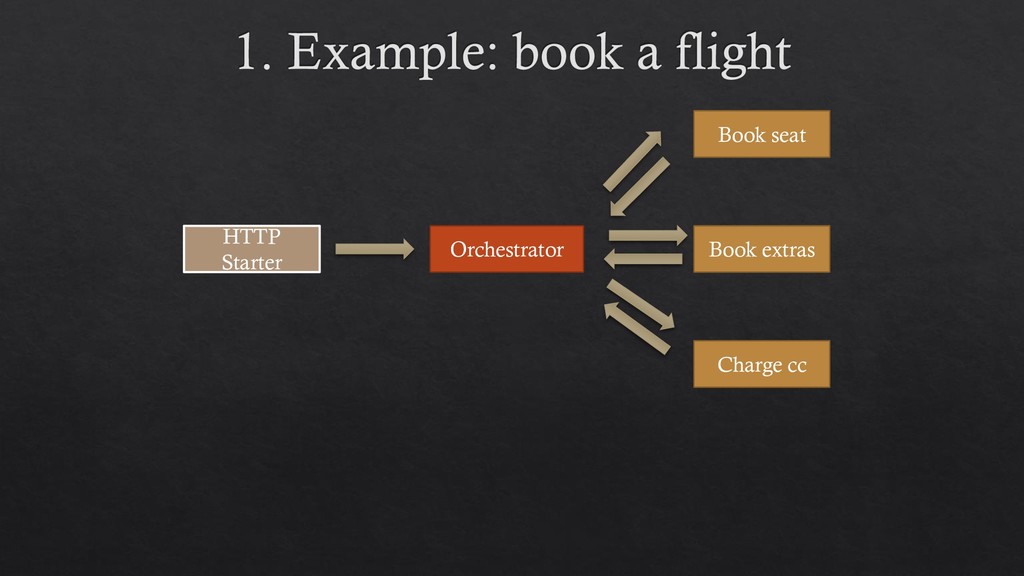
solution of course. Book seat Book extras Charge credit card Orchestrator 1) Orchestrator 2) Events Choreography 3) Route slip Should we use an orchestrator?
there are still some problems: 1. What if the orchestrator is not available? 2. How to recover from crash? 3. Should we save his state? Where/how? Orchestrator
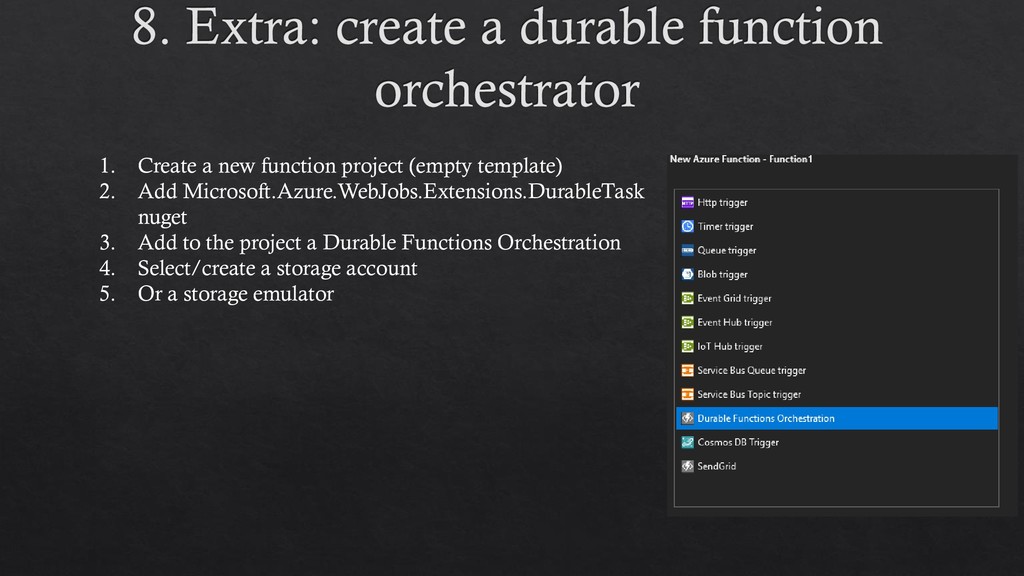
Microsoft.Azure.WebJobs.Extensions.DurableTask nuget 3. Add to the project a Durable Functions Orchestration 4. Select/create a storage account 5. Or a storage emulator
orchestrator are executed on single threads, can’t block or be slow. Also they are run many times per instance, use activities if you don’t want to pay more. 3. No DateTime: use context.CurrentUtcDateTime (i.e. now +30min?) 4. No infinite loop: use context.ContinueAsNew (because of event history)
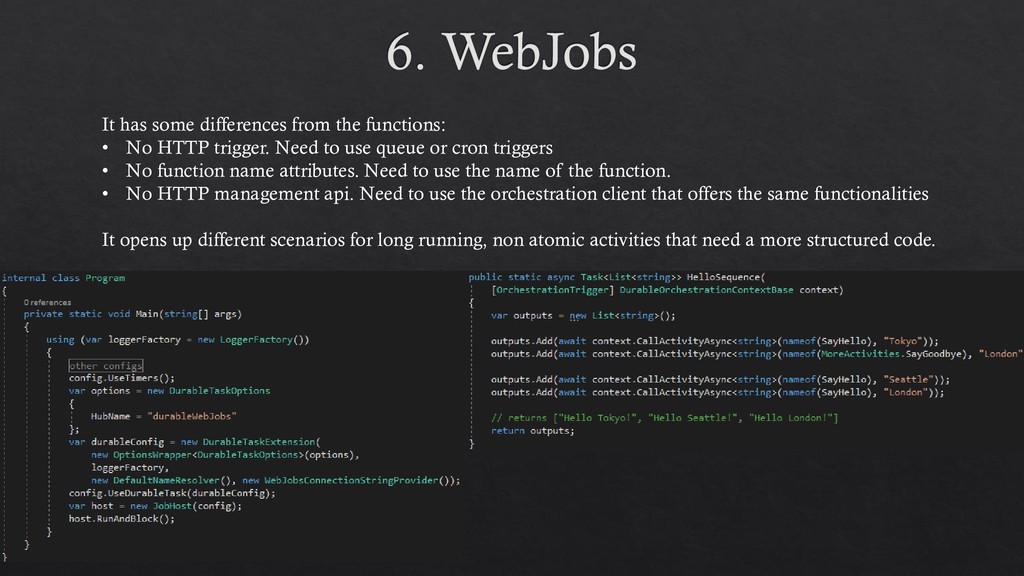
trigger. Need to use queue or cron triggers • No function name attributes. Need to use the name of the function. • No HTTP management api. Need to use the orchestration client that offers the same functionalities It opens up different scenarios for long running, non atomic activities that need a more structured code.
SAGA pattern with an orchestrator. In fact ,one of the main difficulties of implementing such a pattern is to build a reliable long running orchestrator: • It needs to be stateful • It needs to be resilient to crashes Luckily these characteristics are provided off the shelf by the extension and there is no need to add code for the infrastructure.
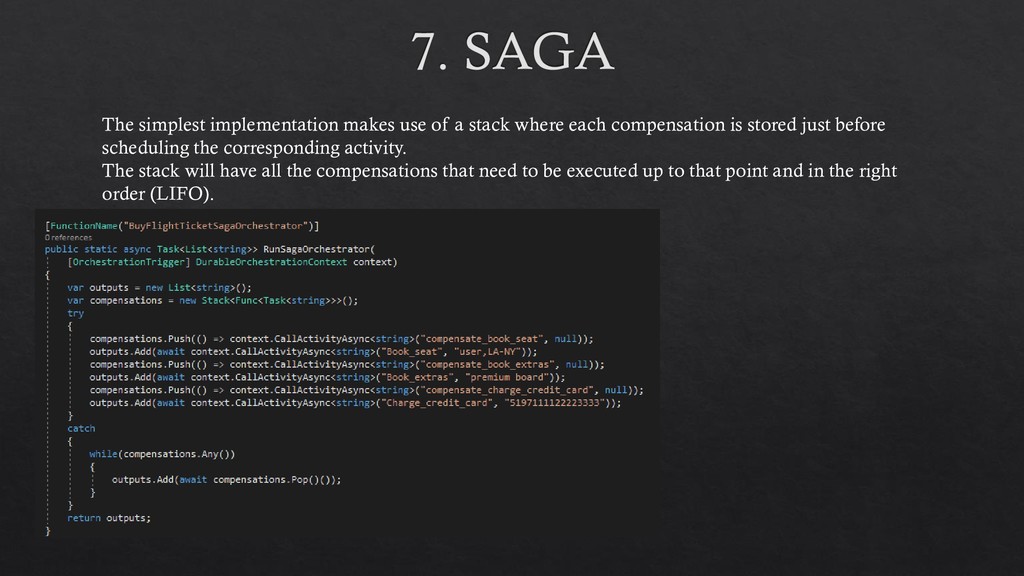
compensation is stored just before scheduling the corresponding activity. The stack will have all the compensations that need to be executed up to that point and in the right order (LIFO).
Insight: It’s a queue world. 1. Introduce your correlation ids, embed it into the payload and extract it when logging 2. No metrics for durations, you need to roll your own and it’s useful to understand how the system behaves 2. Problems I faced: 1. Scalability issues with dynamic hub name configuration. (It’s being tracked as a bug) 2. (azure functions in general) EF core version depends on the azure function underlying infrastructure. EF core 2.2.4 not yet supported at time of writing. 3. It’s async processing. Don’t use it for sync unless you have a dedicated plan and a quick execution.
two different environment with the same storage account but isolate them through a different custom name (don’t do it for prod). 2. Examine the underlying storage infrastructure to understand how it works (but don’t rely on it for functionality): • History table • Queues • Locks on queues blobs 3. Is based on at least once delivery (azure storage queues), so idempotency is required for your steps.
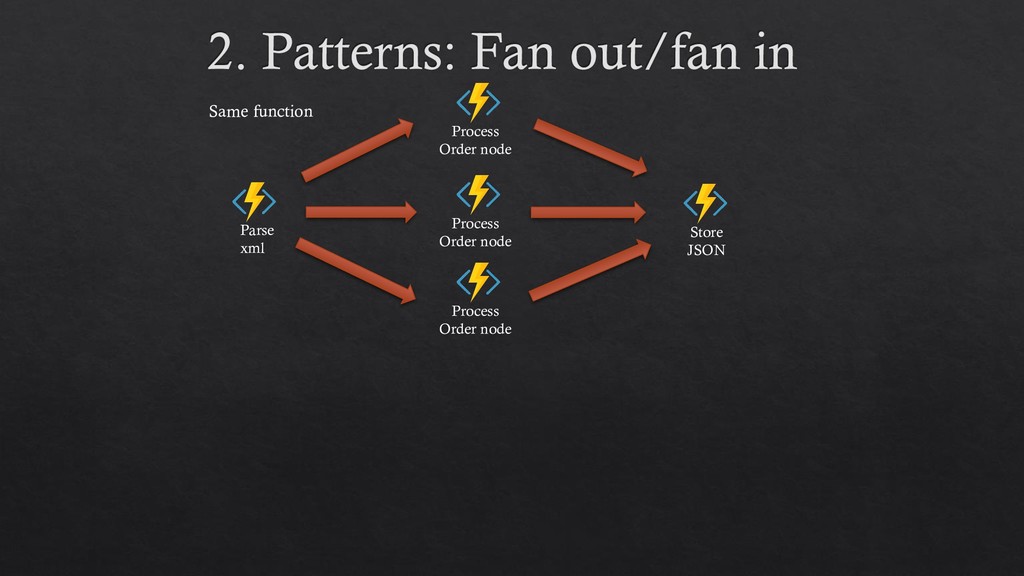
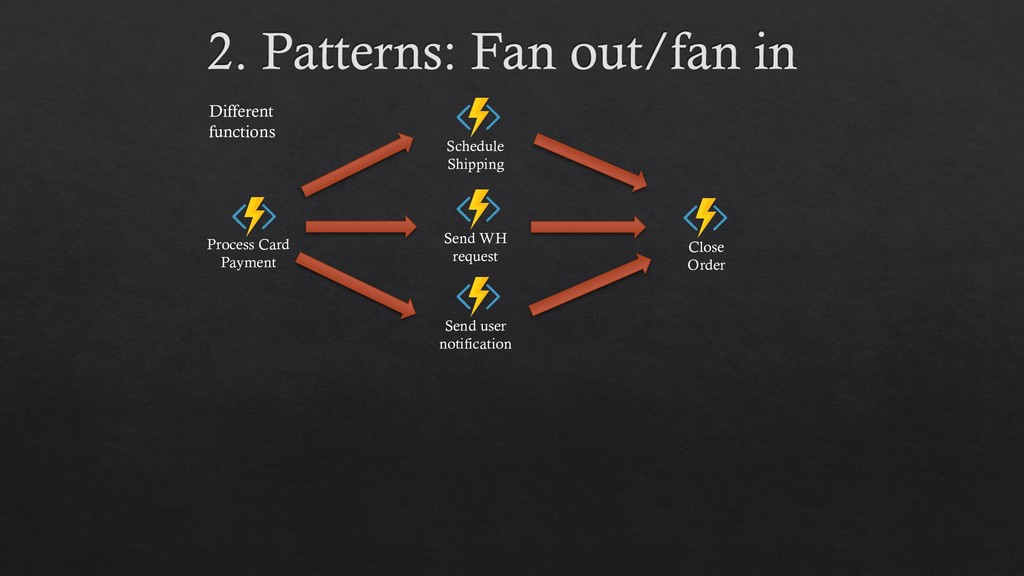
hidden 3. It is designed and implemented following cloud patterns (event sourcing, claim-check, partitioning) 4. Define workflow through code. No JSON, no yaml, no designer 5. Work with tasks -instead of queues and event sourcing tables- which is a more comfortable environment for devs. 6. Many important patterns become trivial to implement: fan in/fan out, http client status polling 7. Serverless advantages: scalability and billing. 8. Seems ready for SAGA (we haven’t seen it yet).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}