three clusters go live (DAL, AMS, SNG) • 2014 — Dedicated development team • 2014 — Launch 11 clusters in new datacenters • 2015 — Launch 5 clusters in new DCs • 2015 — Product integrations with IBM Bluemix • 2016 — Launch 3 clusters in new DCs (and expand an existing cluster into multiple DCs)
each cluster • Two node types • Proxy • Data - account, container, object services • Load balancer • FreeBSD with ZFS ⚠ Do not attempt. • No centralized logs • No log analysis tools
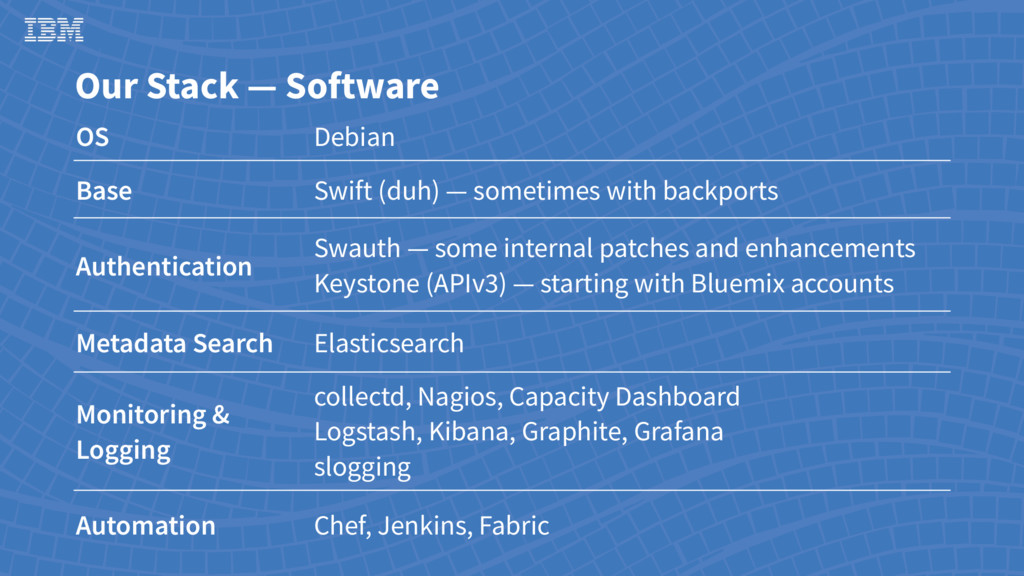
Up to hundreds of nodes per cluster • Three node types • Proxy • Meta - account and container services • Data - object services • Load balancer cluster • Debian Linux • Centralized and searchable logs • Analytics via Spark and Hadoop
cores (24-32 HT cores) • 128GB RAM for proxies • 256GB RAM for data nodes • 10Gbps NICs (separate API vs. storage/replication networks) • 3 - 4 TB disks • Controller card • 2 disks for OS (RAID1) • 1 disk for OS hotswap • 4 disks for SSD caching • 29 disks for data storage • Usually expand by ½-row or a full row at a time
• Never launch something new without test/deploy automation • Must work across all environments (dev, QA, UAT/staging, prod) • Automation needs tests and metrics, too — it is code! • Functional testing should be an automated part of every deploy • Remember your orchestration (knowledge of Swift zones)
put into place • Very obvious stuff: • Space and IOPS, errors from SMART/XFS/kernel/controller, etc. • HTTP response code aggregates, latency aggregates by verb, etc. • Swift metrics: • If nothing else, async pendings • Replicator failures and partitions/sec rates • Replicator last completion timestamp vs. ring push timestamp
emit ops metrics • New features benefit from emitting usage metrics • Don’t forget debug-level log messages • Automatic checks for precipitating conditions that lead to failures (not just for the error log lines that result from them afterwards)
(and keep them small when possible) • Coordinate rebalances around node/cluster maintenance • Don’t let IOPS levels grow too high before expanding capacity • Customer IOPS vs. Replicator & Auditor IOPS — know your limits
the smallest you can get away with) • Using swauth? Use an SSD storage policy for AUTH_.auth containers • Namespace any custom API additions (and be consistent) • When possible, ask community about new middleware thoughts • Upstream is important! Stay involved and give back when possible
{kind=link}
{kind=link}
![2012: When things were [mostly] simpler… • 7-10 nodes in](https://files.speakerdeck.com/presentations/dd32b0ebb0974e23bed40737b33baeb1/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}