Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
cronworkflowを用いた バッチ障害時の運用改善
Search
南條綾乃
March 13, 2023
Technology
680
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
cronworkflowを用いた バッチ障害時の運用改善
南條綾乃
March 13, 2023
More Decks by 南條綾乃
See All by 南條綾乃
Linux初心者がAmazon Linux 2023への移行に奮闘した話
ayanonanjo
1
940
Other Decks in Technology
See All in Technology
ローカルLLMとLINE Botの組み合わせ その3 / LINE DC Generative AI Meetup #8
you
PRO
0
130
Claude Codeとハーネスについて考えてみる
oikon48
18
9.1k
クラウド上のデータ復旧で見落としがちな制約: 医療系 SaaS の BCP 設計から得た教訓
kakehashi
PRO
0
3.2k
AIに「使われる」時代のSaaS戦略 〜既存WebAPIのMCPサーバー化における開発ノウハウ〜
ekispert_api
0
310
AIDLC_ヤフーショッピングの取り組み
lycorptech_jp
PRO
0
600
Terraform共通モジュールをチーム横断で“変えられる”運用へ ― リリースと適用の分離
kekke_n
1
2.5k
脱金融のフューチャー・デザイン / Future Design Beyond Finance
ks91
PRO
0
140
DatabricksにおけるMCPソリューション
taka_aki
1
180
End-to-Endで考える信頼性 — LINEアプリにおける クライアント開発×SRE連携の実践
maruloop
4
3.9k
生成AIの活用/high_school2026
okana2ki
0
120
なぜ私たちのSREプラクティスはなかなか機能しないのか 〜システムより先に組織を見る〜 / Why our SRE practices aren't really working
vtryo
3
3.4k
プロンプト_きのこカンファレンス2026_LT
yurufuwahealer
0
150
Featured
See All Featured
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
260
Done Done
chrislema
186
16k
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
190
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
490
Evolving SEO for Evolving Search Engines
ryanjones
0
240
The Limits of Empathy - UXLibs8
cassininazir
1
410
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
390
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
The Cost Of JavaScript in 2023
addyosmani
55
10k
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
65
56k
Thoughts on Productivity
jonyablonski
76
5.2k
Transcript
cronworkflowを用いた バッチ障害時の運用改善 氏名: 南條綾乃 2023/03/13 Kubernetes Novice Tokyo #23
自己紹介 名前: 南條綾乃 会社: 株式会社NTTデータ(2021年入社) 業務: バックエンド開発 実家で飼っている柴犬と亀
バッチの良い運用設計とは?
良い運用設計とは 回復性 可観測性 管理力 処理の進行状態を把握できるか 処理の完了状態を把握できるか 障害を検知し適切な行動を選択できるか 容易に再実行が可能か 参考: https://www.yamarkz.com/blog/implementation-practices-for-batch-processing
CNCF Cloud Native Definition v1.0より項目抜粋 実行コストが少ないか
しかし、これまでは... 回復性 可観測性 管理力 処理の進行状態を把握できるか 処理の完了状態を把握できるか 障害を検知し適切な行動を選択できるか 容易に再実行が可能か 参考: https://www.yamarkz.com/blog/implementation-practices-for-batch-processing
CNCF Cloud Native Definition v1.0より項目抜粋 実行コストが少ないか APを修正して から実行 手動で 再実行 手動で 再実行
cronworkflowを用いて "バッチの良い運用設計"を 目指したので、その取り組みにつ いてLTさせていただきます!
cronworkflowって何?
cronworkflowとは Kubernetes上で実行されることを想定したワークフローエンジン である、argo workflowの一種 KubernetesのCRD(Custom Resource Definition)として実行 cronjobと同じ設定を使用し実行可能
何を実施したの?
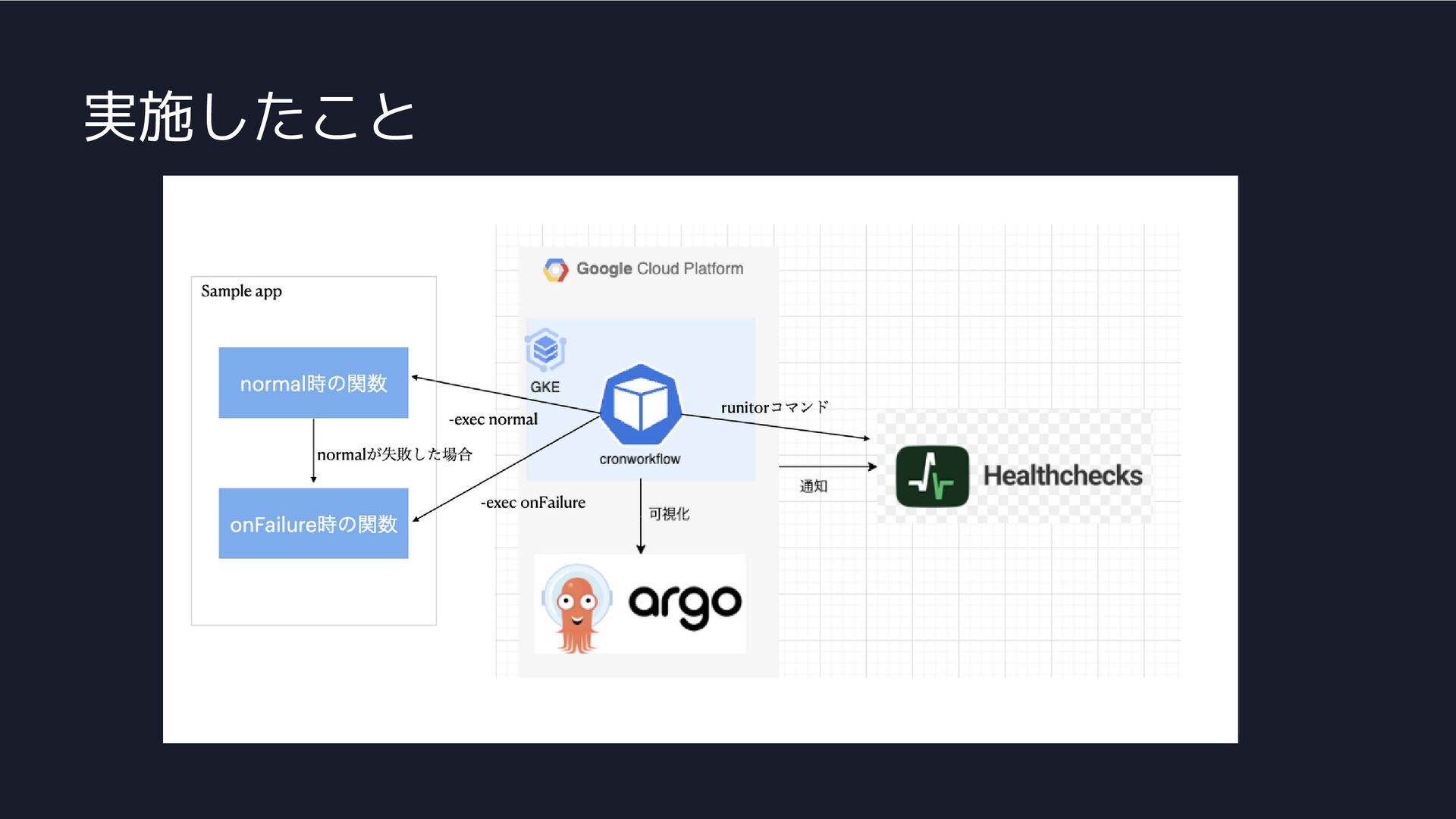
実施したこと ・障害時に動かす処理をコマンドライン引数で管理 ・障害時にバッチを自動実行
実施したこと
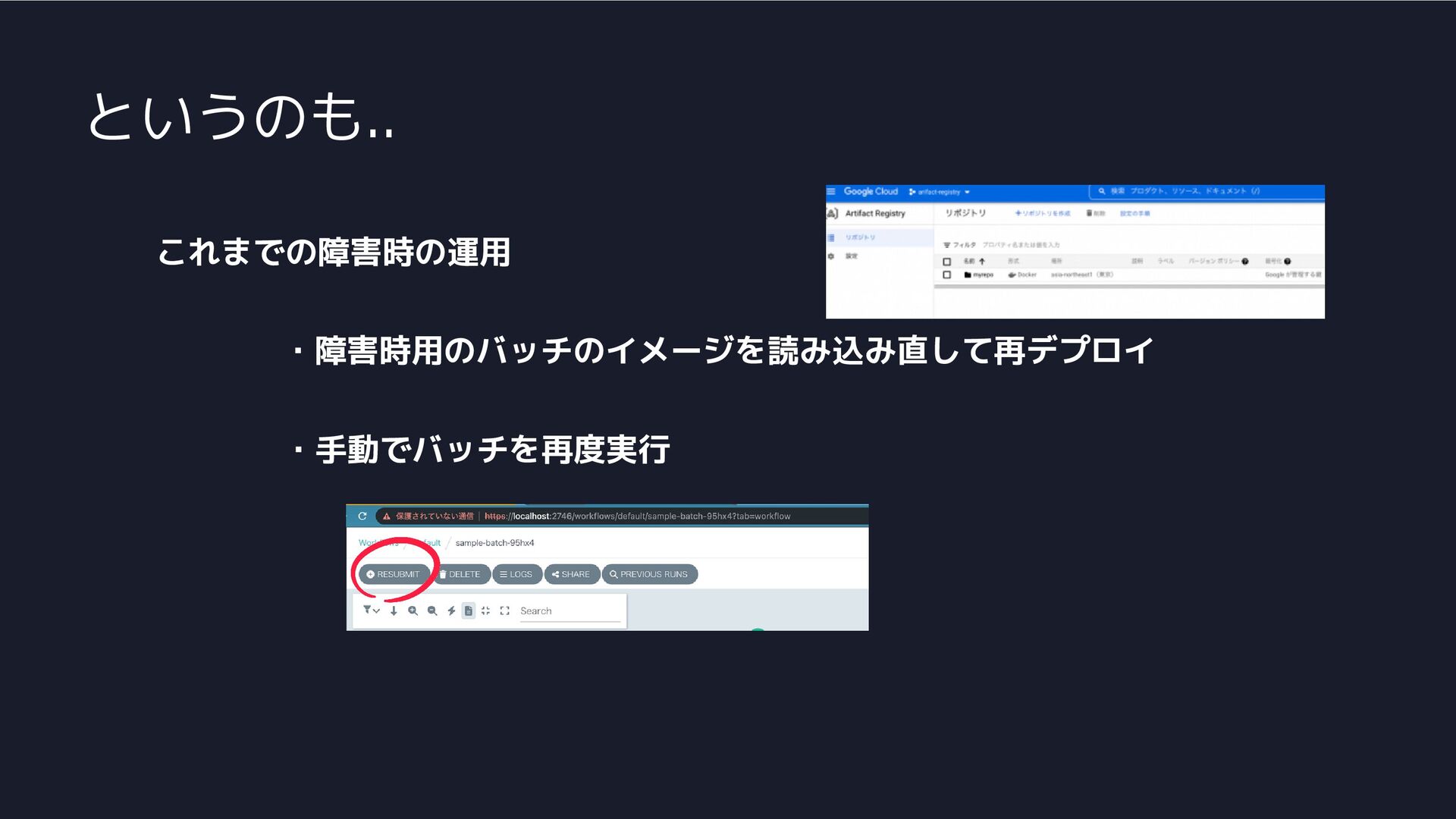
というのも.. これまでの障害時の運用 ・手動でバッチを再度実行 ・障害時用のバッチのイメージを読み込み直して再デプロイ
管理コストが少ないか これまでの問題の解決 回復性 可観測性 管理力 処理の進行状態を把握できるか 処理の完了状態を把握できるか 障害を検知し適切な行動を選択できるか 容易に再実行が可能か 参考:
https://www.yamarkz.com/blog/implementation-practices-for-batch-processing CNCF Cloud Native Definition v1.0より項目抜粋 APを修正 しない仕組み 自動で 再実行 手動で 再実行
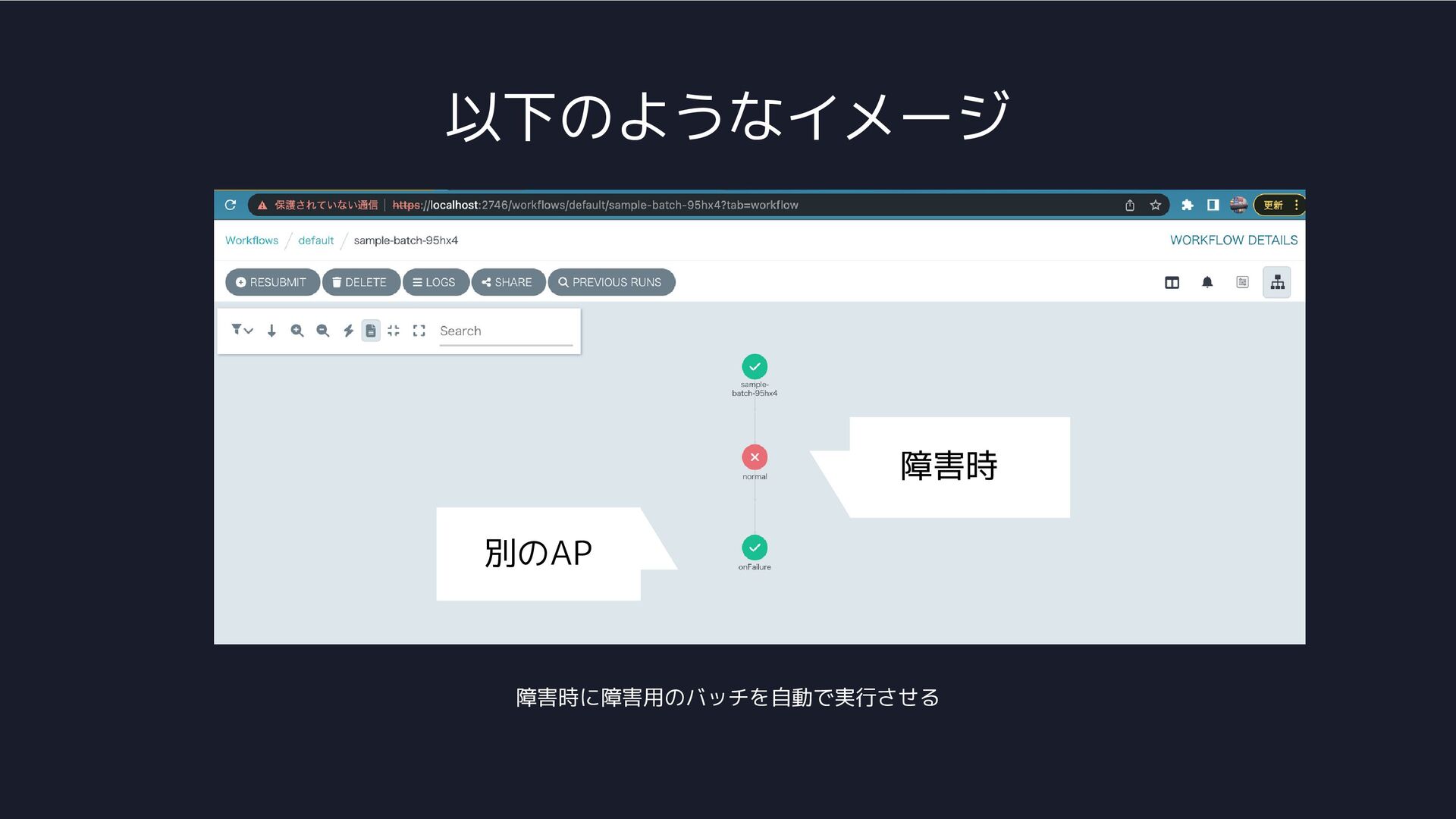
以下のようなイメージ 障害時に障害用のバッチを自動で実行させる 障害時 別のAP
マニフェストファイル どんなん?
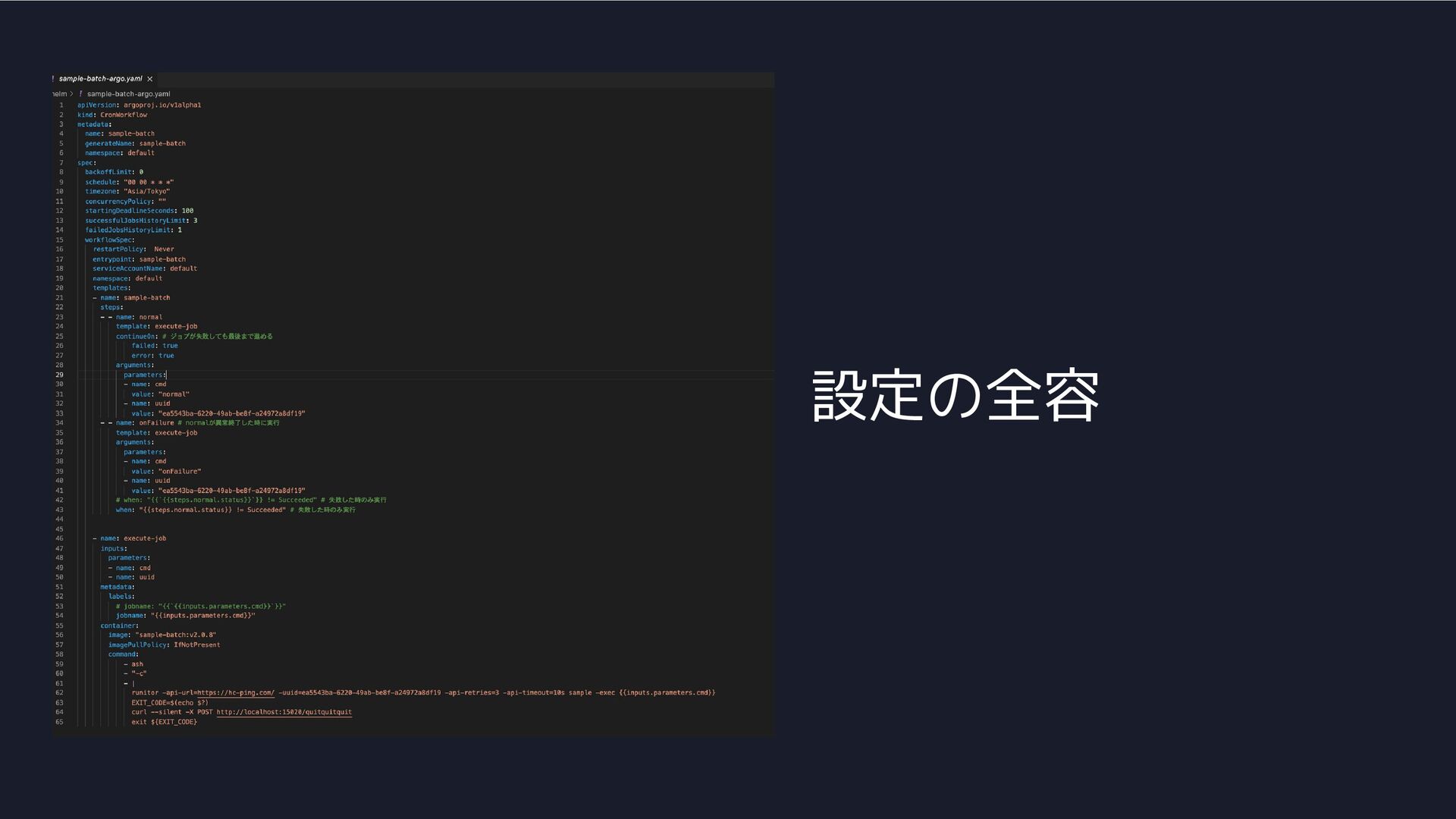
設定の全容
障害発生時 通常時 helmfileで設定時は、 コメントアウトのように記載
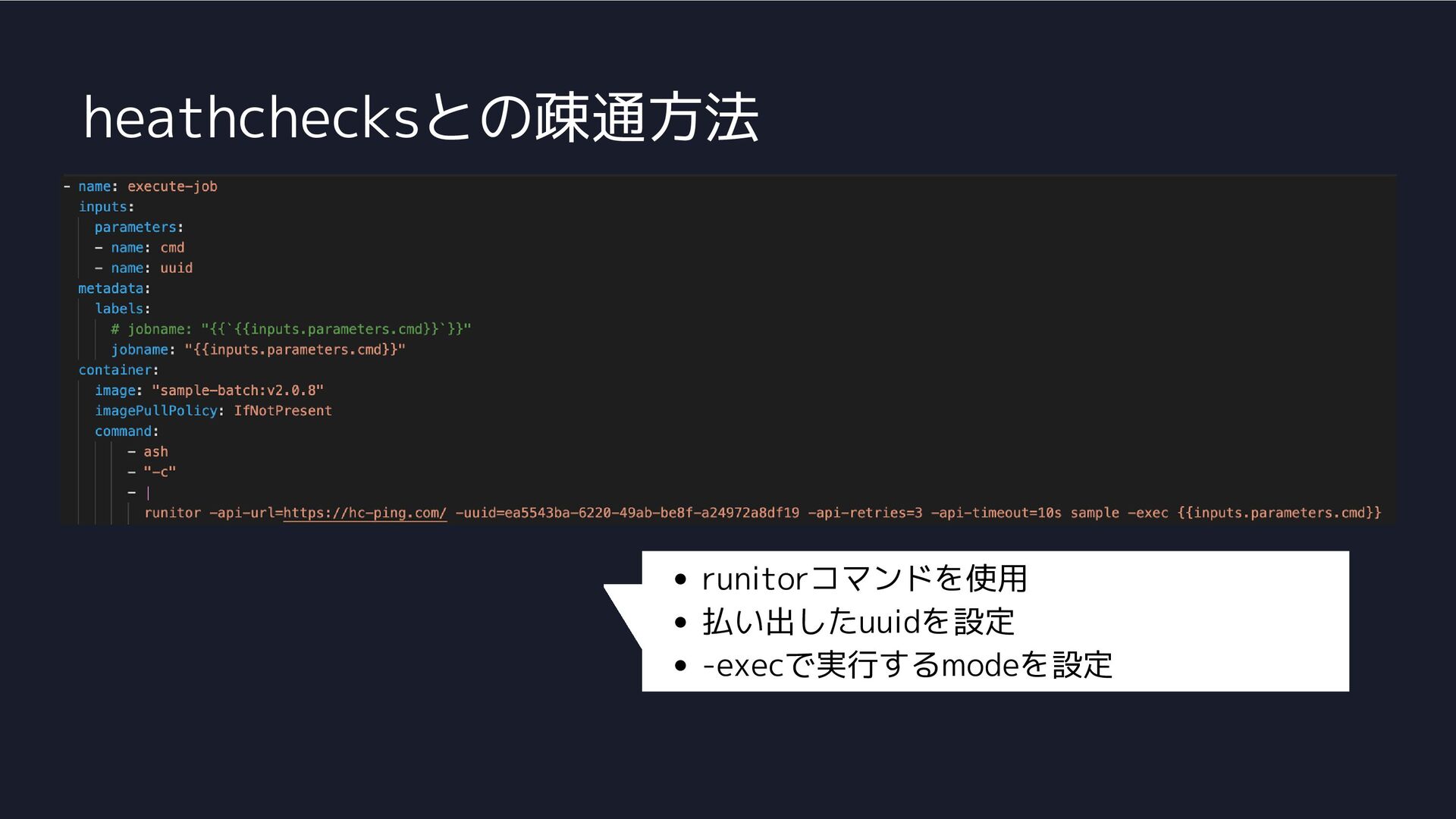
コマンドライン引数での 処理の管理って?
コマンドライン引数での処理の管理 execを定義 (defaultは空) ここで、モードにより 呼び出したいメソッド を変える
ここまでで 回復性、管理力は解決!
実行コストが少ないか では.. 回復性 可観測性 管理力 処理の進行状態を把握できるか 処理の完了状態を把握できるか 障害を検知し適切な行動を選択できるか 容易に再実行が可能か 参考:
https://www.yamarkz.com/blog/implementation-practices-for-batch-processing CNCF Cloud Native Definition v1.0より項目抜粋 APを修正 しない仕組み 自動で 再実行 手動で 再実行
可観測性は どうやって解決してるの?
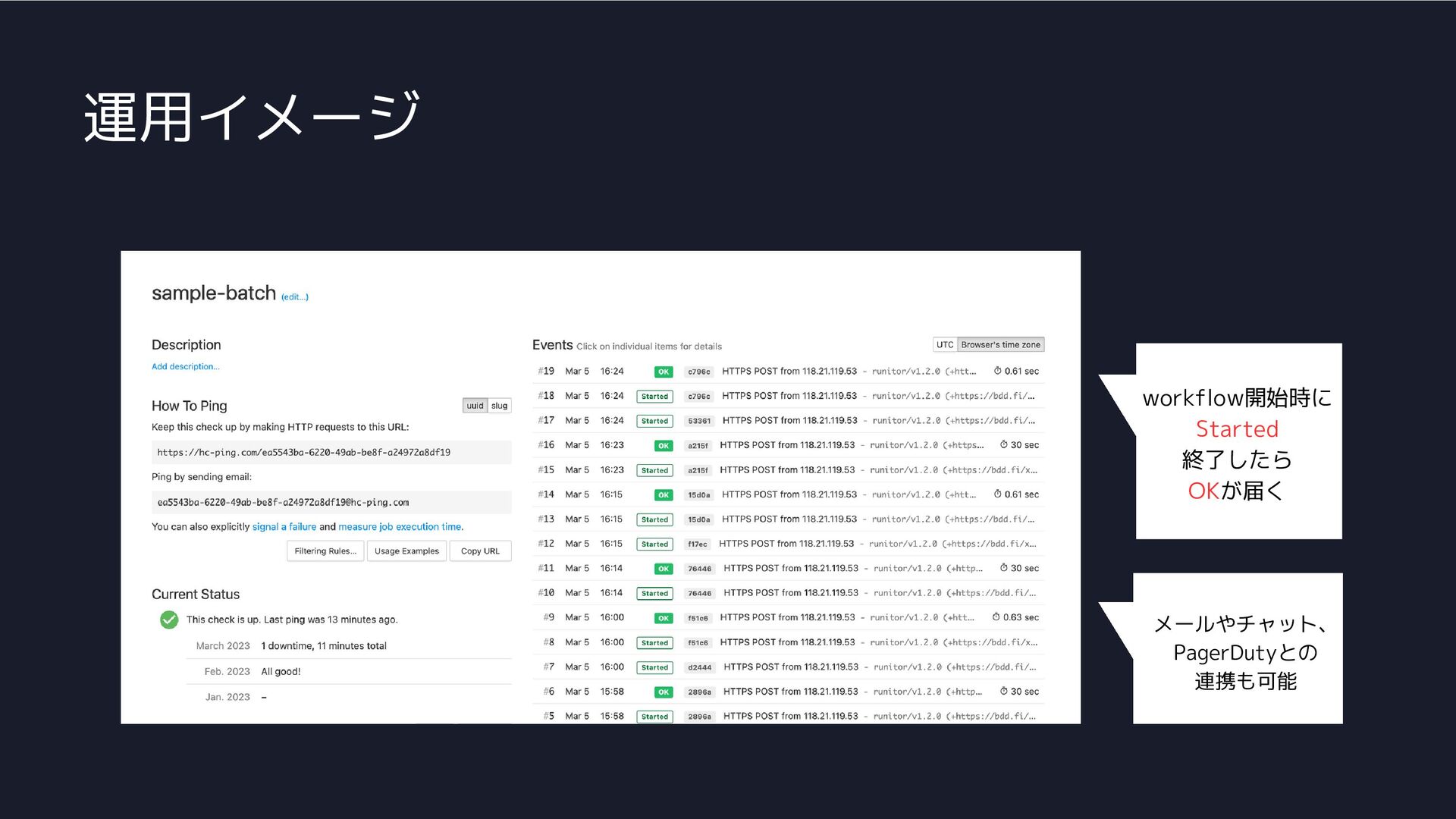
Healthchecksで解決!
Healthchecksとは ジョブの「起動状態」を監視するサービス ※実行状態は監視しない(AP内部でエラーetc) 予定していた時刻にジョブが正常起動したか ジョブの想定実行時間よりも実行時間が長くなっていないか
運用イメージ workflow開始時に Started 終了したら OKが届く メールやチャット、 PagerDutyとの 連携も可能
どうやって使うの?
heathchecksとの疎通方法 runitorコマンドを使用 払い出したuuidを設定 -execで実行するmodeを設定
デモします!
デモ ①通常実行 ②通常実行→障害発生→障害時のAP実行
デモ
実行コストが少ないか まとめ 回復性 可観測性 管理力 処理の進行状態を把握できるか 処理の完了状態を把握できるか 障害を検知し適切な行動を選択できるか 容易に再実行が可能か 参考:
https://www.yamarkz.com/blog/implementation-practices-for-batch-processing CNCF Cloud Native Definition v1.0より項目抜粋 APを修正 しない仕組み 自動で 再実行
ご静聴 ありがとうございました!
リマインド機能について 企業 エンドユーザー リンクを発行 リンクで登録などを実施 リンクの期限1日前にリマインドメール 参考:
詳細 リマインド対象のリンクを DBから取得 該当するリンク所有者に 1件ずつメールを送信 参考:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}