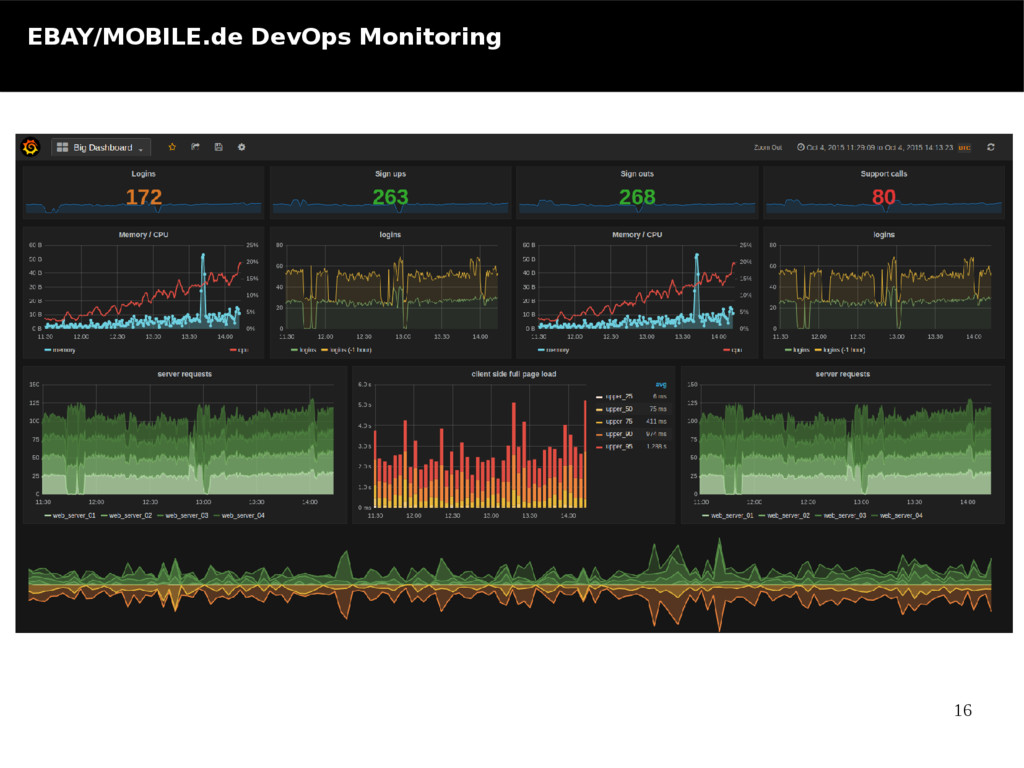
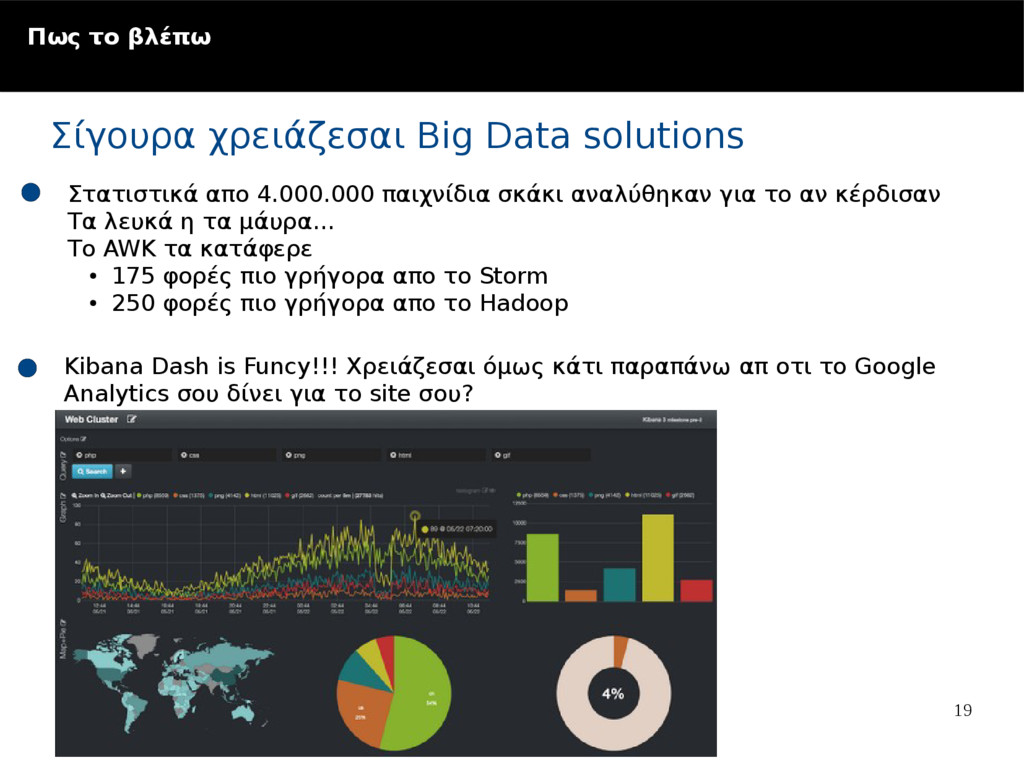
Sub Topic Tο πρόβλημα To mobile.de χρησημοποιεί ενα cluster απο εκατοντάδες servers που τρέχουν Διάφορες εφαρμογές όπως mongoDB, RabitMQ, Elasticsearch, Squid. Χρειάζονταν ένα κεντρικό σημείο παρακολούθησης όλων αυτών για την σωστή Αναπτυξη του cluster αλλα και την ευρεση ανωμαλιών Οι πιθανές λύσεις • Monit • Nagios • monitis H τελική επιλογή TICK STACK • Nagios – Ειχε χρόνια στο χώρο και εχει φτάσει στο pick του, Δεν ξεχωρίζει της κατηγορίες των εγγραφών, no aggregations, scalability problems • TICK STACK – μπορει να πάρει δεδομένα απο οποιαδήποτε πηγή υπάρχει εκει έξω με ρυθμό 100,000/sec/instance, Taging/Fields on records, aggregations, Διαφορετικές μηχανές παραγωγής γραφιμάτων απο τα δεδομένα (graphana, chronograf, graphite), έξυπνος μηχανισμός ειδοποιήσεων με triggers, REST HTTP API for custom εφαρμογές, SQL LIKE QL, realtime response <100ms
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}