Conférence AFUP Montpellier – 10 juin
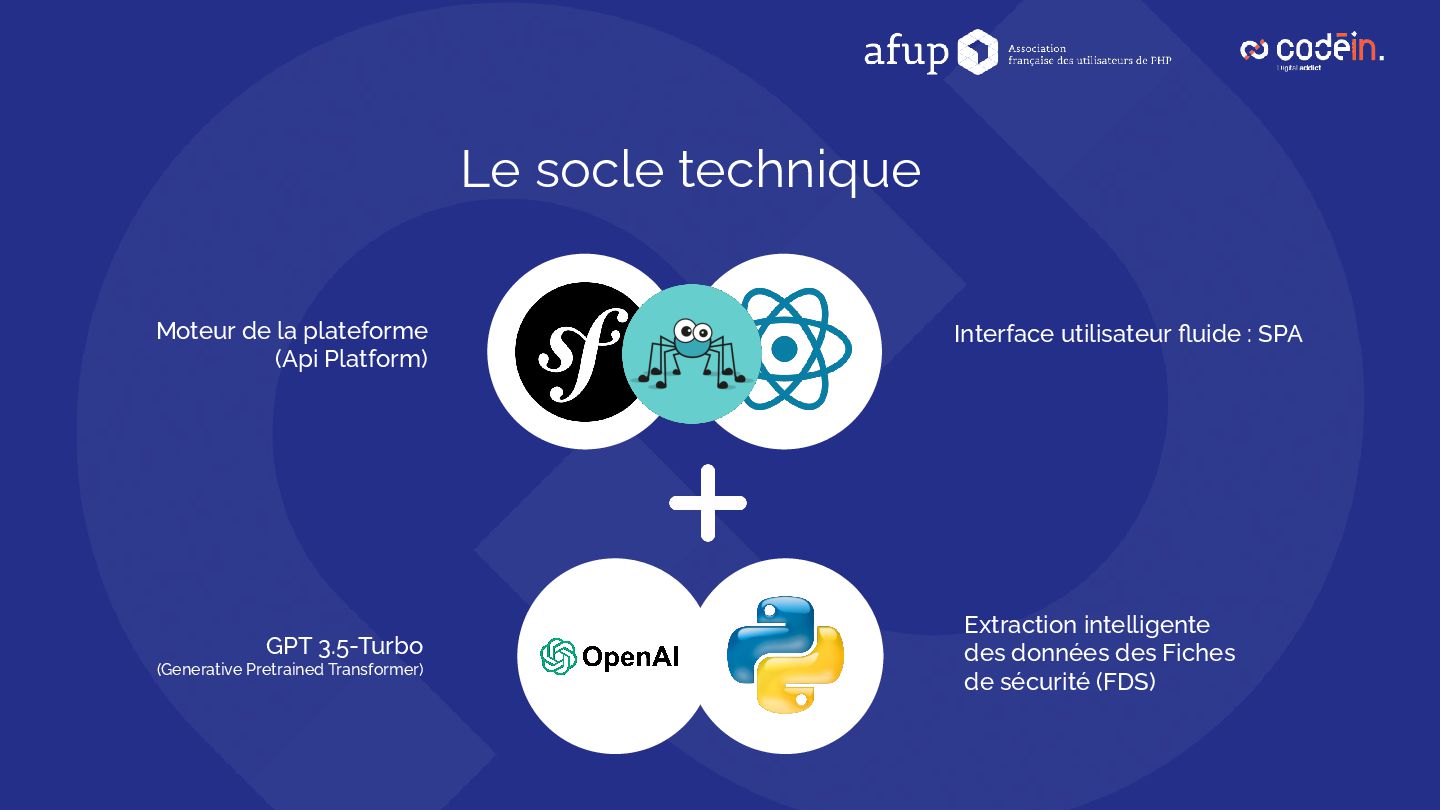
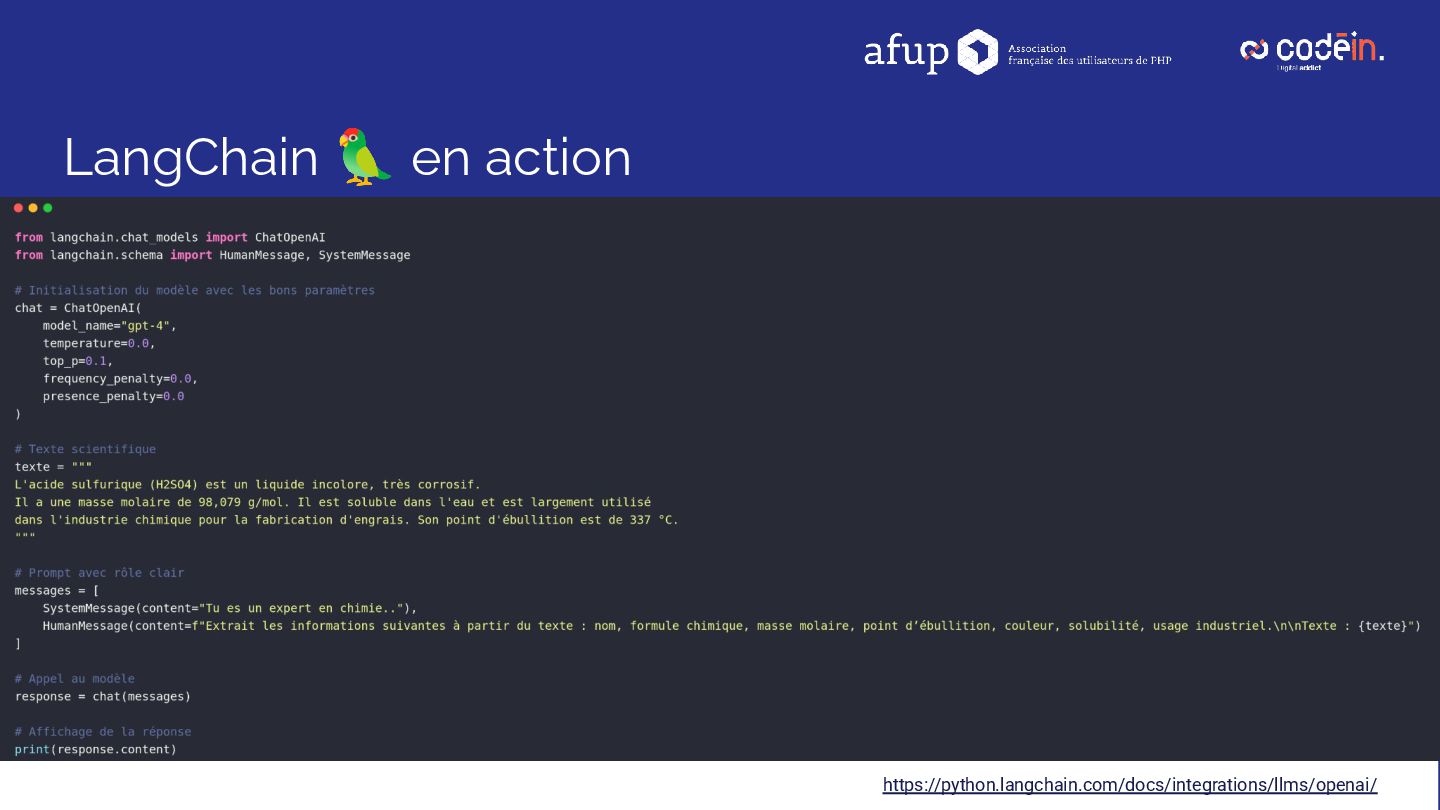
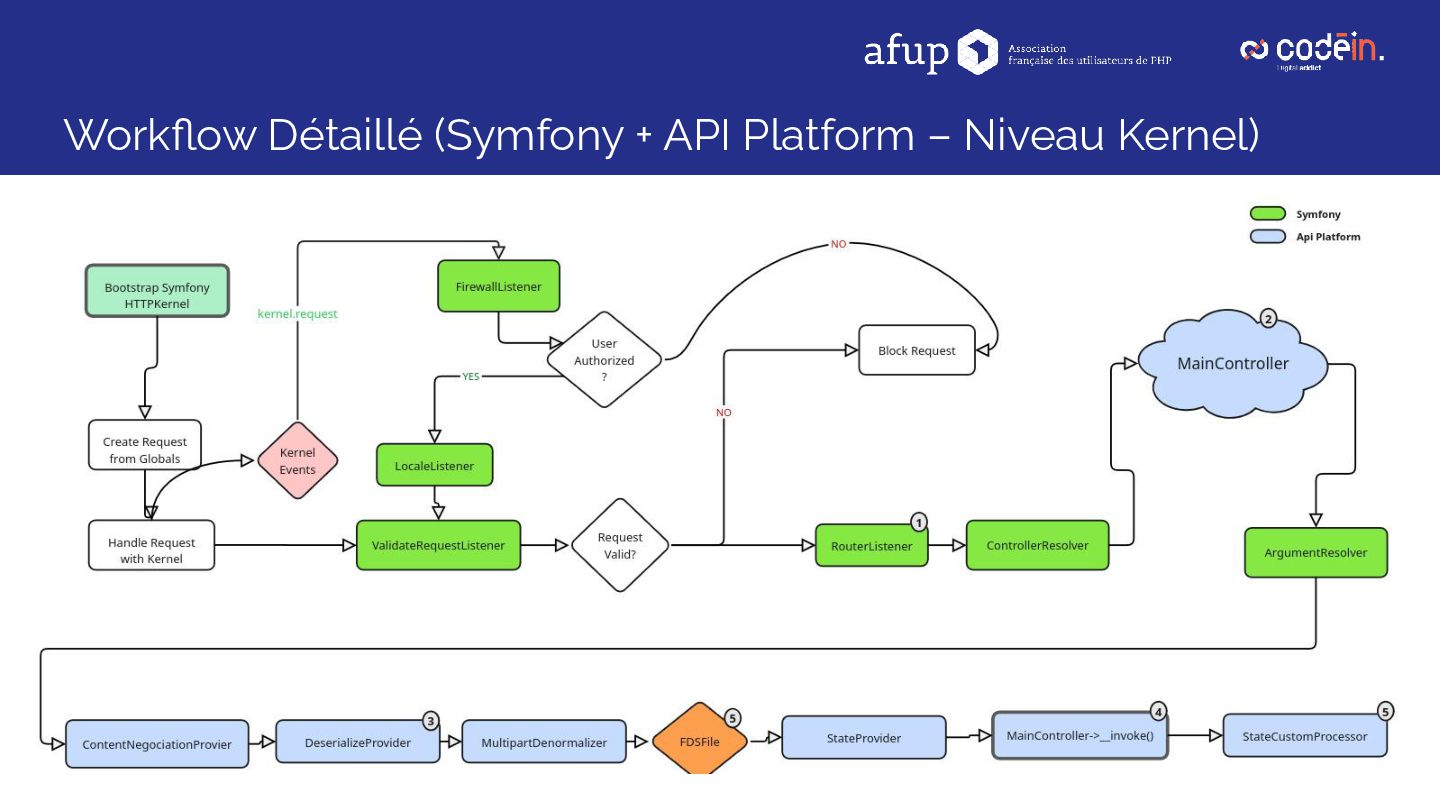
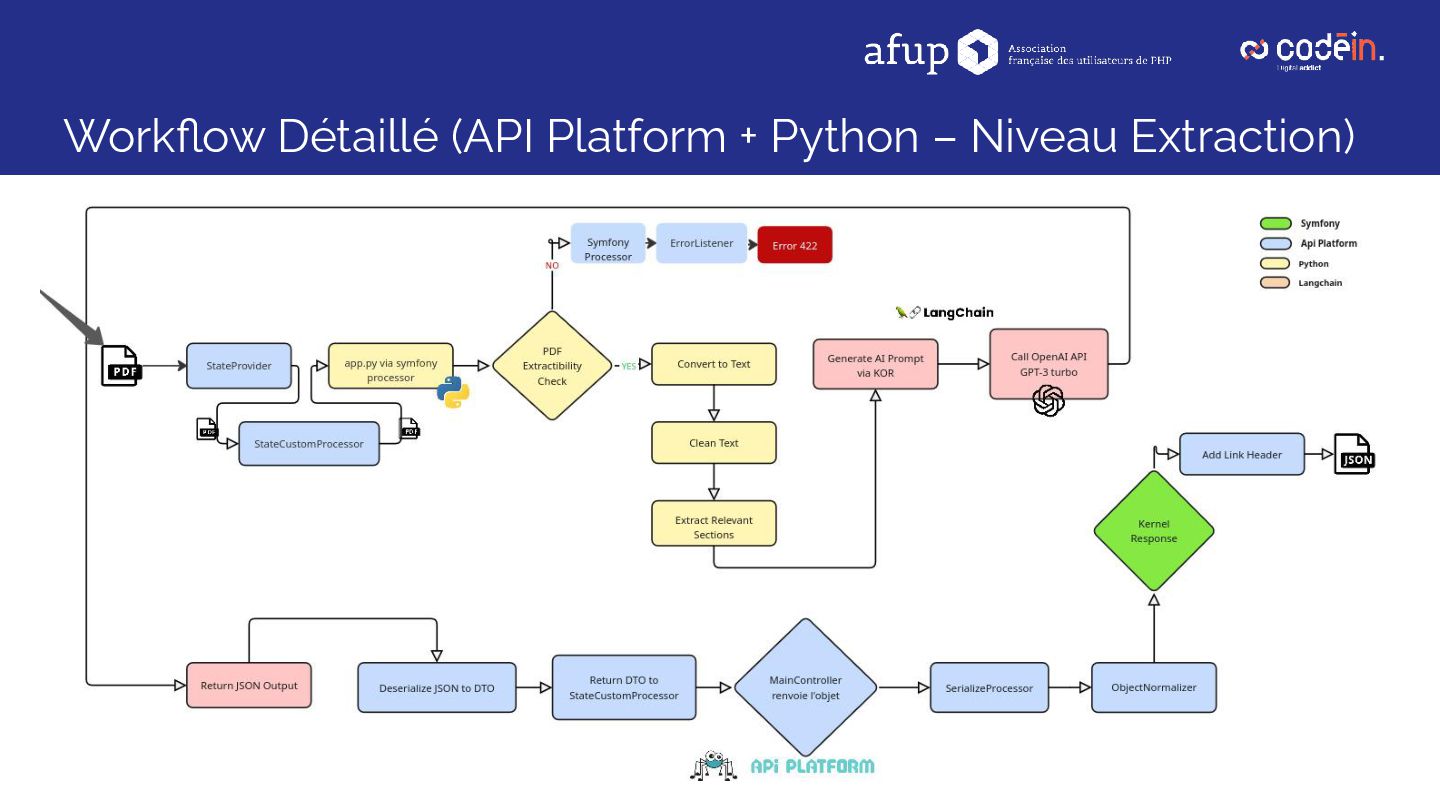
Retour d'expérience sur le déploiement d'une solution d'IA en production, combinant Symfony, API Platform, LangChain et OpenAI, pour automatiser l'analyse des Fiches de Données de Sécurité (FDS) — l'équivalent, pour les produits chimiques, des notices pour les médicaments : de véritables cartes d'identité détaillant risques, substances, pictogrammes et précautions d'usage.
L'objectif : remplacer une saisie manuelle longue (20 min/document) par une extraction automatisée, fiable et structurée.
Un enjeu majeur pour les professionnels du BTP, exposés chaque jour à des produits potentiellement dangereux et soumis à des obligations strictes en matière de sécurité.
En résumé : une sorte de Yuka des produits chimiques, au service de la prévention sur les chantiers.
Résultat : un traitement 10 fois plus rapide, une nette réduction des erreurs, et une architecture IA robuste, évolutive et prête pour l’échelle industrielle.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}