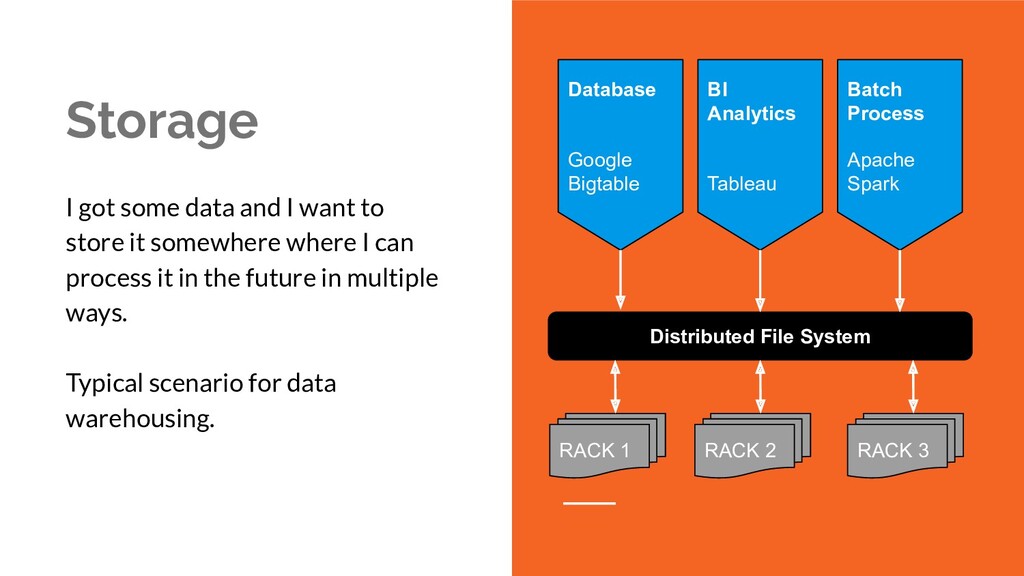
it somewhere where I can process it in the future in multiple ways. Typical scenario for data warehousing. Distributed File System RACK 2 Database Google Bigtable BI Analytics Tableau Batch Process Apache Spark RACK 1 RACK 3
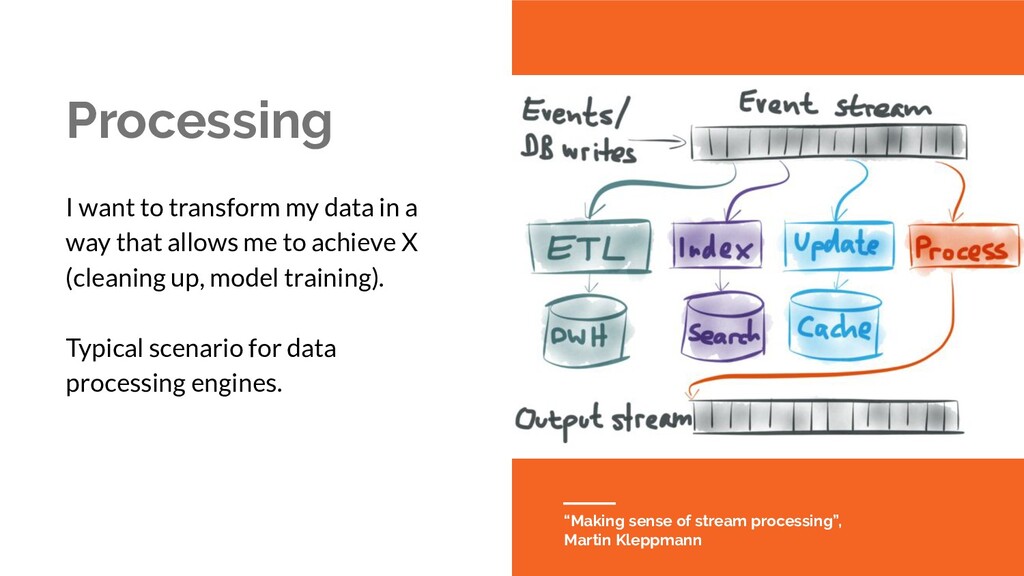
that allows me to achieve X (cleaning up, model training). Typical scenario for data processing engines. “Making sense of stream processing”, Martin Kleppmann
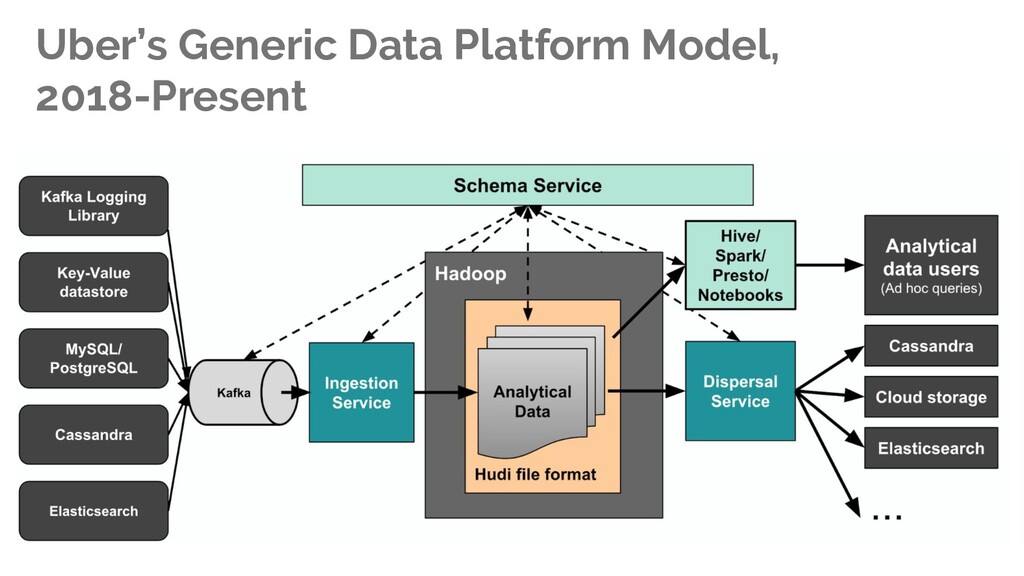
now I want to serve it to the appropriate consumer. Typical scenario for ML model training, data materialization (search … etc) and governance. Distributed File System Governance {api}
city 2. Scrape GMaps reviews of restaurants there 3. Process them w/ Apache Spark 4. Calculate trends for each block in the city ;) 5. Visualize! 6. $ Do you know what the trending restaurants in your favorite city are?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
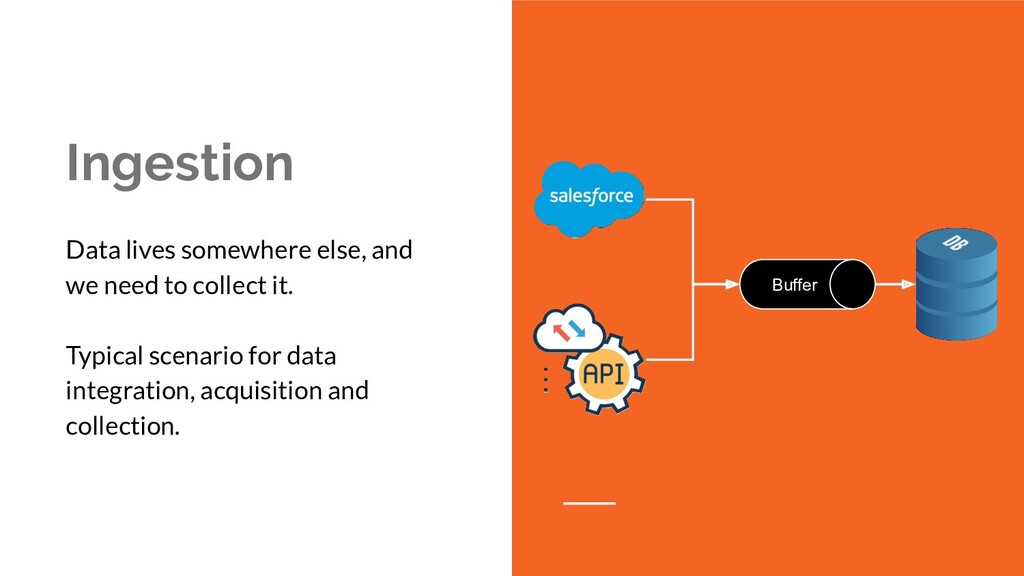{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Time Domain[1] Processing Time When did the system become aware](https://files.speakerdeck.com/presentations/d987e87d3f9649f6909c41cf3298910e/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}