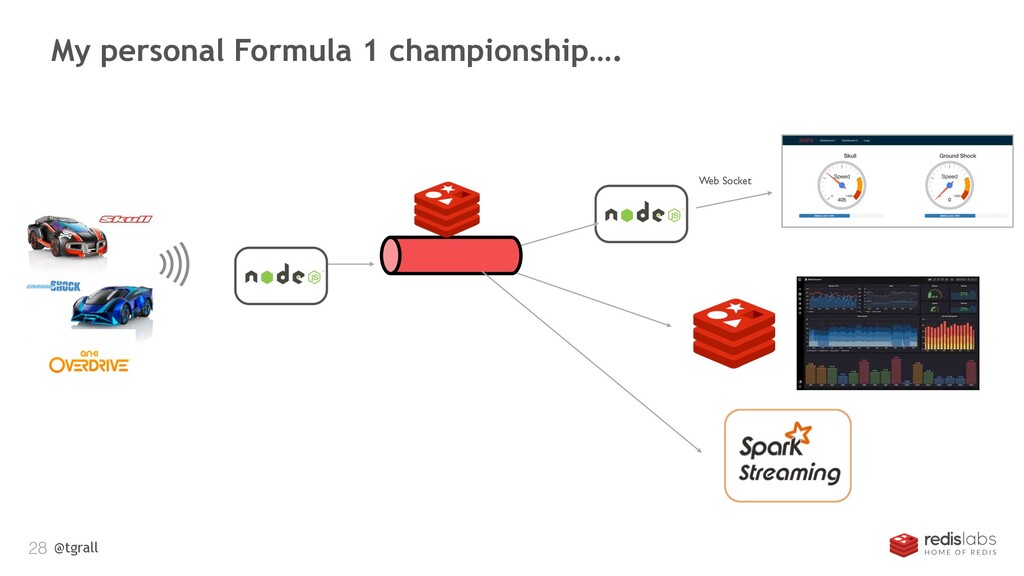
Modern race cars produce lot of data, and all this in real time. In this presentation I will show you how data could be generated and used by various applications in the car, on the track or team head quarter. The demonstration will show how to move data using messaging systems like Apache Kafka, process the data using Apache Spark and use various storage technics: Distributed File System, NoSQL Database. This presentation is a great opportunity to see how to build a " near real time big data application". The code of the demo is available as open source.
About: Tugdual Grall, Technical Account Manager - Redis Labs
Tugdual Grall is Technical Account Manager at Redis Labs where help customer and community to adopt Redis. Before joining Redis Labs Tug was PM at RedHat, Developer Advocate at MapR, MongoDB and Couchbase. Tug has also worked as CTO at eXo Plaform and JavaEE product manager, and software engineer at Oracle. Tugdual is Co-Founder of the Nantes JUG (Java User Group) that holds since 2008 monthly meeting about Java ecosystem.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
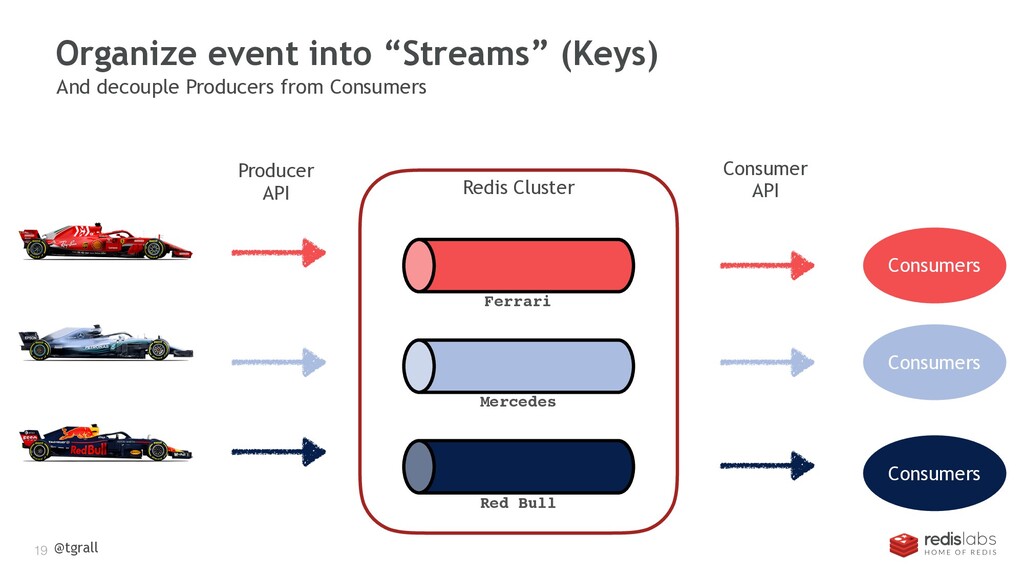
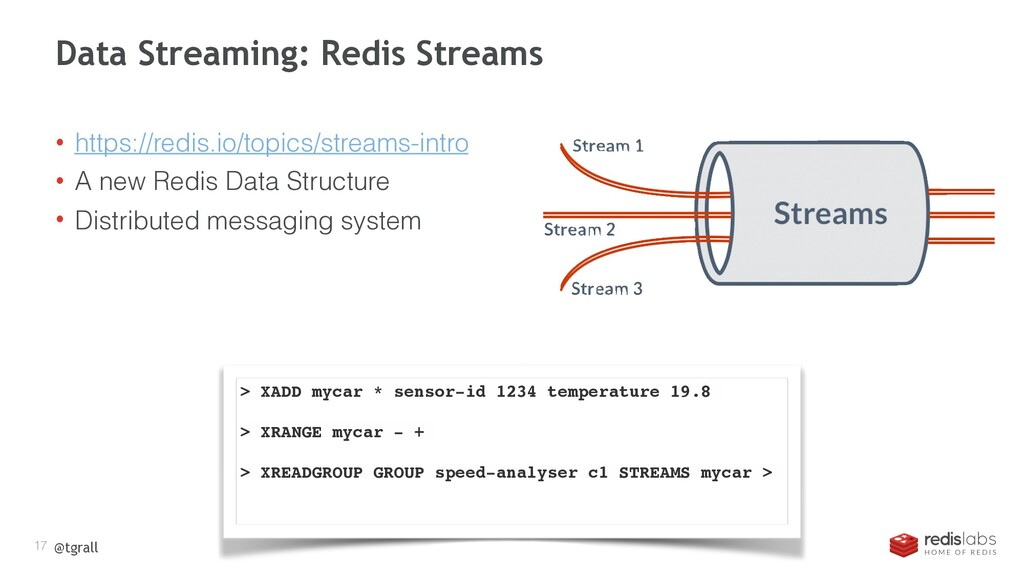{kind=link}
{kind=link}
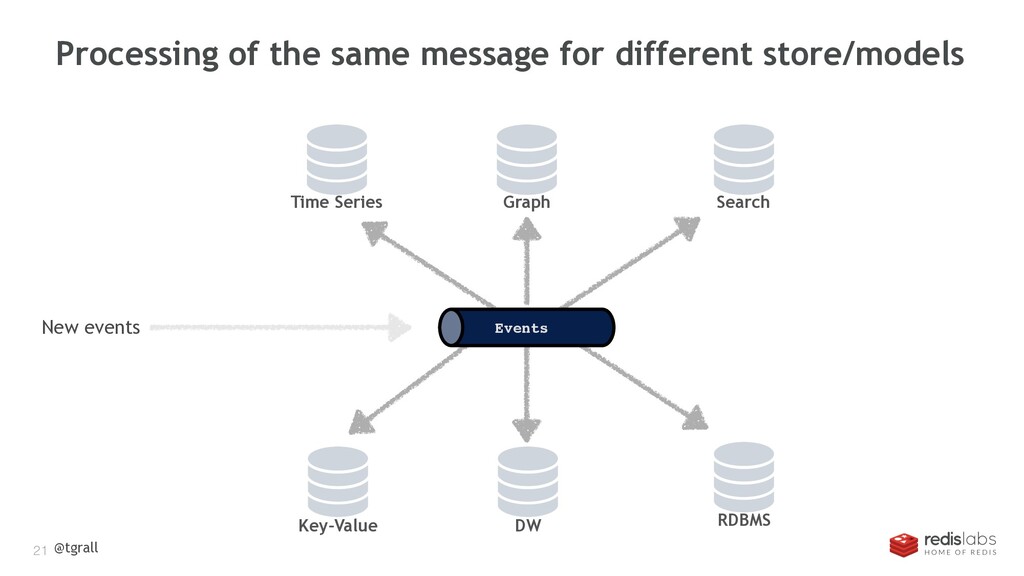
{kind=link}
{kind=link}
{kind=link}
{kind=link}
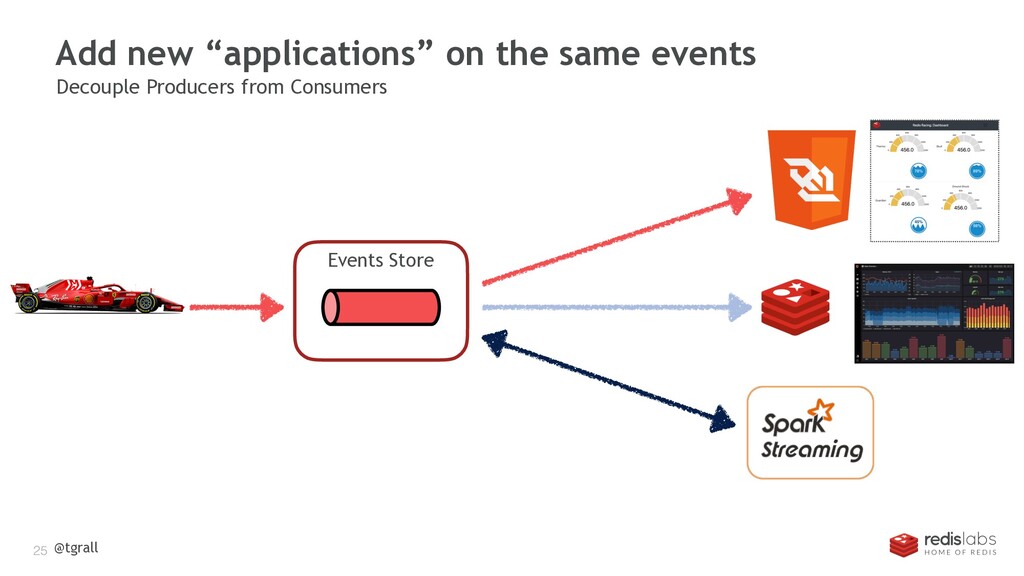
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}