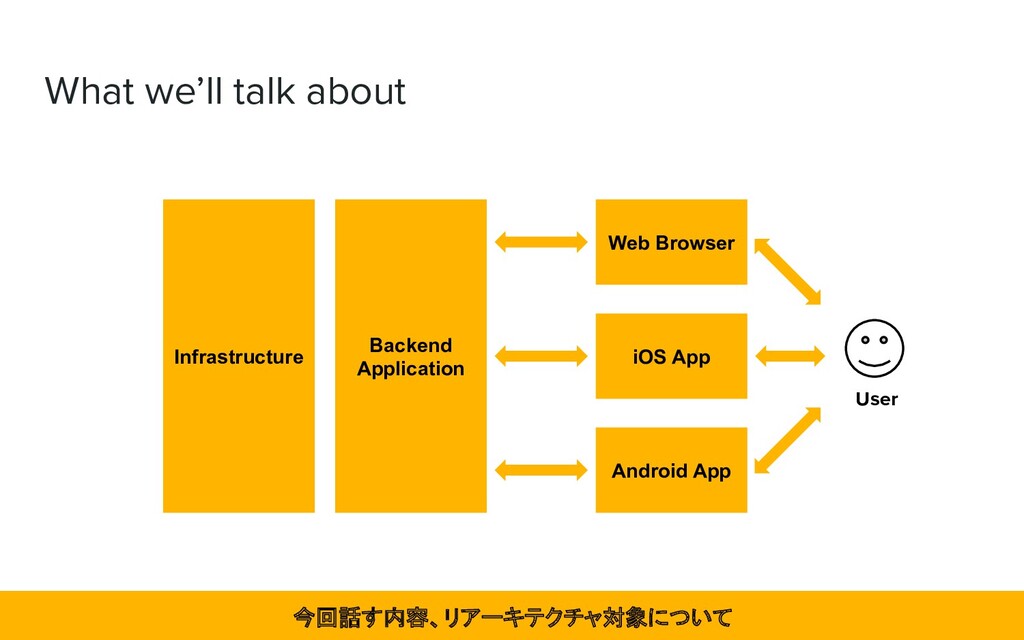
How did we perform re-architecting? ◦ Infrastructure and Backend application Improving ➢ To avoid adding to Technical debt ◦ Development Team Initiatives ➢ Conclusion どのようにリアーキテクチャを行なったのか、技術的負債を増やさない対策をしたのか
stop feature development ➔ We can’t stop backend system 24/7 ➔ There's no time to pay off the technical debt ➔ Almost none people involved in the initial development of the system サービスも機能開発も止められない、時間も足りない、初期開発メンバーもほぼいない
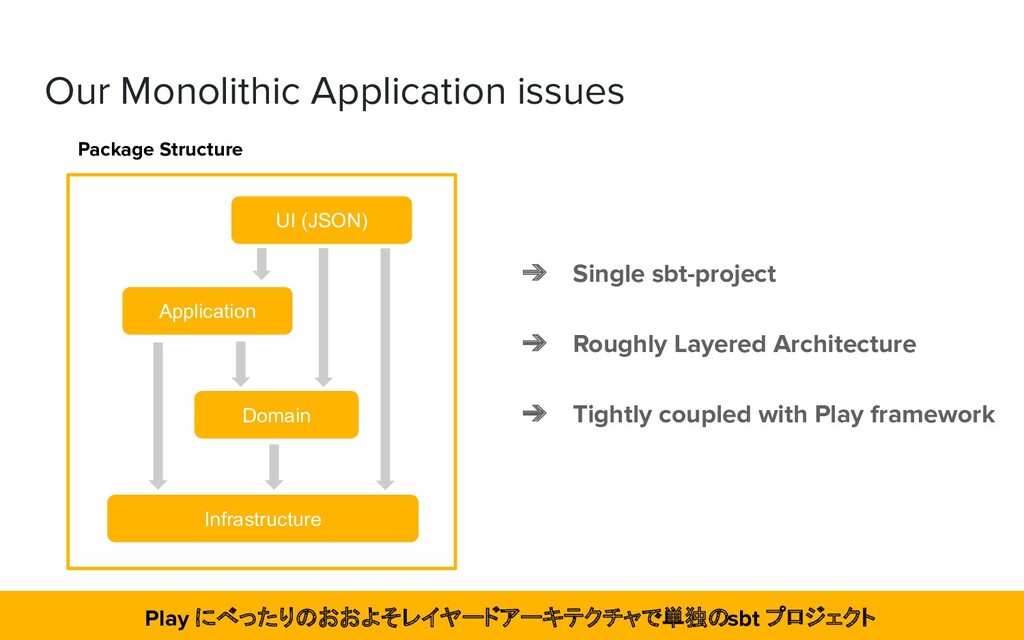
both the infrastructure and backend application. ➢ Difficult to solve just by refactoring the application ❖ We decided to focus on improving the infrastructure first and then improve the application. アプリケーションのリファクタリングだけでは根本解決が難しいので、インフラ改善から着手
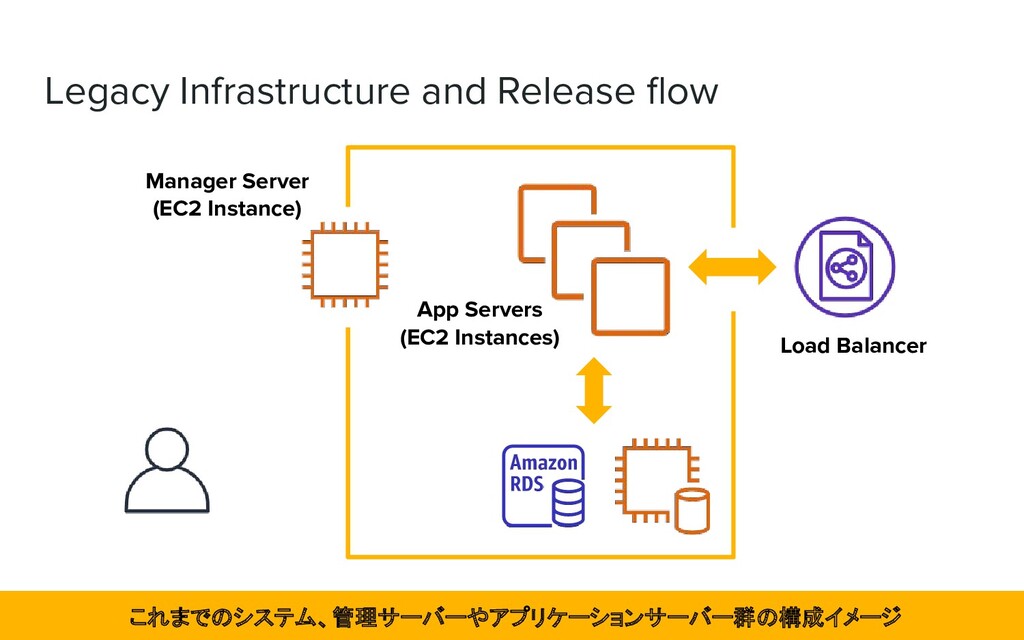
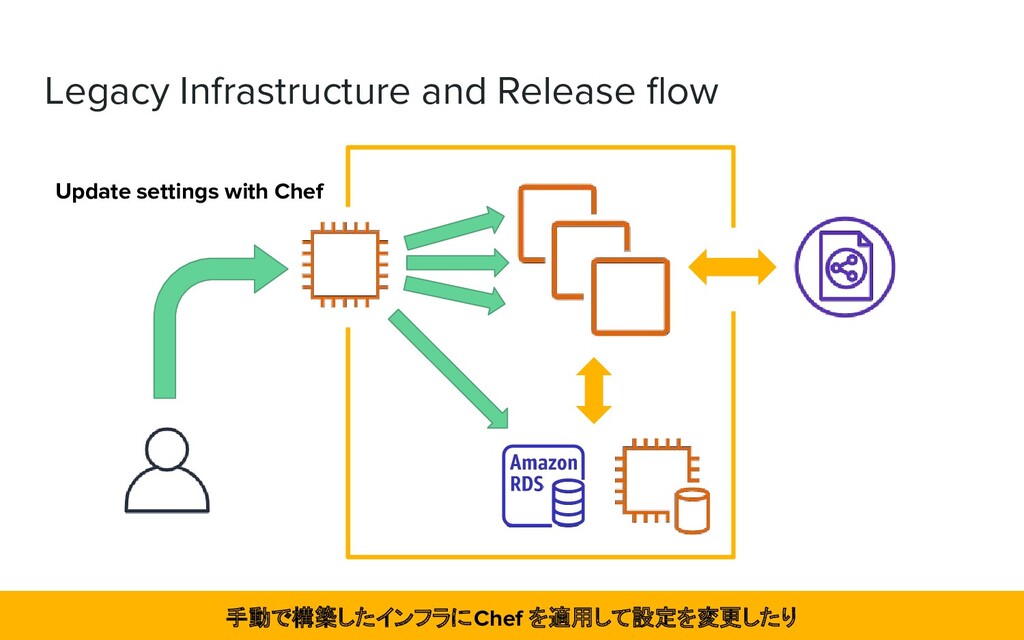
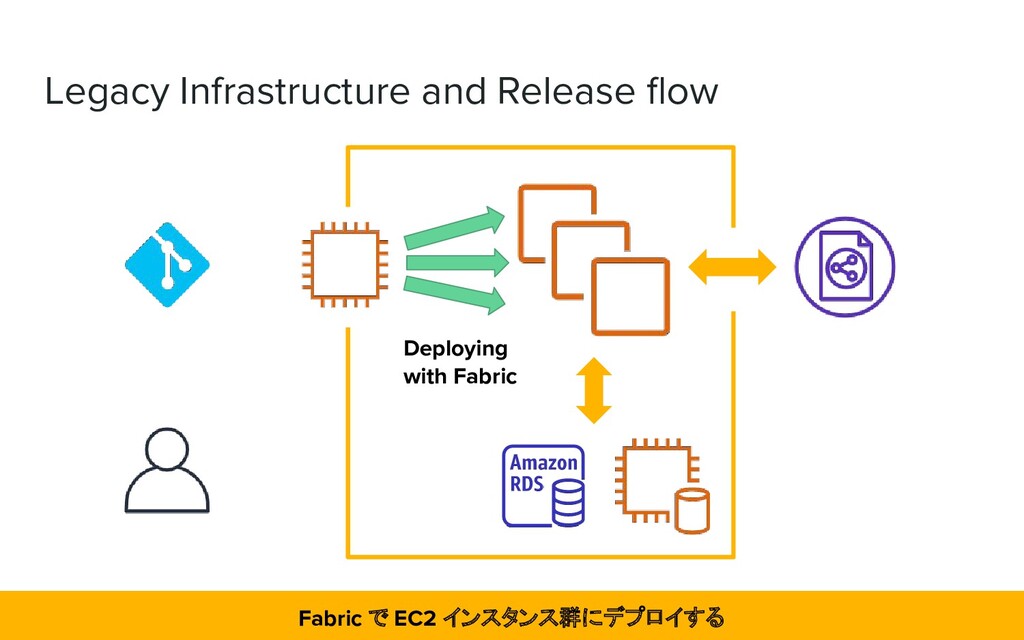
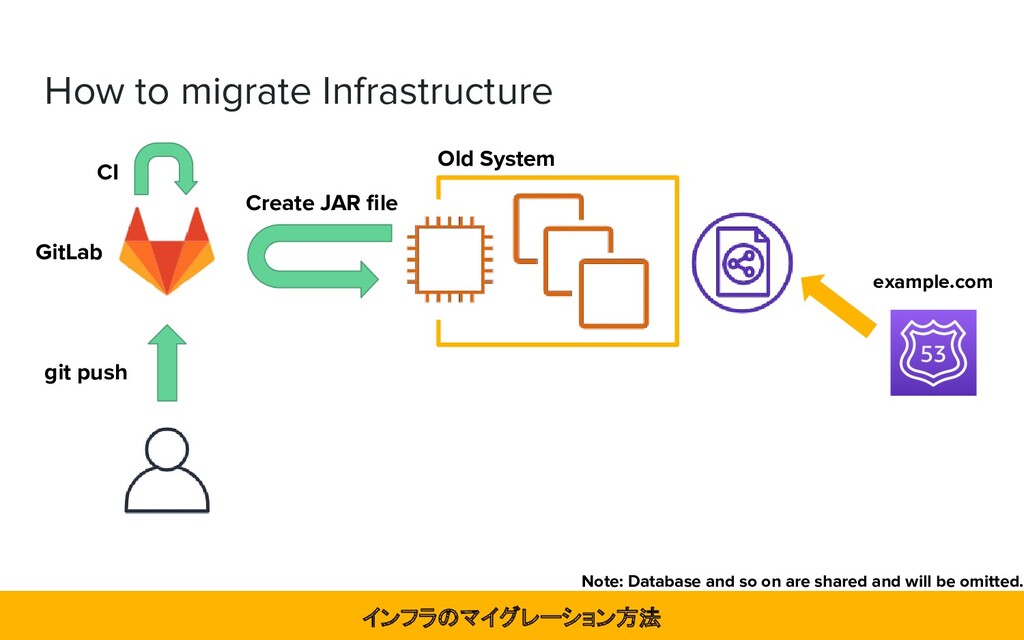
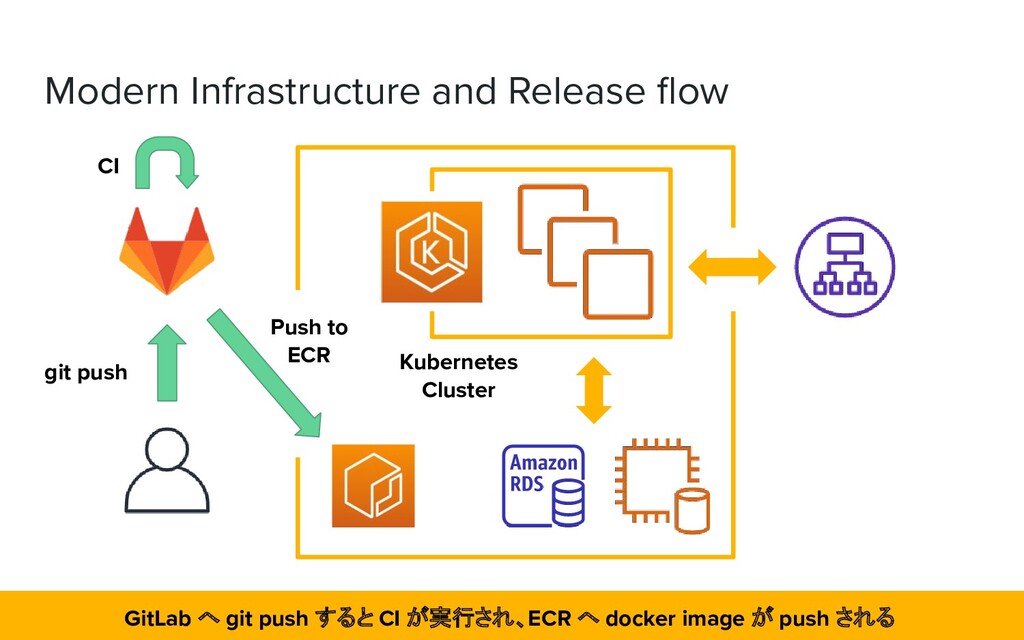
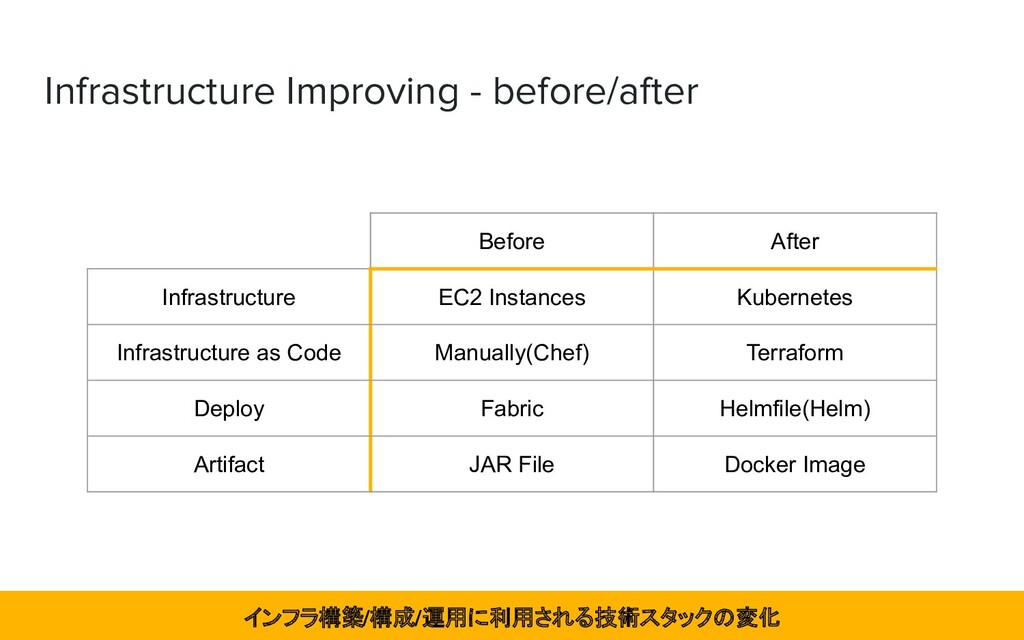
manually and Chef on AWS ➔ Create and deploy artifacts in Fabric ➔ Launching backend application on Amazon EC2 instance 大半が手動で AWS 上に構築されたインフラで、EC2 インスタンスに Fabric でデプロイしていた
possible ➔ Chef, Fabric are practically unmaintainable due to the secret sauce ➔ The current infrastructure is not reproducible Auto Scaling ができず、Chef や Fabric が秘伝のタレでインフラの再現が難しい状態
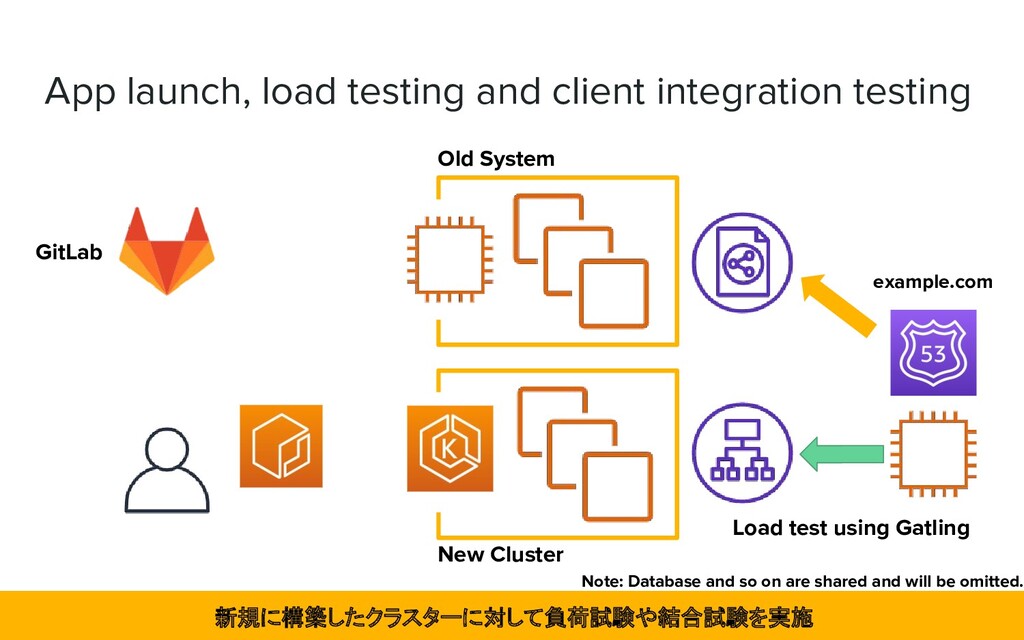
a lot of AWS services ➢ As a result of the test, we determined that it was practical and could be operated by us if it was managed ❖ The team had engineers familiar with Cloud Native technology ➢ Not EKS, but the k8s itself had already been introduced in the company EKS を採用。社内導入事例もあり、検証して実用可能と判断
Auto Scaling ❖ Using Terraform for Configuration Management ➢ Managing configuration with declarative statements ❖ Prepare load test scenarios with Gatling ➢ Added the ability to simulate the load on the system during operation ➢ To verify that the newly built environment meets the required specifications Auto Scaling に対応し、構成を宣言的記述で管理。負荷テスト環境を構築した。
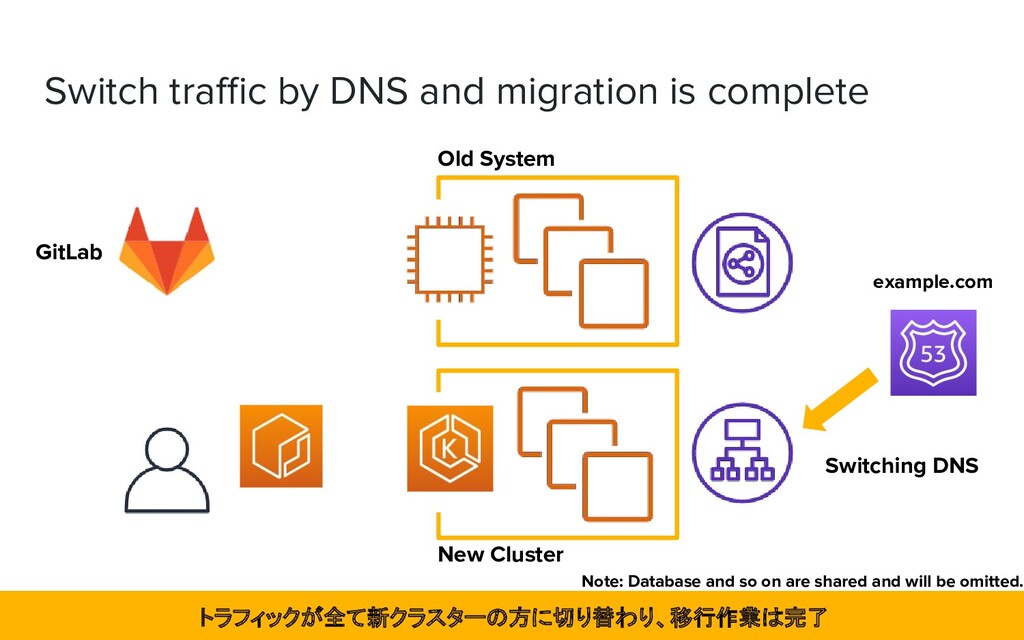
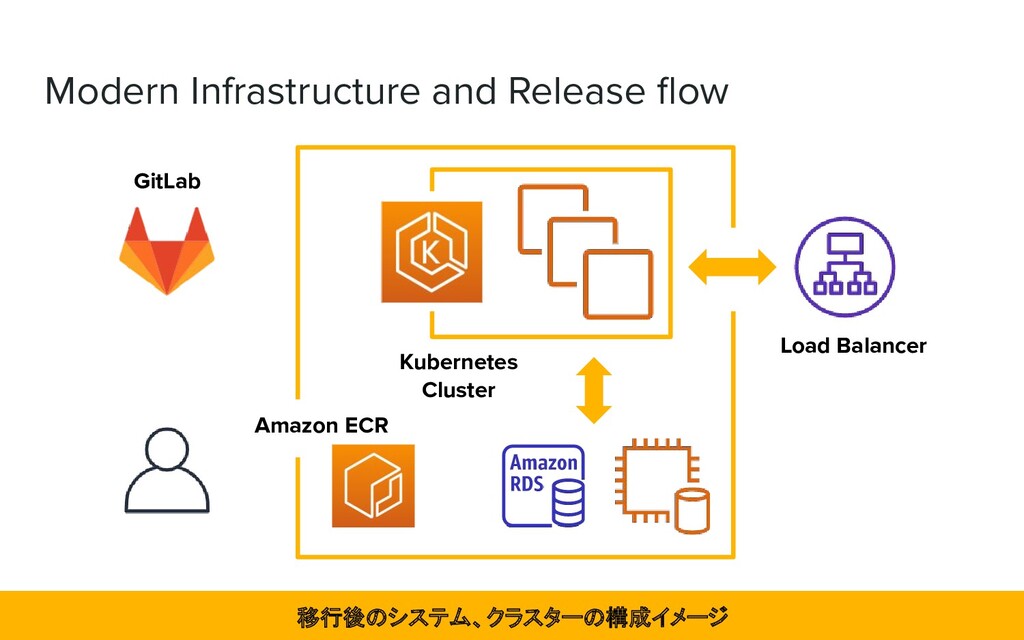
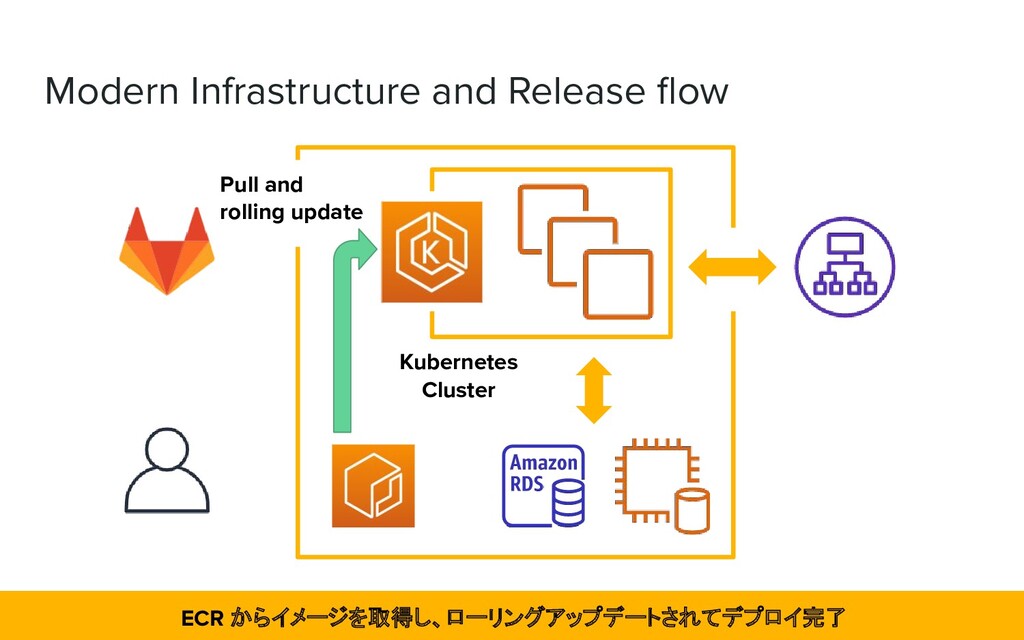
Application is now more flexible ➢ Terraform allows us to rebuild our own systems from the infrastructure ➢ Existing members of the team are now experienced in building initial infrastructure ❖ It led to reduced operational costs ➢ All application engineers can now manage the infrastructure as well アプリケーション分割に自由度が生まれ、再構築が可能になり、コスト削減にもつながった
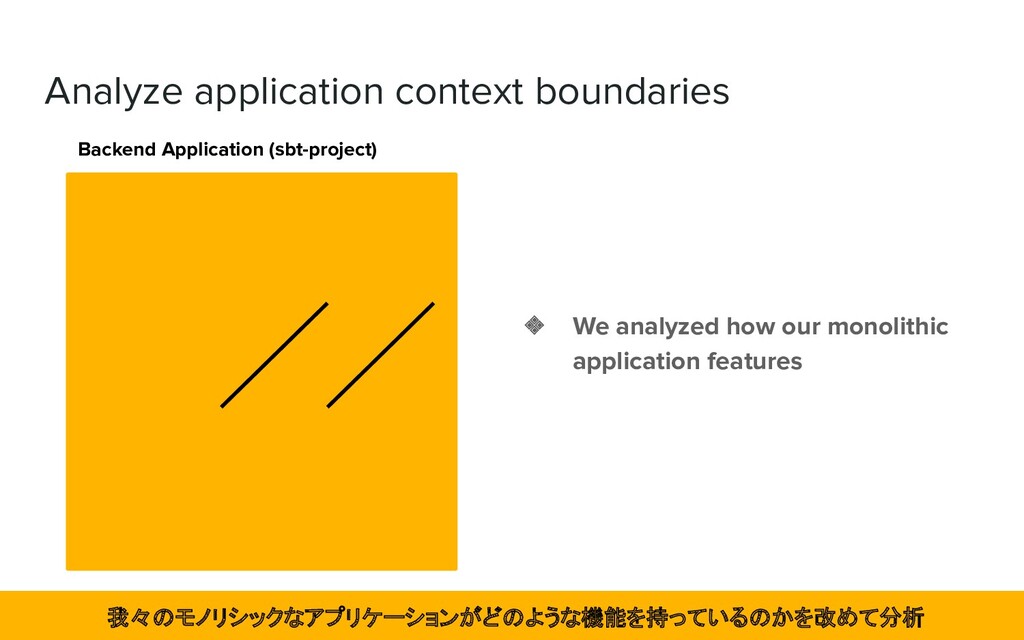
for the team structure. ❖ The aggregation was not sufficiently analyzed. ➢ It was decided that the first step was to better define the context boundaries of the application. ❖ There were many considerations ➢ The first priority is to develop features. Then we had to get used to developing and operating on the new infrastructure. ➢ Technology verification is underway. マイクロサービス化実施せず。機能開発、新インフラの運用に慣れることを優先。技術検証中
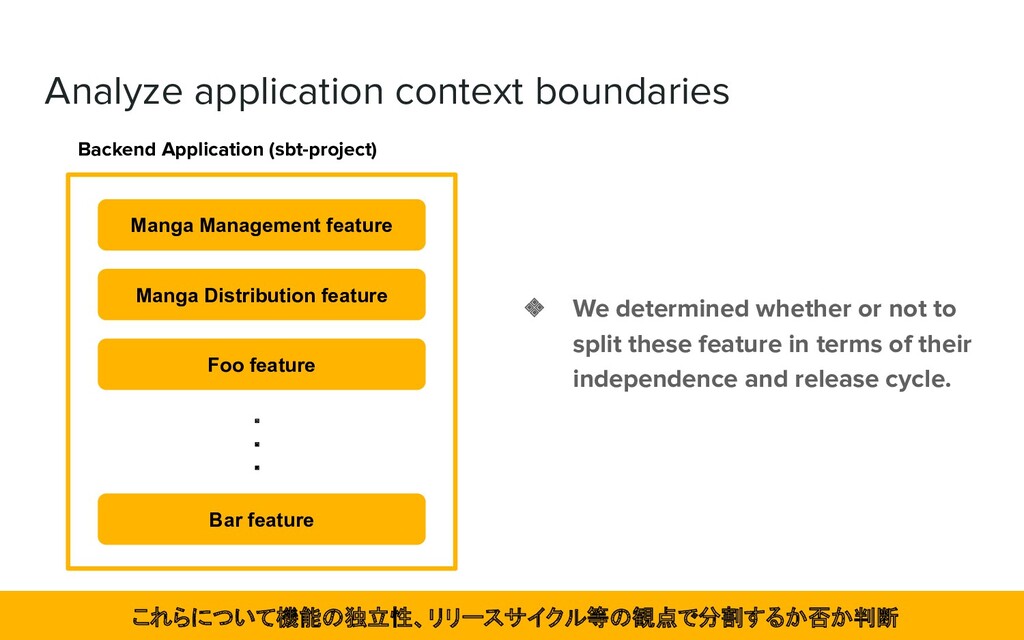
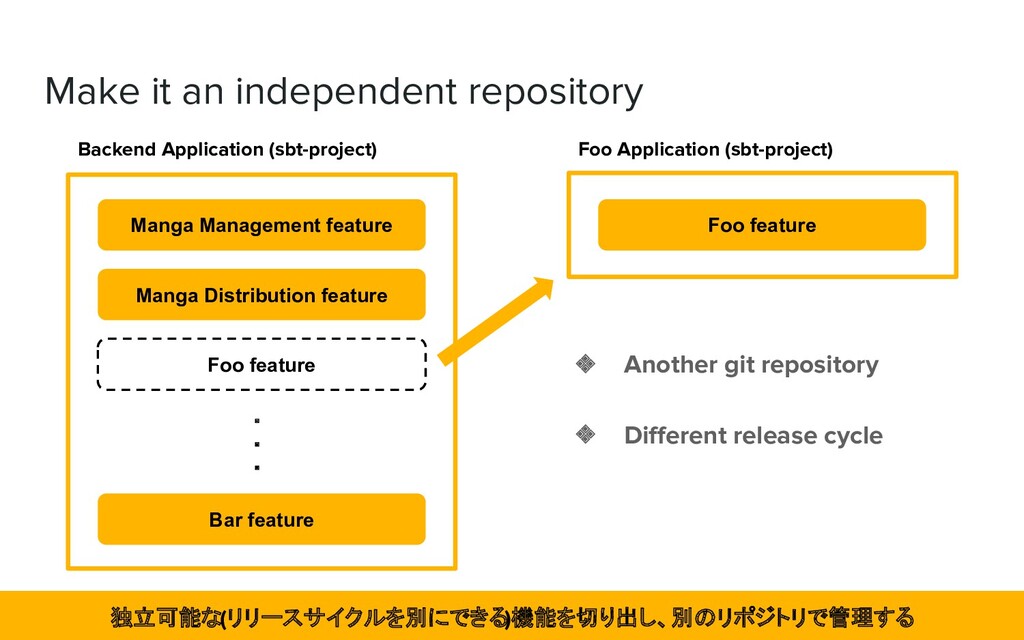
whether or not to split these feature in terms of their independence and release cycle. Manga Management feature Manga Distribution feature Foo feature Bar feature ・ ・ ・ これらについて機能の独立性、リリースサイクル等の観点で分割するか否か判断
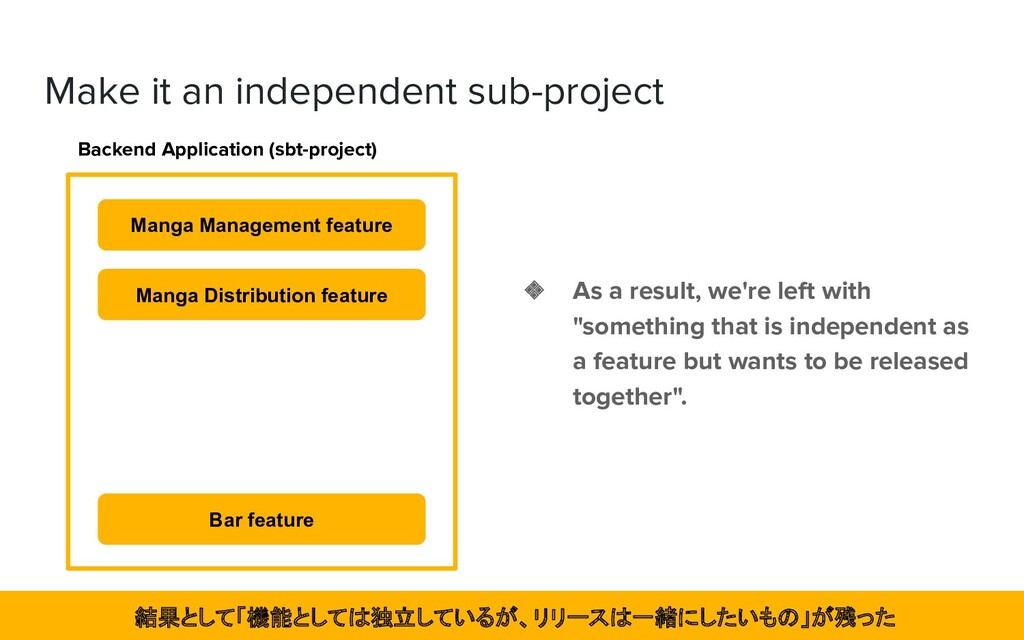
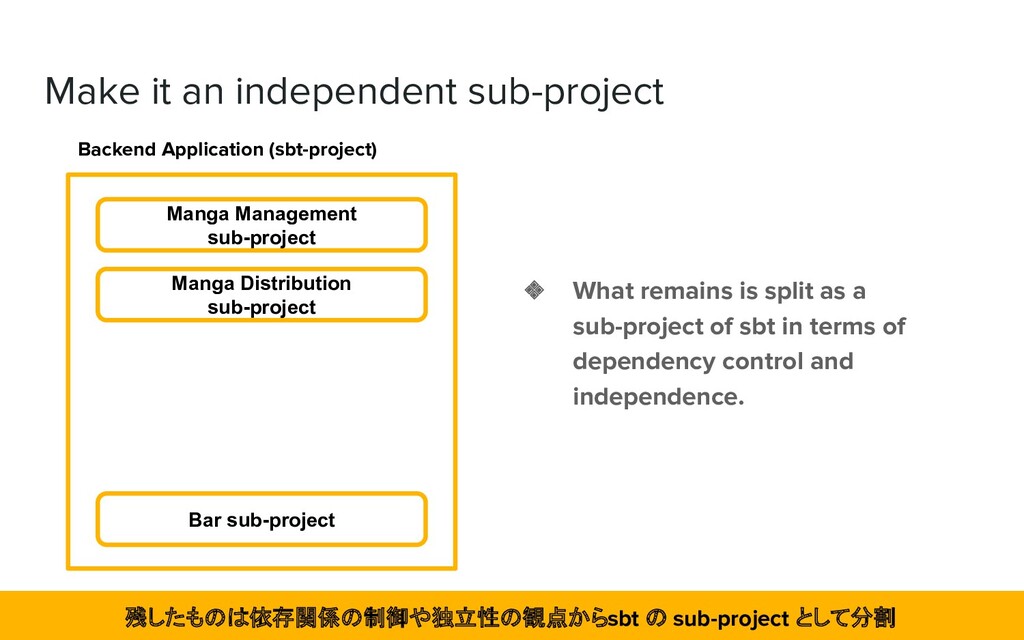
feature Manga Distribution feature Bar feature ❖ As a result, we're left with "something that is independent as a feature but wants to be released together". 結果として「機能としては独立しているが、リリースは一緒にしたいもの」が残った
sub-project Manga Distribution sub-project Bar sub-project ❖ What remains is split as a sub-project of sbt in terms of dependency control and independence. 残したものは依存関係の制御や独立性の観点から sbt の sub-project として分割
between features ❖ Localized settings ❖ Easier to test and confirm operation lazy val root = project .aggregate( mangaManagement, mangaDistribution, bar ) lazy val mangaManagement = project lazy val mangaDistribution = project lazy val bar = project build.sbt sub-project に切り出したことで依存管理や設定の局所化、テスト /動作確認が行いやすくなる
domain model ➔ API response consisting of multiple aggregates ➔ Will request multiple queries from the DB. Difficult to JOIN in SQL ➔ Discrepancies in data structures required by read/write are a factor 読み込み/書き込み、それぞれの場面で求められるドメインモデルは構造が異なる
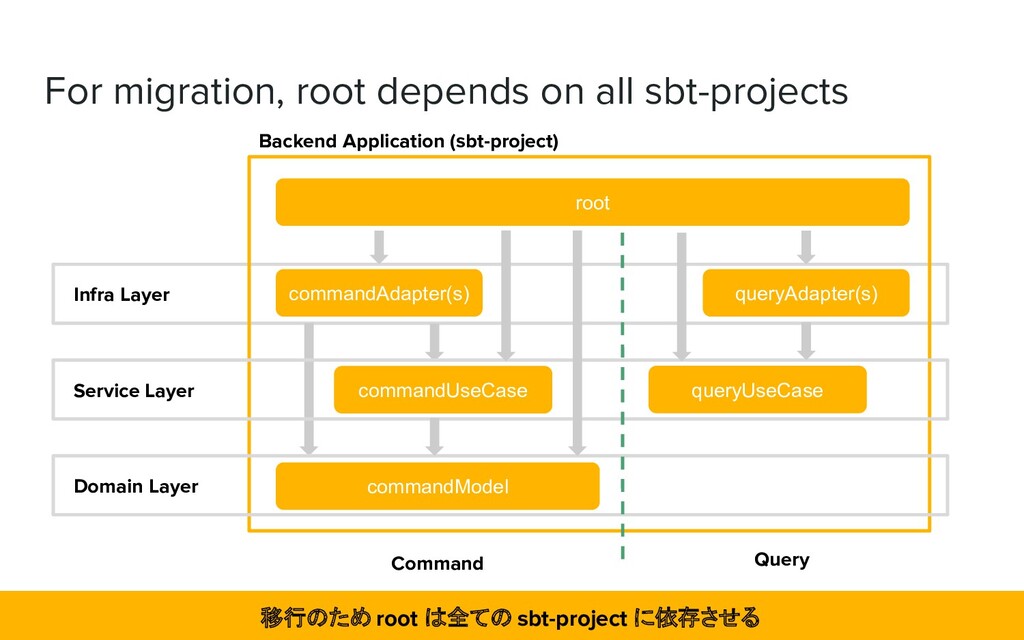
want to keep the release cycle the same, so we'll separate it in build.sbt ❖ The sbt project setting is split based on the port/adapter pattern データベースは共有とした。ヘキサゴナルアーキテクチャをベースに sbt-project を分割
response JSON was dynamically assembled ➔ The structure cannot be ignored in order to migrate the implementation without changing the behavior of the API ➔ There was a demand for this in the development of new API ➔ It's hard to documentation with OpenAPI レスポンス JSON が動的に組み立てられていた。構造をドキュメント化したいが OpenAPI は辛い
❖ No need to test the JSON structure, so less testing time is required ❖ The generated DTO makes it easier to implement new features DSL を開発したことで仕様定義やテスト、 API の移行や新機能の開発について工数を削減できた
has made it easier to estimate the work ➢ Reduced CI and release time ❖ Open to expand and close to modify compared to before re-architecture ➢ It also led to a system for inter-service communication in the k8s cluster 分割したことで作業見積もりのしやすさや CI/CD の時間削減、機能の追加変更に強くなった
on the size of the development item ➢ Design is always necessary, but you can flexibly switch between them depending on the scale of the project and the time it takes to work. ➢ If it is complicated, implement user story mapping etc ❖ Incorporated the definition of communication format by DSL into the flow ➢ Developers can now seamlessly define specifications between server and client 規模感に応じた設計/開発の流れを柔軟に。API 仕様定義 DSL を開発フローに組み込んだ
a baseball team. ➢ It is not a Camping ➢ Held once a quarter, two weeks ❖ Do “Not Urgent but Important” tasks. ➢ No feature development tickets will be implemented. ❖ Contributes not only to repayment of technical debt, but also to elimination of events that could become debt in the future 四半期に一度「重要だけど緊急でない」作業に二週間がっつり取り組む通称「キャンプ」を実施
Backend Application is now more flexible ➢ Terraform allows us to rebuild our own systems from the infrastructure ➢ Existing members of the team are now experienced in building initial infrastructure ❖ It led to reduced operational costs ➢ All application engineers can now manage the infrastructure as well アプリケーション分割に自由度が生まれ、再構築が可能になり、コスト削減にもつながった
feature has made it easier to estimate the work ➢ Reduced CI and release time ❖ Open to expand and close to modify compared to before re-architecture ➢ It also led to a system for inter-service communication in the k8s cluster 分割したことで作業見積もりのしやすさや CI/CD の時間削減、機能の追加変更に強くなった
have achieved great results ➢ We didn't choose to system replace or big-rewrite ➢ It took a while, but I was able to see and feel the changes ❖ Re-architecture given us a flexible system ➢ The groundwork has been laid for the introduction of advanced technology. ➢ This is passage. To be continued… ❖ We have an ongoing system in place to confront technical debt ➢ An approach from both a technical debt repayment and prevention perspective. 小さな改善を積み重ね、柔軟なシステムを得た。技術的負債と向き合う体制も整備。改善はつづく
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}