In cloud-native environments and microservices applications world, Prometheus has become the standard for monitoring. Even Docker or Kubernetes expose native metrics. This talk would cover why, and what differentiates it from more traditional approaches. How can it be used to monitor both systems and applications, and would also show a real case on how to develop Prometheus-native applications. We will also see how to integrate Alertmanager with other alert systems or incident management systems already deployed.
About: Beatriz Martínez, Cloud engineer - IBM
Beatriz Martínez works at IBM’s Architecture and Innovation department, mainly focus on enterprise-grade cloud environments. Passionate about technology and innovation, she is an insatiable learner who loves getting involved with open-source communities.
{kind=link}
{kind=link}
{kind=link}
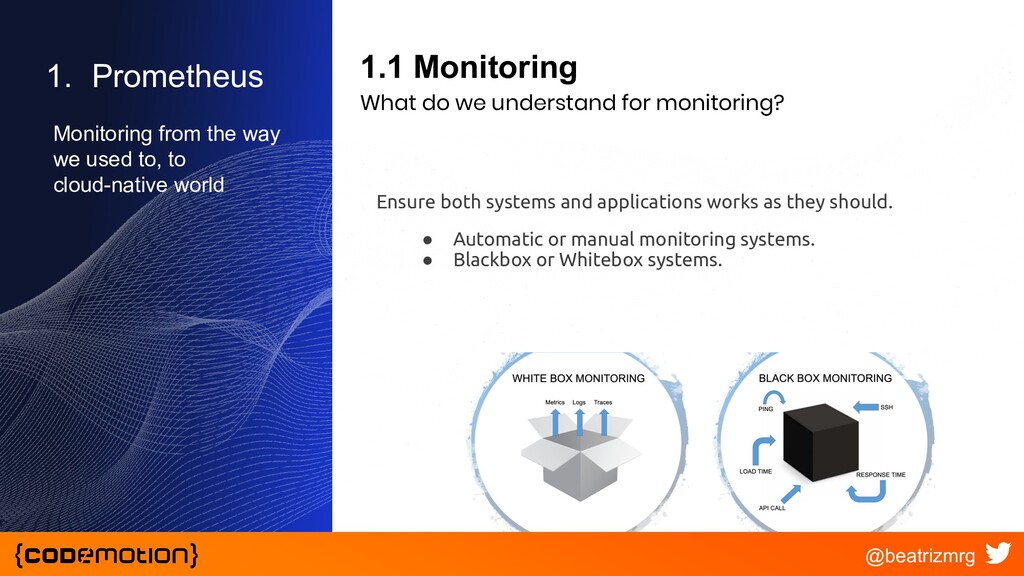{kind=link}
{kind=link}
{kind=link}
{kind=link}
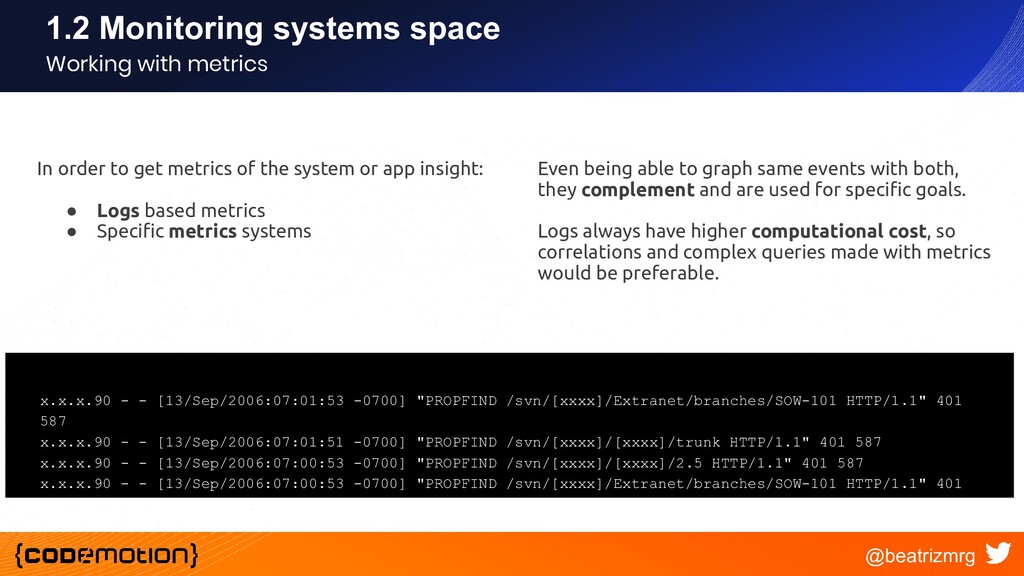{kind=link}
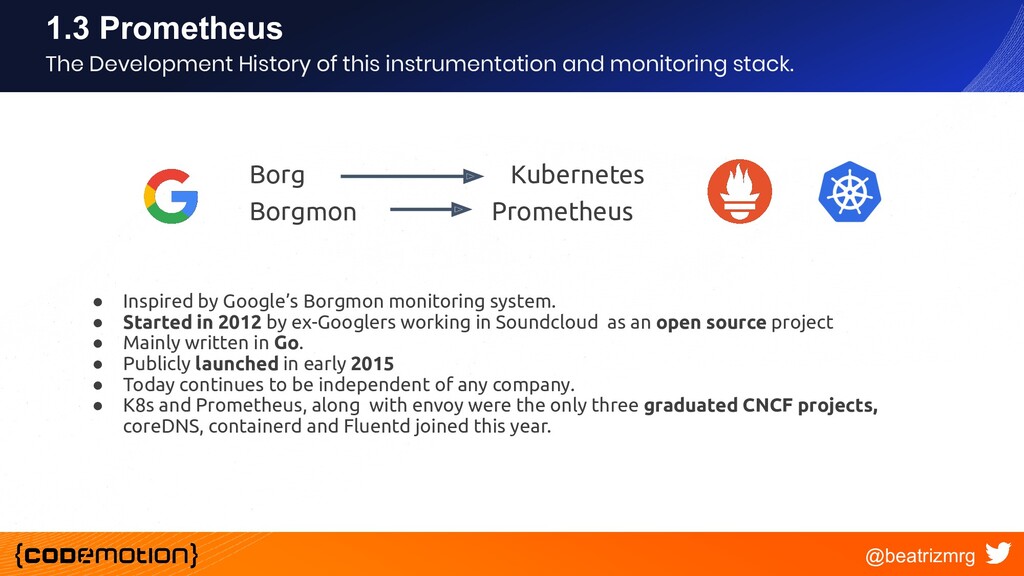{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
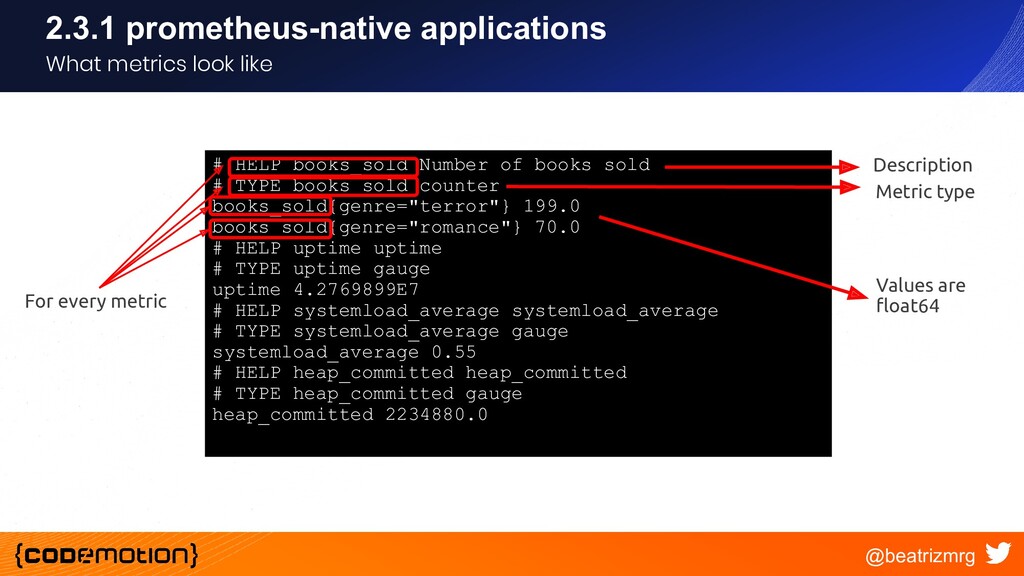{kind=link}
{kind=link}
{kind=link}
{kind=link}
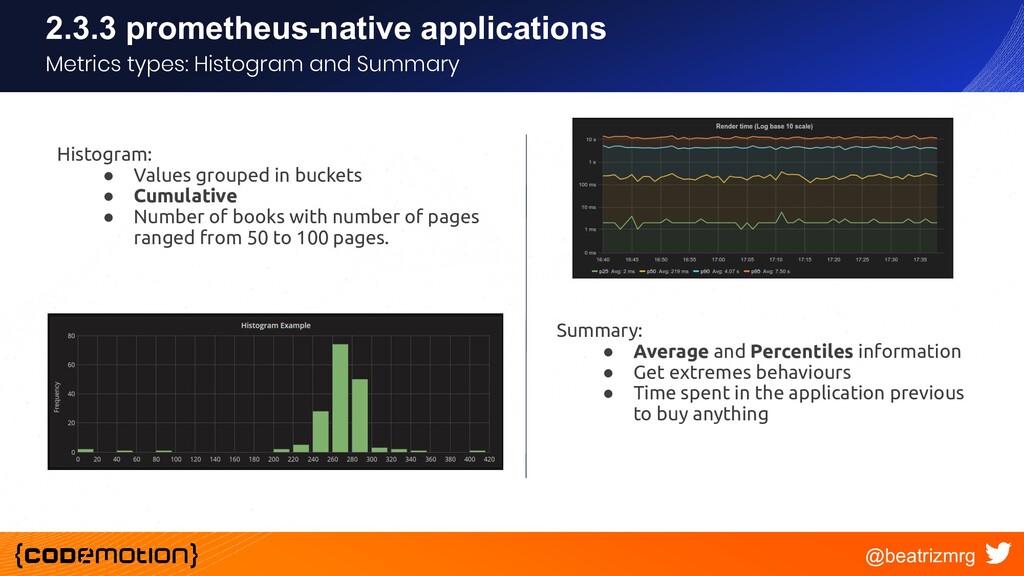{kind=link}
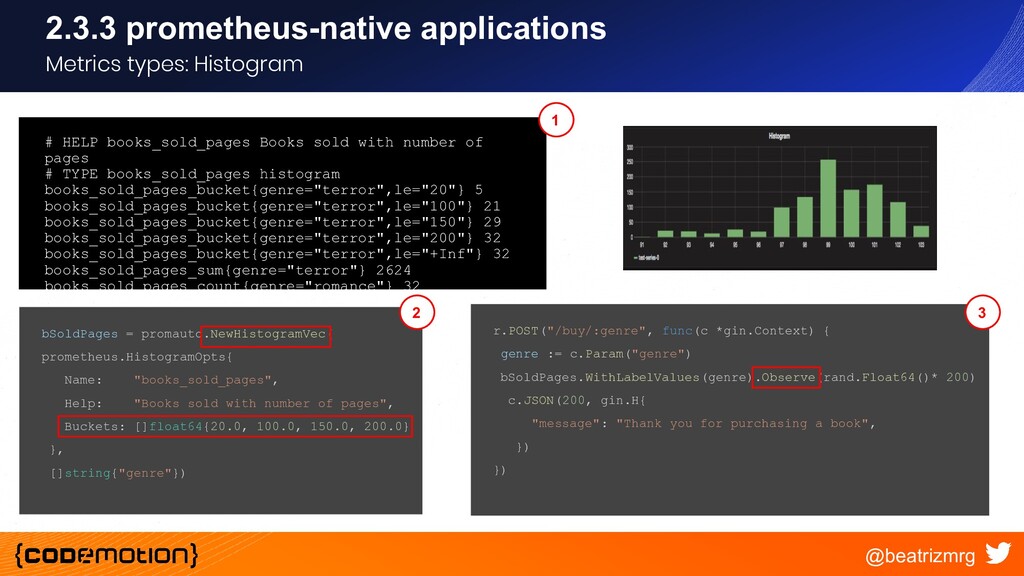{kind=link}
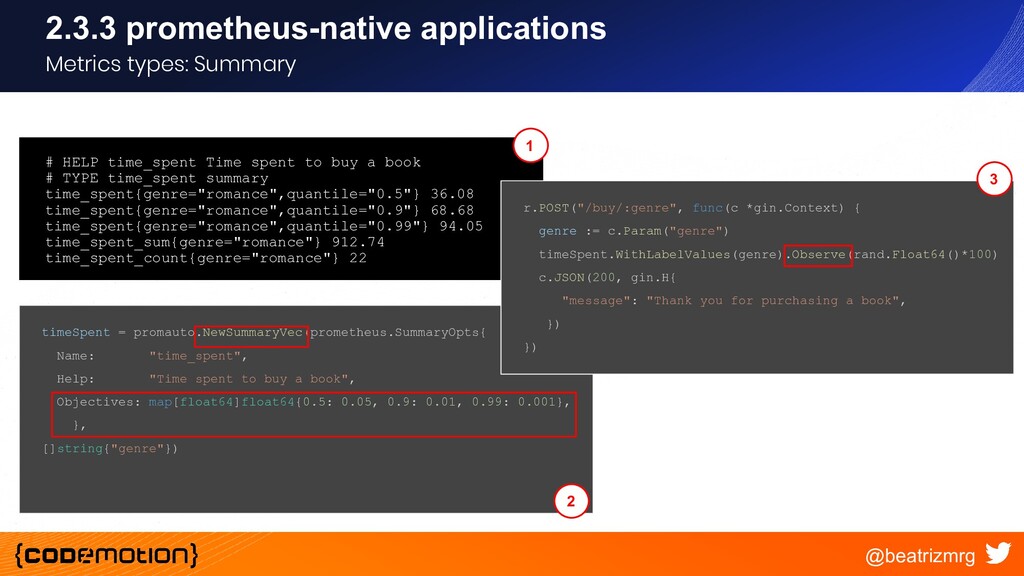{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}