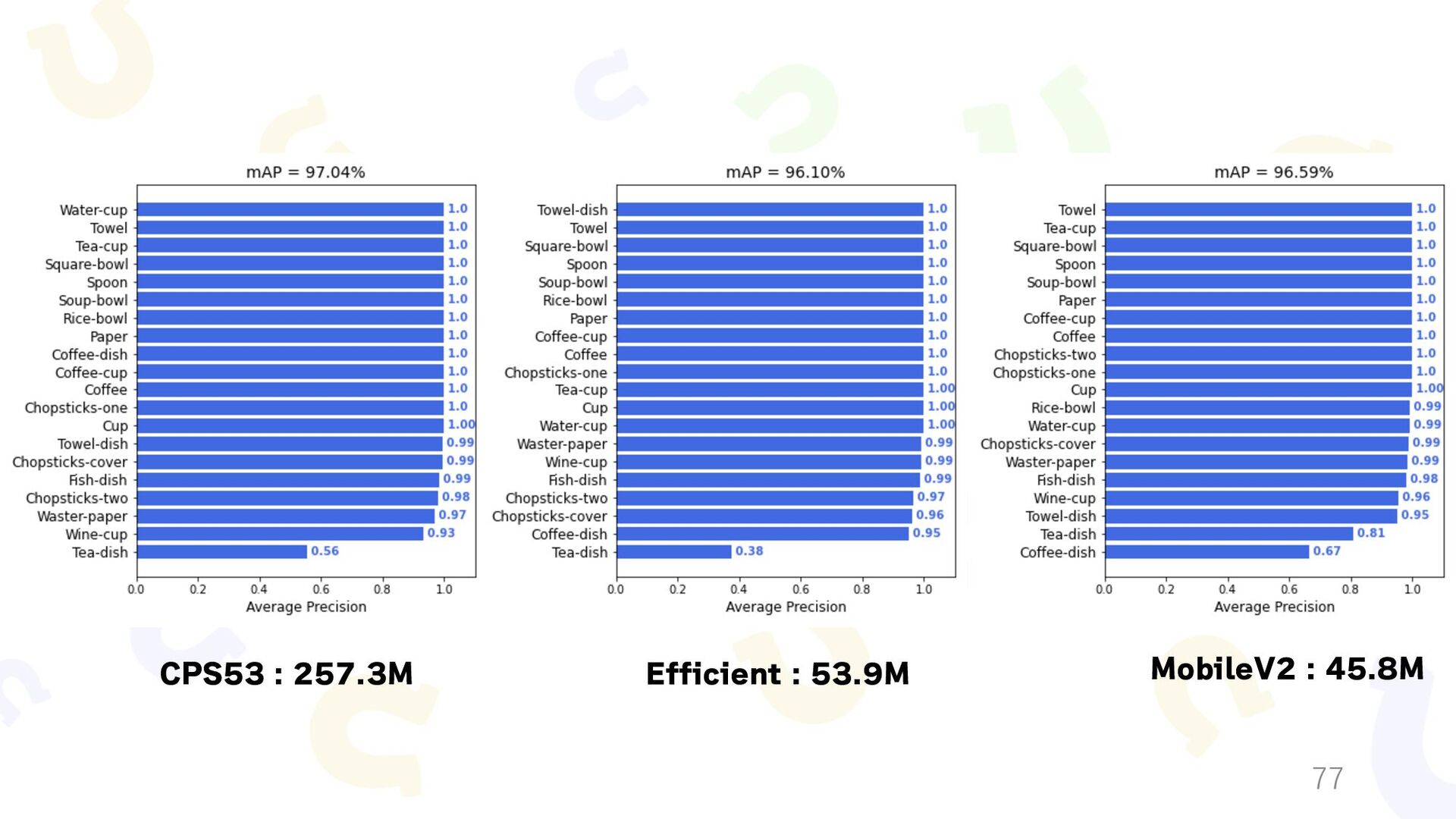{kind=link}
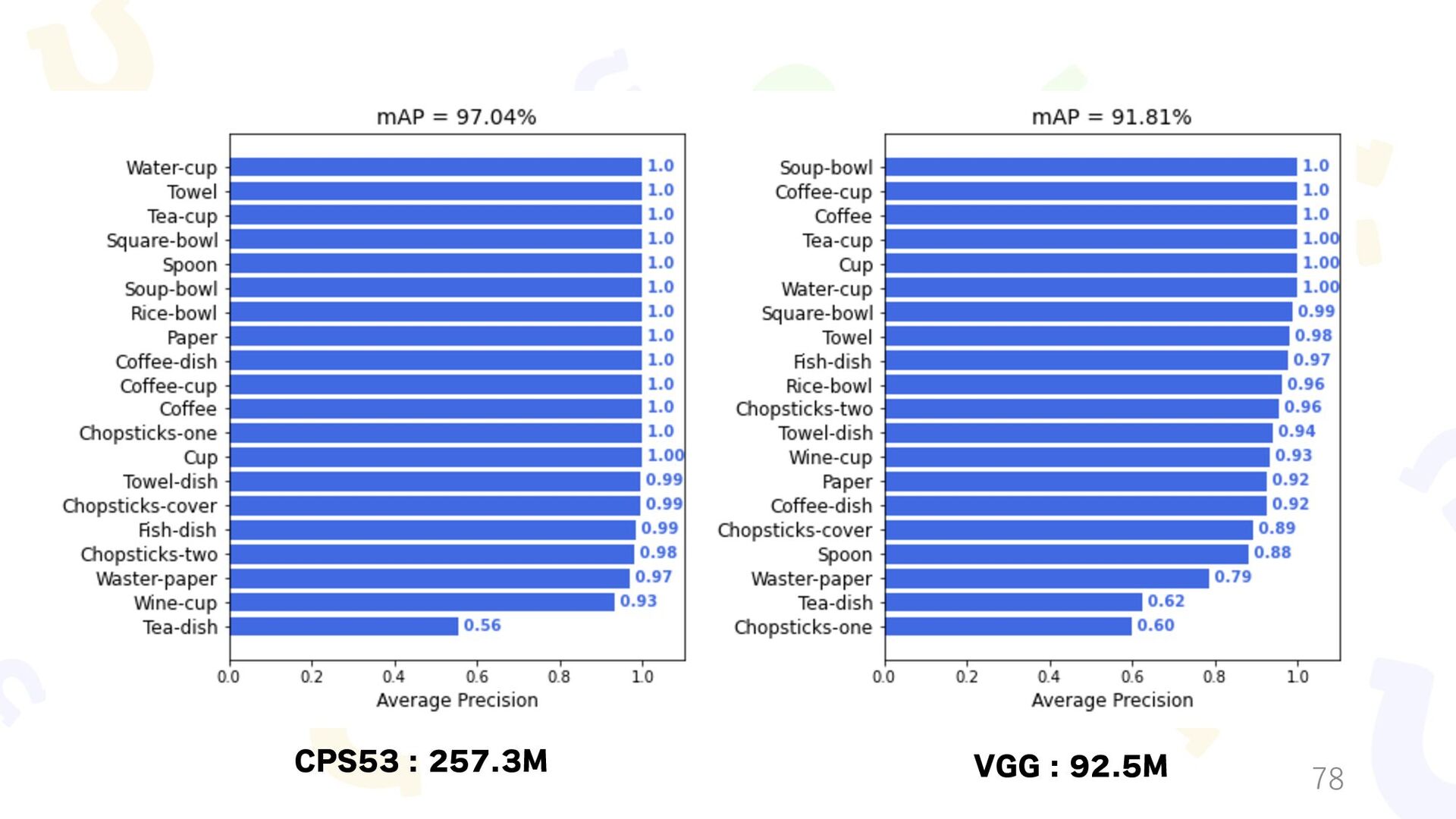{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}