Apache Storm Storm is a real-time distributed computing framework for reliably processing unbounded data streams. It was created by Nathan Marz and his team at BackType, and released as open source in 2011 (after BackType was acquired by Twitter).
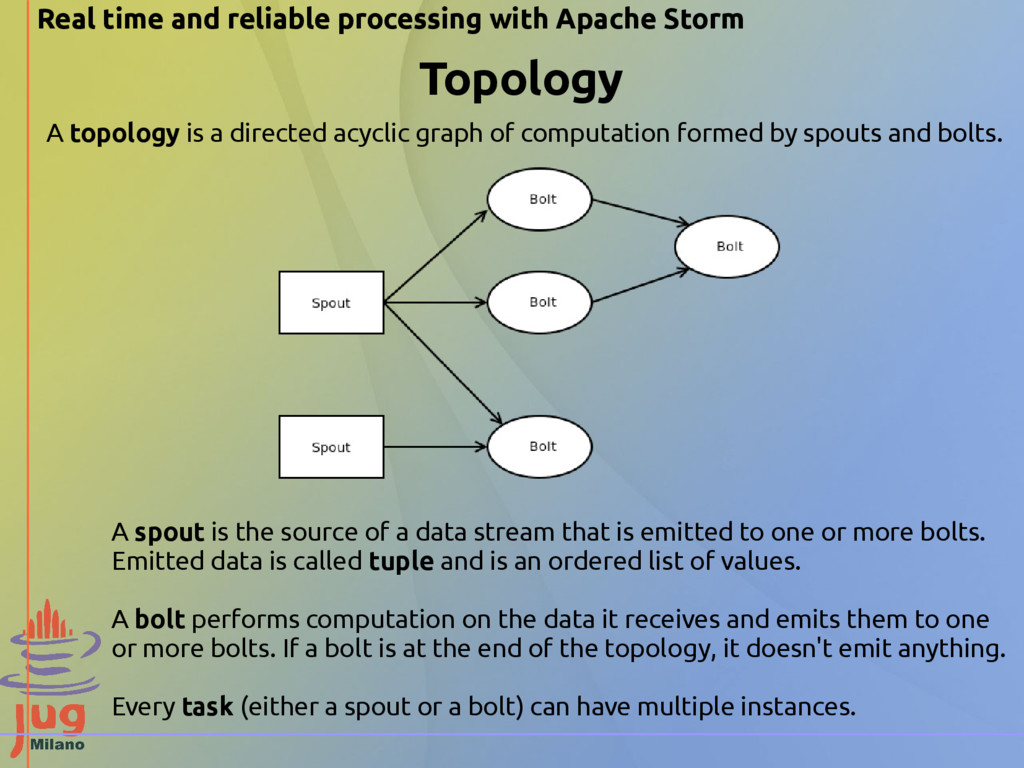
that is emitted to one or more bolts. Emitted data is called tuple and is an ordered list of values. A bolt performs computation on the data it receives and emits them to one or more bolts. If a bolt is at the end of the topology, it doesn't emit anything. Every task (either a spout or a bolt) can have multiple instances. A topology is a directed acyclic graph of computation formed by spouts and bolts. Real time and reliable processing with Apache Storm
Random random; @Override public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { outputFieldsDeclarer.declare(new Fields("val")); } @Override public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) { this.spoutOutputCollector = spoutOutputCollector; random = new Random(); } @Override public void nextTuple() { spoutOutputCollector.emit(new Values(random.nextInt() % 100)); } } Real time and reliable processing with Apache Storm A simple topology: the spout
RandomValuesTopology { private static final String name = RandomValuesTopology.class.getName(); public static void main(String[] args) { TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("random-spout", new RandomSpout()); builder.setBolt("writer-bolt",new FileWriteBolt()) .shuffleGrouping("random-spout"); Config conf = new Config(); conf.setDebug(false); conf.setMaxTaskParallelism(3); LocalCluster cluster = new LocalCluster(); cluster.submitTopology(name, conf, builder.createTopology()); Utils.sleep(300_000); cluster.killTopology(name); cluster.shutdown(); // to run it on a live cluster // StormSubmitter.submitTopology("topology", conf, builder.createTopology()); } } A simple topology: the topology
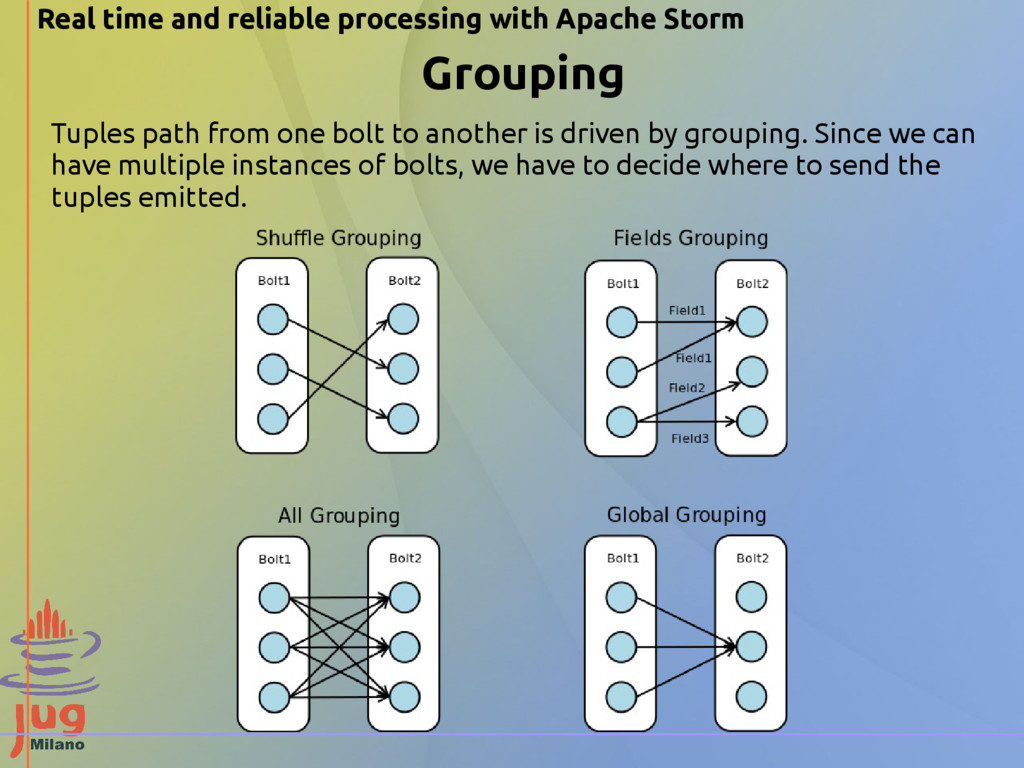
by grouping. Since we can have multiple instances of bolts, we have to decide where to send the tuples emitted. Real time and reliable processing with Apache Storm
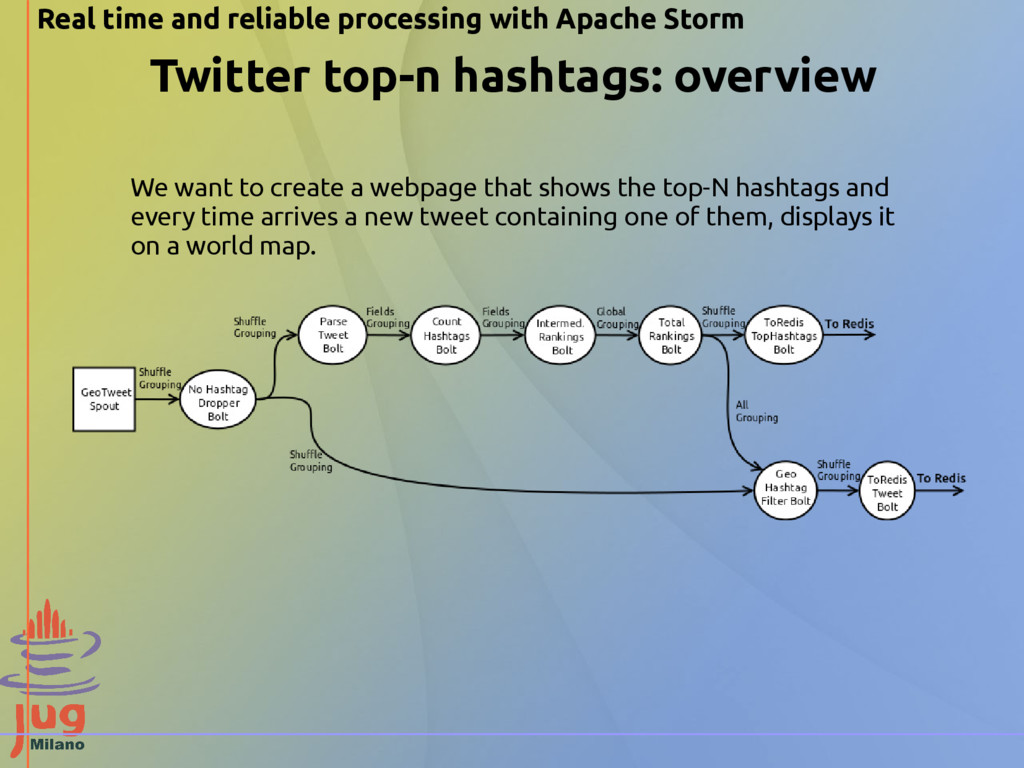
hashtags and every time arrives a new tweet containing one of them, displays it on a world map. Twitter top-n hashtags: overview Real time and reliable processing with Apache Storm
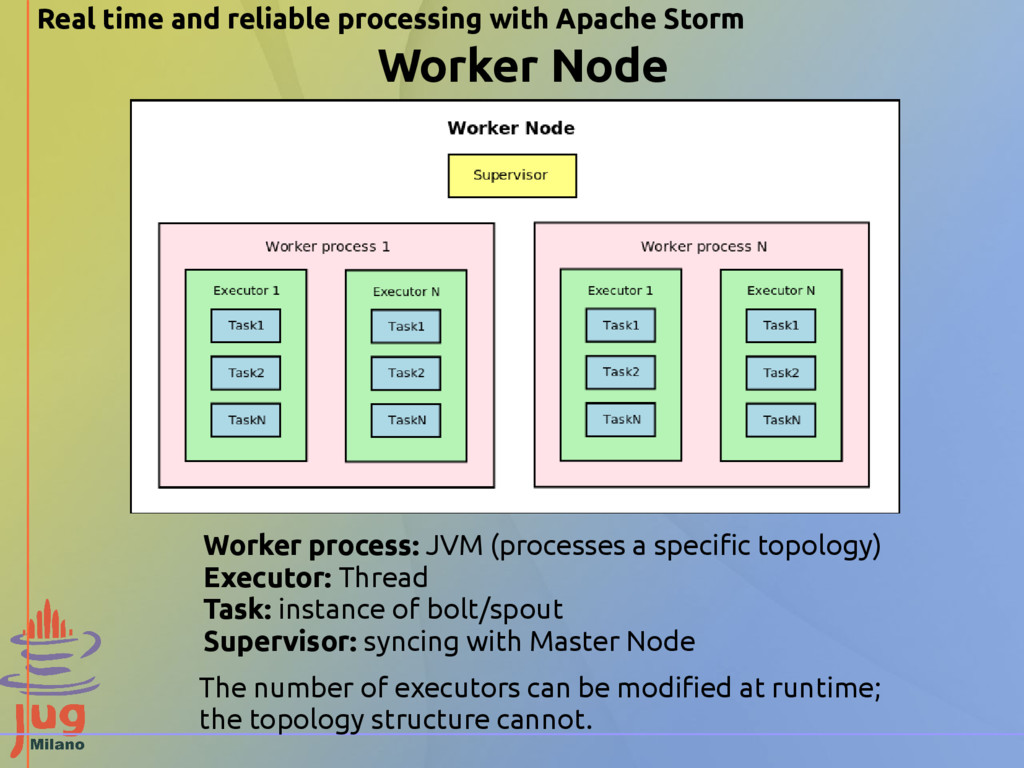
the cluster, assigning jobs to nodes, and monitoring for failures. Worker node: executes a subset of a topology (spouts and/or bolts). It runs a supervisor daemon that listens for jobs assigned to the machine and starts and stops worker processes as necessary. Zookeeper: manages all the coordination between Nimbus and the supervisors. Real time and reliable processing with Apache Storm
Thread Task: instance of bolt/spout Supervisor: syncing with Master Node The number of executors can be modified at runtime; the topology structure cannot. Real time and reliable processing with Apache Storm
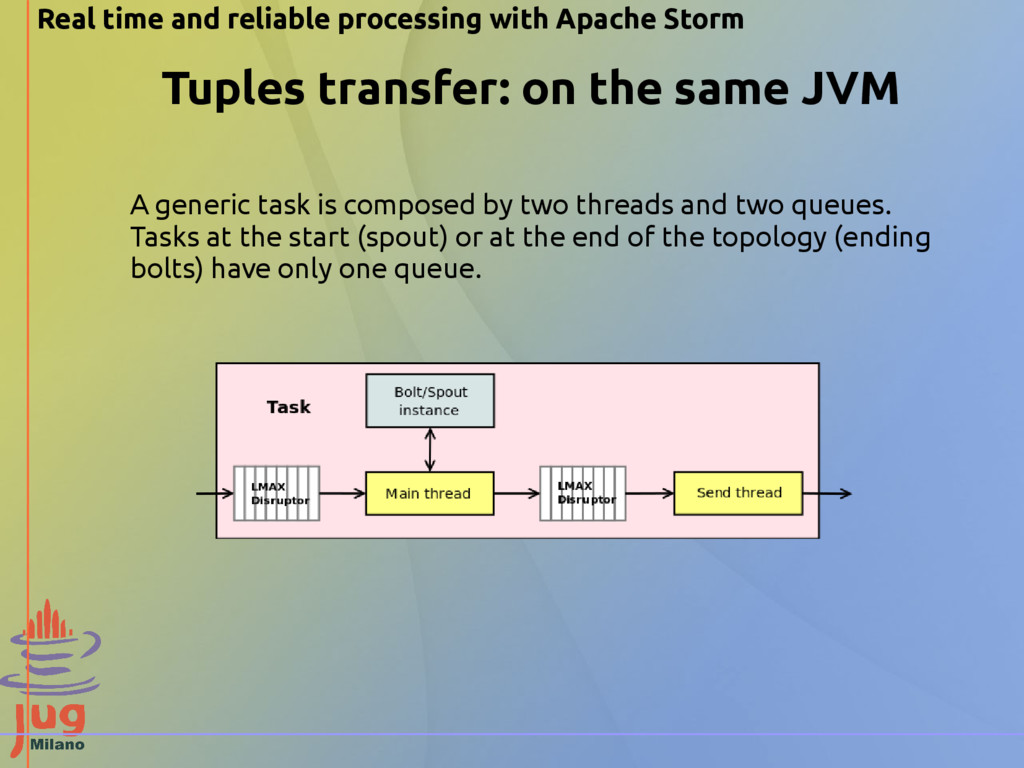
JVMs For serialization, Storm tries to lookup a Kryo serializer, which is more efficient than Java standard serialization. The network layer for transport is provided by Netty. Also for performance reasons, the queues are implemented using the LMAX Disruptor library, which enables efficient queuing. Real time and reliable processing with Apache Storm Storm supports two different types of transfer:
composed by two threads and two queues. Tasks at the start (spout) or at the end of the topology (ending bolts) have only one queue. Real time and reliable processing with Apache Storm
producer/consumer, if the producer supplies data at a higher rate than the consumer, the queue will overflow. The transfer queue is more critical because it has to serve all the tasks of the worker, so it's stressed more than the internal one. If an overflow happens, Storm tries - but not guarantees - to put the overflowing tuples into a temporary queue, with the side- effect of dropping the throughput of the topology. Real time and reliable processing with Apache Storm
in the order coming from spouts and in case of failure (network, exceptions) are just dropped • at-least-once: in case of failure tuples are re-emitted from the spout; a tuple can be processed more than once and they can arrive out of order • exactly-once: only available with Trident, a layer sitting on top of Storm that allows to write topologies with different semantic Real time and reliable processing with Apache Storm
Storm The three main concepts to achieve at-least-once guarantee level are: • anchoring: every tuple emitted by a bolt has to be linked to the input tuple using the emit(tuple, values) method • acking: when a bolt successfully finishes to execute() a tuple, it has to call the ack() method to notify Storm • failing: when a bolt encounters a problem with the incoming tuple, it has to call the fail() method The BaseBasicBolt we saw before takes care of them automatically (when a tuple has to fail, it must be thrown a FailedException). When the topology is complex (expanding tuples, collapsing tuples, joining streams) they must be explicitly managed extending a BaseRichBolt.
Storm The ISpout interface defines - beside others - these methods: void open(Map conf,TopologyContext context,SpoutOutputCollector collector); void close(); void nextTuple(); void ack(Object msgId); void fail(Object msgId); To implement a reliable spout we have to call inside the nextTuple() method: Collector.emit(values, msgId); and we have to manage the ack() and fail() methods accordingly.
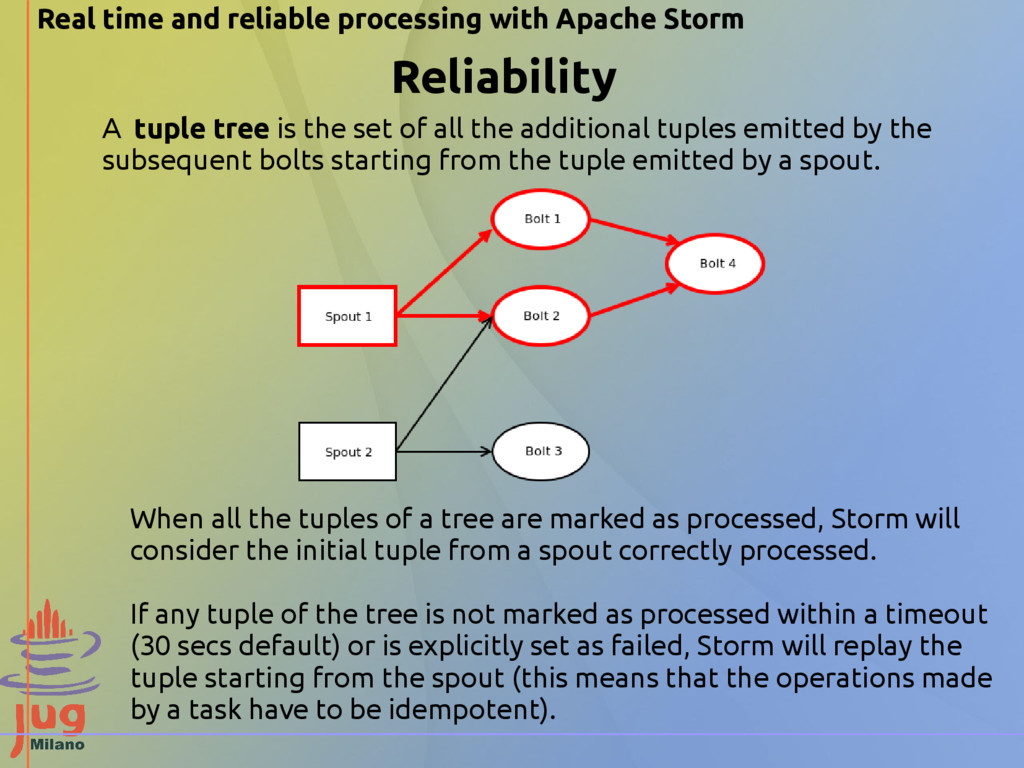
additional tuples emitted by the subsequent bolts starting from the tuple emitted by a spout. When all the tuples of a tree are marked as processed, Storm will consider the initial tuple from a spout correctly processed. If any tuple of the tree is not marked as processed within a timeout (30 secs default) or is explicitly set as failed, Storm will replay the tuple starting from the spout (this means that the operations made by a task have to be idempotent). Real time and reliable processing with Apache Storm
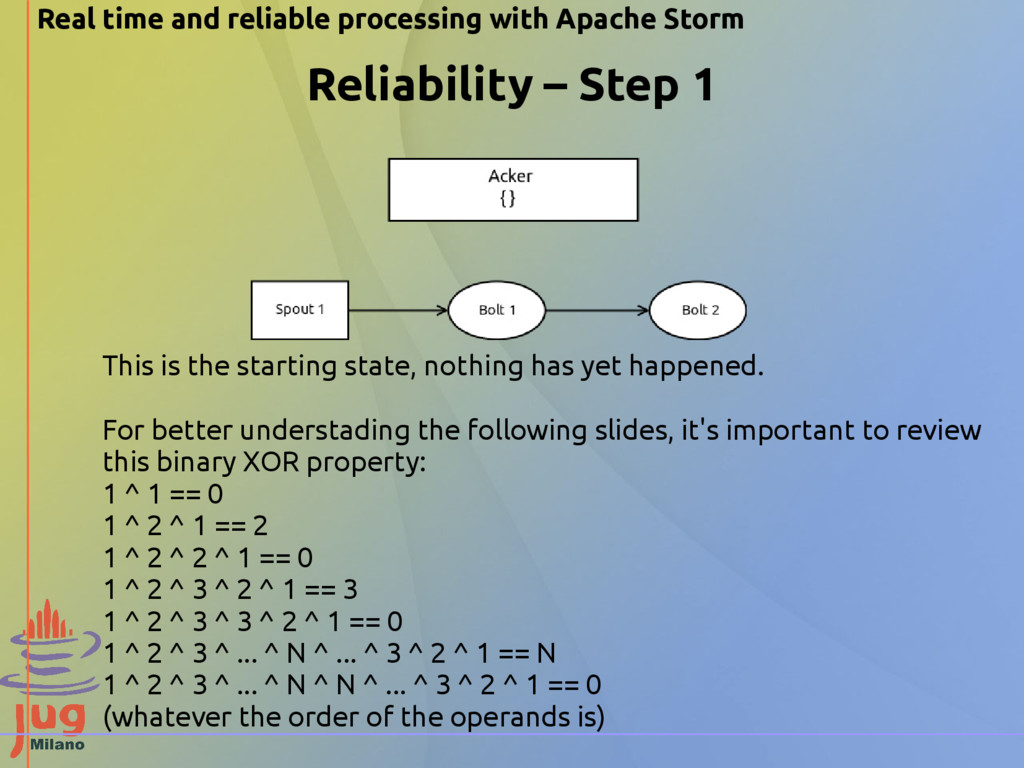
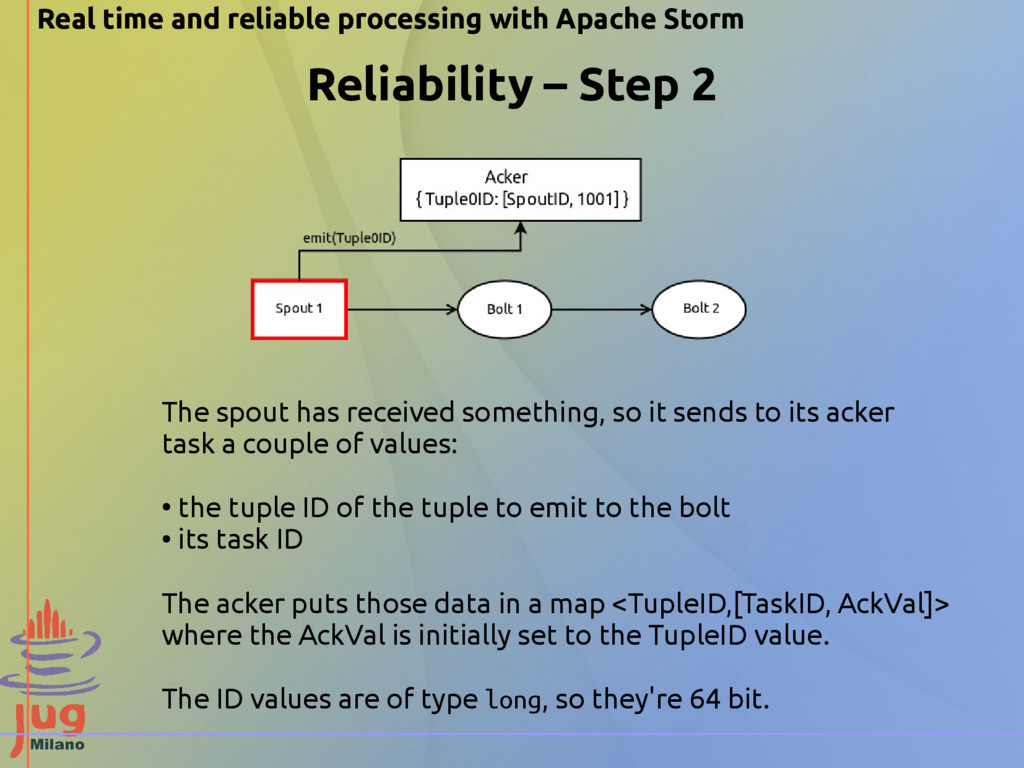
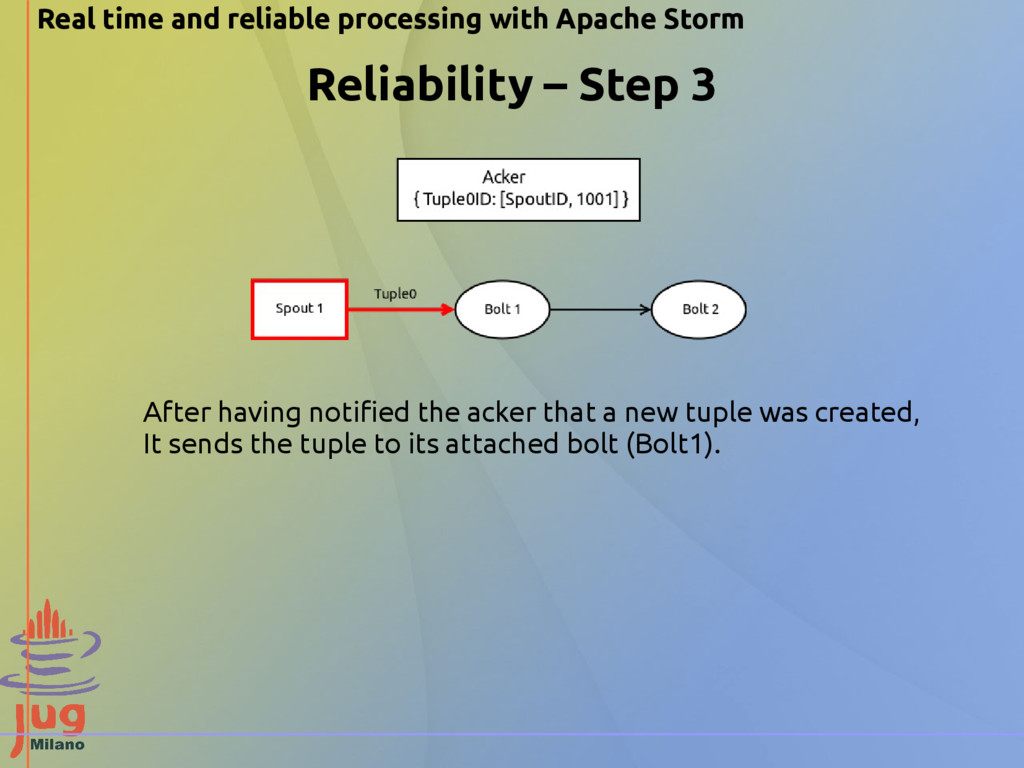
Step 2 The spout has received something, so it sends to its acker task a couple of values: • the tuple ID of the tuple to emit to the bolt • its task ID The acker puts those data in a map <TupleID,[TaskID, AckVal]> where the AckVal is initially set to the TupleID value. The ID values are of type long, so they're 64 bit.
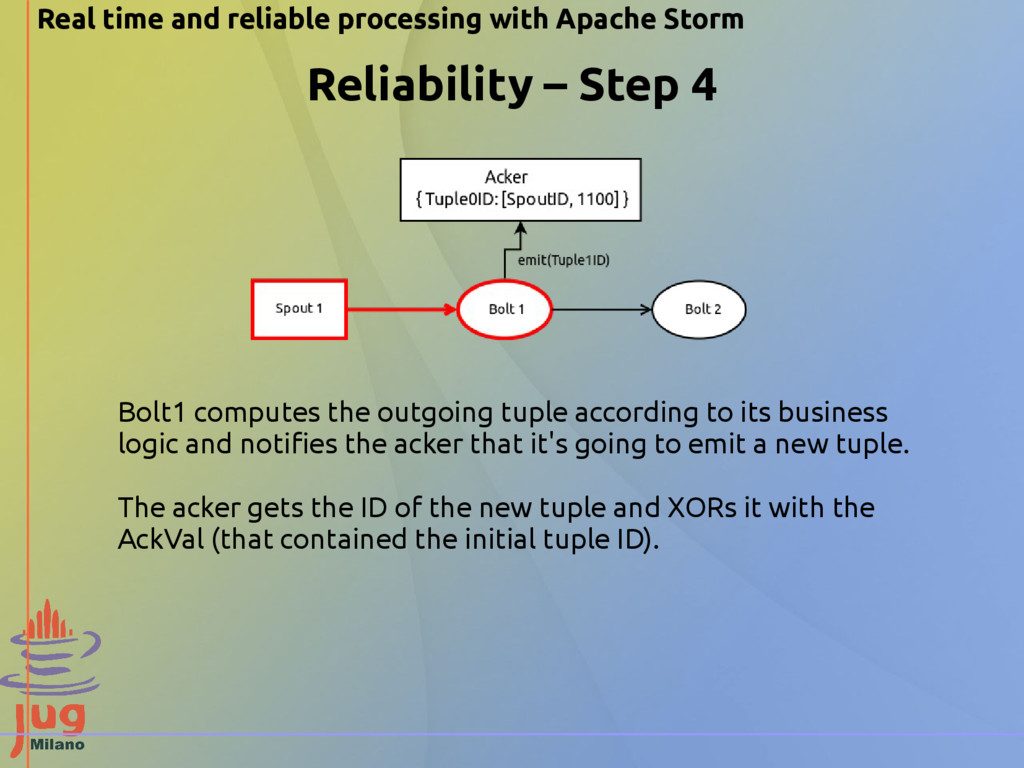
Step 4 Bolt1 computes the outgoing tuple according to its business logic and notifies the acker that it's going to emit a new tuple. The acker gets the ID of the new tuple and XORs it with the AckVal (that contained the initial tuple ID).
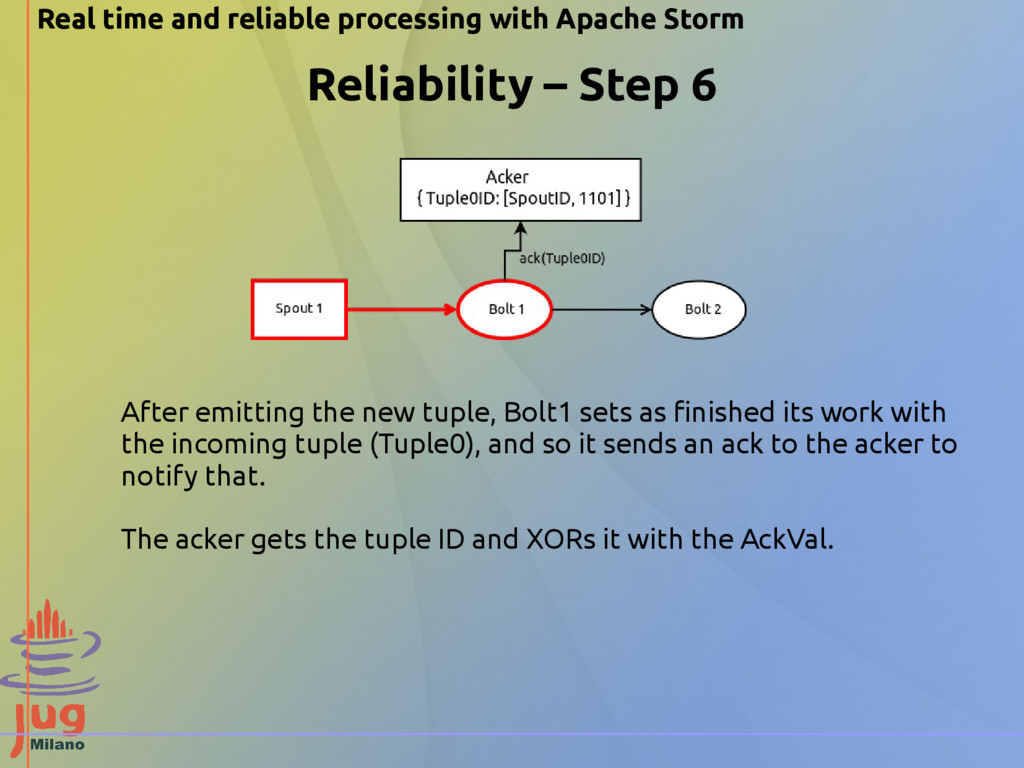
Step 6 After emitting the new tuple, Bolt1 sets as finished its work with the incoming tuple (Tuple0), and so it sends an ack to the acker to notify that. The acker gets the tuple ID and XORs it with the AckVal.
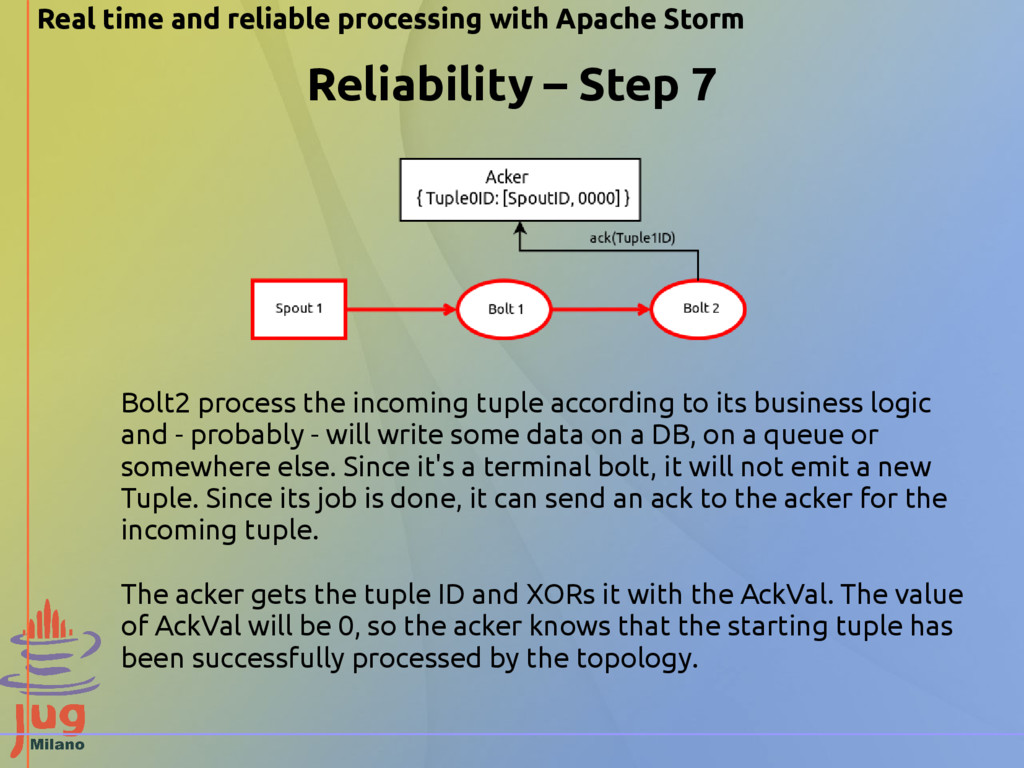
Step 7 Bolt2 process the incoming tuple according to its business logic and - probably - will write some data on a DB, on a queue or somewhere else. Since it's a terminal bolt, it will not emit a new Tuple. Since its job is done, it can send an ack to the acker for the incoming tuple. The acker gets the tuple ID and XORs it with the AckVal. The value of AckVal will be 0, so the acker knows that the starting tuple has been successfully processed by the topology.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
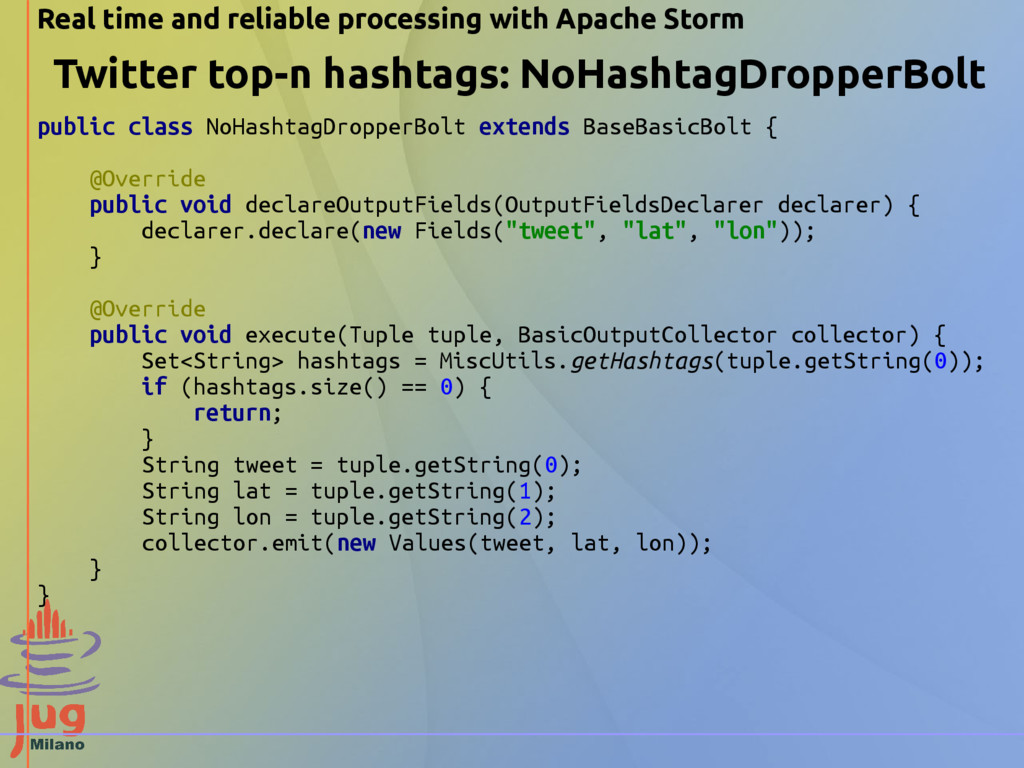{kind=link}
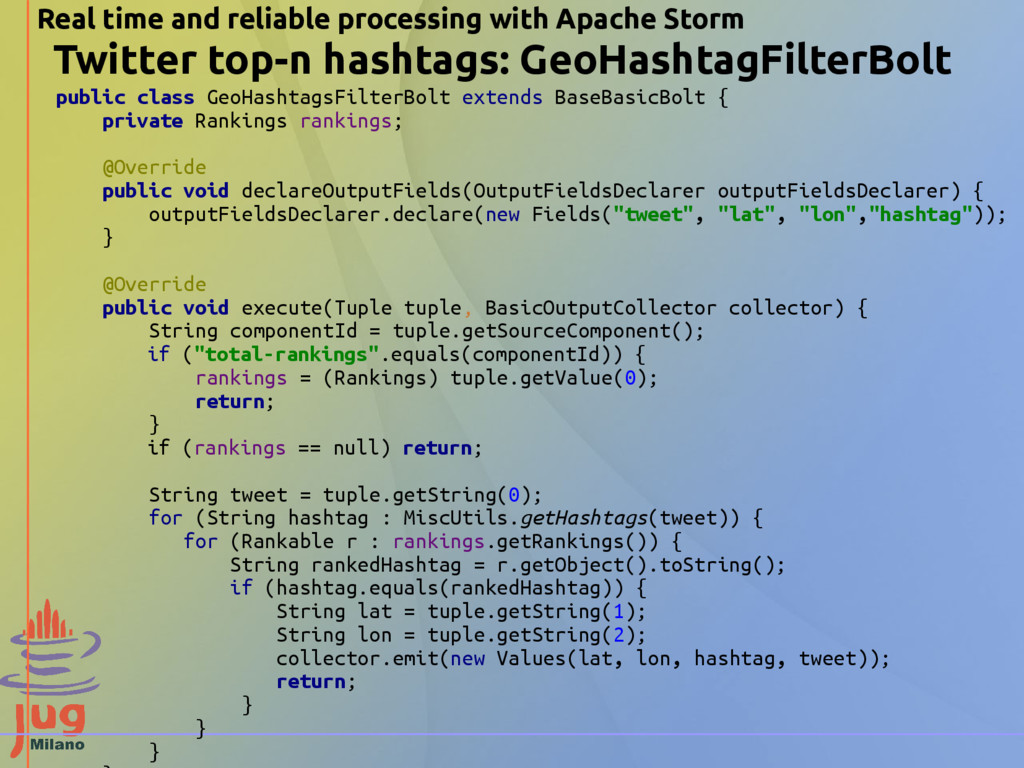{kind=link}
{kind=link}
{kind=link}
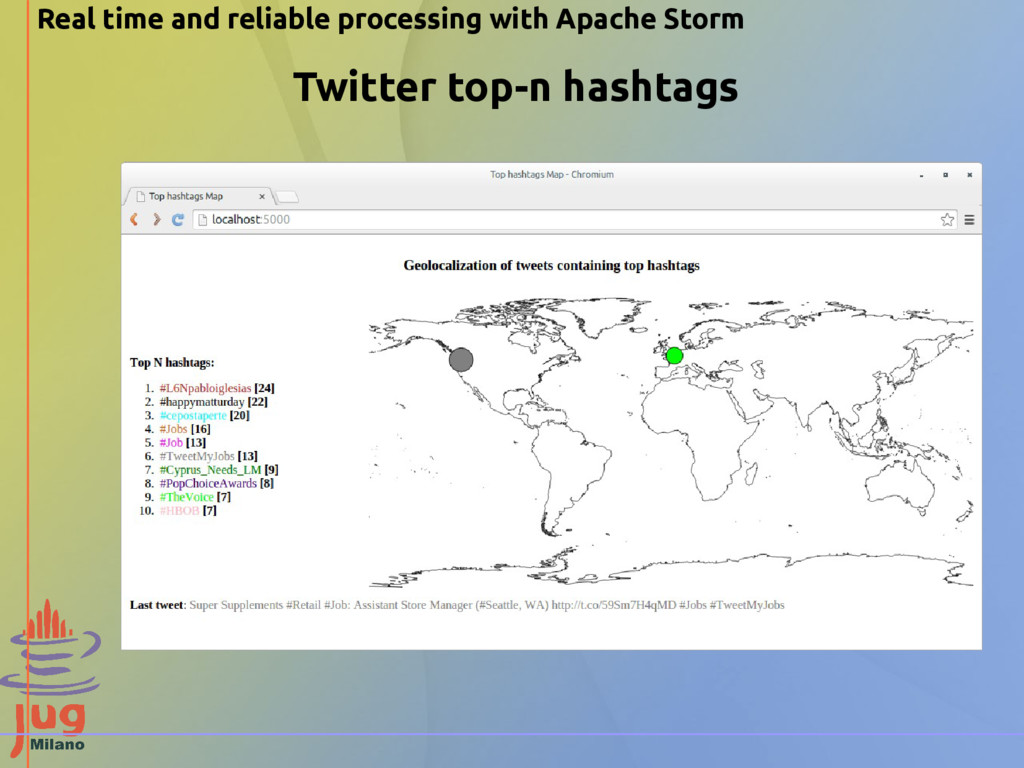{kind=link}
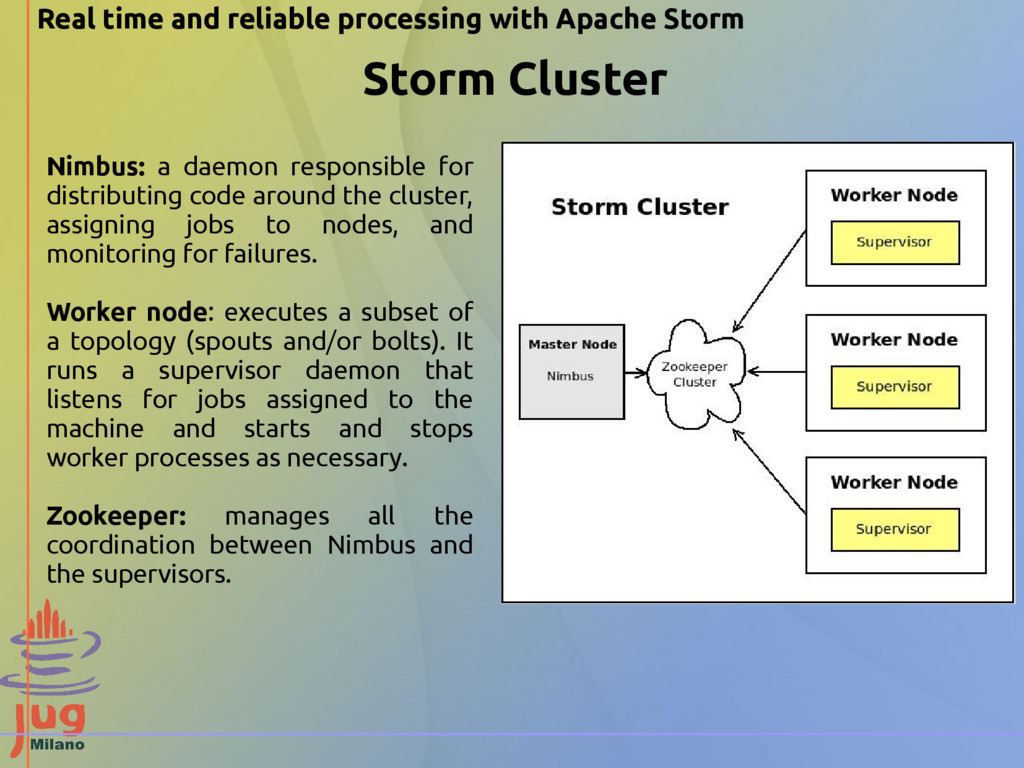{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}