• You’ve deployed your cluster- now what? • Speeding up deployments • Cleaning up after yourself • Fun with user-data • A little bit on monitoring/observability/debugging
to build/push/pull) Image size is determined (mostly), by the number of layers your image has, and how large those layers are. A few tips: • Use shared base images wherever possible • Limit the data written to the container layer • Chain RUN statements • Prevent cache misses at build for as long as possible
instruction, Docker will look at each following instruction to see if it matches the cached version. Only ADD and COPY will look at checksums for a match Other than ADD and COPY, only the string of the command is used, not the contents of the files. Once the cache is broken, every subsequent layer is built again.
important for speeding up your deploys: smaller, lighter images can build and push more quickly during your CI/CD process, and pull more quickly during your deploys.
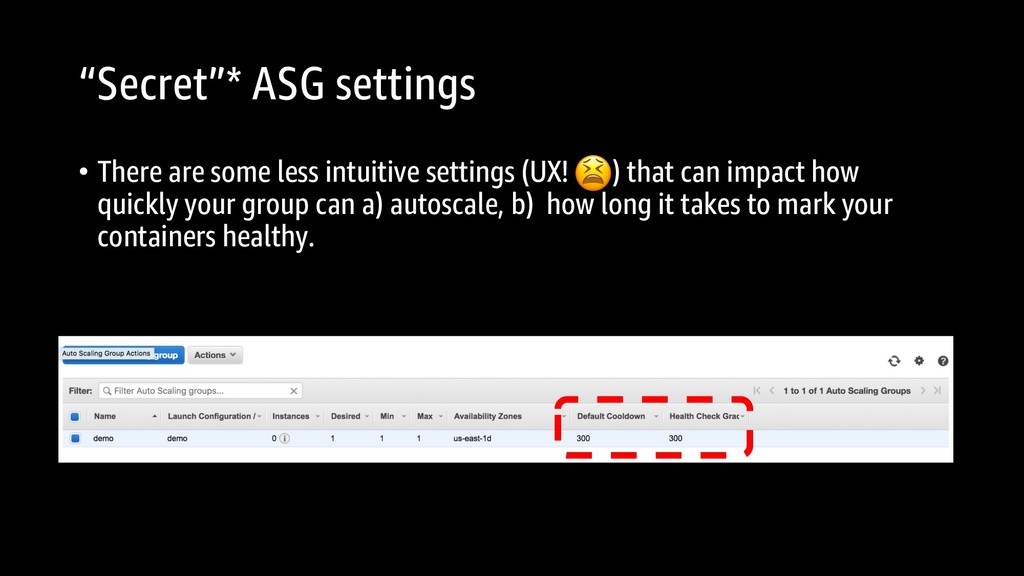
will wait before evaluating the rule again Health check grace period: amount of time, in seconds, that the autoscaling group will wait before health checking the service.
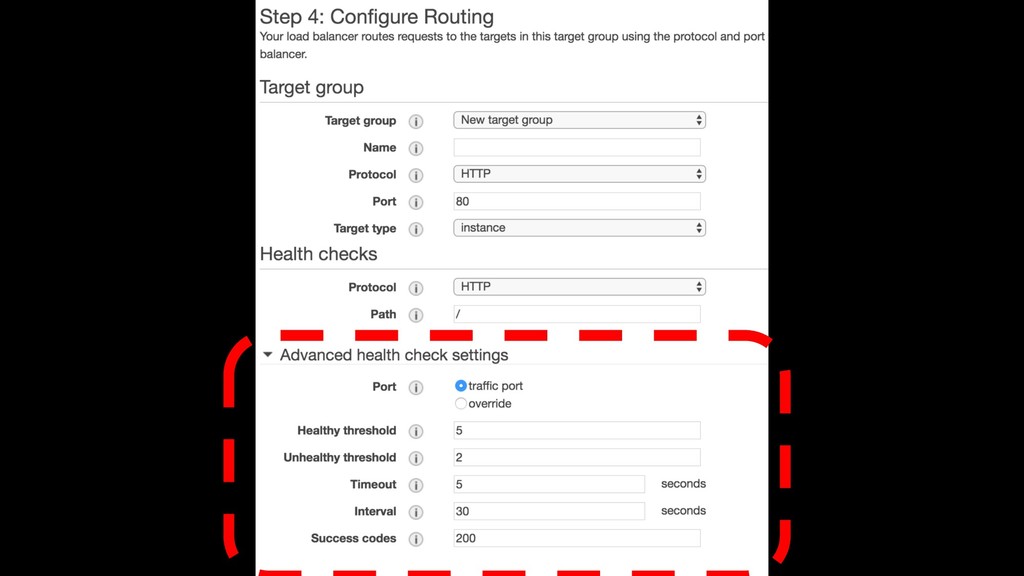
happens through a few settings: Healthy and unhealthy thresholds determine how many times your health check endpoint is tried before your container is declared healthy or unhealthy. The shorter you can make the interval between these checks, the faster your deployment will be. Be careful though- you need to give your application enough time to actually pass.
dangling/untagged images, containers, and volumes. Most orchestration platforms (like ECS/EKS, or Kubernetes) will do some garbage collection for you, but it’s not always enough. Too many unused images, containers and volumes will: • Steal your disk space • Wake you up • Cost you cash money
you can tune the options you have available for garbage collection. • If you want to cleanup more aggressively, you can look at setting these ecs-agent options*: ECS_ENGINE_TASK_CLEANUP_WAIT_DURATION ECS_IMAGE_CLEANUP_INTERVAL ECS_NUM_IMAGES_DELETE_PER_CYCLE * don’t know how to set ecs-agent options? We’ll talk about it in a second!
has a cleanup function! • Can clean up images and containers, controlled through kubelet flags • Image collection is based on disk usage • Container collection is based on flags (or the defaults) • minimum-container-ttl-duration • maximum-dead-containers-per-container • maximum-dead-containers Just like with ECS, be careful not to collect so aggressively that you lose useful containers
containers, you know the drill), aren’t the only way to lose your disk space. Log rotate is also configurable. Rotate away more files, or more often, or both. With Ubuntu, you can do that with /etc/logrotate.conf. For example, you could change monthly to daily.
customize quite a bit through the ecs-agent. This is good for things like customizing image cleanup, and changing how your instances interact with Docker and AWS (for example, changing Docker flags, or resource usage). Full list of options is available here. Options can be set in /etc/ecs/ecs.config
ECS or EKS (or Fargate, but that’s not possible yet). With EKS, this is easy! Just select your own when you start the cluster. For ECS, this is a little trickier. Fun fact: this is the icon for AMI
AMI, but life is too short to not have custom AMIs. A few steps to registering your own AMI with ECS: 0. Make sure your AMI has the right requirements! 1. Install ecs-agent 2. Install Docker daemon (if it’s not already installed) 3. Register instance with cluster 4. Optional (but good): some sort of init process to manage the ecs-agent Most of these options can be set in EC2 user-data (more on that in a sec)
it If you’re using Amazon Linux, you need the correct role, and Docker installed. If you’re not using Amazon Linux, you have a few more steps to follow: documentation is here.
shell scripts, and cloud-init directives. Or MIME multi-part files. Wild. User-data is good for everything from starting services, to configuring your environment, to enabling options and flags that aren’t supported in the UI. Scripts run at boot, and you can modify them through the EC2 Console.
use a Docker flag that’s not supported in the UI? $ echo ”WHATEVER_FLAG=hi” >> /etc/sysconfig/docker An actual, candid reaction from the ECS team when I told them I do this.
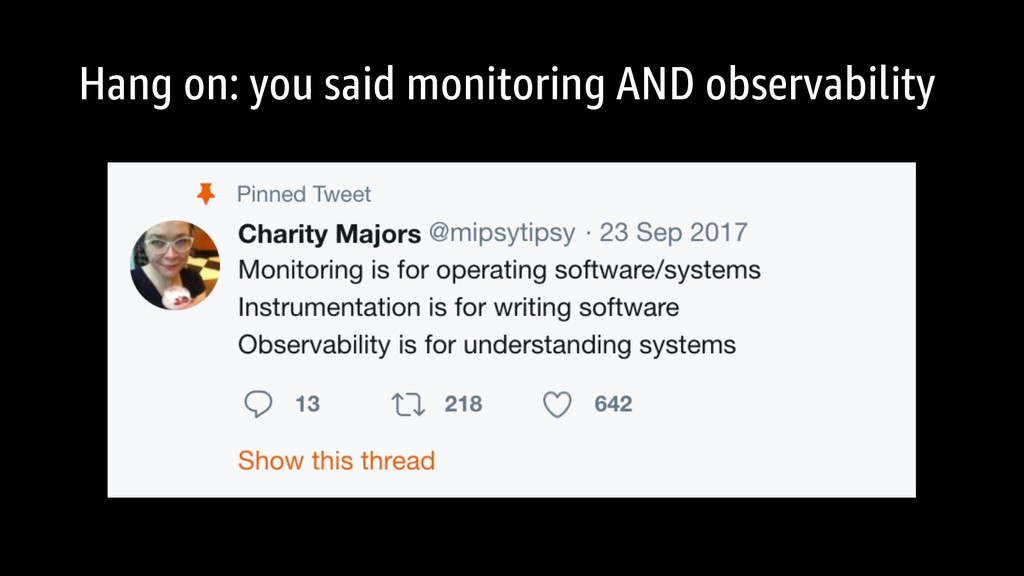
noise • Page only on issues that require immediate, emergency attention • You need all of it- both monitoring AND observability (more than just logs!) • Make sure you’re asking and answering the right questions.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}