the data and p (+) and p (-) are the probability of positive or negative cases in subset S. Interpretation: If X ∈ S, how many bits are needed to determine whether X is positive or negative?
Depth: Principal Component Analysis) 2. Leskovec, J., Rajaraman, A., & Ullman, J. D. (2014). Mining of massive datasets. Cambridge University Press. (Section 11.1-11.2)
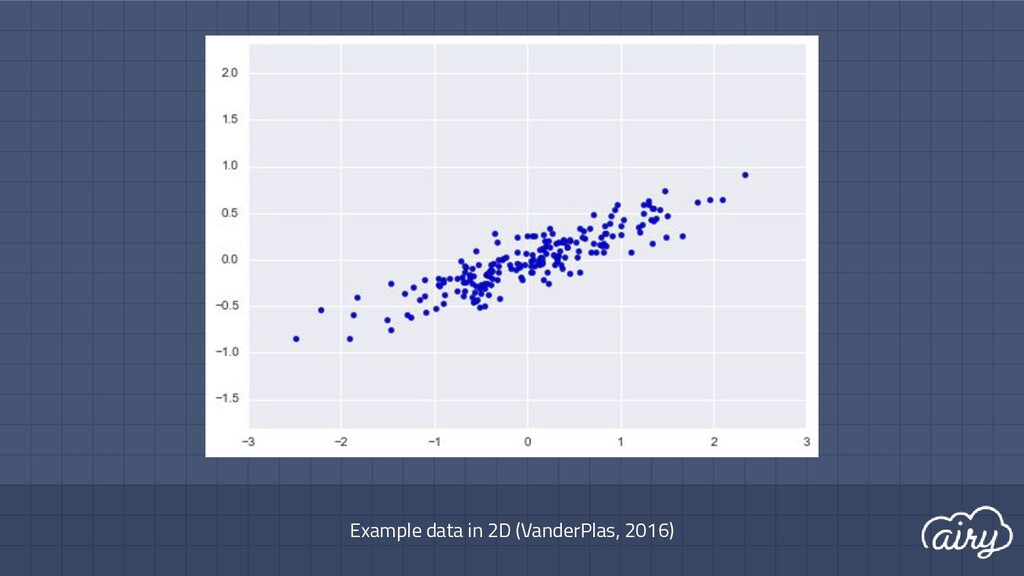
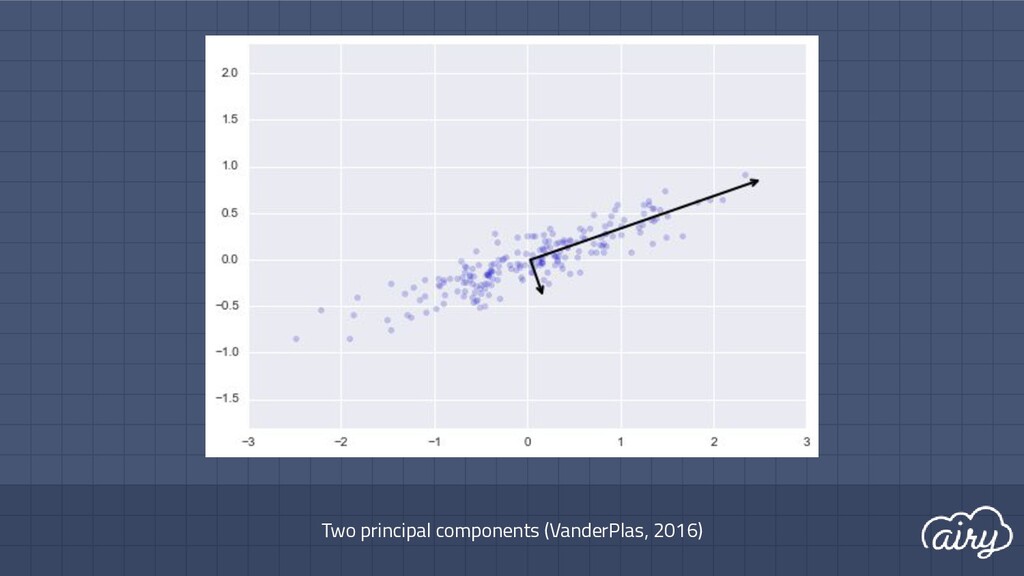
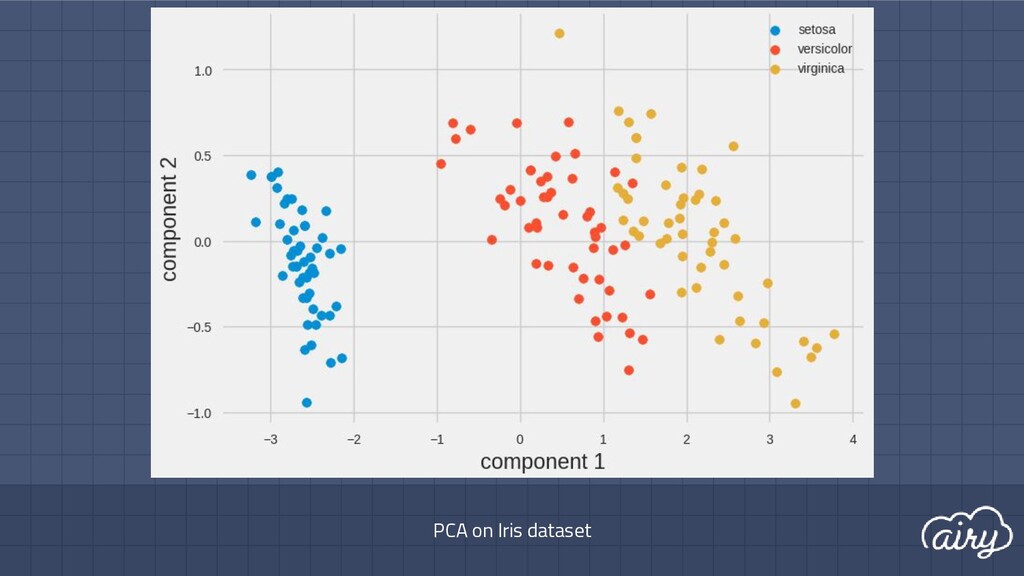
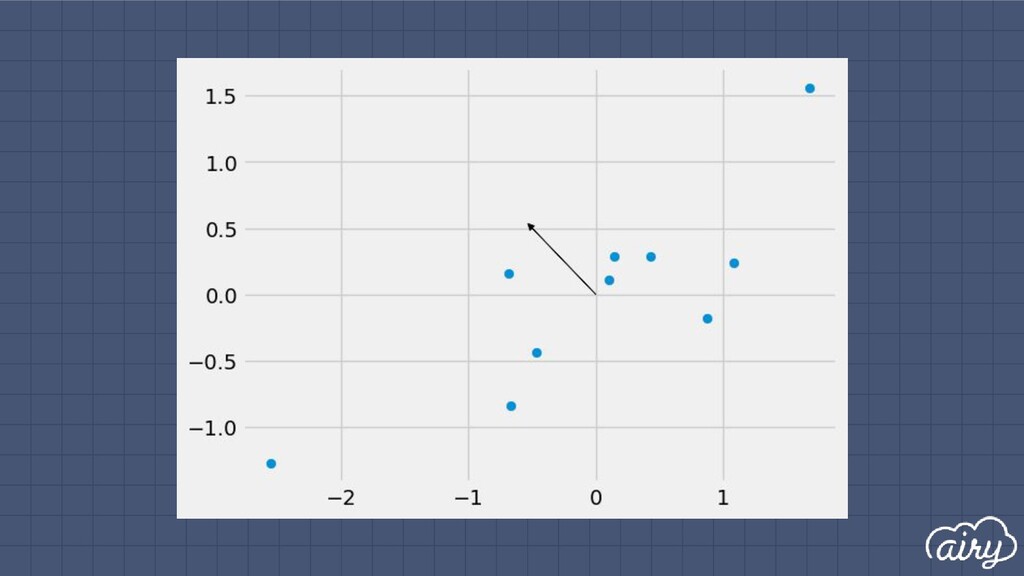
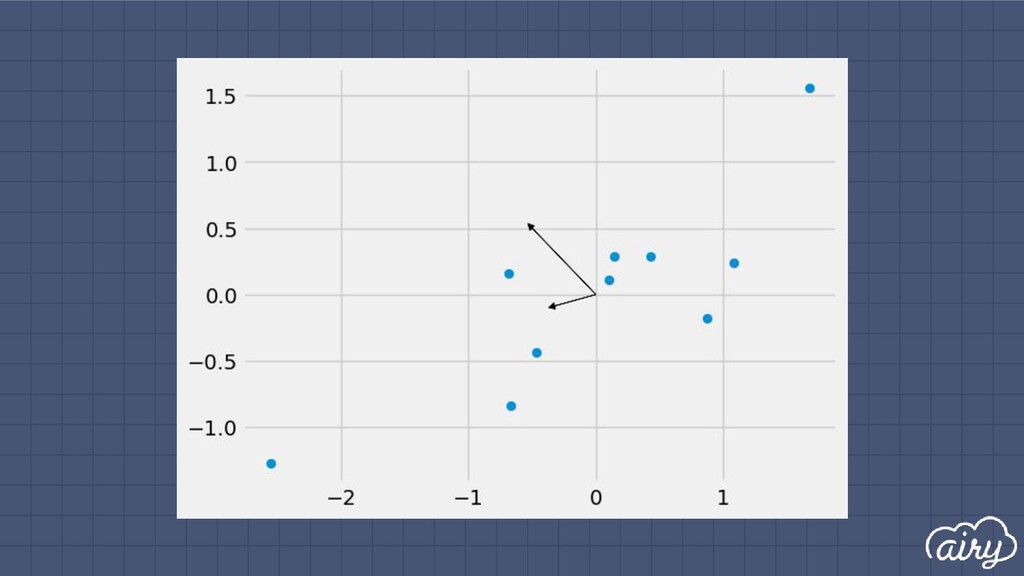
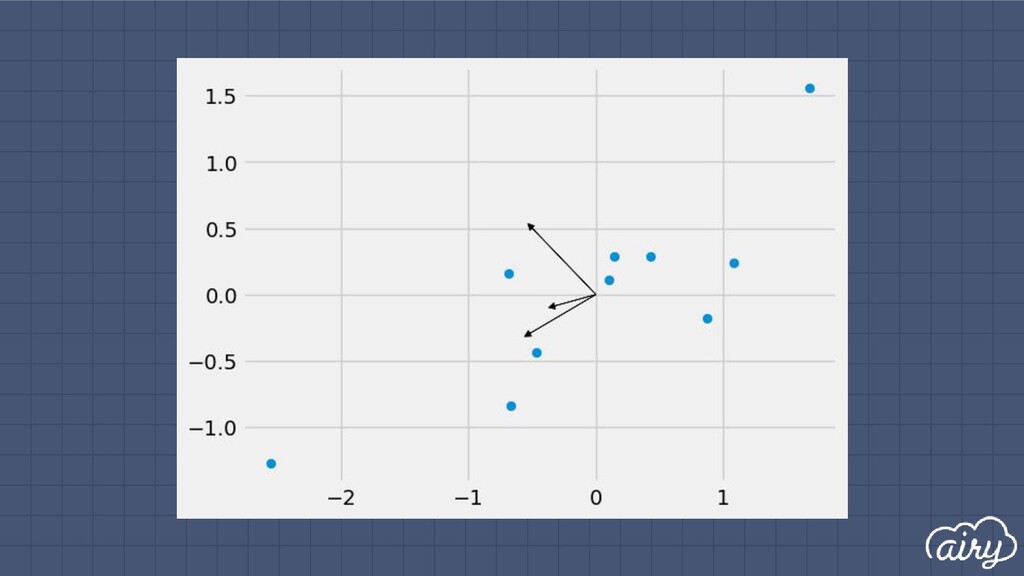
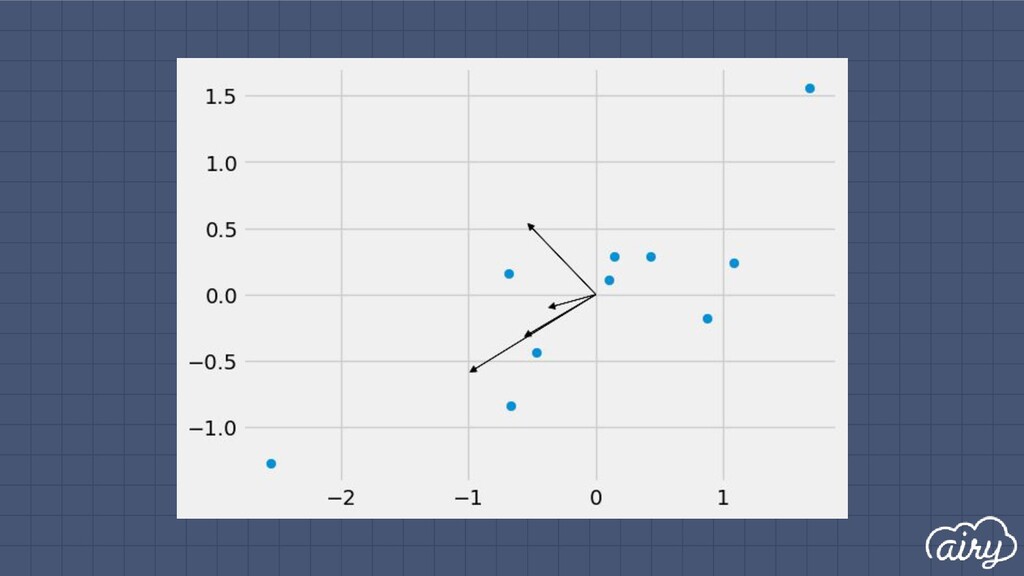
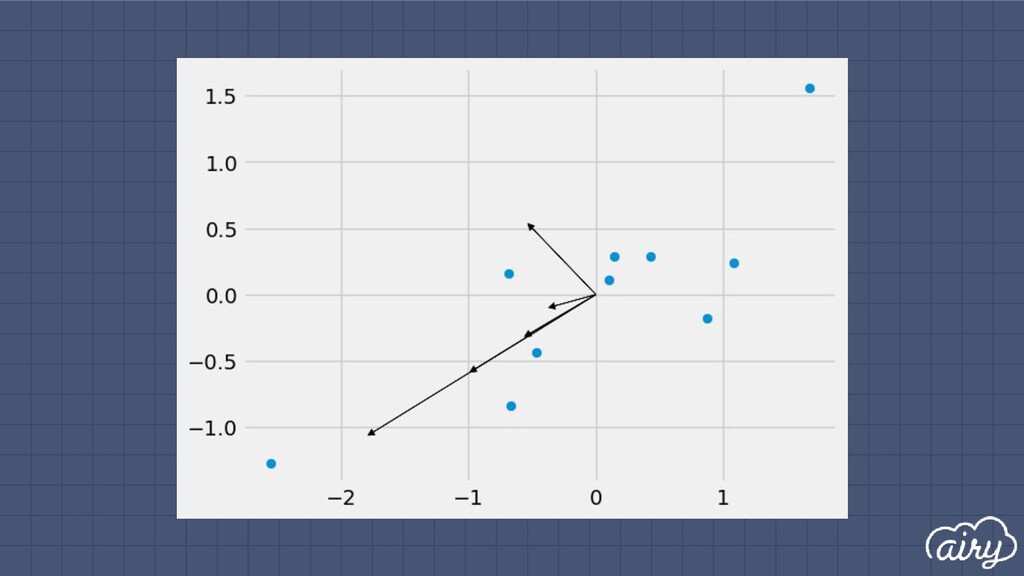
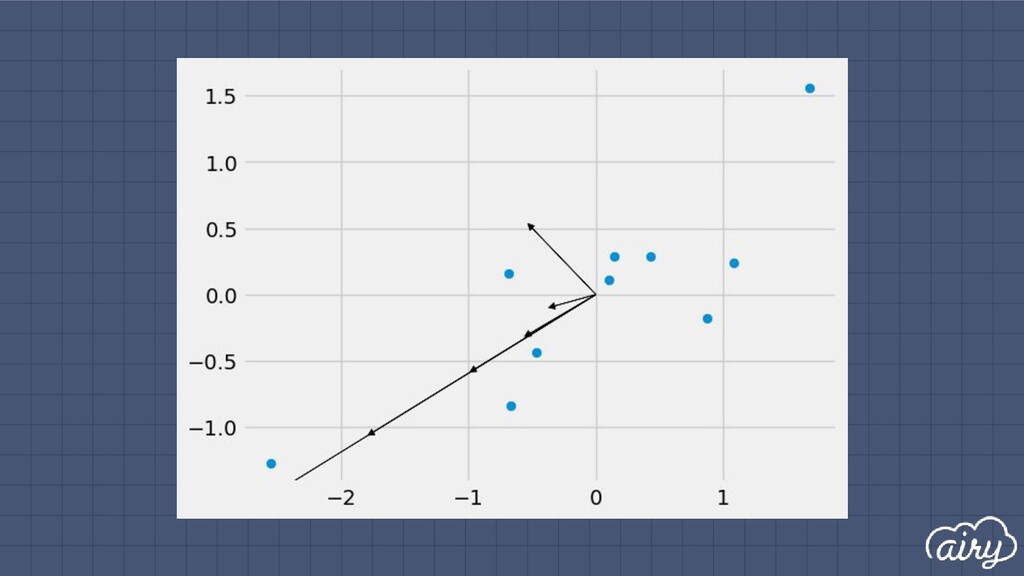
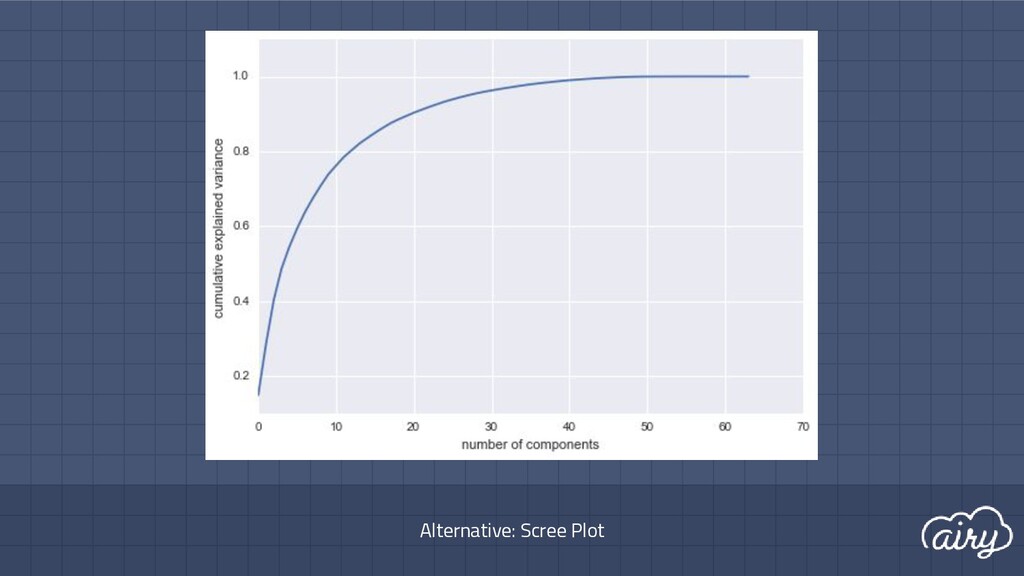
a. 1st: direction of the greatest variability in the data b. 2nd: perpendicular to 1st, greatest variability of what’s left c. … and so on until d (original dimensionality) 2. First m << d components become m new dimensions
▫ Solve det(Σ - λI) = 0 ▫ Find ith eigenvector by solving Σe i = λ i e i ▫ Principal components are eigenvectors with largest eigenvalues Principal Components
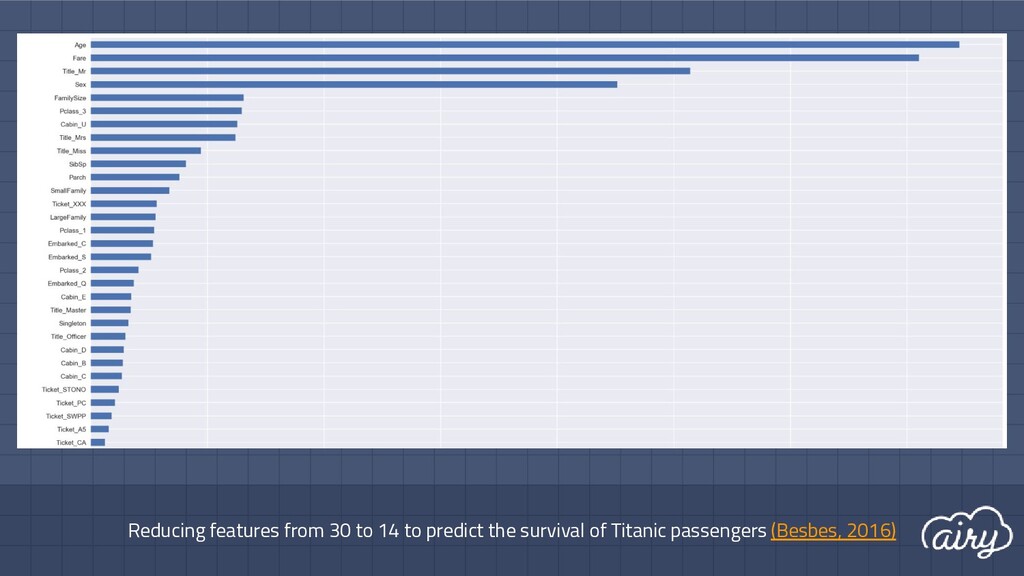
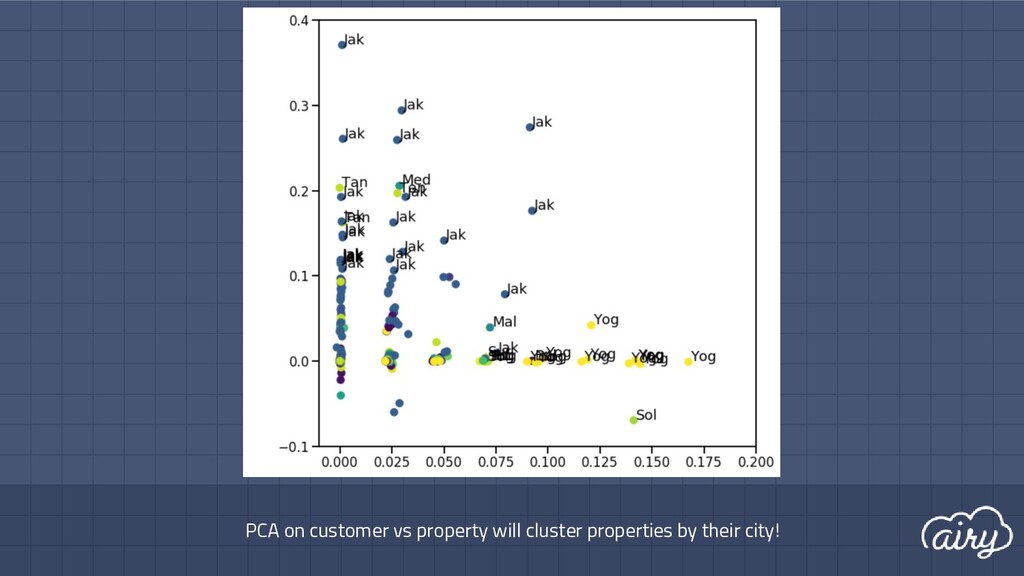
training set A (5-fold CV): - Without SVD (578 unique tokens): 84.52% | 92.15% | 88.06% - With SVD (100 features): 79.38% | 98.43% | 87.86% ▫ 3rd place on test set UKARA 1.0 Challenge Track 1
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Example Given Σ = [2.0 0.8; 0.8 0.6], the eigenvalues](https://files.speakerdeck.com/presentations/56fbeda634c64c5eb0d4796483ae3b9a/slide_57.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}