formats, and compression techniques. • How to minimize memory usage by adjusting data types. • Strategies to reduce both memory and file size simultaneously. • Using the Parquet File Format Agenda Image generated by OpenAI's DALL·E 3 3
of RAM came to me for help. They were facing the challenge of having to load and analyze📊 a file that was a massive 32GB. 🤔 Image generated by OpenAI's DALL·E 3 4
the equipment you already possess, you might need to explore ways to minimize memory usage to get things done. 😟💰🔒🛠🔍 Image generated by OpenAI's DALL·E 3 6
can load 🔄, preprocess, and analyze data📊 that's far larger than your computer's available memory, all without having to upgrade ⏫ your hardware 🖥🚫🔧 or incur additional expenses. 🚫💰 Image generated by OpenAI's DALL·E 3 7
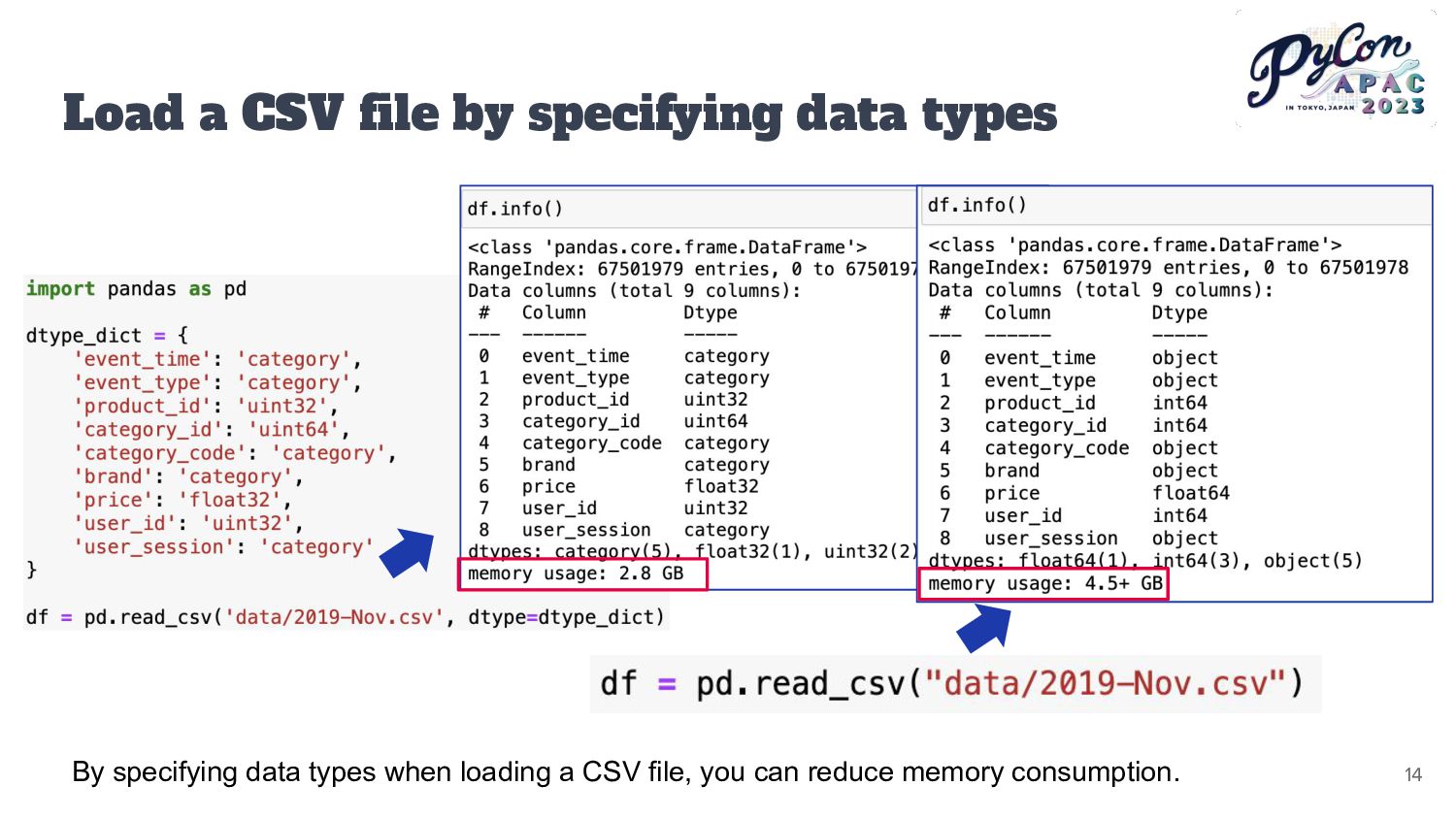
you load a CSV file in Pandas, integers are read as int64 and floats as float64. • If the size of the data is larger than the default specified size, it results in memory wastage. • Can struggle with analyzing datasets larger than the available memory • Even with datasets of adaptable size, memory usage tends to increase due to operations requiring the creation of intermediate copies 13
Parquet format file, • Reload the entire file, • Concat into one file. Presentation Material Code Execution Environment CPU i7, 32GB RAM External Sort Image generated by OpenAI's DALL·E 3 15
• 🔄 Handle data iteratively rather than loading it all at once into memory. • 📊 This method allows for dataset analysis without the need for full memory loading. • 🐼 Using the chunksize parameter in Pandas' read_csv() for this approach. Image generated by OpenAI's DALL·E 3 18
to the entire pandas DataFrame? Image generated by OpenAI's DALL·E 3 Changing the data type alone can be effective in reducing the storage and processing costs of data. For instance, converting data from the float64 type to float32 can cut memory usage in half. 22
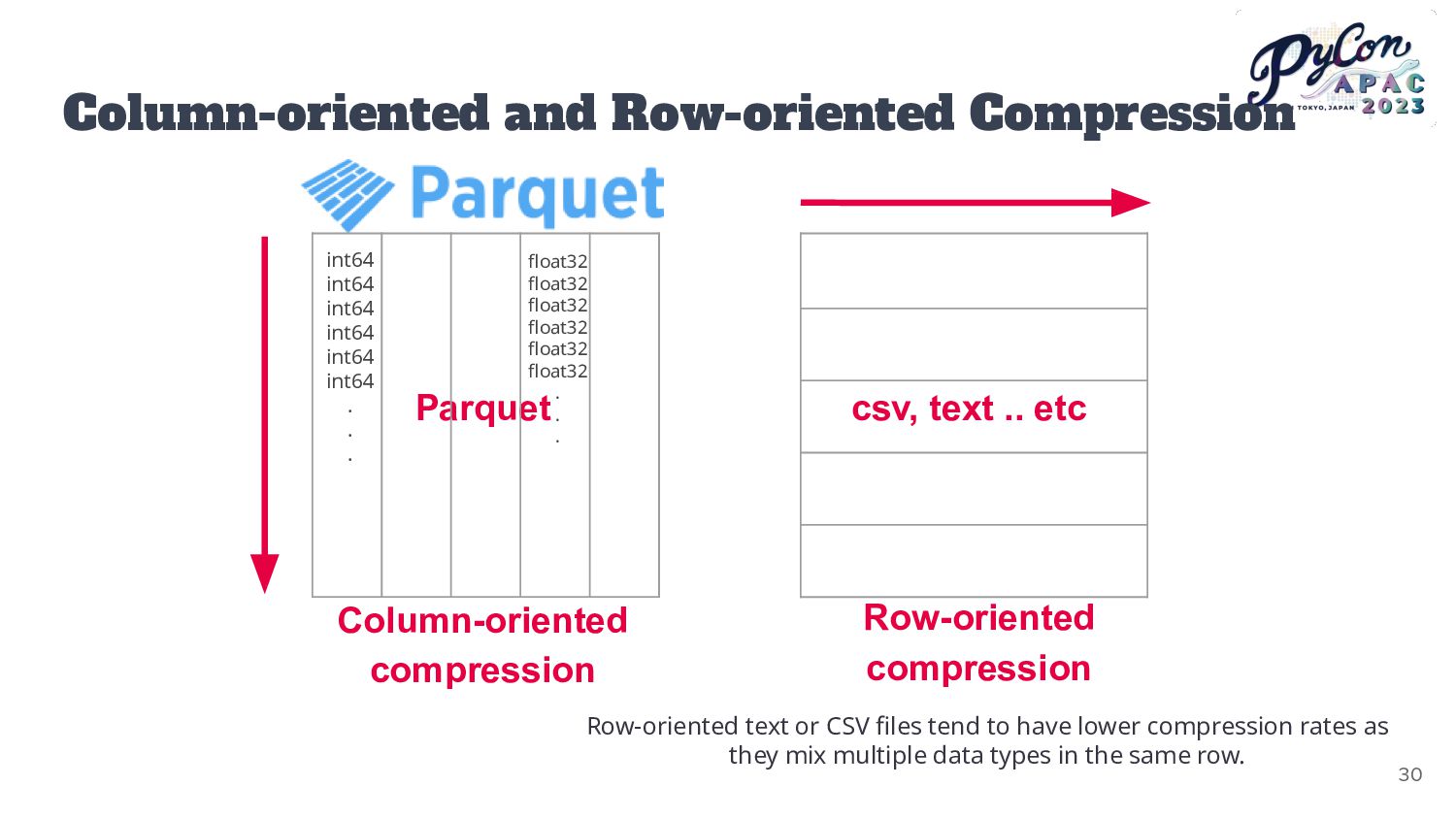
unused columns or rows Reduce memory usage through downcasting Save in Parquet format For string-type data, converting values with low cardinality to categorical values can reduce memory usage. 24
smaller parts for faster loading. Load permissible parts of the file into memory Remove unused columns or rows Reduce memory usage through downcasting Save in Parquet format 27
Two original files totaling 14.68GB (one more is a hidden system file). After conversion, approximately 111 files totaling 2.24GB (one more is a hidden system file). This is based on the assumption that even in Parquet format, it has been downcasted. 28
within the file. • Each time it's loaded, it defaults to a basic data type. • To load it as a specific type, you have to specify it every time, which can be tedious. When using CSV or TXT files. Image generated by OpenAI's DALL·E 3 31
Metadata in Parquet files provides essential information about the structure and content of the files, supporting efficient data reading and querying. 34
format. • Schema information of the data. • The total number of rows stored in the file. • Metadata for each column. • Data types and encoding methods. • The compression methods used. • Basic statistical information for each column, like maximum value, minimum value, and count. 35
larger file into about 100 separate parquet files, they can be loaded in just 30 seconds. Load Parquet format file concat() Remove unused columns or rows To analyze 39
DALL·E 3 Just as we've implemented strategies to optimize memory by eliminating unnecessary usage, we might not require all the data when managing datasets. 44
Remove any unnecessary columns or rows, • and sample only the data that is required. Process only the necessary data into subsets. Image generated by OpenAI's DALL·E 3 45
💾 • Repeatedly concat the subsets. 🔀 • With limited memory, handle large data by processing and then deleting. 🔄🗑 Searching through the entire data set can be time-consuming. 50
dataframe with over 100 million data points, it takes close to 7 minutes. And when calculating retention using groupby() on a daily basis, it takes over a minute. Of course, the computation is still slow, but without preprocessing, it would have either not finished or resulted in a memory error. 54
7 seconds to create a simple date-formatted derived variable from 100 million rows, and around 47 seconds were required for the groupby aggregation operation. 55
rows) 2. Specific Column Indexing and Selective Loading (Reducing the number of columns) 3. Chunking and Iteration 4. Changing Data Types 5. Compressing Data Using Parquet Format 6. Parallel Processing 7. Distributed Processing Frameworks such as Dask, Vaex, PySpark, etc. 57
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}