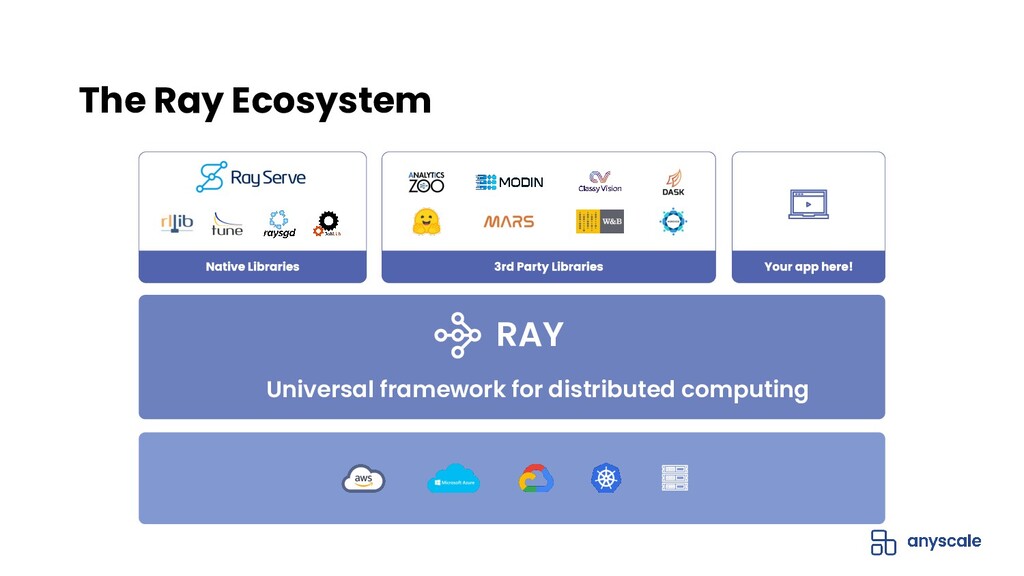
Ray Serve is a framework-agnostic and Python-first model serving library built on Ray. In this introductory webinar on Ray Serve, we will highlight how Ray Serve makes it easy to deploy, operate and scale a machine learning API.
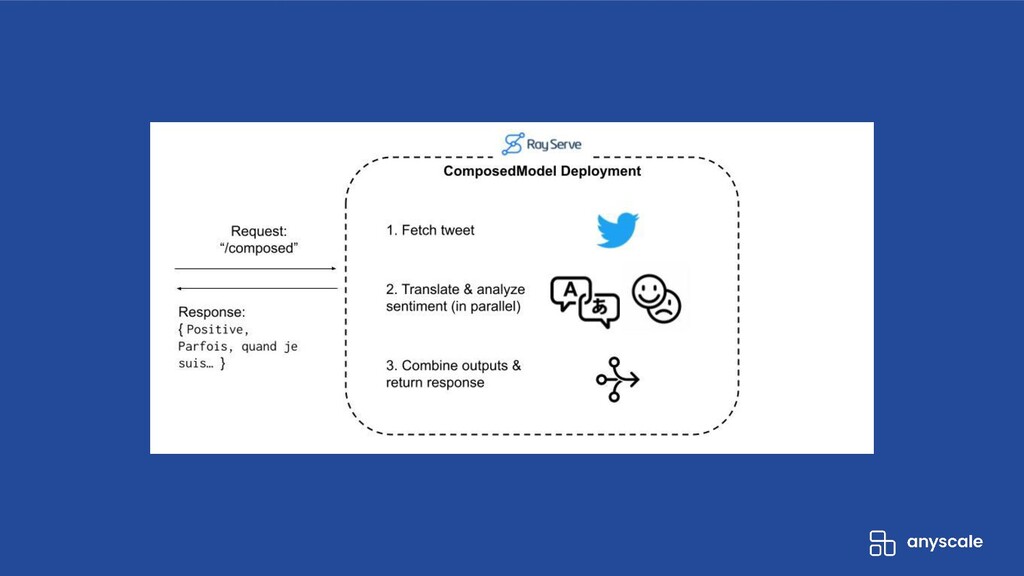
The core of the webinar will be a live demo that shows how to build a scalable API using Natural Language Processing models.
The demo will show how to:
- Deploy a trained Python model and scale it to a cluster using Ray Serve
- Improve the HTTP API using Ray Serve’s native FastAPI integration
- Compose multiple independently-scalable models into a single model, and run them in parallel to minimize latency.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}