} } { "image-vector": [1, 5, -20], "title": "moose family", "file-type": "jpg" } { "index": { "_id": "2" } } { "image-vector": [42, 8, -15], "title": "alpine lake", "file-type": "png" } { "index": { "_id": "3" } } { "image-vector": [15, 11, 23], "title": "full moon", "file-type": "jpg" }
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
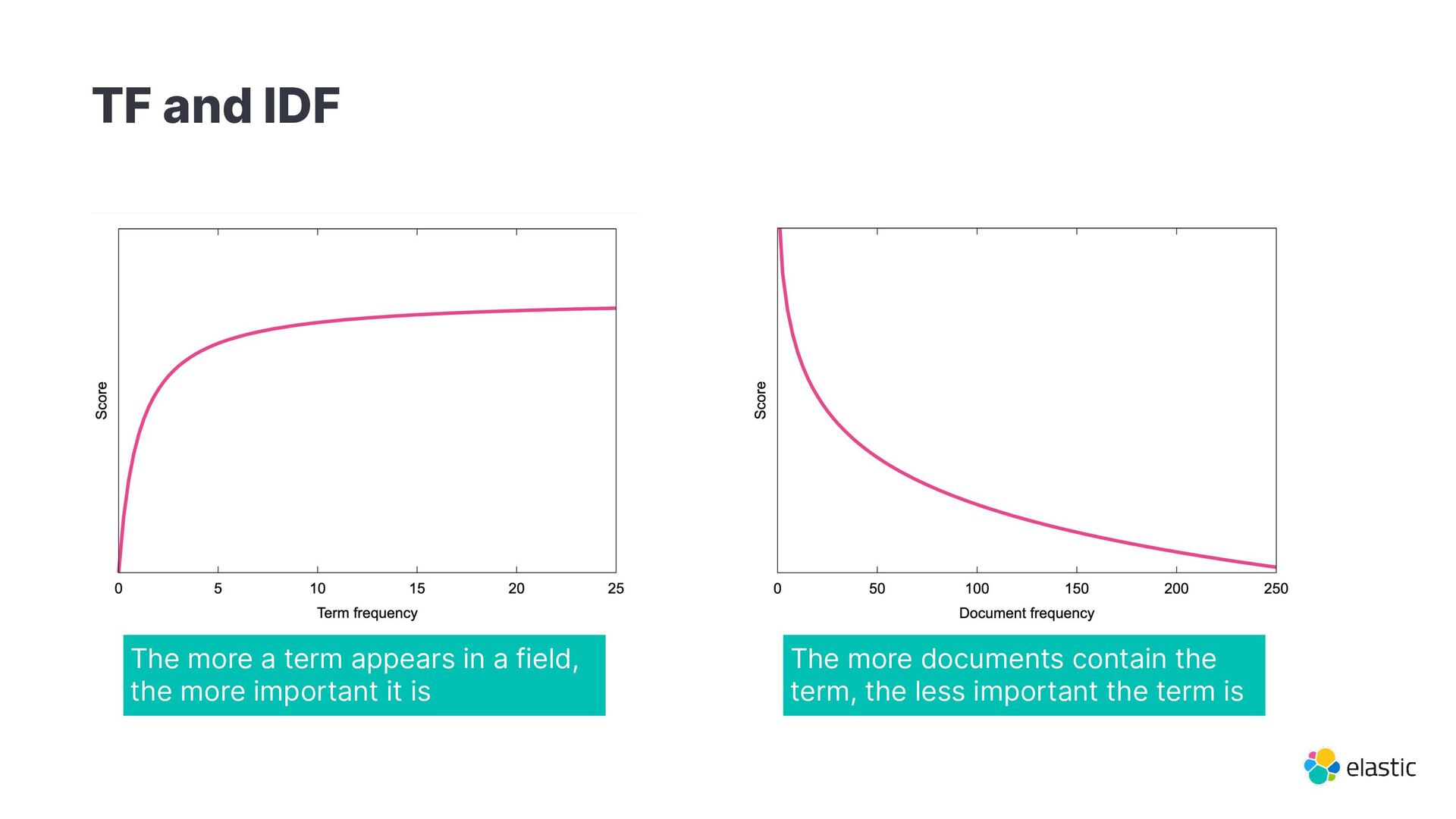{kind=link}
{kind=link}
{kind=link}
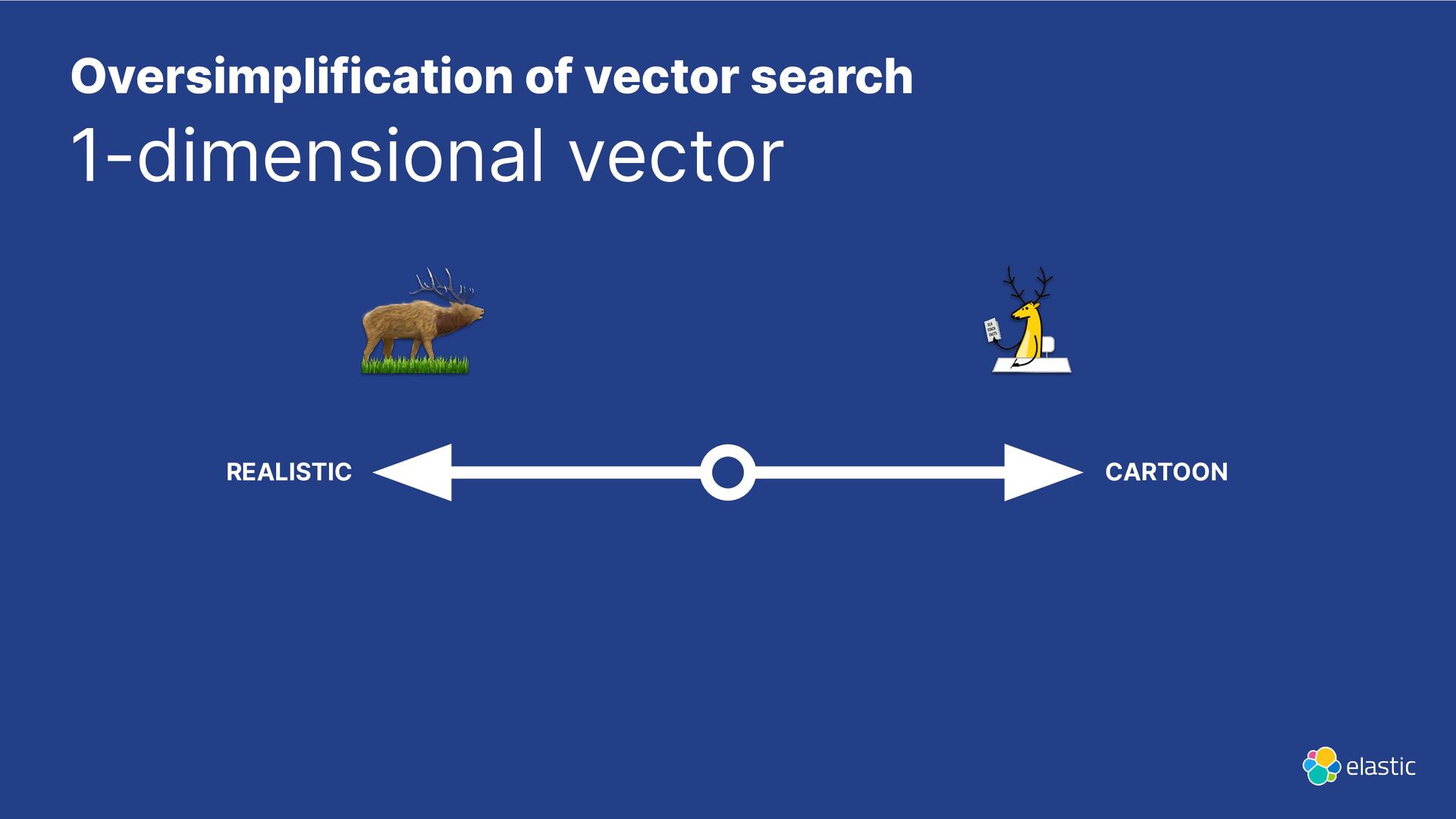{kind=link}
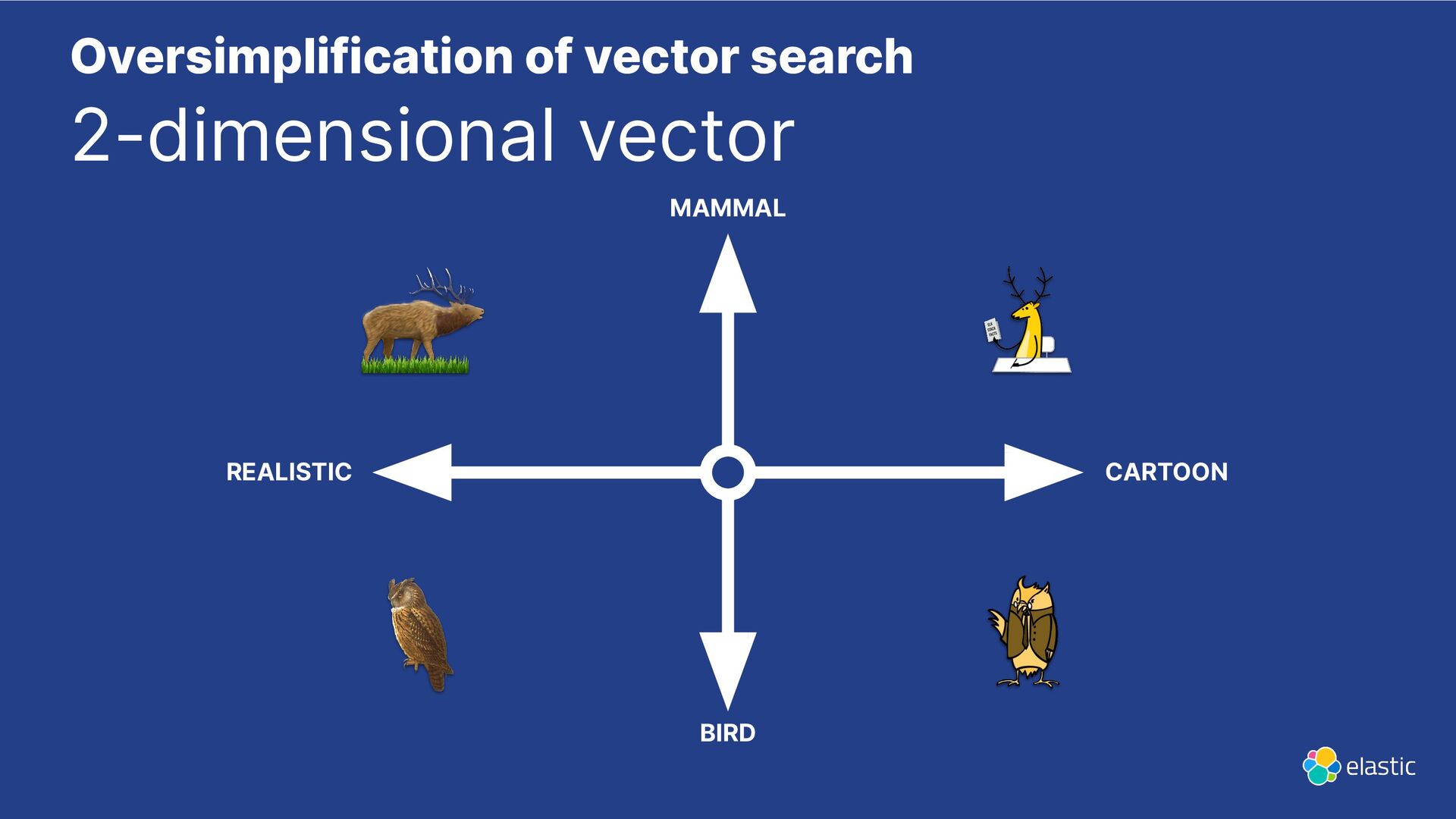{kind=link}
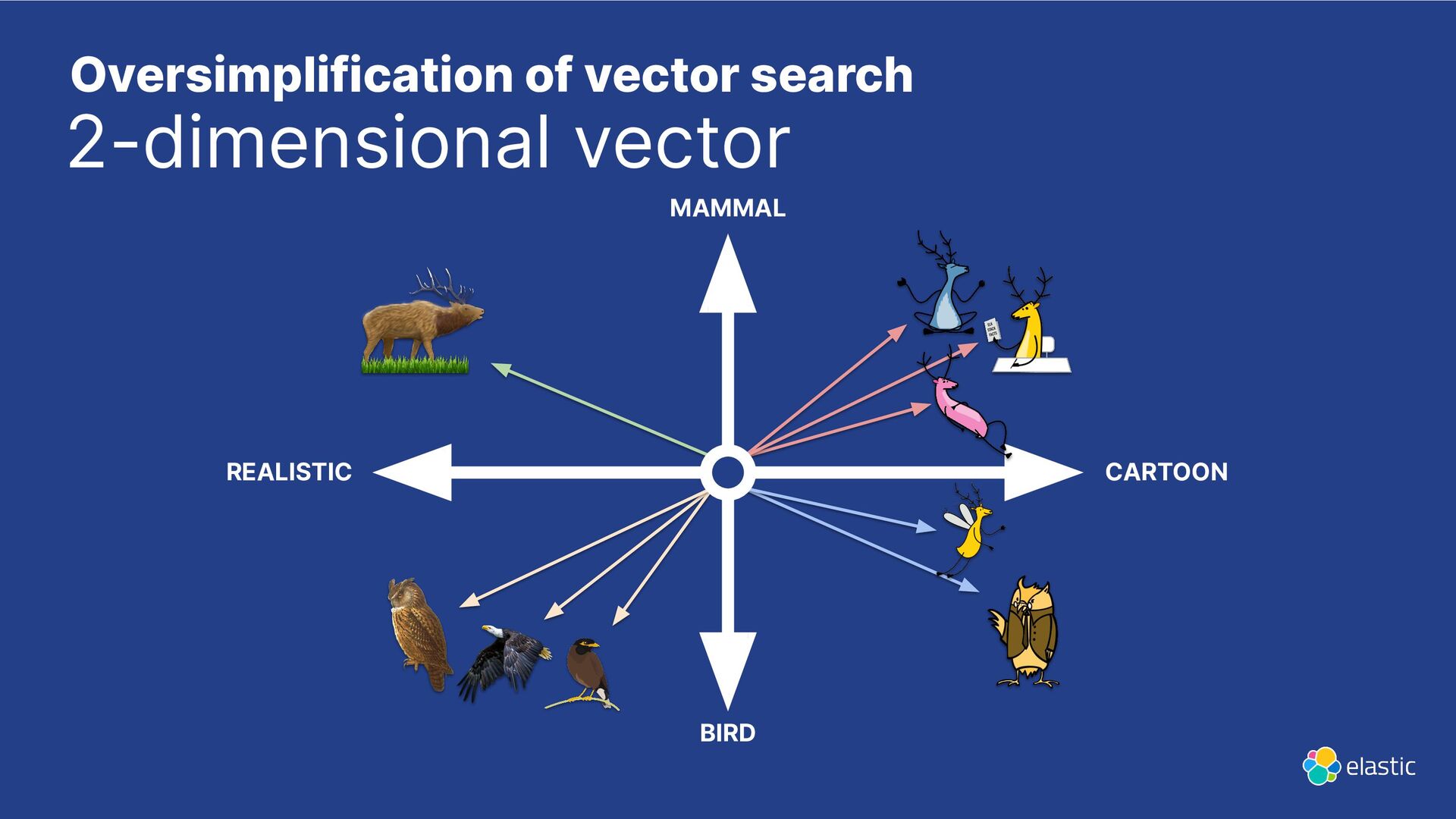{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}