and L. Zhang, “Tare: Type-aware neural program repair,” 2023. [Online]. Available: https://ezproxy.library.dal.ca/login?url=https://www.proquest.com/ conference-papers-proceedings/tare-type-aware-neural-program-repair/ docview/2837138632/se-2 [2] K. Kim, M. Kim, and E. Lee, “Systematic analysis of defect-specific code abstraction for neural program repair,” 2022. [Online]. Available: https://ezproxy.library.dal.ca/ login?url=https://www.proquest.com/conference-papers-proceedings/ systematic-analysis-defect-specific-code/docview/2777587963/se-2 [3] S. Bhatt, “Reinforcement learning 101,” Medium, https://towardsdatascience.com/reinforcement-learning-101-e24b50e1d292 (accessed Dec. 11, 2023). [4] T. Lutellier, H. V. Pham, L. Pang, Y. Li, M. Wei, and L. Tan, “Coconut: combining context-aware neural translation models using ensemble for program repair,” in Proceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis. Virtual Event USA: ACM, Jul. 2020, p. 101–114. [Online]. Available: https://dl.acm.org/doi/10.1145/3395363.3397369 [5] M. Kim, Y. Kim, H. Jeong, J. Heo, S. Kim, H. Chung, and E. Lee, “An empirical study of deep transfer learning-based program repair for kotlin projects,” in Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. Singapore Singapore: ACM, Nov. 2022, p. 1441–1452. [Online]. Available: https://dl.acm.org/doi/10.1145/3540250.3558967 [6] C. S. Xia and L. Zhang, “Conversational automated program repair,” no. arXiv:2301.13246, Jan. 2023, arXiv:2301.13246 [cs]. [Online]. Available: http://arxiv.org/abs/2301.13246 [7] R. Paul, M. M. Hossain, M. L. Siddiq, M. Hasan, A. Iqbal, and J. C. S. Santos, “Enhancing automated program repair through fine-tuning and prompt engineering,” no. arXiv:2304.07840, Jul. 2023, arXiv:2304.07840 [cs]. [Online]. Available: http://arxiv.org/abs/2304.07840 Callum MacNeil 28
{kind=link}
{kind=link}
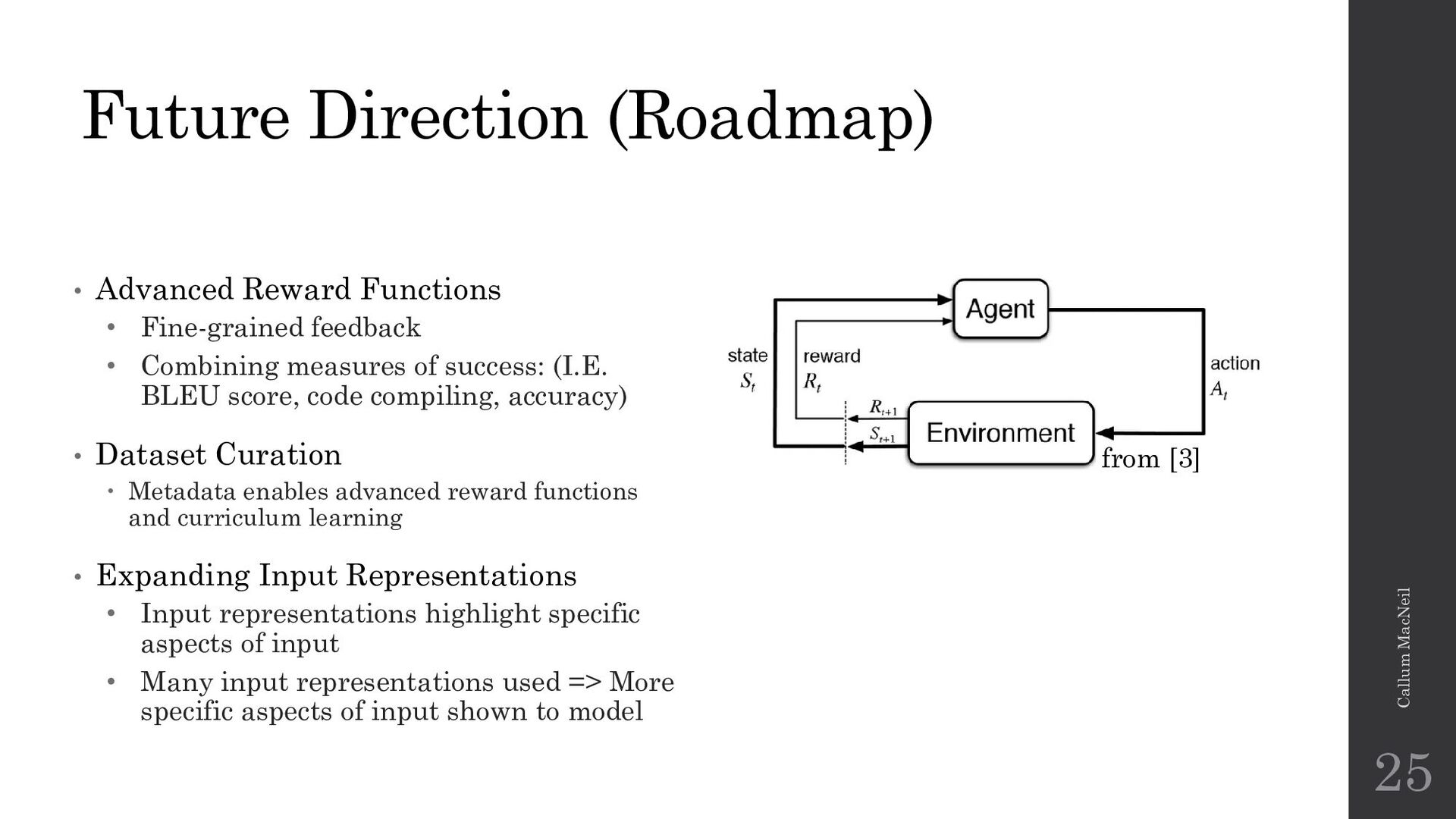
{kind=link}
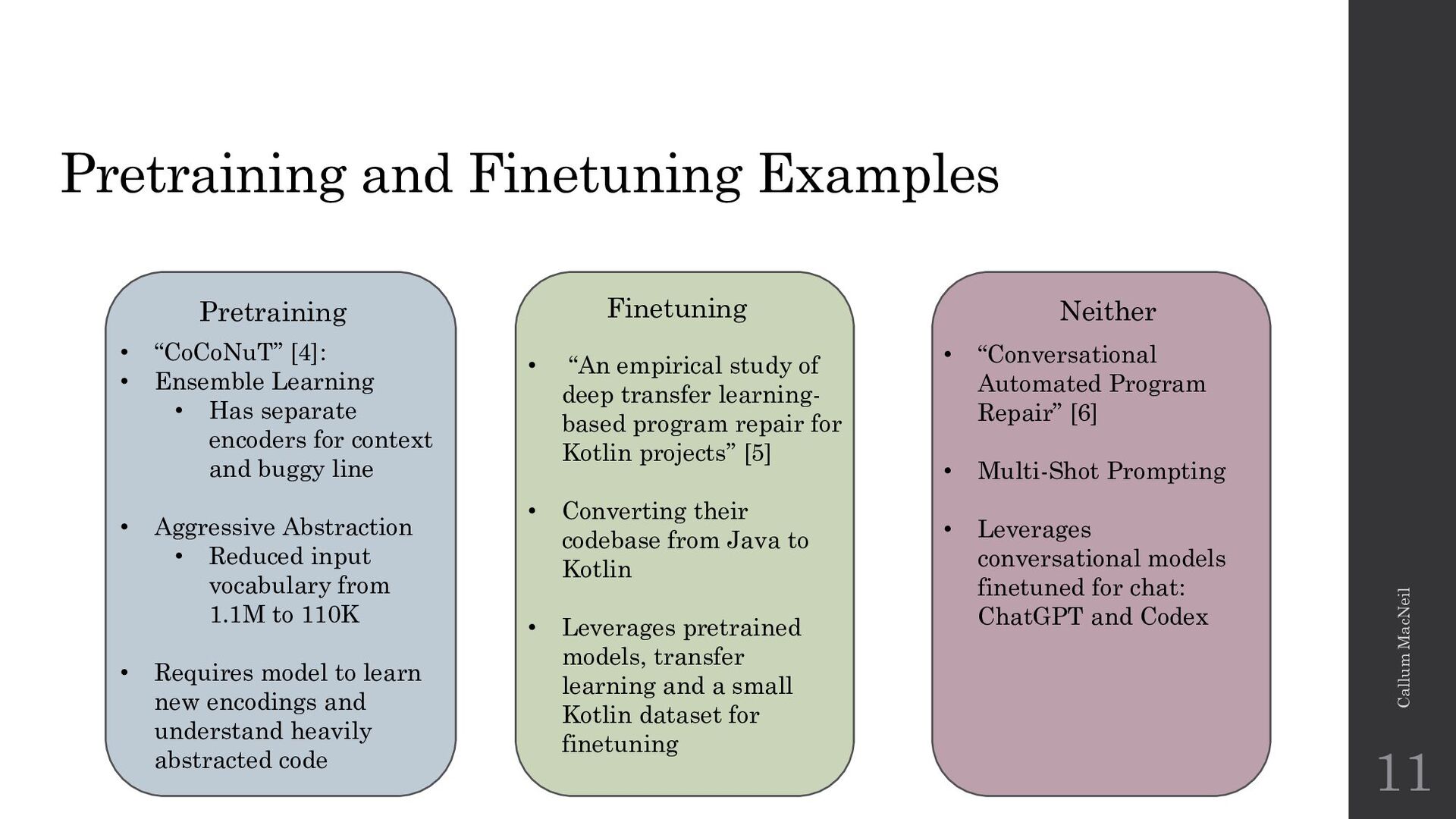
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
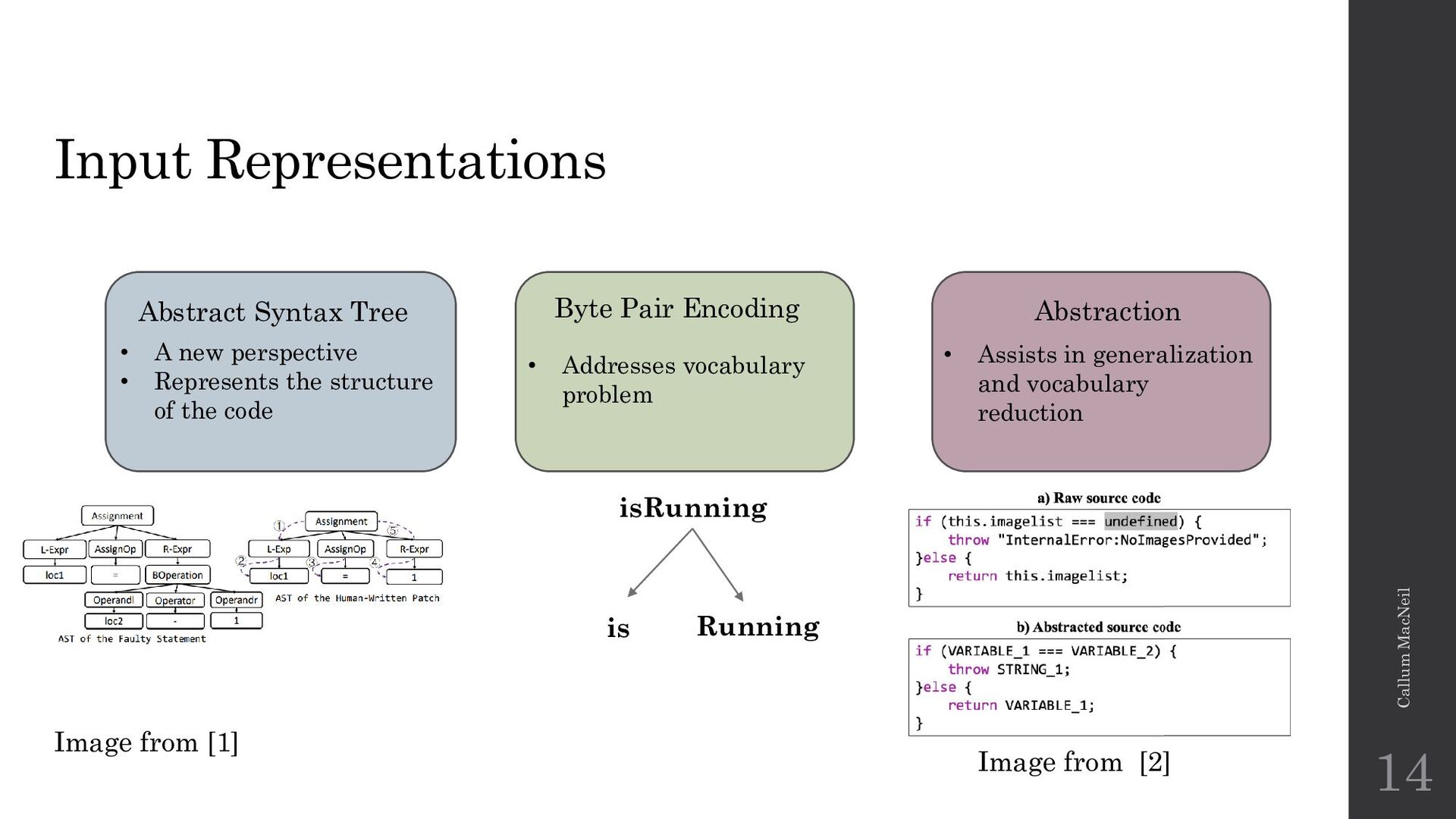{kind=link}
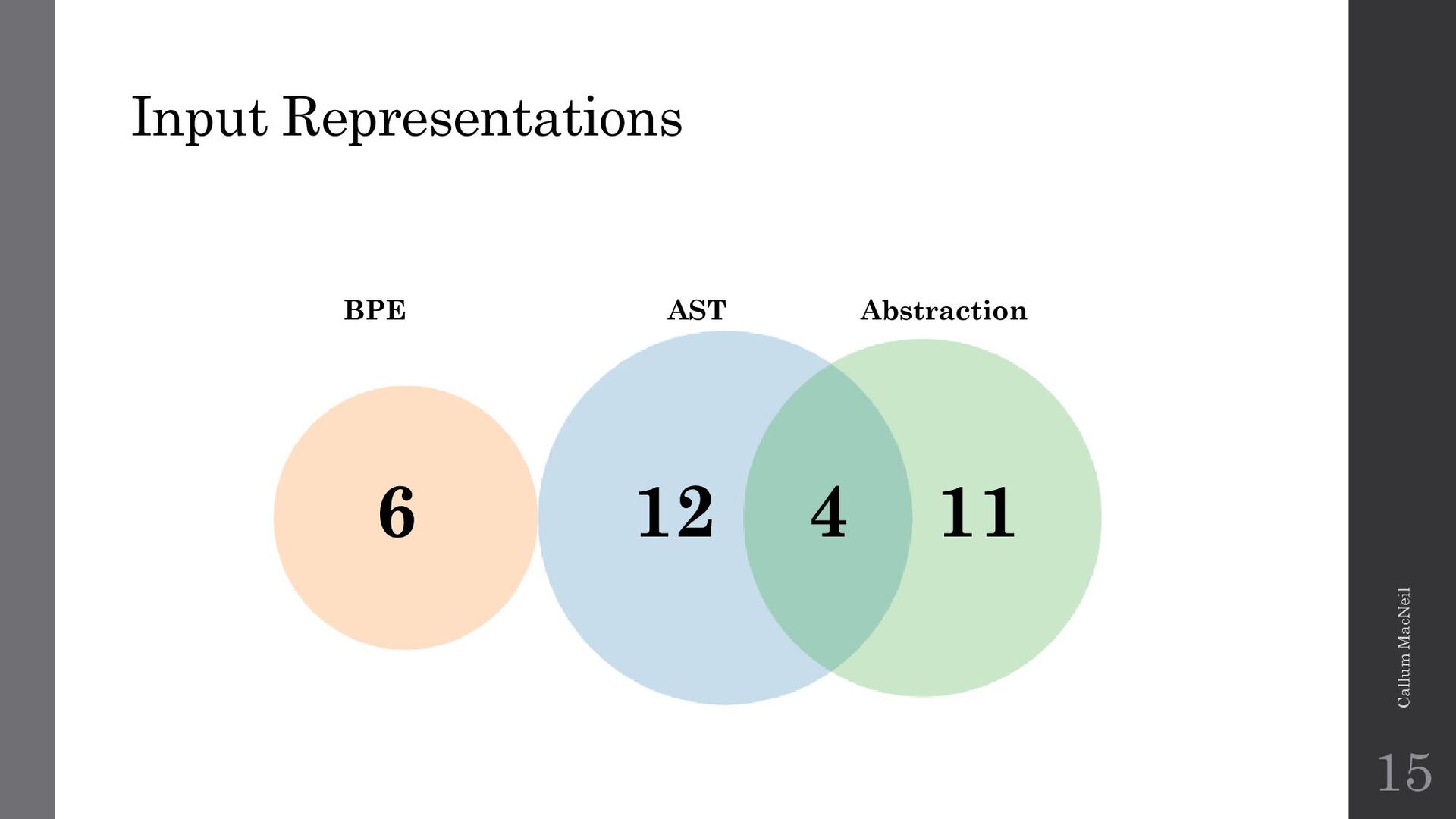{kind=link}
{kind=link}
{kind=link}
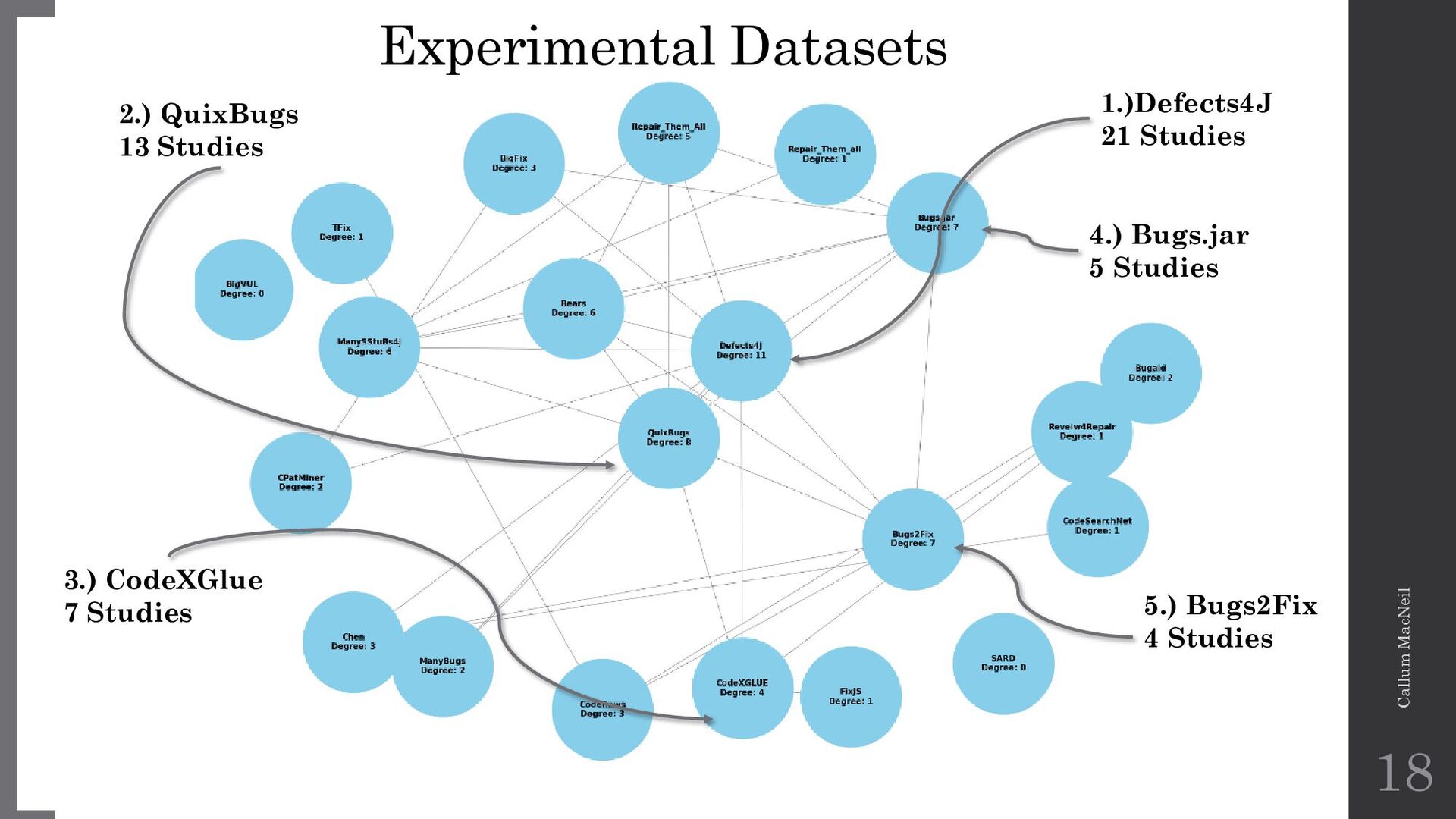{kind=link}
{kind=link}
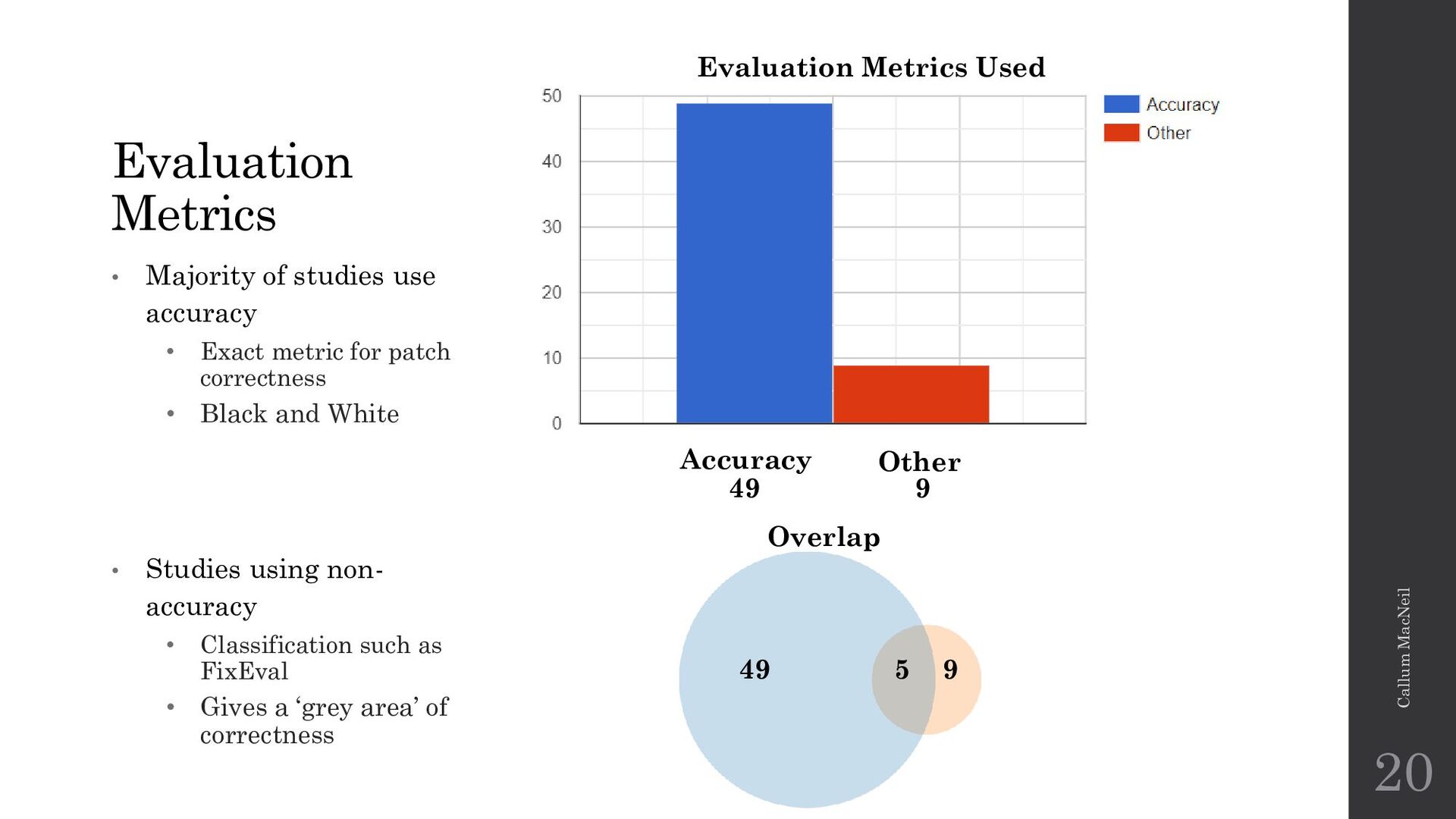{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![References [1] Q. Zhu, Z. Sun, W. Zhang, Y. Xiong,](https://files.speakerdeck.com/presentations/476a0e0d331941cf9a194ad051c7696b/slide_27.jpg){kind=link}
{kind=link}