Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AIのAIによるAIのための出力評価と改善
Search
たまねぎ
June 25, 2025
Technology
970
3
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AIのAIによるAIのための出力評価と改善
たまねぎ
June 25, 2025
More Decks by たまねぎ
See All by たまねぎ
[FlutterKaigi2024] Effective Form 〜Flutterによる複雑なフォーム開発の実践〜
chocoyama
1
13k
iOSDC2023:聴いて話すiOS 現実世界の「音」との連携
chocoyama
1
420
ハードウェア対応のリアル.pdf
chocoyama
0
130
20分でわかる!速習resultBuilder(iOSDC 2022)
chocoyama
7
4k
SwiftUIっぽくした話
chocoyama
1
750
SwiftUIとGraphQLでプロダクトの継続的な破壊に立ち向かう
chocoyama
6
2.8k
Other Decks in Technology
See All in Technology
実装だけじゃない! CCA-F取得エンジニアが教えるClaude Code開発プロセス活用術
diggymo
2
640
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.4k
AI Agent SaaS を支える自社仮想化基盤への挑戦と実運用 / ai-agent-saas-virtualization
flatt_security
2
3.8k
SRE本の知られざる名シーン / The Hidden Gems of Google SRE Book
nari_ex
1
370
Kaggleで成長するために意識したこと
prgckwb
2
310
Road to SRE NEXTの今までとこれから
hiroyaonoe
0
310
ゼロをイチにする仕事が終わったあと
smasato
0
340
アカウントが増えてからでは遅い? ~ マルチアカウント統制の勘所 ~
kenichinakamura
0
220
【Claude Code】鹿野さんに聞く 私の推しの並行開発環境 大公開 / claude-code-parallel-2026-07-15
tonkotsuboy_com
10
6.8k
個人開発で育てる「大規模設計の苗床」 - AI時代の1人開発から始める業務への知識接続 / The Seedbed for Large-Scale Design - From AI-Era Solo Projects to Professional Knowledge
bitkey
PRO
0
150
Control Planeで育てるBtoB SaaSの認証基盤 - SRE NEXT 2026
pokohide
1
2.3k
プロダクトだけじゃない、社内プロセスにおける自動化・省力化ノススメ
kakehashi
PRO
1
3.6k
Featured
See All Featured
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
Highjacked: Video Game Concept Design
rkendrick25
PRO
1
410
How STYLIGHT went responsive
nonsquared
100
6.2k
Claude Code のすすめ
schroneko
67
230k
Accessibility Awareness
sabderemane
1
150
Mind Mapping
helmedeiros
PRO
1
280
How to build a perfect <img>
jonoalderson
1
5.8k
Exploring anti-patterns in Rails
aemeredith
3
440
A Tale of Four Properties
chriscoyier
163
24k
Docker and Python
trallard
47
3.9k
Sharpening the Axe: The Primacy of Toolmaking
bcantrill
46
2.9k
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
Transcript
AIのAIによるAIのための出力評価と改善 AIの出力の質をあげる!チームの集合知を注入する方法
自己紹介 @_chocoyama(たまねぎ) 株式会社LayerX バクラク申請・経費精算チーム Flutterでモバイルアプリ作ってます よく使っているAI Coding Tools Claude Code,
Cursor 最近の悩み 老眼、鼻炎、知覚過敏と顔面周りのおぢ化が急速に進ん でいる © LayerX Inc. 2
「AIの出力の質をあげる!」 そもそも「質が上がった」ということをどう判断していますか?
AIの出力の質が上がったかどうか © LayerX Inc. 「ルールを追加したら、なんかいい感じに動いてそう」 「とりあえずルール見てくれてはいるから、なんかいい感じにやってくれてそう」 4
AIの出力の質が上がったかどうか →「なんかいい感じになってる」を脱しきれない もう少し主観的ではない形で評価したい! ※ 今日話す内容 x 完璧にうまくいっている o 試行錯誤しながら前に進んでいる ©
LayerX Inc. 「ルールを追加したら、なんかいい感じに動いてそう」 「とりあえずルール見てくれてはいるから、なんかいい感じにやってくれてそう」 5
弊チームのAI Codingの状況 © LayerX Inc. 1月ごろからCursor活用開始 ちょうどmdcファイルが使えるようになったぐらいのタイミング 元々活用していたTechDocumentsをそのままルールとしてimport なんとなくプロジェクトの文脈を理解してくれそう!という状態になる 一定レベルを超えない感覚があり、DesignDocやADRを一通りimportしてみるが、まぁまぁ...という感じ
Specっぽいのを入れてみたりしてみるが、良い感じにはならず... 6
改善したい! Tryしてみた
なんとなくの対策1:プロンプトの改善 © LayerX Inc. ルールの改善ではないため、根本的な基盤に対しては何も変化がない 個々の実装者のプロンプト力にも依存しており、再現性がない 8
なんとなくの対策2:ルールの追加や改善 © LayerX Inc. 足りてなさそうなルールの追加 ちゃんとワークしているのかよくわからない 「追加したルール見てくれてるから多分良さそう」から脱しきれない ルール設定のベストプラクティスへの準拠やAIによるルール改善を試す 対応内容によっては、明らかにアウトプット品質が低下 低下しなかったとしても、何が変わったのかイマイチわからない
9
なんとなくの対策3:AI Coding Agentの変更 © LayerX Inc. 「Claude Code使ってるとルールそんなに整備しなくてもいい感じだよ」 ルールの呪縛から逃れられるのであれば、それが一番楽 Cursor,
Cline, Roo Code → Claude Codeに切り替え 確かに良くなった感じがするが、うまくいかないこともまだまだ多い Flutter/Dartは弱い?プロジェクトが複雑すぎる? 10
そもそもルールがワークしてるか 把握できていない
何か対応を入れようとしてみても... その対応を入れたことで、どういった変化が 出るかがいまいち見えない 変わらないならまだしも、出力を悪化させる のは避けたい気持ちも生まれる 積極的にルールいじる動きになれない © LayerX Inc. 12
計測してみよう
どう計測するか LLMのアウトプットってシステマチックに評価できるもの...? © LayerX Inc. x「モデルの性能」自体を評価するような計測 o 実ユースケースに近い、アウトプットされたコードを評価するような計測 実行のたびに大きく結果が変わる 結果はテキストデータになるため、評価はある程度定性的に判断するしかない
14
世のプロダクトはどうやって評価している? © LayerX Inc. LangSmith がそれに近いアプローチをしている ※ LangSmith: LLMアプリケーションを構築するためのプラットフォーム 以下の組み合わせを構成し、LLMのアウトプットを評価
Datasets:評価対象となるもの(何を検証するか) Evaluators:出力を評価する関数(どう採点するか) Human:人が採点 Heuristic:ルールベースで採点 LLM-as-judge:LLMが採点 Pairwise:バージョンを比較して判定 15
エージェントに対する評価の方法 © LayerX Inc. Final Response:最終的なレスポンスだけを評価する ブラックボックス的にテキストレスポンスを評価することになるので、LLM-as-judge Evaluatorが効果的 「時間がかかる」 「内部の動作を評価していない」
「評価指標の定義が難しい」という欠点がある Single Step:エージェントのステップを単独で評価する 高速で実行でき、アプリケーションの失敗箇所を特定しやすい 「エージェントの全体像が把握できない」 「後半ステップのデータセット作成が困難」という欠点がある Trajectory:期待された経路をたどったかどうかを評価する エージェントが取った全てのステップを評価するアプローチ 複数の正しいパスがある場合に評価しづらい 16
今回試した組み合わせ → これを動かすための仕組みを用意した © LayerX Inc. 評価方法:Final Response Datasets:実装コード Evaluators:LLMが主体となり、人が最終チェック
17
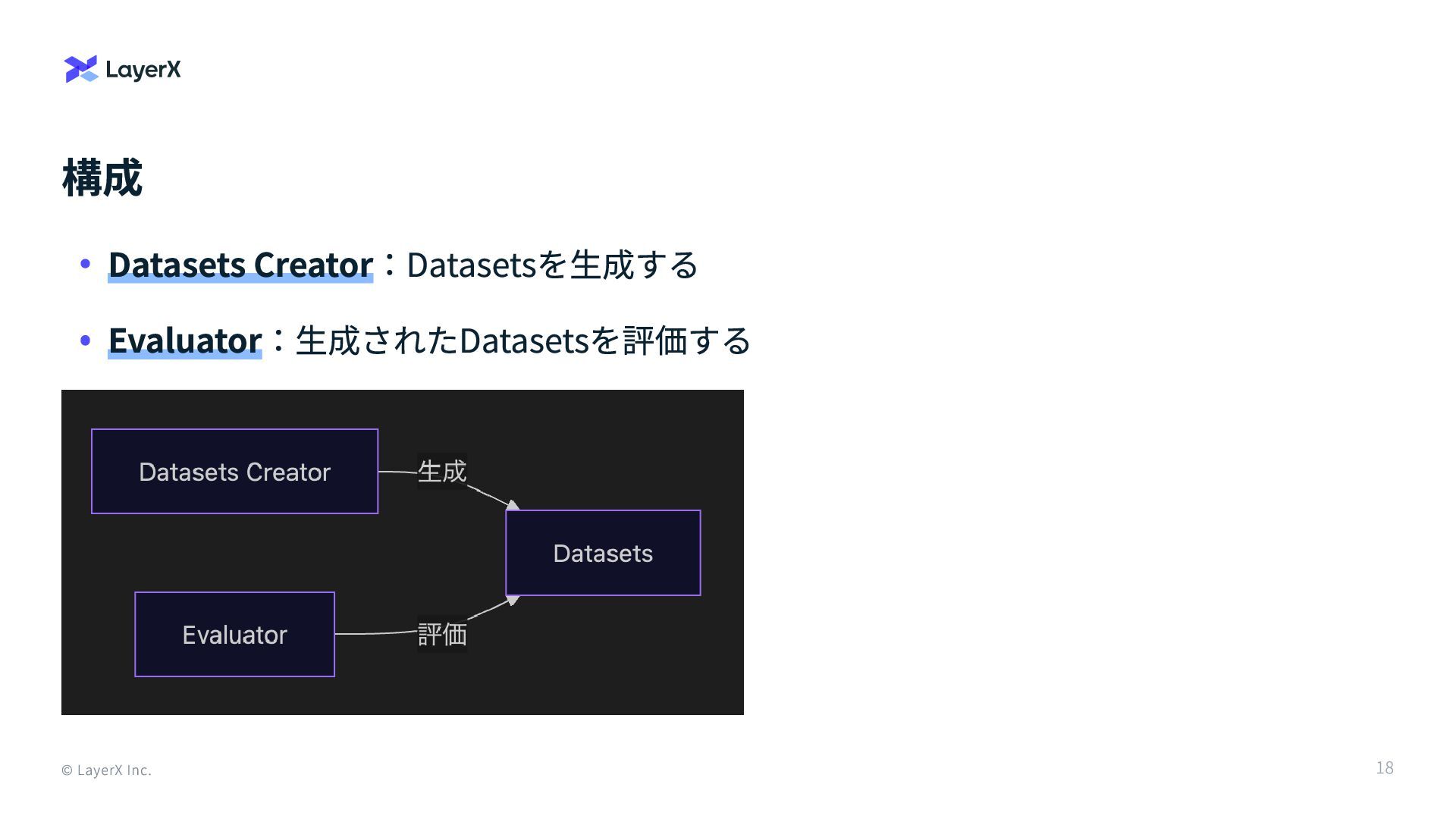
構成 © LayerX Inc. Datasets Creator:Datasetsを生成する Evaluator:生成されたDatasetsを評価する 18
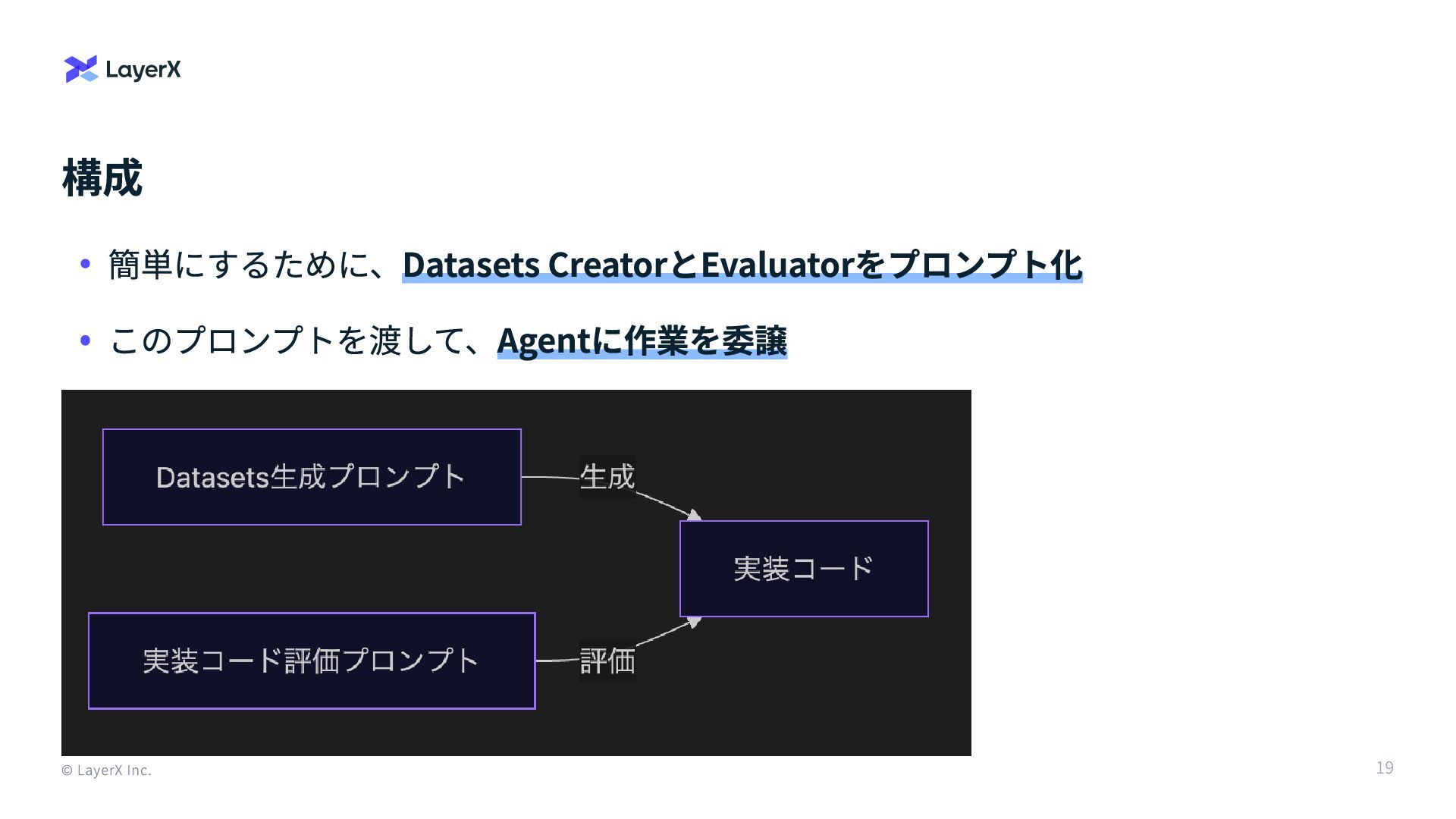
構成 © LayerX Inc. 簡単にするために、Datasets CreatorとEvaluatorをプロンプト化 このプロンプトを渡して、Agentに作業を委譲 19
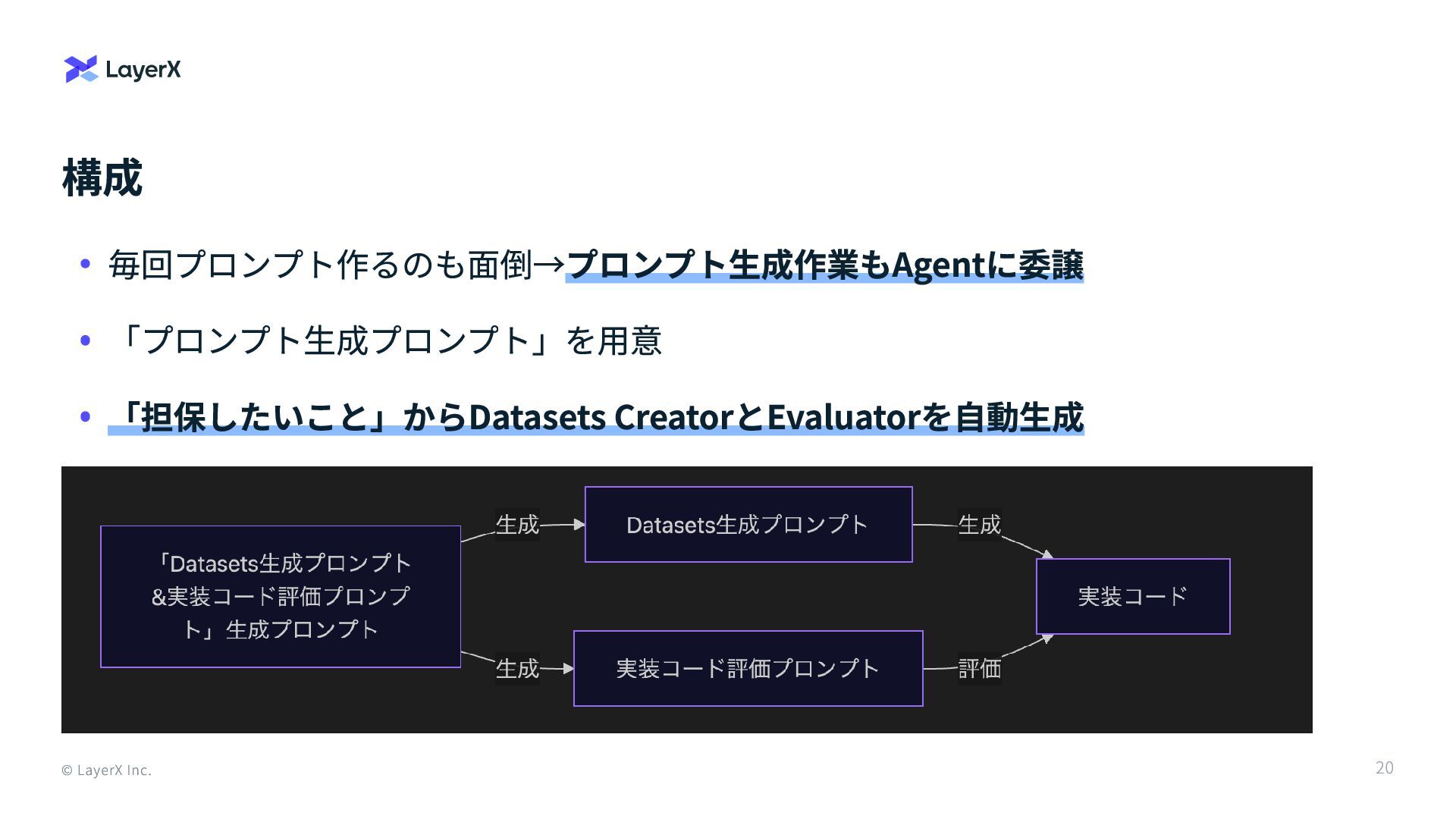
構成 © LayerX Inc. 毎回プロンプト作るのも面倒→プロンプト生成作業もAgentに委譲 「プロンプト生成プロンプト」を用意 「担保したいこと」からDatasets CreatorとEvaluatorを自動生成 20
動作イメージ Claude CodeのCustom Slash Commandでプロンプ ト生成用プロンプトを実行 /create-benchmark で起動 © LayerX
Inc. 21
Datasets Creator 検証対象となるDatasets (実装コード)を生成する ためのタスクを定義したフ ァイル AIにはこれをプロンプトと して渡して、Datasetsを生 成してもらう ©
LayerX Inc. 22
Evaluator 生成されるDatasets(実装コード) をどう評価するか定義したファイル 最終的に、AIにこれを読ませながら成 果物の評価を行ってもらう © LayerX Inc. 23
評価の実行 Datasets Creatorと Evaluatorの内容に問題がな いことを確認 /benchmark で起動 LLMのアウトプットは一定 にはならない 複数回並列実行して総合的に判
断(Claude CodeのTaskツール で実現) © LayerX Inc. 24
結果 © LayerX Inc. 25
できるようになったこと © LayerX Inc. 「なんかよさそう」 「なんかイマイチ」という状態を客観的に評価できるようになった 変更前後の差分を見ることで、対応内容に価値があるかを判断しやすくなった (今後)モデルを変えるだけで、どういった変化が現れるか検証しやすくなった 26
実際に改善できたこと
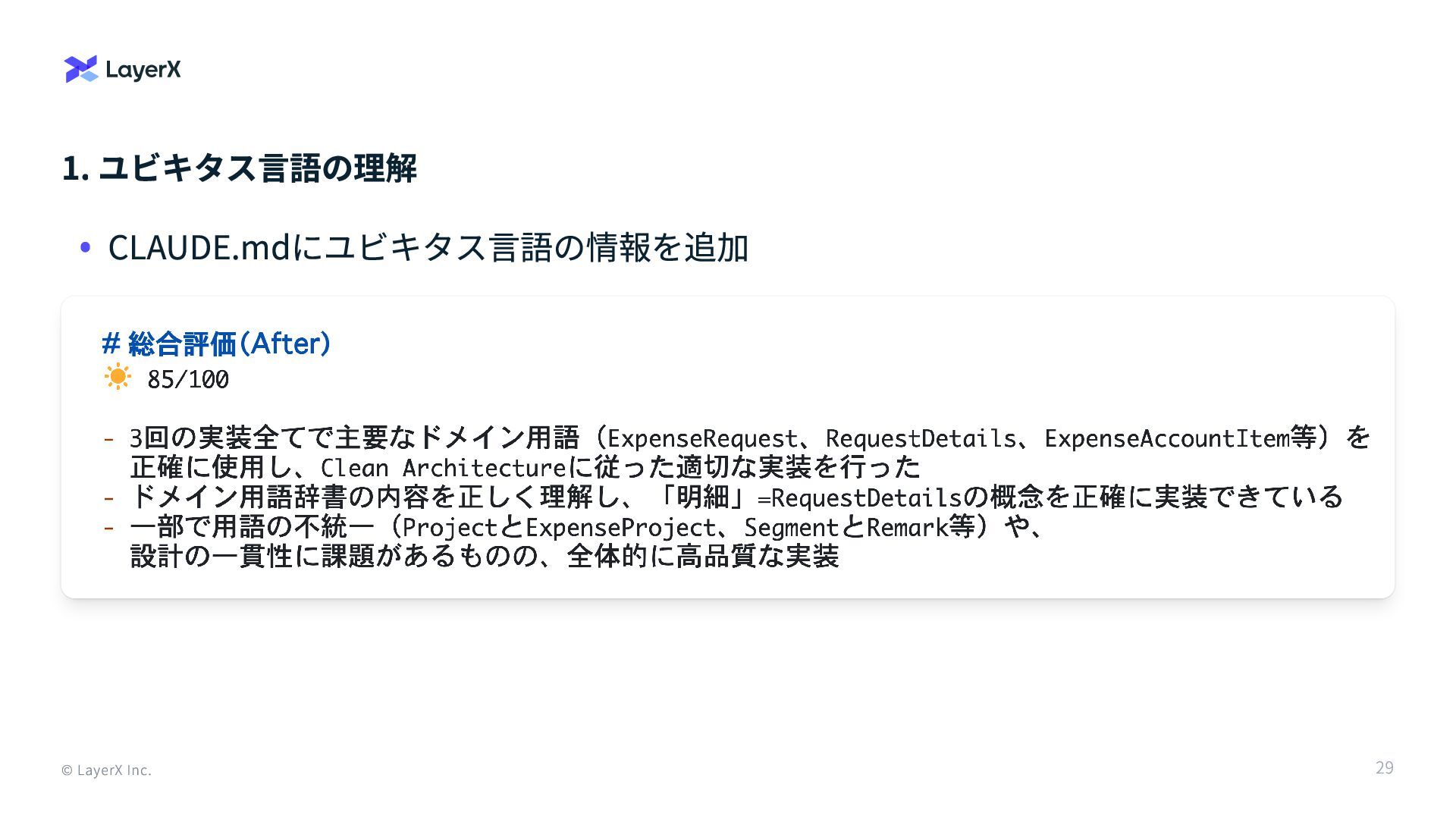
1. ユビキタス言語の理解 © LayerX Inc. Claude Codeに乗り換えてから、ユビキタス言語の理解が足りてない気がする → ドメイン用語の理解度チェックのベンチマークを追加 28
1. ユビキタス言語の理解 © LayerX Inc. CLAUDE.mdにユビキタス言語の情報を追加 29
2. 定型的な実装の安定化 © LayerX Inc. すでに存在する実装パターンがあるが踏襲してくれない 30
2. 定型的な実装の安定化 © LayerX Inc. 実装の手順を記述したPlaybookを追加し、 CLAUDE.md にそのindex情報を追加 (コンテキストサイズを抑えるためimportまではしない) 31
課題 © LayerX Inc. 実行時間が長い コスト面を考えるとCIに載せられない try & errorも時間がないとできない(git worktreeなど活用して裏で回しておくことはできるが...)
これを実行する習慣は中々つかない 今回実験的にやってみているが、普段積極的にやるかと言うとやらない気がする... ここまで仕組み化はせず、プロジェクトで何個か挙動を確認するためのスニペットを持っておくぐらいでも十分 かも あくまでベンチマーク 実際の実装時に100%期待結果が出るとは限らない ある程度、個々のプロンプトにも左右される (が、近い将来"プロンプト力"のようなものは重要じゃなくなってくるかもしれない) 32
今後、より意味のあるものにするには 継続的に色々試していくぞ! © LayerX Inc. ベンチマークの作成と起動をオートにする 「うまくいかなかったこと」を溜めておく → これをトリガーに自律的に改善を回せたら良いかもしれない AIからの自動提案などと組み合わせる
それらの改善提案を適用すると、「Before/Afterでこうなるよ」を合わせて示す → 取り込むモチベーションになる 33
None
© LayerX Inc. 35
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}