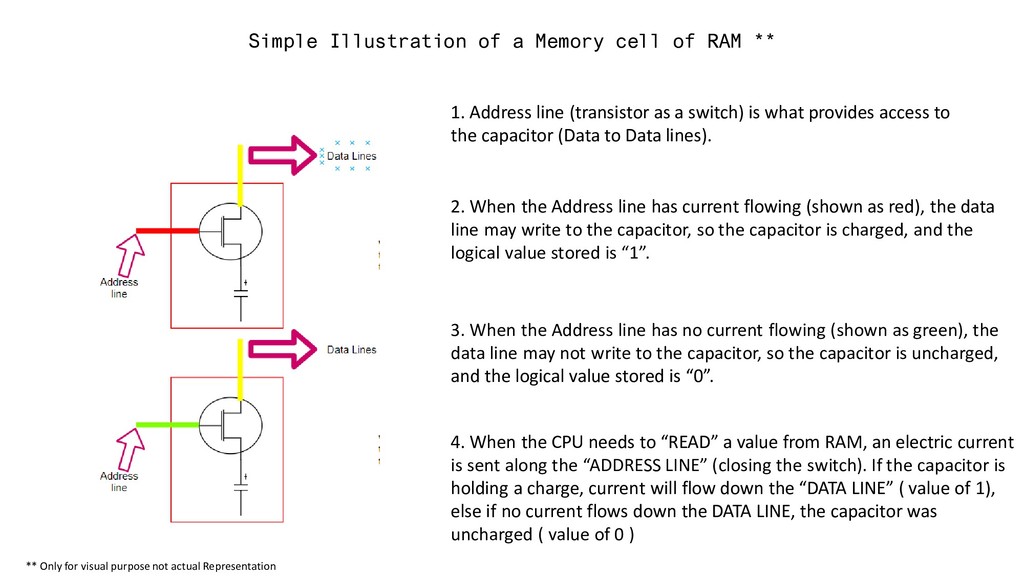
Only for visual purpose not actual Representation 1. Address line (transistor as a switch) is what provides access to the capacitor (Data to Data lines). 2. When the Address line has current flowing (shown as red), the data line may write to the capacitor, so the capacitor is charged, and the logical value stored is “1”. 3. When the Address line has no current flowing (shown as green), the data line may not write to the capacitor, so the capacitor is uncharged, and the logical value stored is “0”. 4. When the CPU needs to “READ” a value from RAM, an electric current is sent along the “ADDRESS LINE” (closing the switch). If the capacitor is holding a charge, current will flow down the “DATA LINE” ( value of 1), else if no current flows down the DATA LINE, the capacitor was uncharged ( value of 0 )
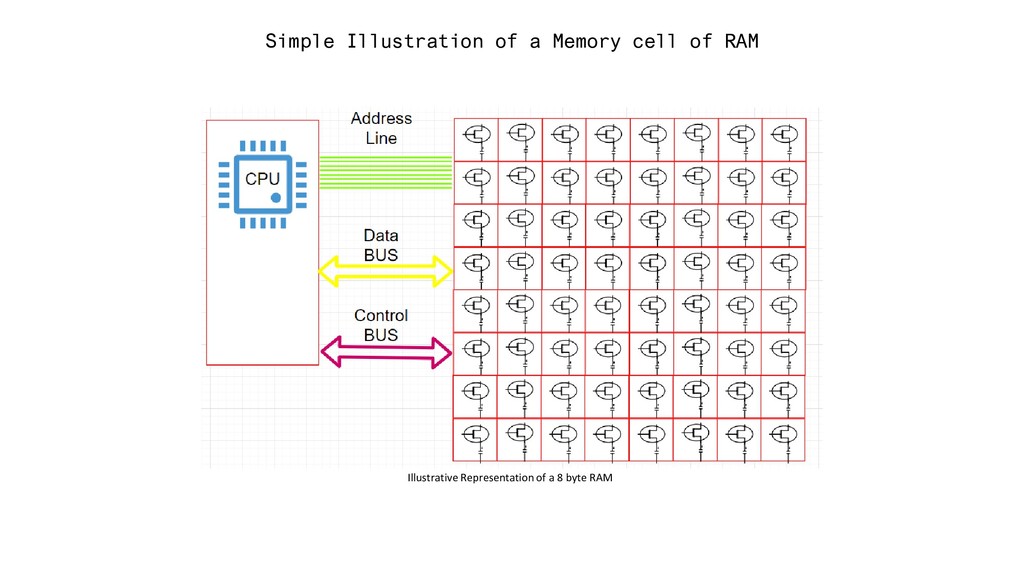
“BYTE” in DRAM is assigned a unique numeric identifier (address). “Physical bytes present != Number of address line”. ( eg 16bit intel 8088, PAE ) 2. Each “Address line can send 1 bit value, so it basically specifies a “SINGLE BIT” in the address of a given byte. 3. In our Diagram we have 32 address line. So each BYTE will get “32 bit” as address. [ 00000000000000000000000000000000 ] – low memory address. [ 11111111111111111111111111111111 ] – high memory address. 4. Since we have 32 bit address for each byte, so our address space consists of 2^32 addressable bytes (4 GB).
virtual address space. 2. Address of a byte in this virtual address space is no longer the same as the address that the processor places on the address bus. This means that translation data structures and code will have to be established in order to map a byte in the virtual address space to a physical byte.
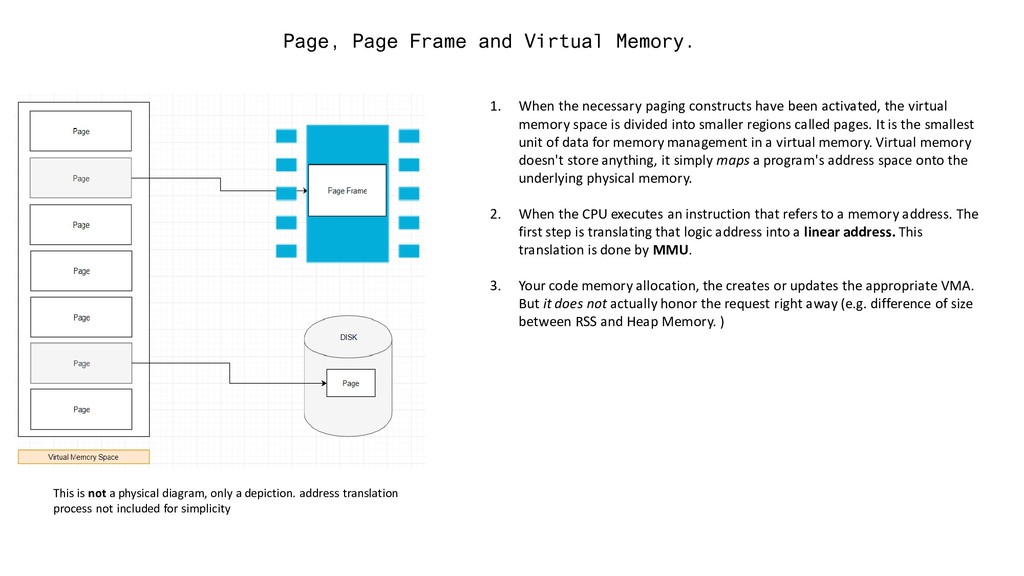
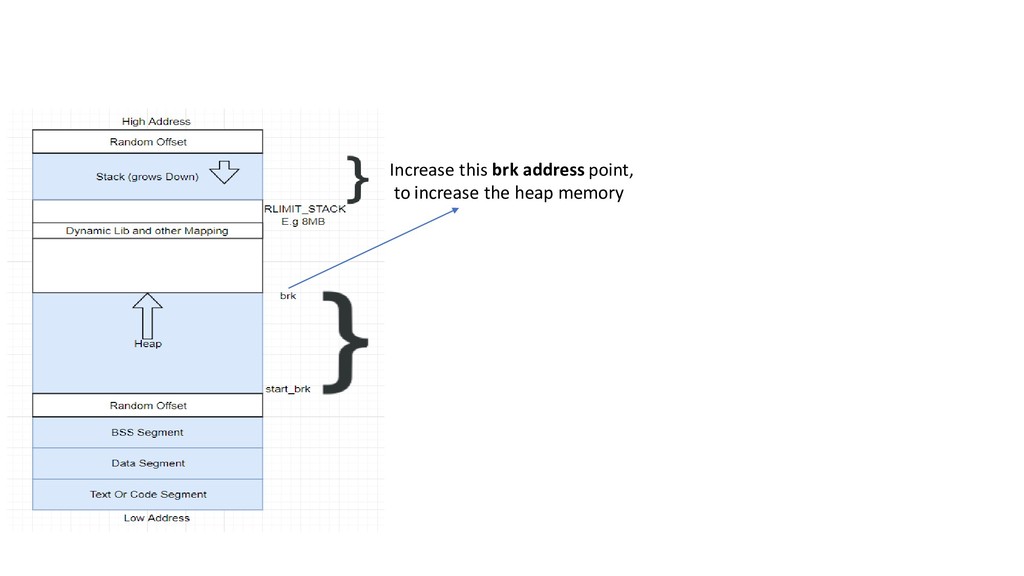
paging constructs have been activated, the virtual memory space is divided into smaller regions called pages. It is the smallest unit of data for memory management in a virtual memory. Virtual memory doesn't store anything, it simply maps a program's address space onto the underlying physical memory. 2. When the CPU executes an instruction that refers to a memory address. The first step is translating that logic address into a linear address. This translation is done by MMU. 3. Your code memory allocation, the creates or updates the appropriate VMA. But it does not actually honor the request right away (e.g. difference of size between RSS and Heap Memory. ) This is not a physical diagram, only a depiction. address translation process not included for simplicity
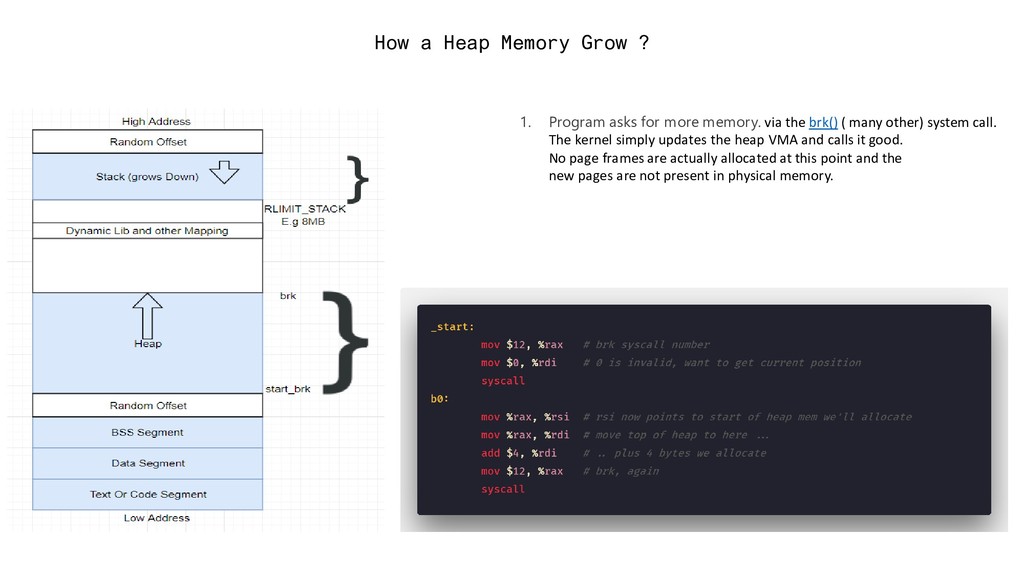
more memory. via the brk() ( many other) system call. The kernel simply updates the heap VMA and calls it good. No page frames are actually allocated at this point and the new pages are not present in physical memory.
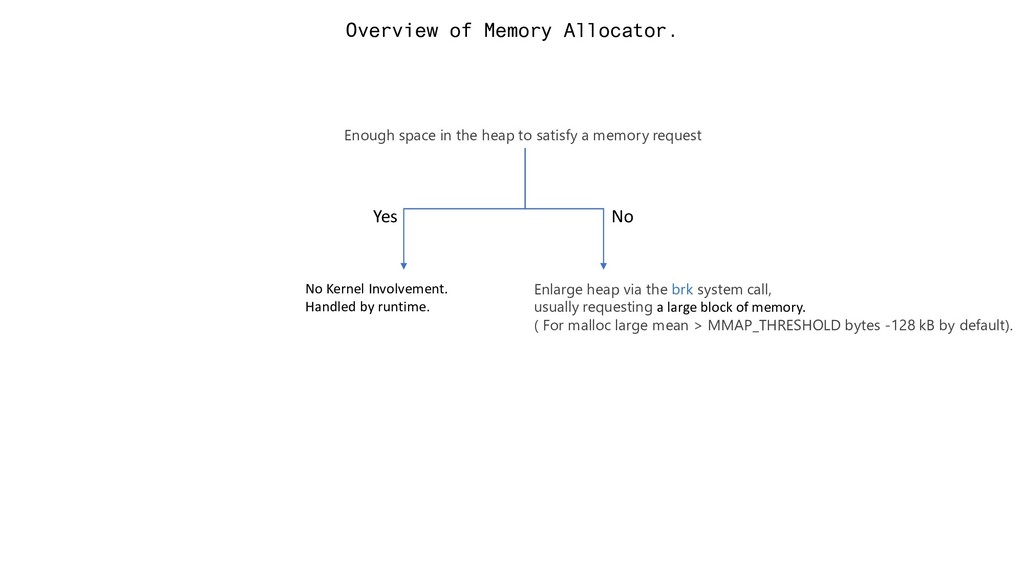
satisfy a memory request No Yes No Kernel Involvement. Handled by runtime. Enlarge heap via the brk system call, usually requesting a large block of memory. ( For malloc large mean > MMAP_THRESHOLD bytes -128 kB by default).
– Memory is allocated by the allocator larger than the memory requested. 2. External – Memory is too small to be allocated to the program. So Where does the memory fragment come from ? The answer to this question depends on the specific memory allocation algorithm. 1. Free List 2. Segregated Free List 3. Buddy System
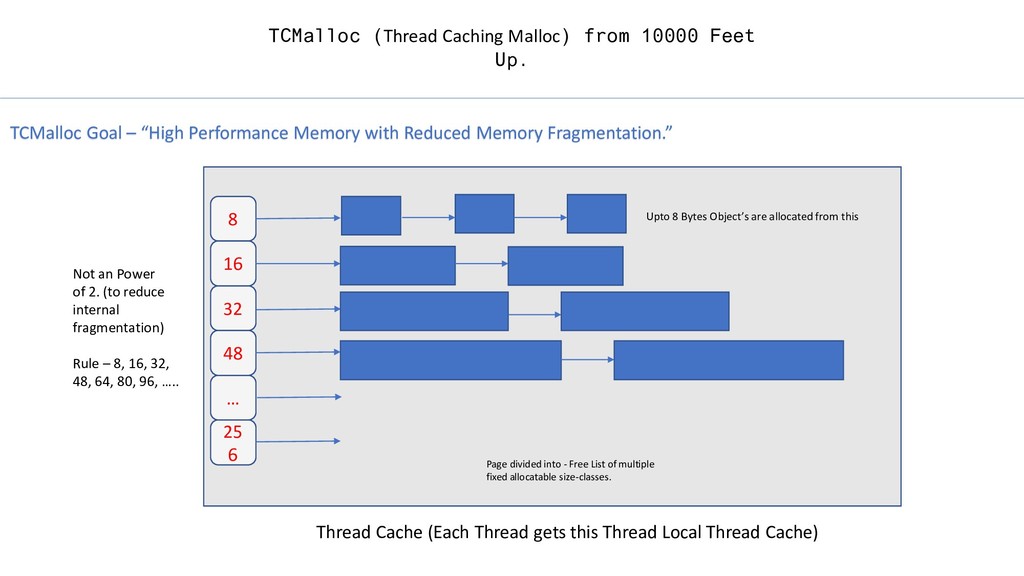
Object’s are allocated from this TCMalloc (Thread Caching Malloc) from 10000 Feet Up. TCMalloc Goal – “High Performance Memory with Reduced Memory Fragmentation.” Page divided into - Free List of multiple fixed allocatable size-classes. Not an Power of 2. (to reduce internal fragmentation) Rule – 8, 16, 32, 48, 64, 80, 96, ….. Thread Cache (Each Thread gets this Thread Local Thread Cache)
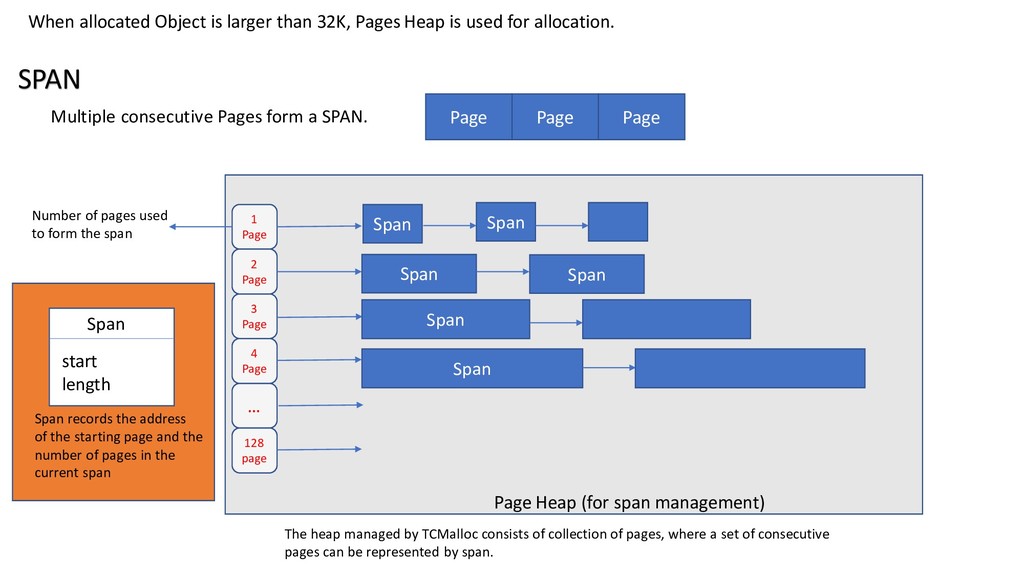
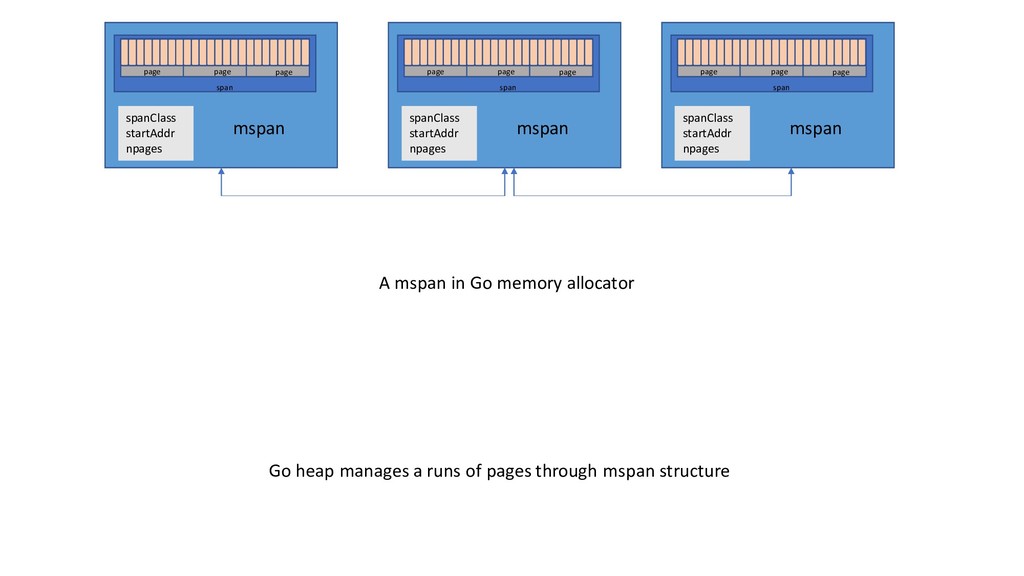
used for allocation. Multiple consecutive Pages form a SPAN. SPAN Page Page Page 1 Page 2 Page 3 Page 4 Page … 128 page Span Span Span Span Span Span Page Heap (for span management) Number of pages used to form the span Span start length Span records the address of the starting page and the number of pages in the current span The heap managed by TCMalloc consists of collection of pages, where a set of consecutive pages can be represented by span.
page span spanClass startAddr npages mspan page page page span spanClass startAddr npages mspan A mspan in Go memory allocator Go heap manages a runs of pages through mspan structure
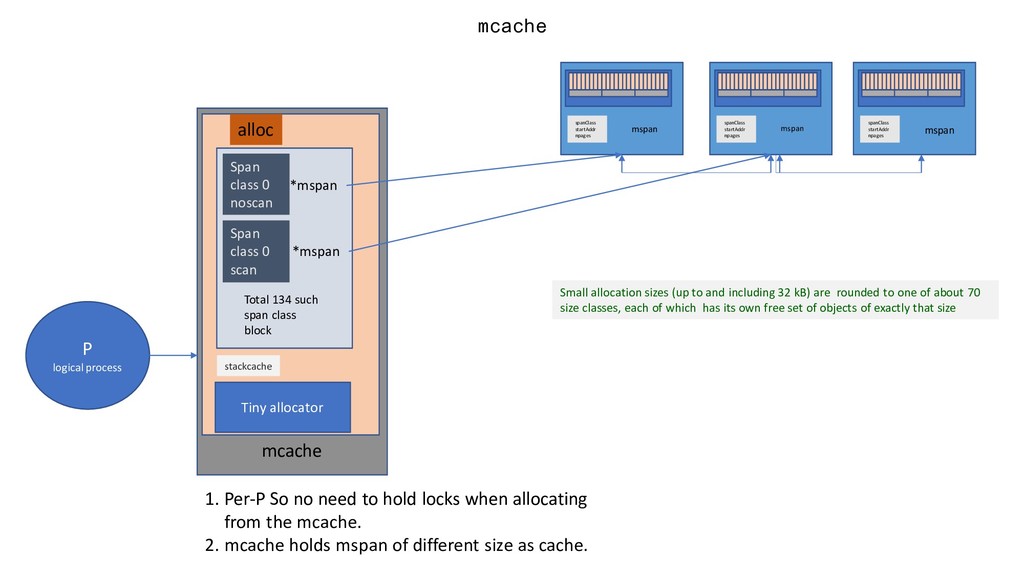
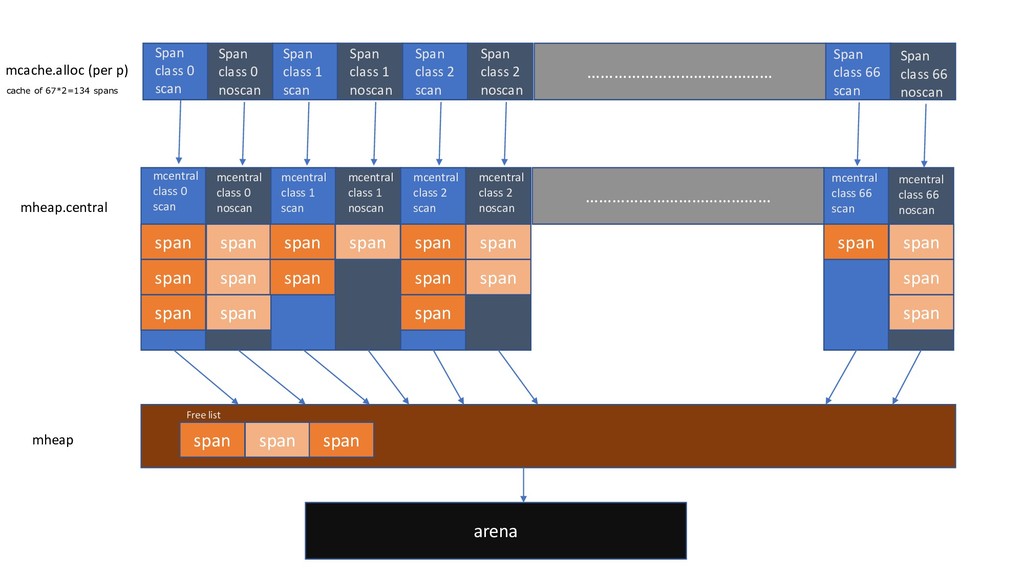
*mspan *mspan Tiny allocator Total 134 such span class block mcache stackcache P logical process 1. Per-P So no need to hold locks when allocating from the mcache. 2. mcache holds mspan of different size as cache. spanClass startAddr npages mspan spanClass startAddr npages mspan spanClass startAddr npages mspan Small allocation sizes (up to and including 32 kB) are rounded to one of about 70 size classes, each of which has its own free set of objects of exactly that size
object allocator tiny of mcache. (In fact, tiny is a pointer, let's just say that.) 2.Object size > 16 byte && size <=32K byte, first use the corresponding size class allocation in mcache. What Goes to mcache.
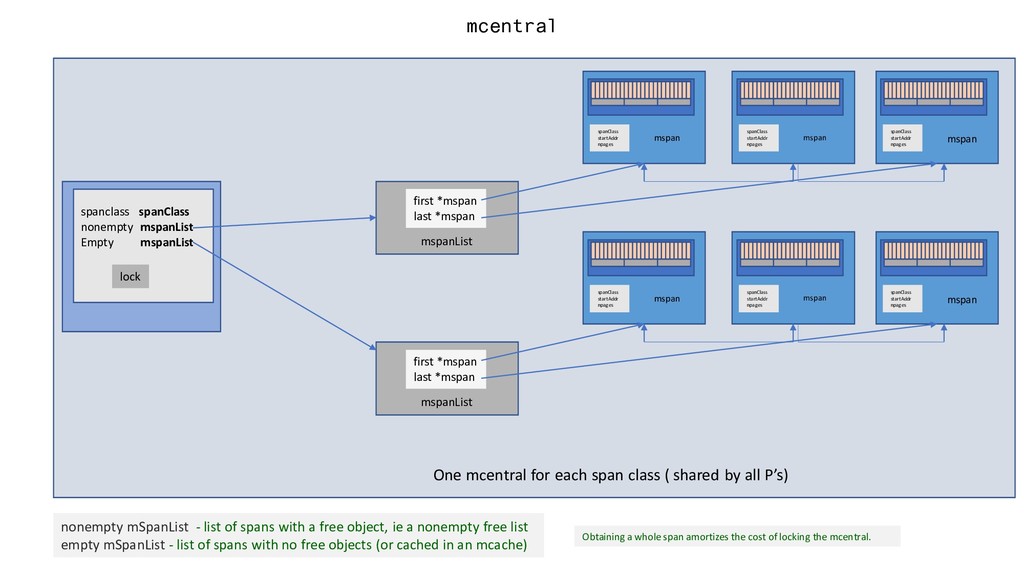
for each span class ( shared by all P’s) first *mspan last *mspan mspanList spanClass startAddr npages mspan spanClass startAddr npages mspan spanClass startAddr npages mspan first *mspan last *mspan mspanList spanClass startAddr npages mspan spanClass startAddr npages mspan spanClass startAddr npages mspan nonempty mSpanList - list of spans with a free object, ie a nonempty free list empty mSpanList - list of spans with no free objects (or cached in an mcache) Obtaining a whole span amortizes the cost of locking the mcentral.
allocated directly from mheap • Size < 16B, using mcache's tiny allocator allocation • Size between 16B ~ 32k, calculate the sizeClass to be used, and then use the block allocation of the corresponding sizeClass in mcache • If the sizeClass corresponding to mcache has no available blocks, apply to mcentral • If there are no blocks available for mcentral, apply to mheap and use BestFit to find the most suitable mspan. If the application size is exceeded, it will be divided as needed to return the number of pages the user needs. The remaining pages constitute a new mspan, and the mheap free list is returned. • If there is no span available for mheap, apply to the operating system for a new set of pages (at least 1MB) Allocating a large run of pages amortizes the cost of talking to the operating system. But Go allocates pages in even large size at OS Level.
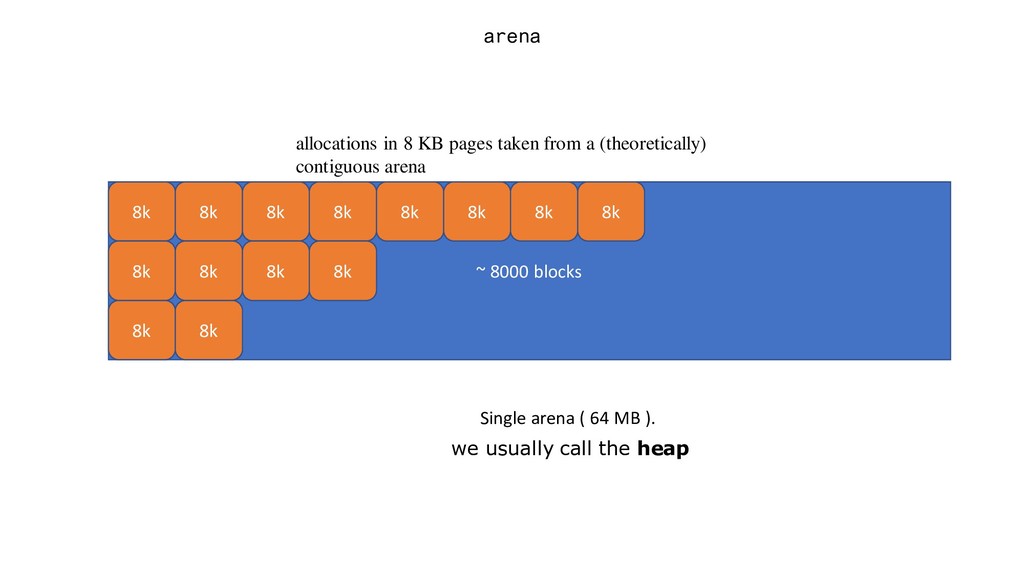
consists of a set of arenas. The initial heap mapping is one arena i.e 64MB. Currently sized as (v 1.11.5) Note: Please take these number with a grain of salt. Subject to change. 1. Earlier go used to reserve a continuous virtual address upfront, on 64-bit system the arena size was 512 GB. ( what happens if an allocations are large enough and is rejected by mmap ?) 2. Currently memory is mapped in small increments as our program needs it.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![mheap mcentral mspanList mspanList mcentral mspanList mspanList mheap.central [numSpanClasses] total](https://files.speakerdeck.com/presentations/aae5db4fa2eb4d869c233aa11664b1c9/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}