に近づいている ➢ 自動化・AIへの移譲は進んでもデータ分析の全体プロセスは変わ らないのではないか? ➢ Ubieデータ分析基盤に求められる責務はデータパイプラインの構 築・運用という狭いプロセスではなく、 end-to-end の分析ライフサイクル (ADLC) のenablingへ ➢ ライフサイクル中の各プロセスをよく理解し、生成 AI含め 適切なhowを提供し、データ利活用推進する roleへchange The Analytics Development Lifecycle (ADLC) https://www.getdbt.com/resources/the-analytics-develop ment-lifecycle You are the best judge of how you are maximally effective. https://www.getdbt.com/resources/the-analytics-development-lifecycle より
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
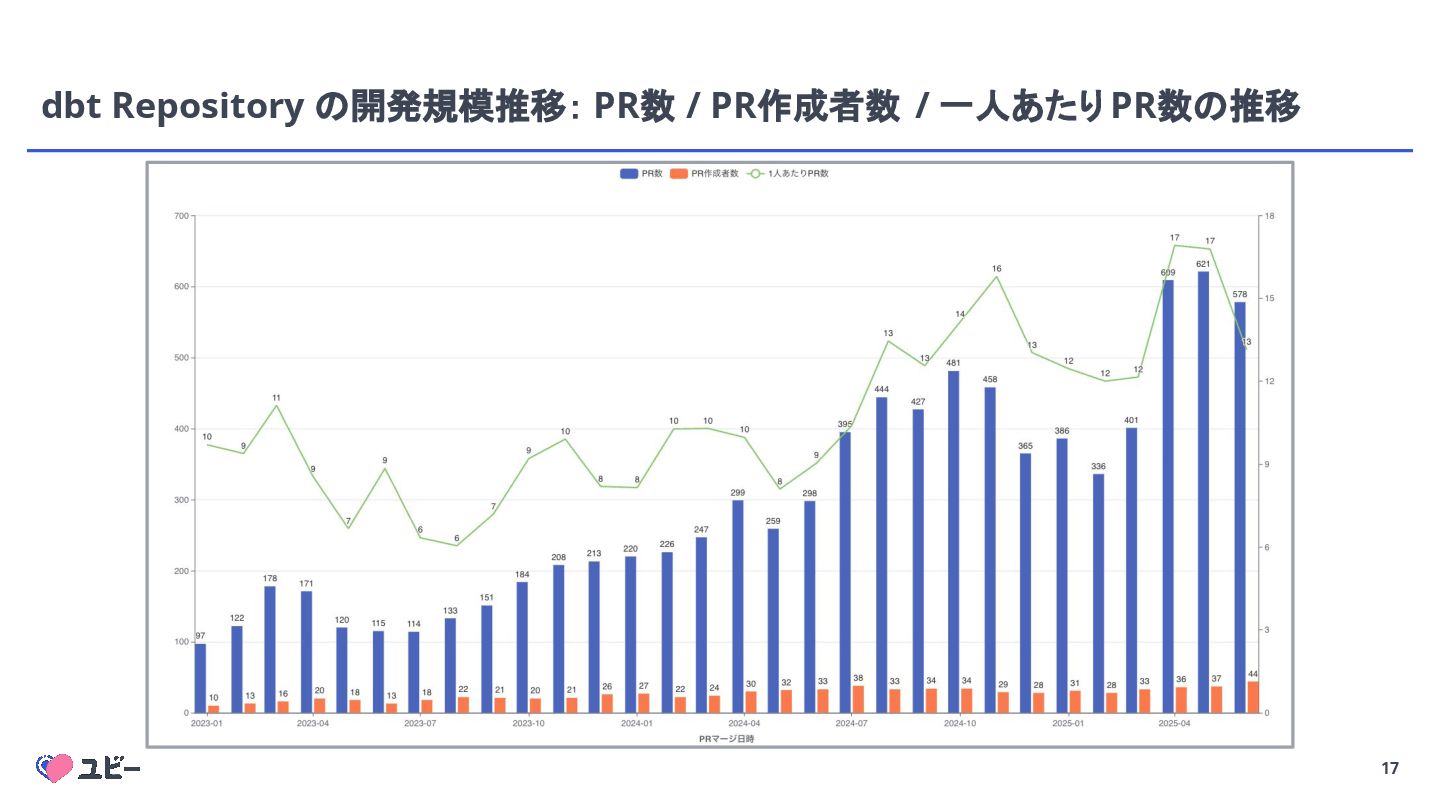{kind=link}
{kind=link}
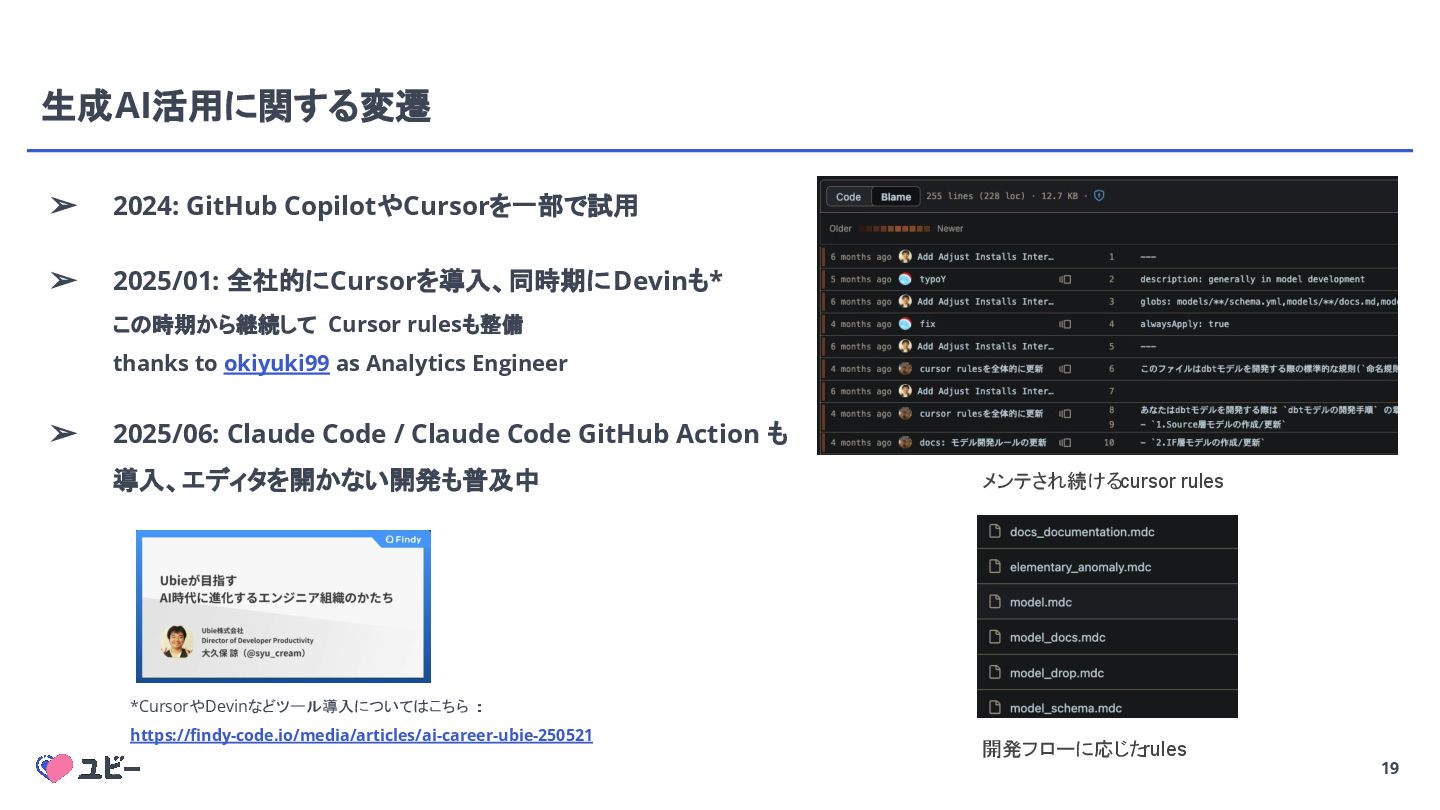{kind=link}
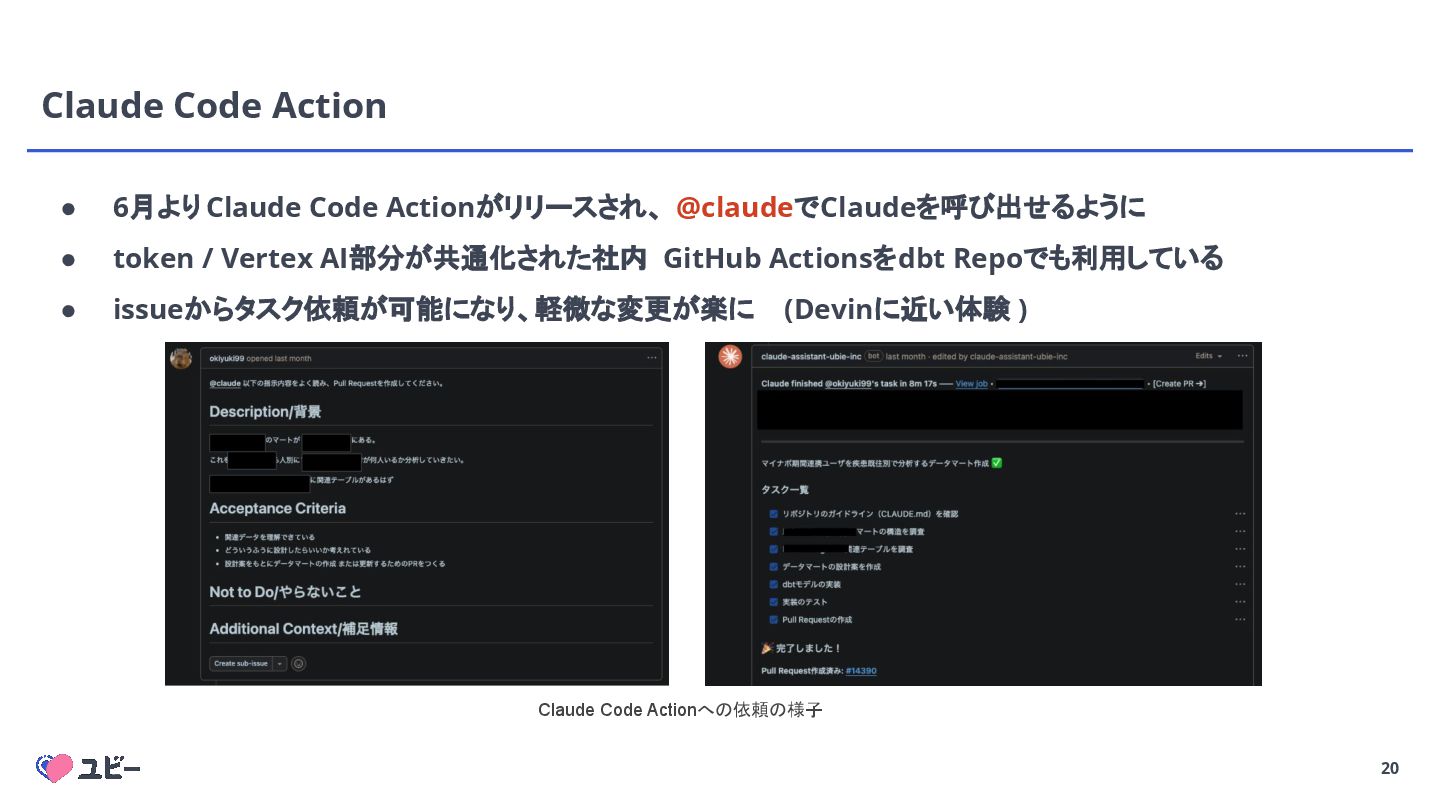{kind=link}
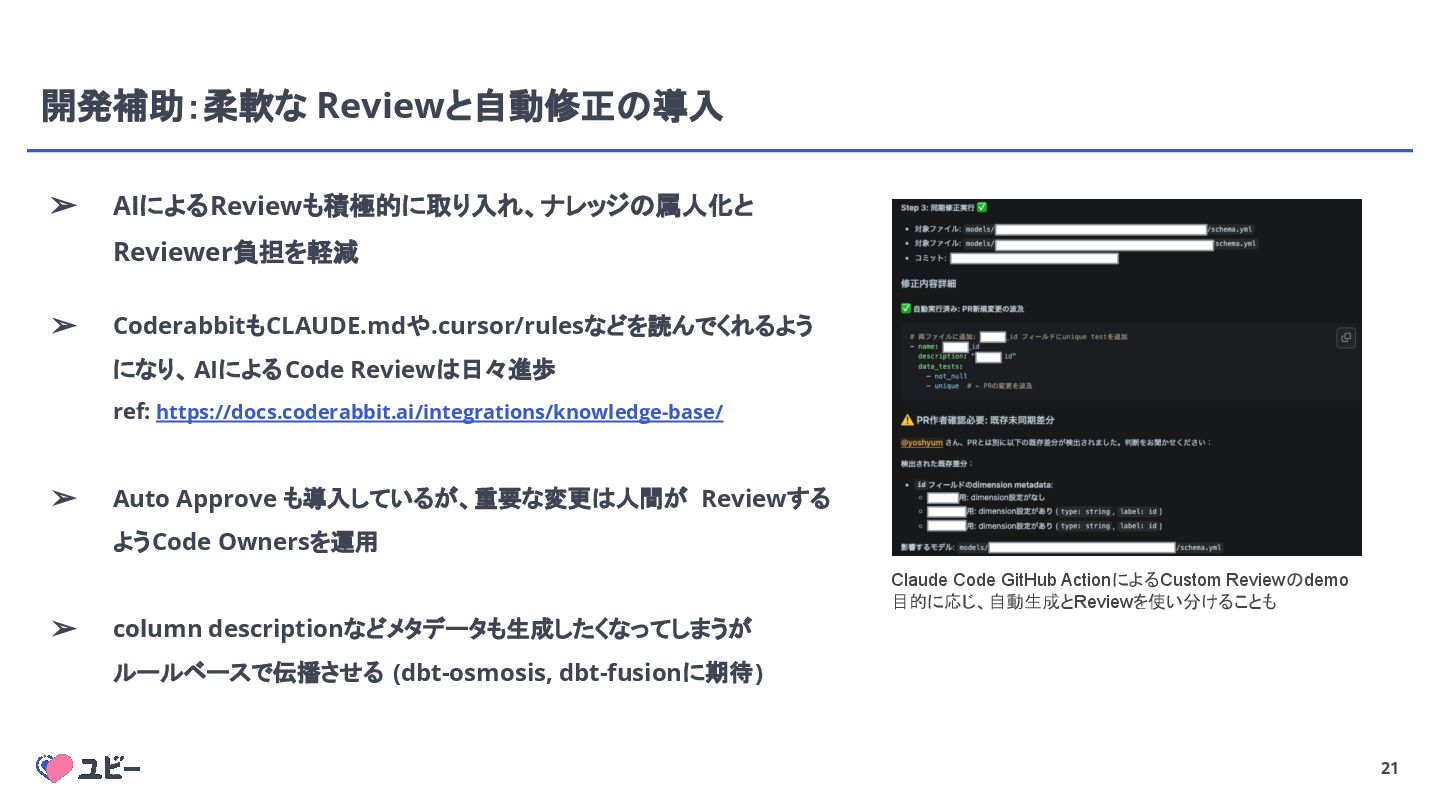{kind=link}
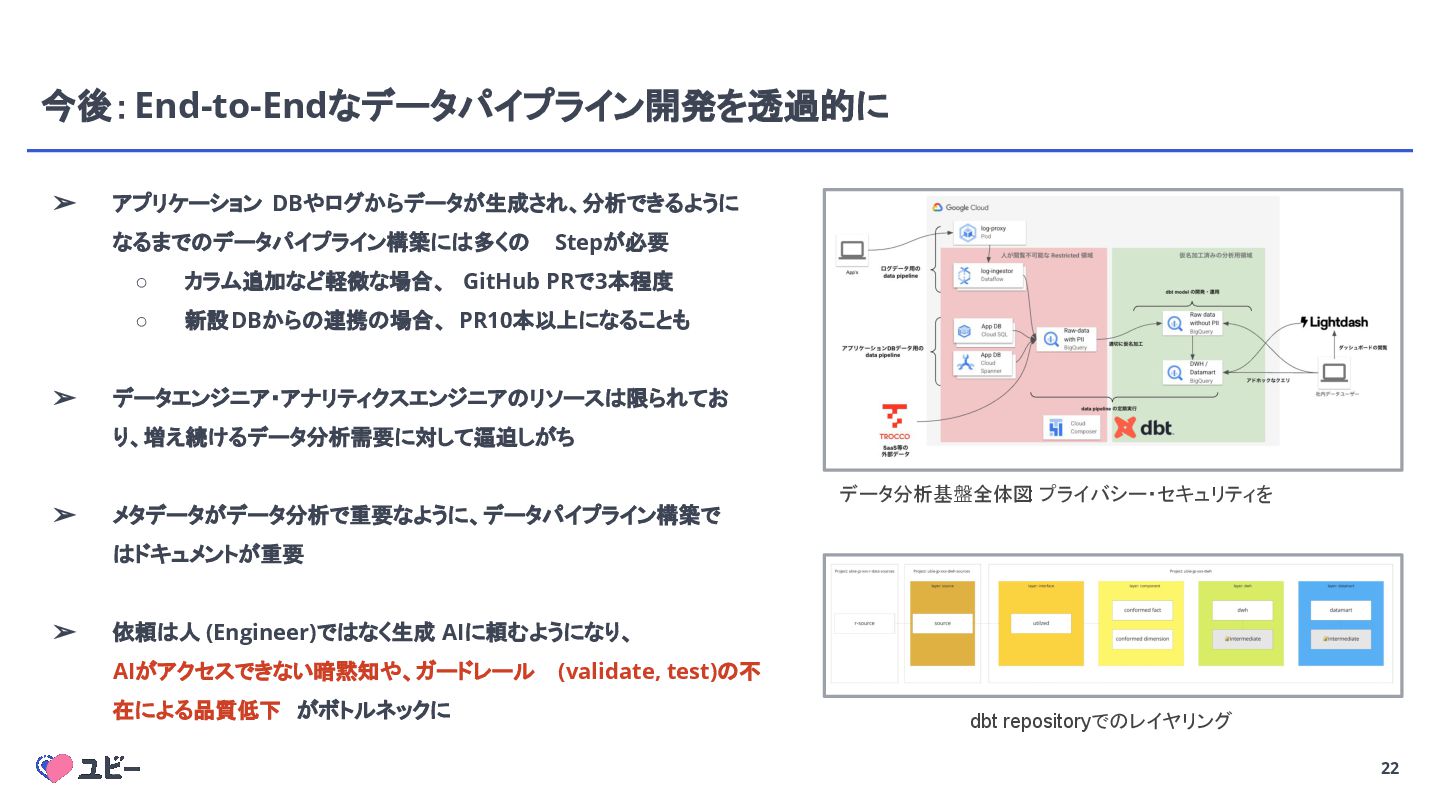{kind=link}
{kind=link}
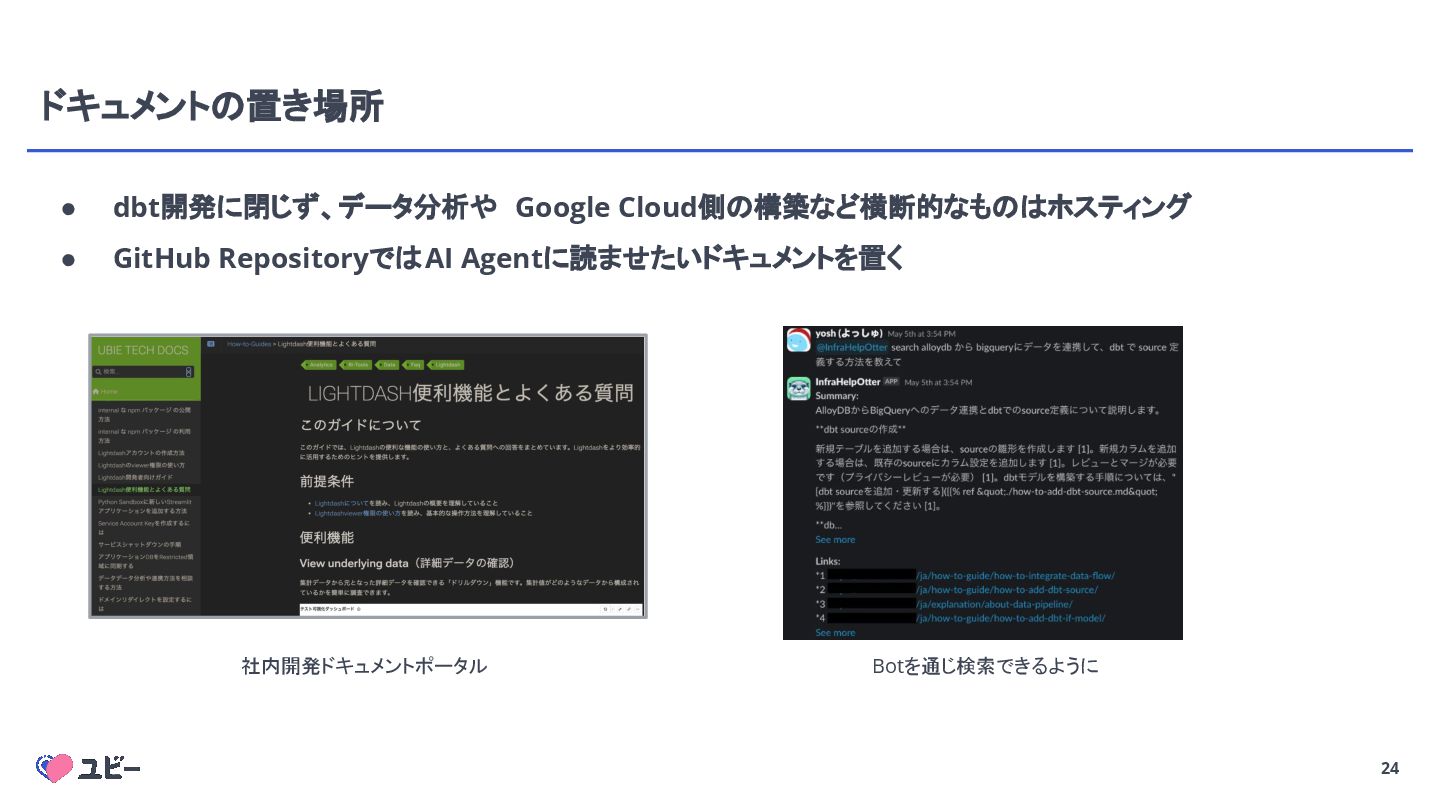{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}