sample = 128 / 1259712, flags = list( conv_1_filters = c(16, 32, 64), conv_1_kernel = c(8, 16, 32), conv_1_pooling = c(2, 4), conv_1_dropout = c(0.1, 0.2, 0.5), conv_2_filters = c(16, 32, 64), conv_2_kernel = c(8, 16, 32), conv_2_pooling = c(2, 4), conv_2_dropout = c(0.1, 0.2, 0.5), dense_1_nodes = c(32, 64, 128, 256), dense_1_dropout = c(0.1, 0.2, 0.5), dense_2_nodes = c(32, 64, 128, 256), dense_2_dropout = c(0.1, 0.2, 0.5) )) 1.2M total combinations of flags (sampled to 128 combinations)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
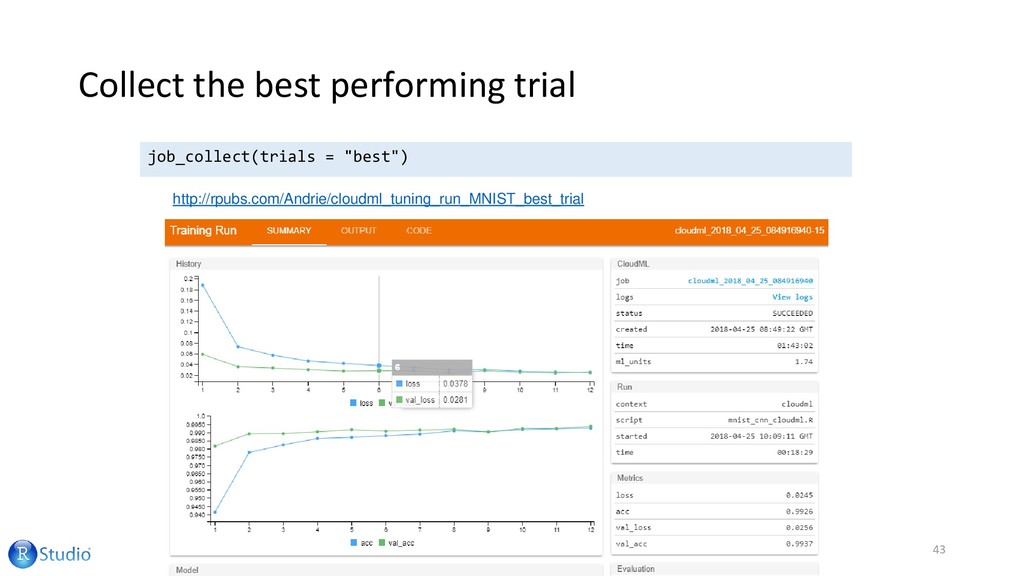{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}