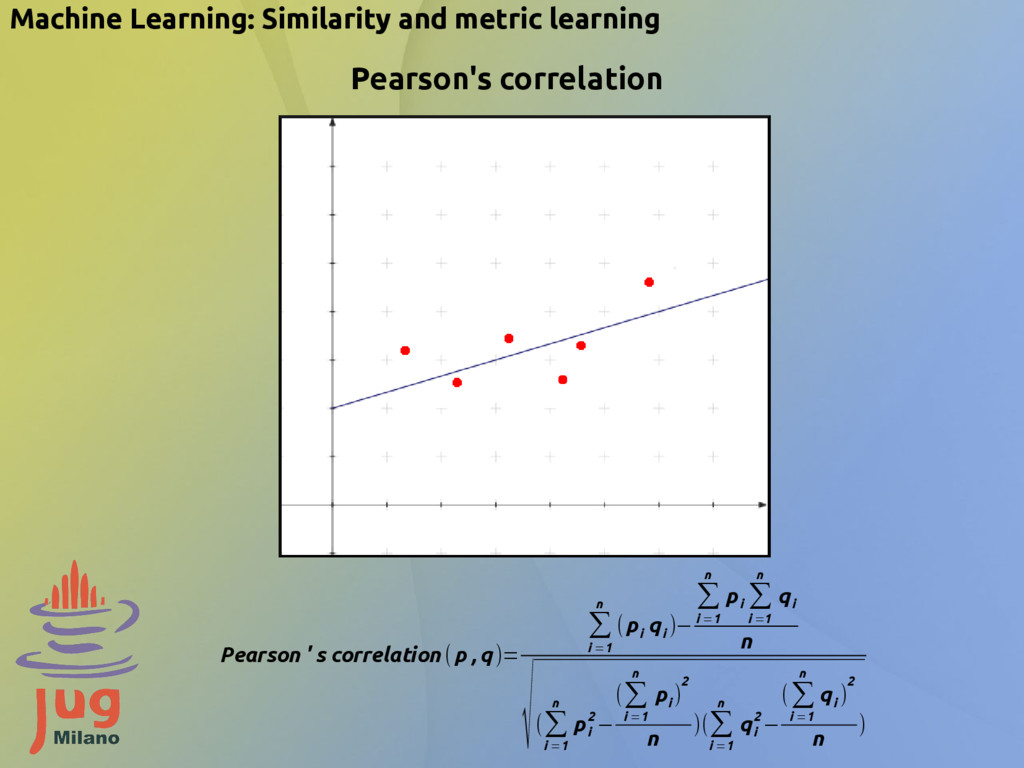
n (p i q i )− ∑ i =1 n p i ∑ i =1 n q i n √(∑ i =1 n p i 2 − (∑ i =1 n p i ) 2 n )(∑ i =1 n q i 2 − (∑ i =1 n q i ) 2 n ) Machine Learning: Similarity and metric learning Pearson's correlation
subset that have tastes like yours. Based on what this subset likes or dislikes the system can recommend you other items. Two main approaches: - User based filtering - Item based filtering Machine Learning: Similarity and metric learning Collaborative filtering
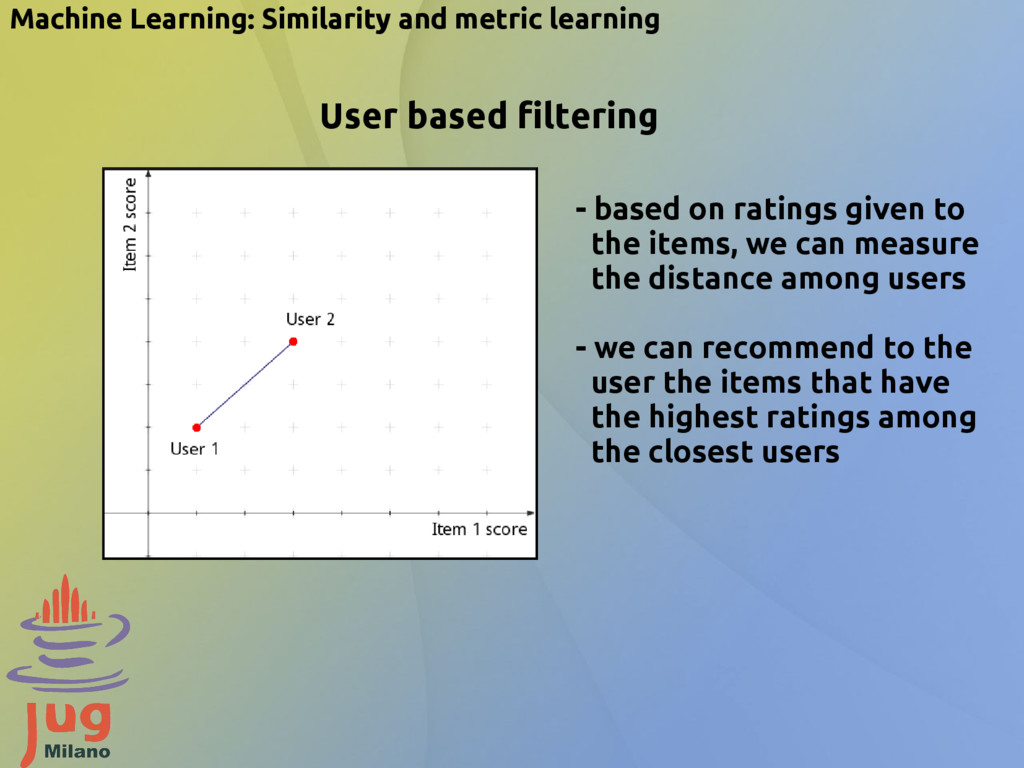
based on ratings given to the items, we can measure the distance among users - we can recommend to the user the items that have the highest ratings among the closest users
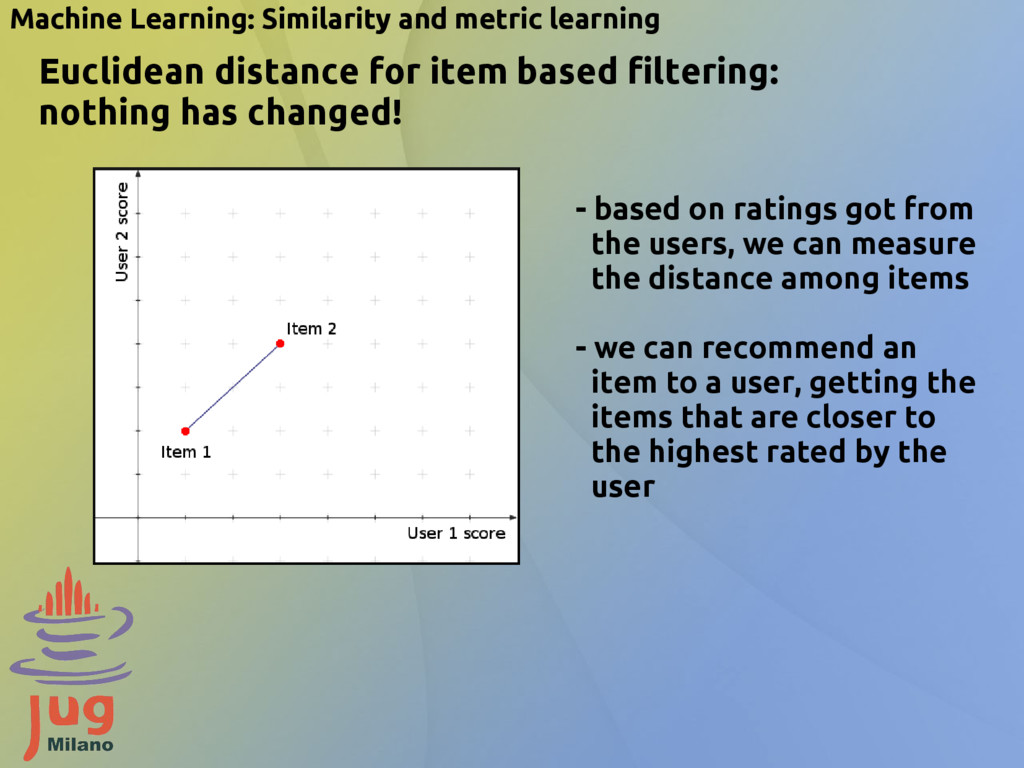
based filtering: nothing has changed! - based on ratings got from the users, we can measure the distance among items - we can recommend an item to a user, getting the items that are closer to the highest rated by the user
Learning: Bayes' classifier Example: given a company where 70% of developers use Java and 30% use C++, and knowing that half of the Java developers always use enhanced for loop, if you look at the snippet: which is the probability that the developer who wrote it uses Java? for (int j=0; j<100; j++) { t = tests[j]; } P (A∣B )= P (B∣A)P (A) P (B ) Bayes' theorem
Learning: Bayes' classifier Example: given a company where 70% of developers use Java and 30% use C++, and knowing that half of the Java developers always use enhanced for loop, if you look at the snippet: which is the probability that the developer who wrote it uses Java? for (int j=0; j<100; j++) { t = tests[j]; } P (A∣B )= P (B∣A)P (A) P (B ) Bayes' theorem Hint: A = developer uses Java B = developer writes old for loops
Learning: Bayes' classifier Example: given a company where 70% of developers use Java and 30% use C++, and knowing that half of the Java developers always use enhanced for loop, if you look at the snippet: which is the probability that the developer who wrote it uses Java? for (int j=0; j<100; j++) { t = tests[j]; } P (A∣B )= P (B∣A)P (A) P (B ) Bayes' theorem Solution: A = developer uses Java B = developer writes old for loops P (A∣B)= P (B∣A)P (A) P (B) = 0.5⋅0.7 0.65 =0.54 P(A) = prob. that a developer uses Java = 0.7 P(B) = prob. that any developer uses old for loop = 0.3 + 0.7*0.5 = 0.65 P(B|A) = prob. that a Java developer uses old for loop = 0.5
- trained on a set of known classes - computes probabilities of elements to be in a class - smoothing required P c (w 1 , .... ,w n )= ∏ i =1 n P (c∣w i ) ∏ i =1 n P (c∣w i )+∏ i=1 n (1−P (c∣w i ))
want a classifier for Twitter messages - define a set of classes: {art, tech, home, events,.. } - trains the classifier with a set of alreay classified tweets - when a new tweet arrives, the classifier will (hopefully) tell us which class it belongs to
{ +, - } - define a set of words: { like, enjoy, hate, bore, fun, …} - train a NBC with a set of known +/- comments - let NBC classify any new comment to know if +/- - performance is related to quality of training set
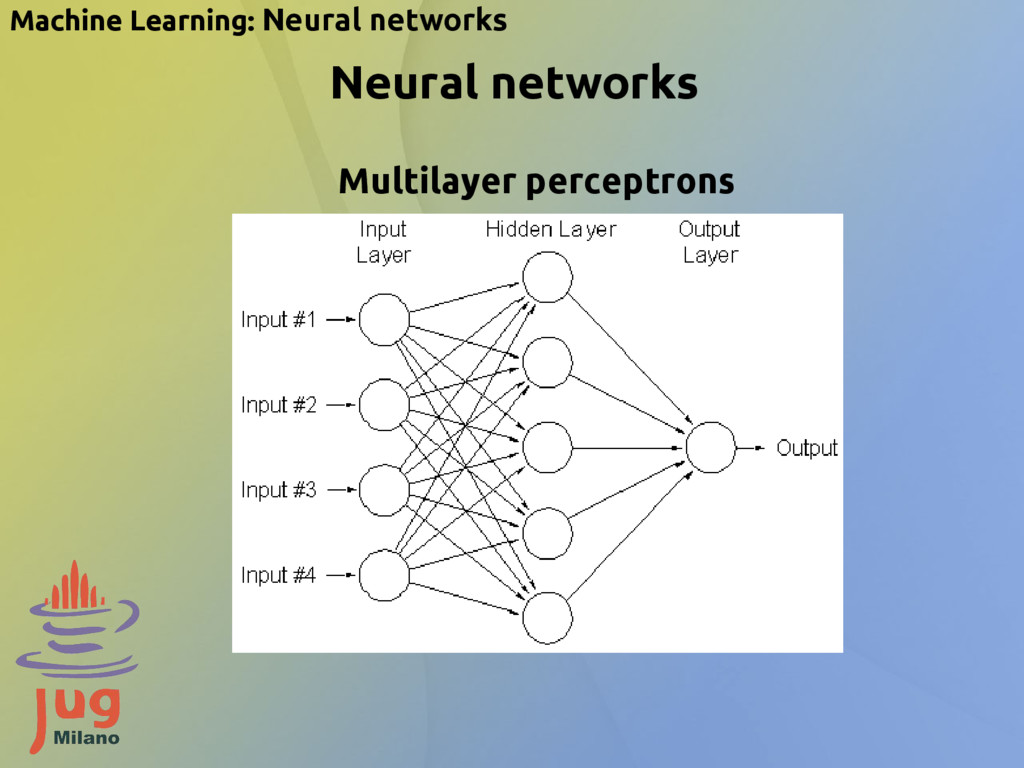
- Forward propagation of a training pattern's input through the neural network in order to generate the propagation's output activations - Backward propagation of the propagation's output activations through the neural network using the training pattern target in order to generate the deltas of all output and hidden neurons Phase 2: Weight update - Multiply its output delta and input activation to get the gradient of the weight - Bring the weight in the opposite direction of the gradient by subtracting a ratio of it from the weight
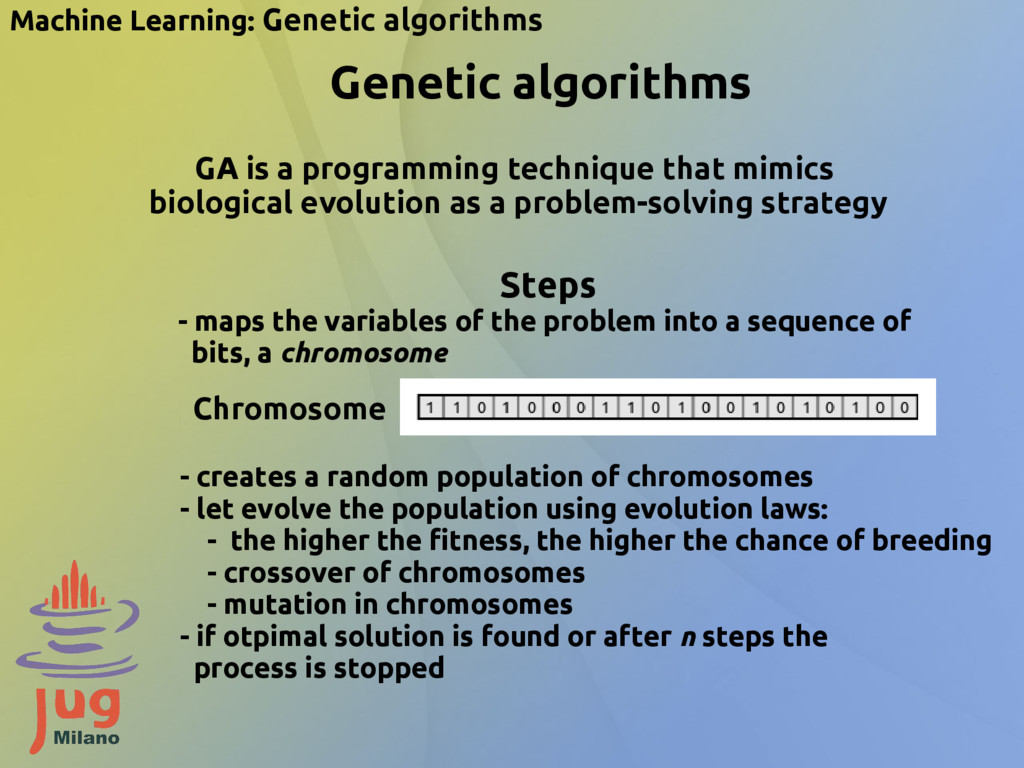
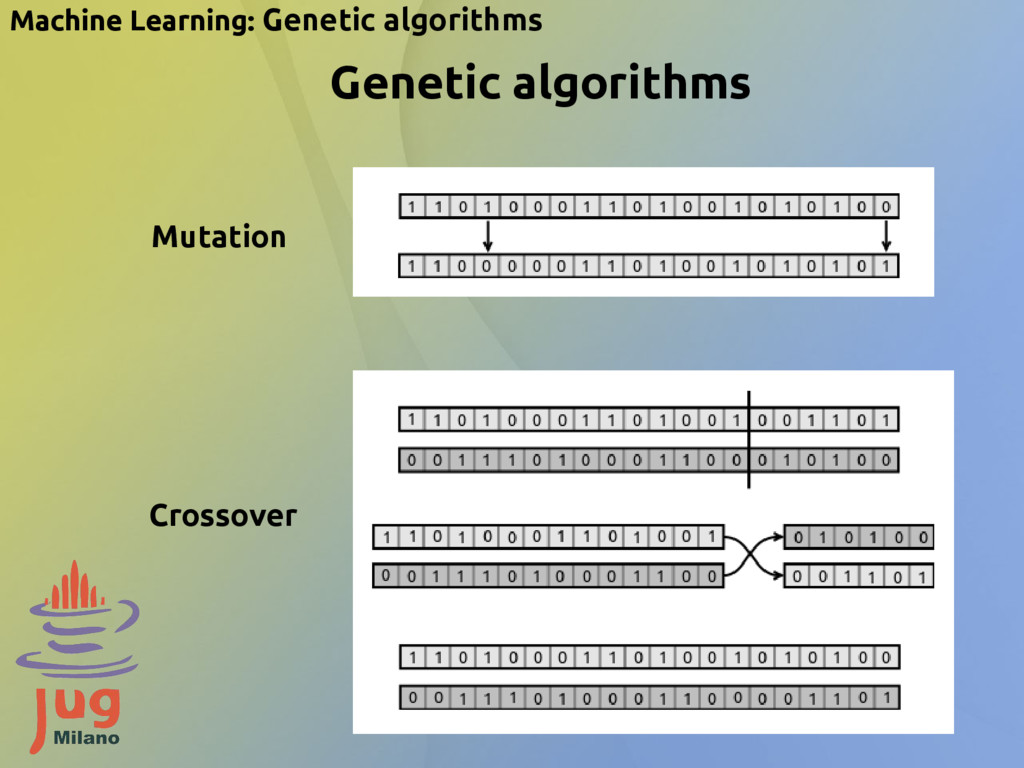
technique that mimics biological evolution as a problem-solving strategy Steps - maps the variables of the problem into a sequence of bits, a chromosome Chromosome - creates a random population of chromosomes - let evolve the population using evolution laws: - the higher the fitness, the higher the chance of breeding - crossover of chromosomes - mutation in chromosomes - if otpimal solution is found or after n steps the process is stopped
{kind=link}
![Machine Learning: Intro [Wikipedia]: a branch of artificial intelligence that](https://files.speakerdeck.com/presentations/9b6a0e8844ae4094b91b0b813a421916/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
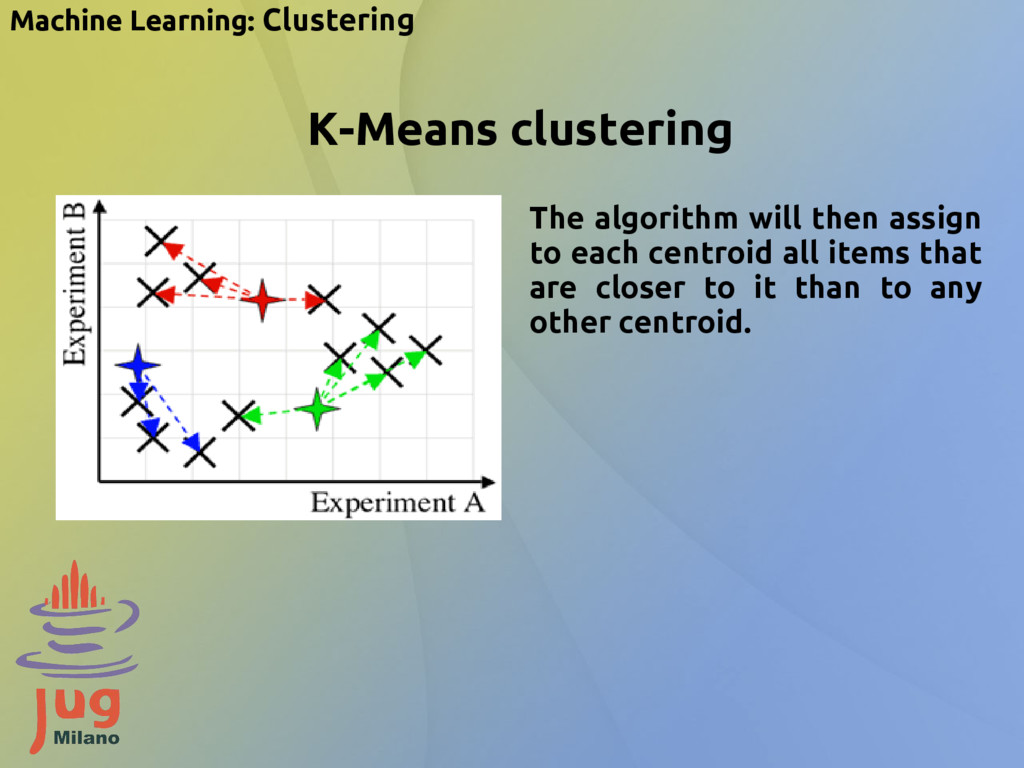{kind=link}
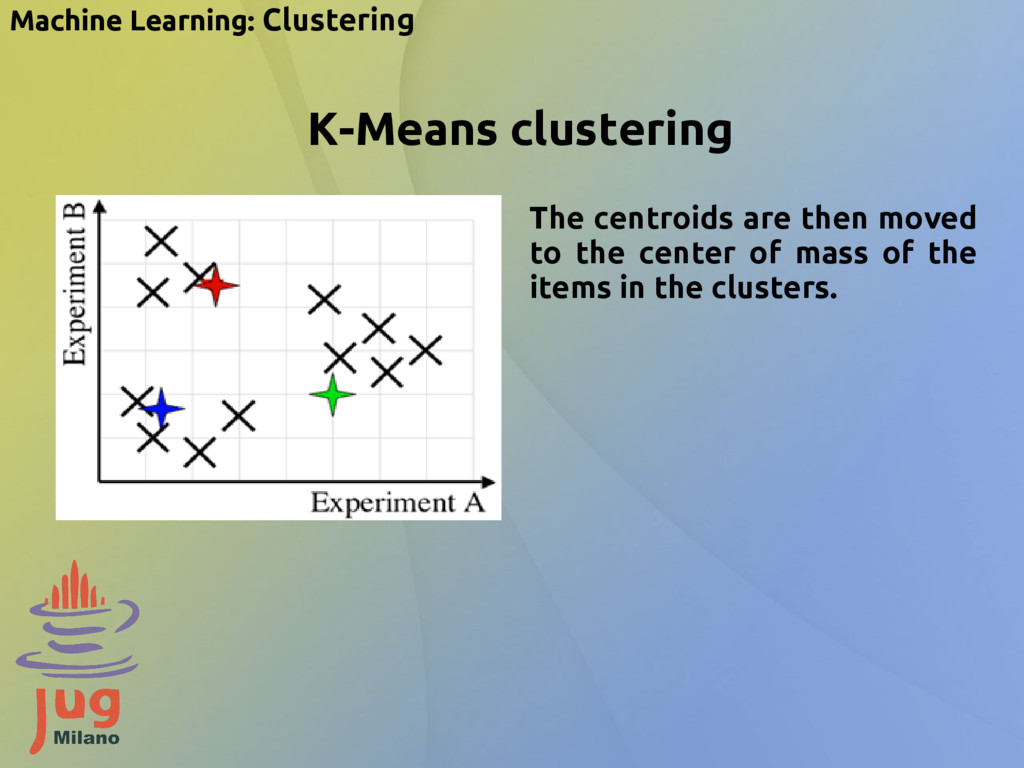{kind=link}
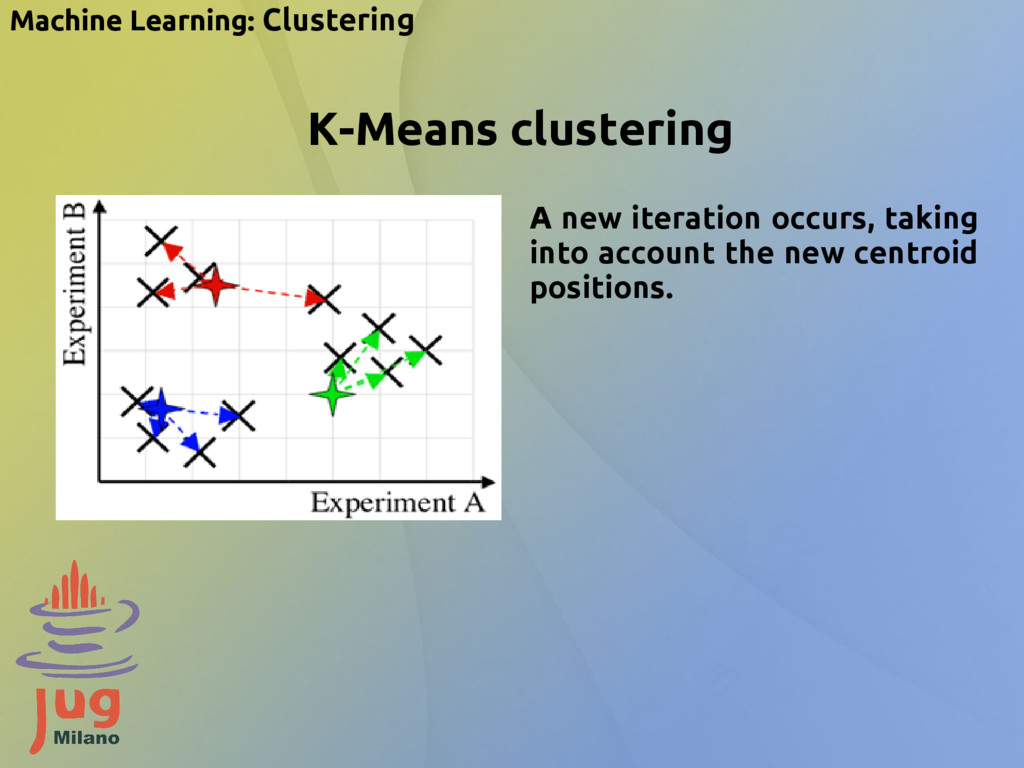{kind=link}
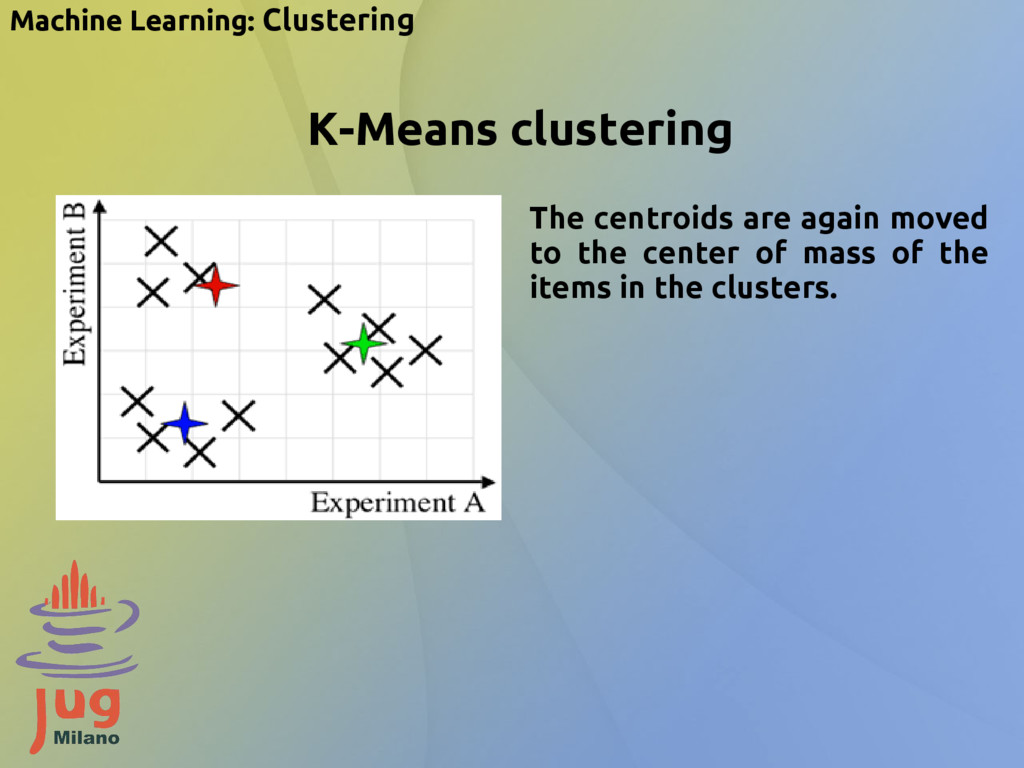{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}