us to perform mixed graph and non-graph data analysis in pySpark Lightning talk by: Elena Nemtseva at 32 PyData London Meetup https://graphframes.github.io/ People behind GraphFrames: Ankur Dave (UC Berkeley AMPLab) Alekh Jindal (Microsoft) Li Erran Li (Uber) Reynold Xin (Databricks) Joseph Gonzalez (UC Berkeley) Matei Zaharia (MIT and Databricks)
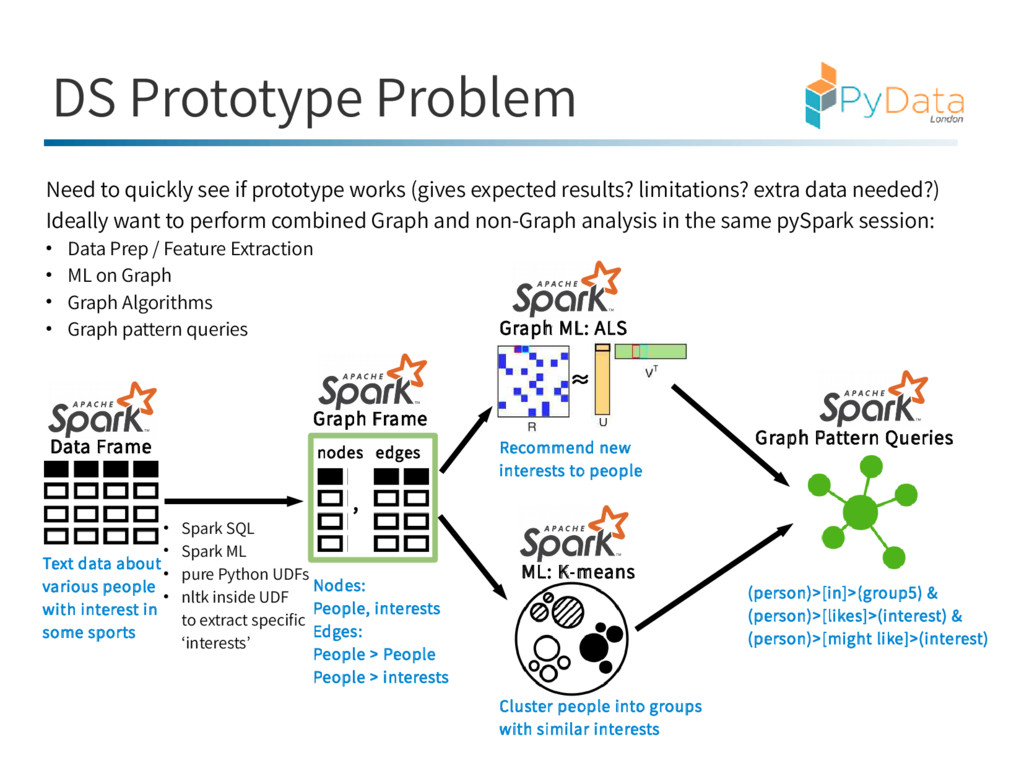
(gives expected results? limitations? extra data needed?) Ideally want to perform combined Graph and non-Graph analysis in the same pySpark session: • Data Prep / Feature Extraction • ML on Graph • Graph Algorithms • Graph pattern queries Data Frame • Spark SQL • Spark ML • pure Python UDFs • nltk inside UDF to extract specific ‘interests’ Text data about various people with interest in some sports Graph Frame nodes edges , Nodes: People, interests Edges: People > People People > interests Graph Pattern Queries (person)>[in]>(group5) & (person)>[likes]>(interest) & (person)>[might like]>(interest) Graph ML: ALS ML: K-means Recommend new interests to people Cluster people into groups with similar interests ≈
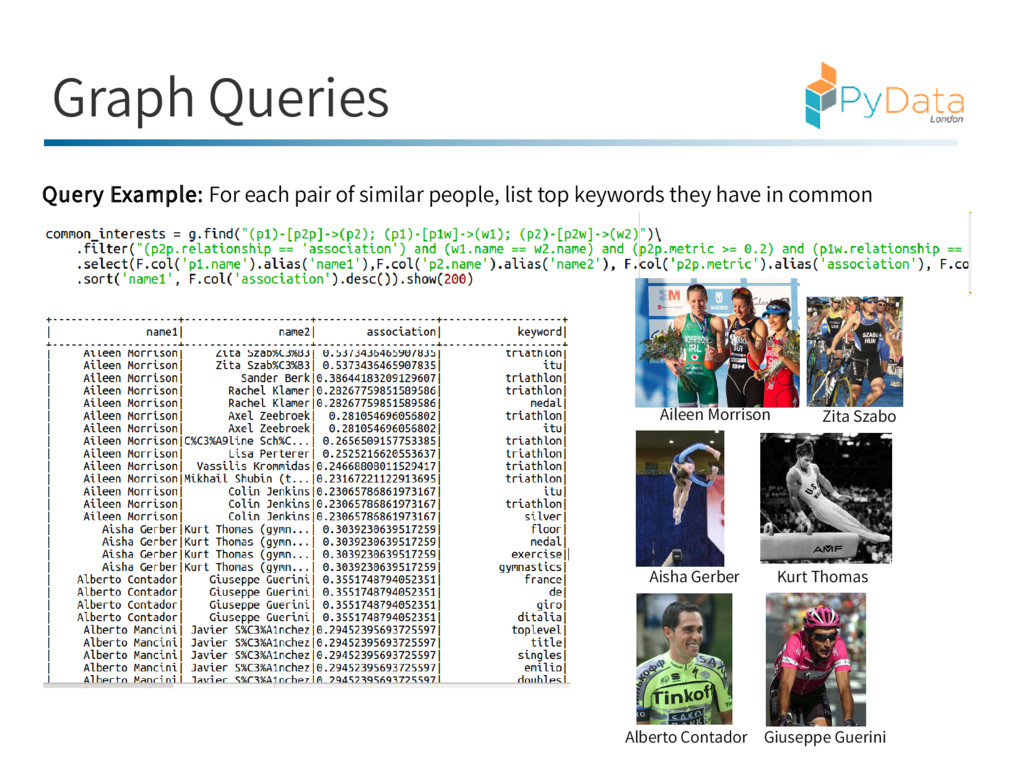
Data Frames The data frames were created in pySpark using ordinary SparkSQL with ‘edge weight’ metrics pre- calculated using Spark ML (Note: Spark’s UDFs can be wrapped around most python functions) g = GraphFrame(nodes, edges)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}