learning’. Springer. Breiman, L. ( ). ‘Bagging predictors’. Machine Learning, ( ), – . Chernozhukov, V., Chetverikov, D., Demirer, M., Du o, E., Hansen, C., Newey, W. & Robins, J. ( ). ‘Double/debiased machine learning for treatment and structural parameters’. e Econometrics Journal, ( ), C –C . Cutler, A., Cutler, D. R. & Stevens, J. R. ( ). Random forests. In C. Zhang & Y. Ma (Eds.), Ensemble machine learning (pp. – ). Springer US. Hornik, K., Stinchcombe, M. & White, H. ( ). ‘Multilayer feedforward networks are universal approximators’. Neural Networks, , – . Lovell, M. C. ( ). ‘A simple proof of the fwl theorem’. e Journal of Economic Education, ( ), – eprint: https://doi.org/ . /JECE. . . - .
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
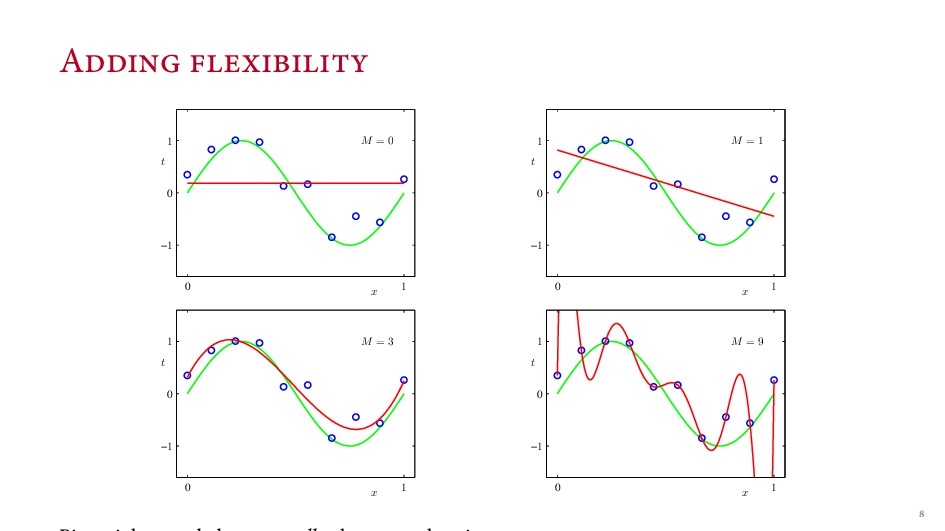{kind=link}
{kind=link}
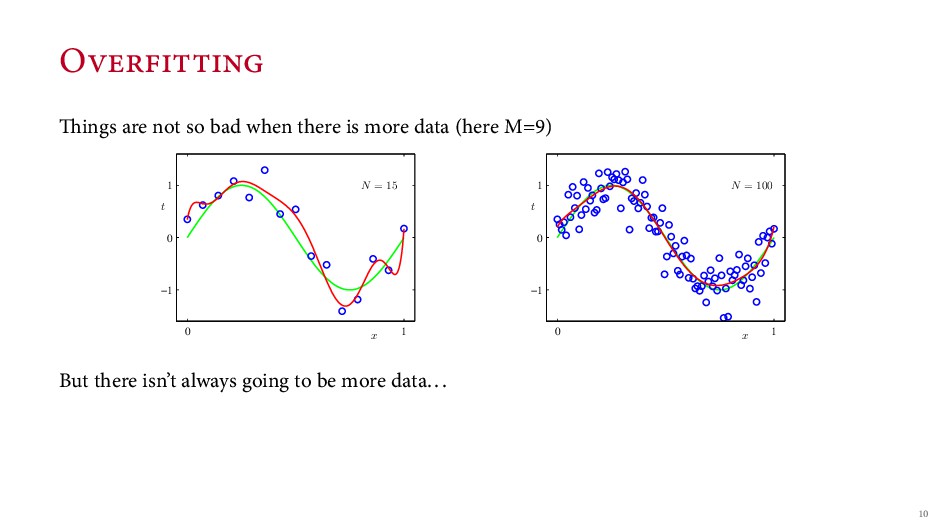{kind=link}
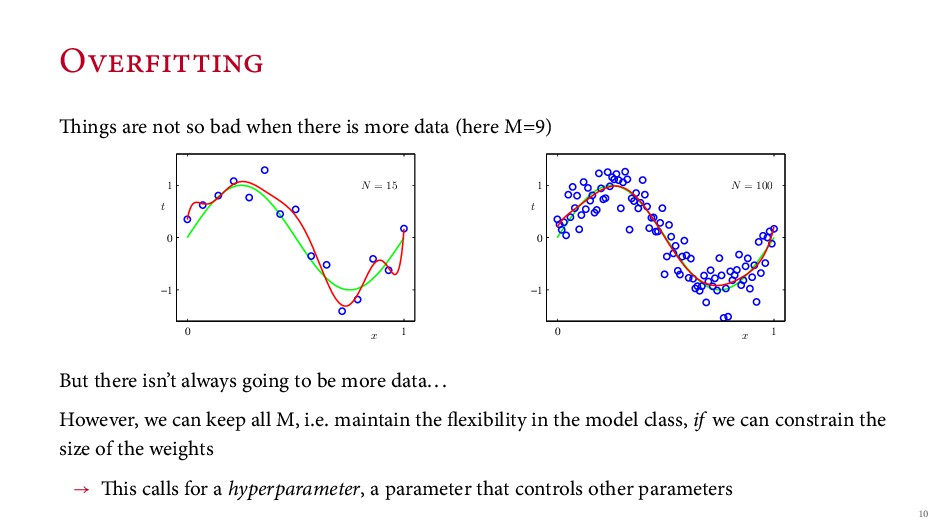{kind=link}
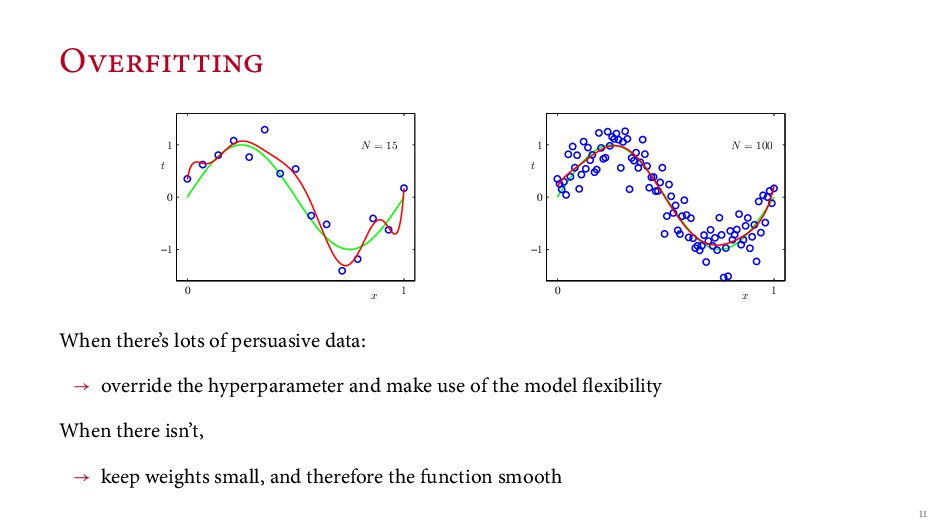{kind=link}
{kind=link}
{kind=link}
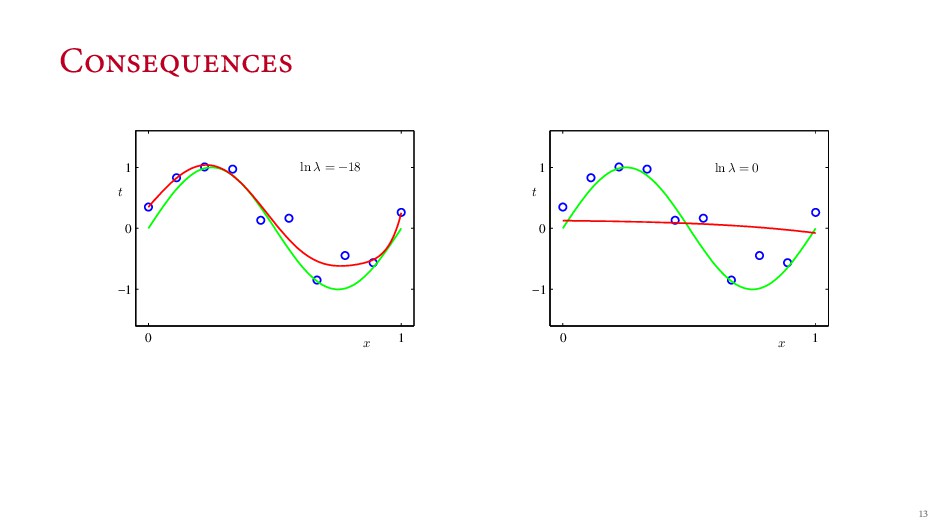{kind=link}
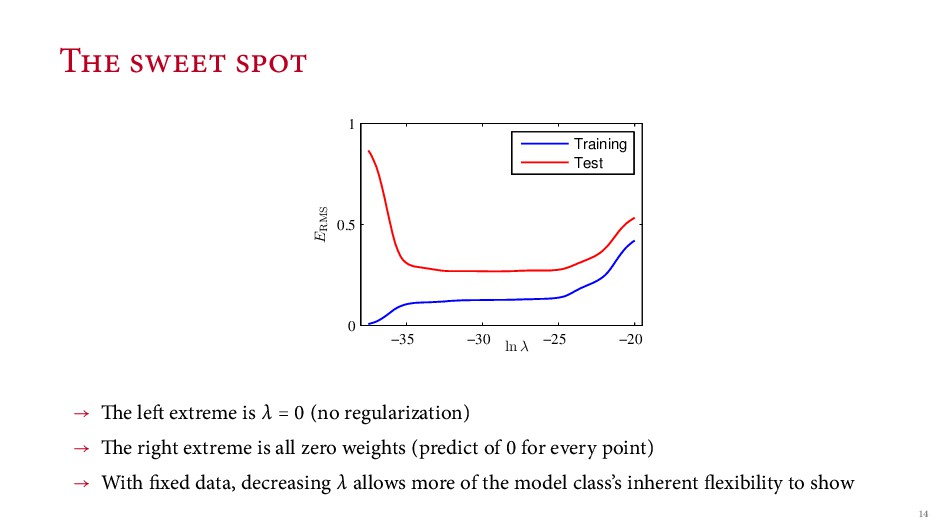{kind=link}
{kind=link}
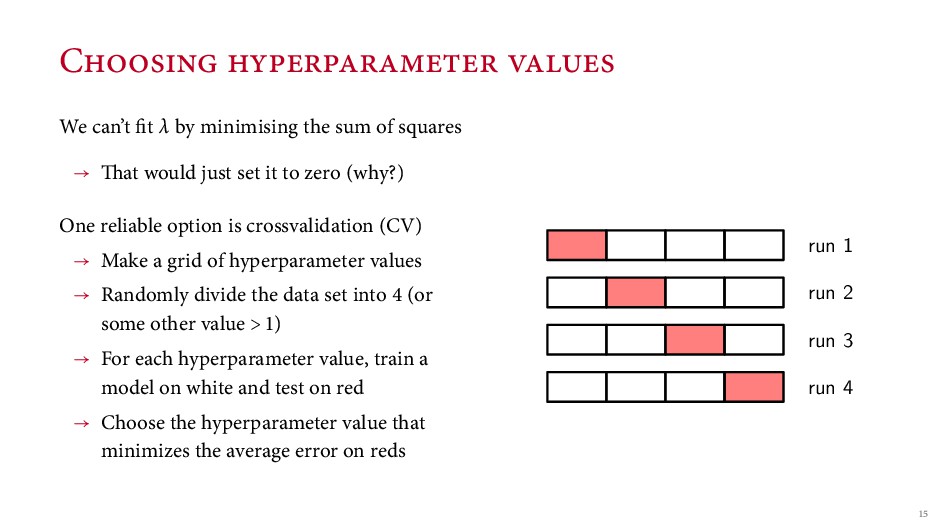{kind=link}
{kind=link}
{kind=link}
{kind=link}
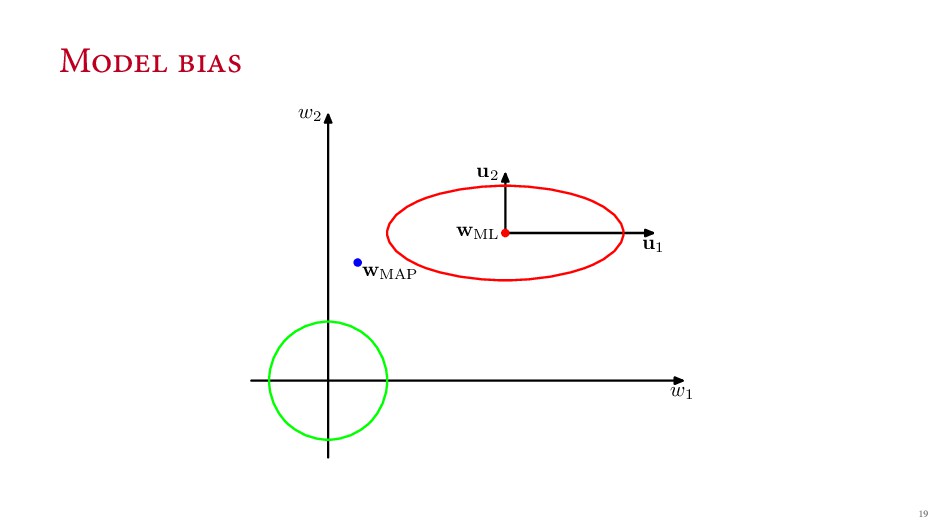{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}