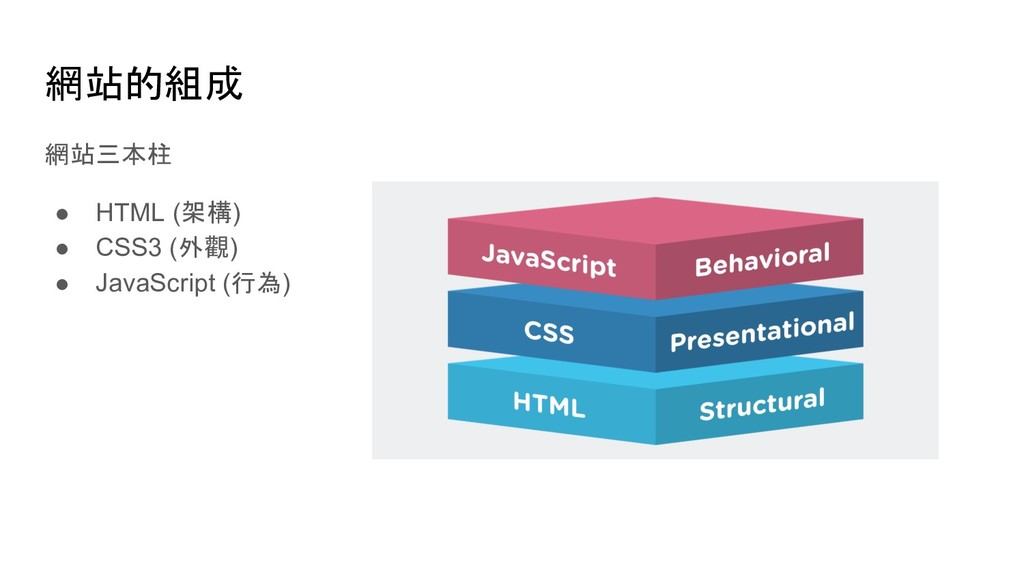
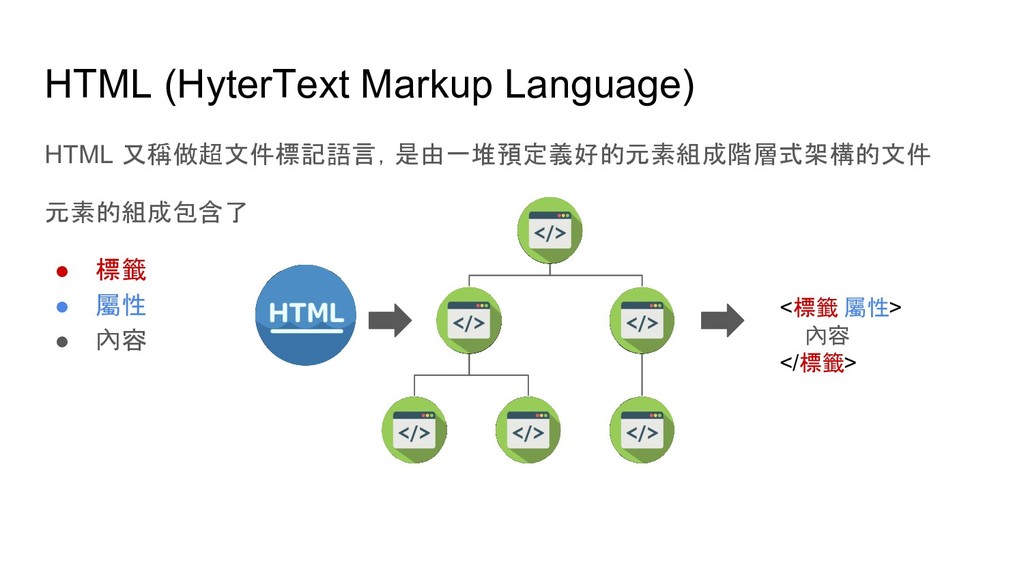
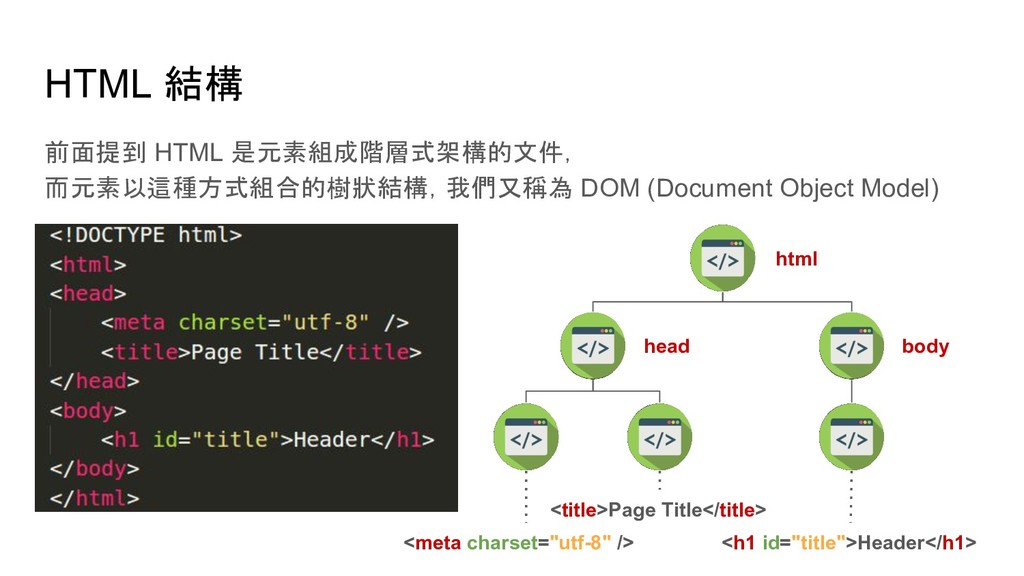
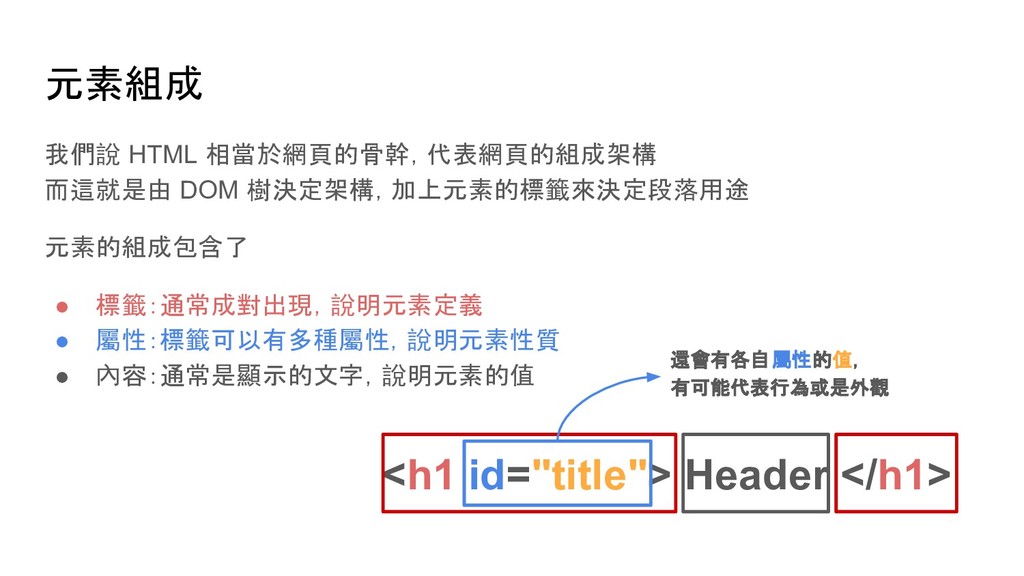
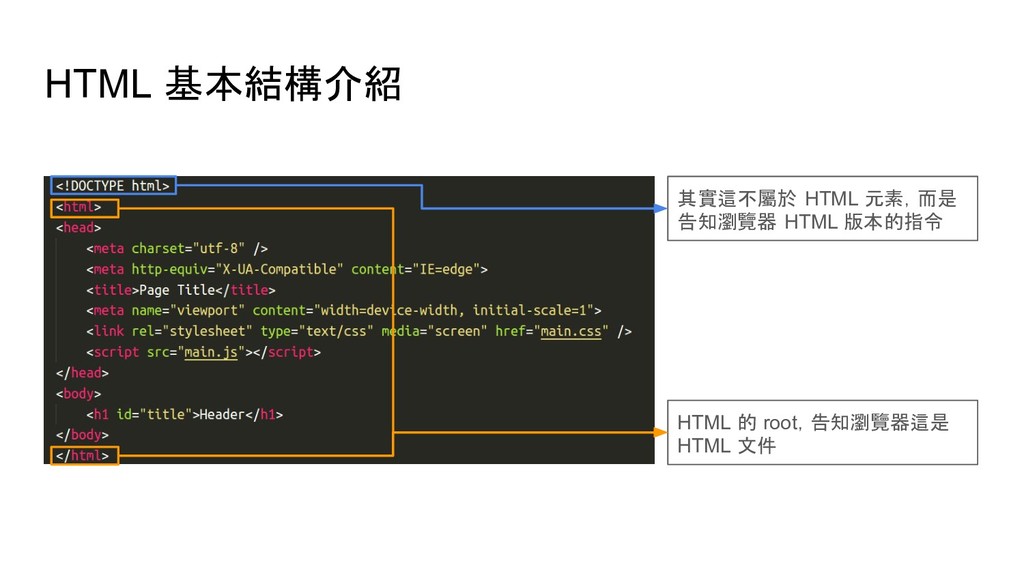
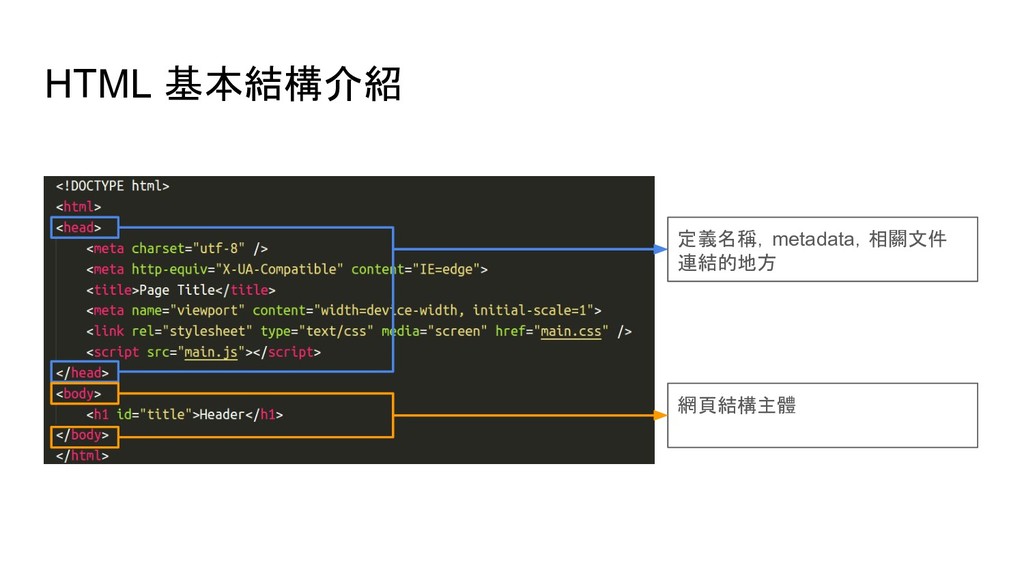
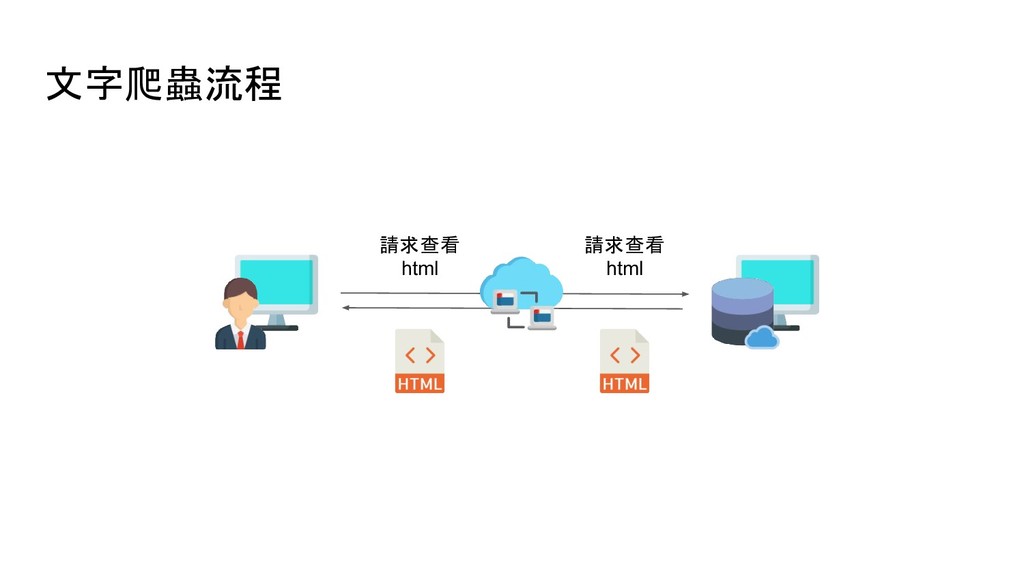
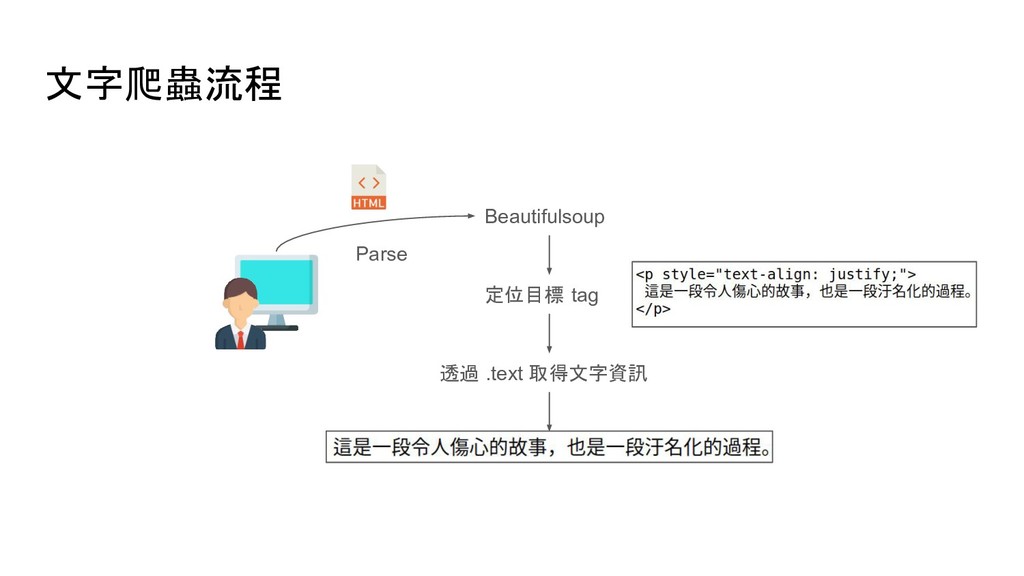
soup.find('p') # 尋找網頁中第一個 p tag soup.find_all('p') # 尋找網頁中所有 p tag # 尋找網頁中所有 id 是 main 的 p tag soup.find_all('p', {'id': 'main'}) soup.p.img # 尋找網頁中第一個 p tag 底下的 img tag soup.p['style'] # 取得 p tag 中 style 屬性的值 soup.p.text # 取得 p tag 中的文字
soup.select('.test') # 尋找所有 css class 為 test 的 tag soup.select('#test') # 尋找所有 id 為 test 的 tag soup.select('div, p') # 尋找所有的 div 與 p tag soup.select('div p') # 尋找所有 div 中的 p tag soup.select('div > p') # 尋找所有 parent 是 div 的 p tag soup.select('a[href^="url"]') # 尋找所有連結開頭是 url 的 a tag 參考內容:CSS Selector Reference,CSS Selector Tester
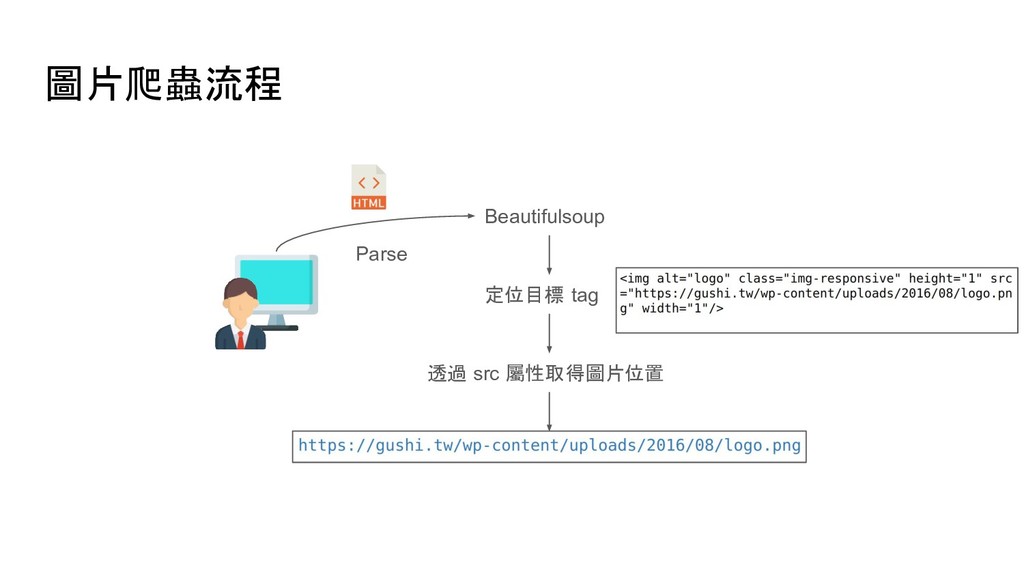
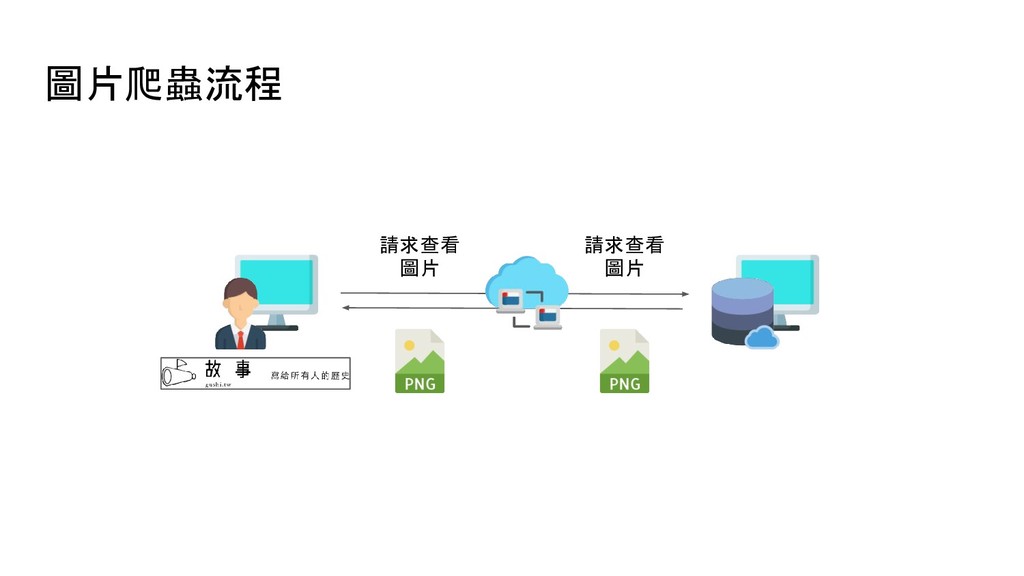
= requests.get(image_url, stream=True) with open('logo.png', 'wb') as f: # receive 10240 bytes per chunk for chunk in resp.iter_content(chunk_size=10240): f.write(chunk) 程式執行結束後,就會把圖片下載下來並存成 logo.png
import By # 尋找所有 p tag driver.find_elements(By.XPATH, '//p') # 尋找任意 id 為 first 的 tag driver.find_elements(By.XPATH, '//*[@id="first"]') # 尋找任意 id 為 second 或 third 的 h2 tag driver.find_elements(By.XPATH, '//h2[@id="second"] | //h2[@id="third"]' )
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![練習 爬取 PTT 上標題如下的所有文章 [新聞] 2噸水晶球沿街滾 撞壞5輛汽 機車和民宅 • URL](https://files.speakerdeck.com/presentations/3b577cf9d728493a940455485300dd40/slide_175.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}