Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
trocco第5回ユーザー会_troccoとAmazon Redshiftで挑んだコンテンツマ...
Search
CUEBiC Inc.
September 05, 2023
1k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
trocco第5回ユーザー会_troccoとAmazon Redshiftで挑んだコンテンツマーケティングの分析基盤構築
CUEBiC Inc.
September 05, 2023
More Decks by CUEBiC Inc.
See All by CUEBiC Inc.
BigQueryのメタデータ管理を、スクラッチで やったはなし
cuebic9bic
2
170
BigQueryのTVFを型駆動で自動生成する世界
cuebic9bic
0
240
AIに頼りすぎない新人育成術
cuebic9bic
3
840
反脆弱性(アンチフラジャイル)とデータ基盤構築
cuebic9bic
3
550
Tableau API連携の罠!?脱スプシを夢見たはずが、逆に依存を深めた話
cuebic9bic
3
370
今だから言えるセキュリティLT_Wordpress5.7.2未満を一斉アップデートせよ
cuebic9bic
2
1.1k
BigQuery Remote FunctionでLooker Studioをインタラクティブ化
cuebic9bic
4
730
構造化すれば怖くない 画像検索から始める木を見て森に入る勉強法
cuebic9bic
2
540
〜可視化からアクセス制御まで〜 BigQuery×Looker Studioで コスト管理とデータソース認証制御する方法
cuebic9bic
3
480
Featured
See All Featured
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
Context Engineering - Making Every Token Count
addyosmani
9
1k
From π to Pie charts
rasagy
0
240
The Art of Programming - Codeland 2020
erikaheidi
57
14k
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
How to Talk to Developers About Accessibility
jct
2
460
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.8k
The SEO identity crisis: Don't let AI make you average
varn
0
520
GitHub's CSS Performance
jonrohan
1033
470k
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
The Curse of the Amulet
leimatthew05
2
13k
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
590
Transcript
〜成果集計処理を劇的に改善!〜 troccoとAmazon Redshiftで挑んだ コンテンツマーケティングの分析基盤構築 株式会社キュービック テクノロジーエキスパートセンター Tech Lead 尾﨑勇太 2023.9.4
開示範囲:公開ドキュメント 1
株式会社キュービックとは? 2 株式会社キュービック /CUEBiC Inc. 社名 事業 設立 資本金 拠点
2006 年 10 月 24 日 31,000,000円 人員 約 300 名(単体)※インターンを含む 約 484 名(連結) ※2022年3月現在 デジタルメディア事業、集客支援事業 ほか 東京、福岡
3 ▪これまでの実績 創業時より一貫して取り組んできたデジタルメディ ア事業を軸に、たしかな成長を続けています。 ヒト起点のマーケティング×デザインで、高品質な サービスやプロダクトを実現。 それによりステークホルダーの皆さまから厚い信頼 を獲得し、現在の実績につながっています。 デジタルメディア業界のトップラ ンナーとして成長し続ける
4 ▪デジタルメディア事業 ー ビジネスモデル
自己紹介 5 株式会社キュービック Tech Lead/データエンジニア 尾﨑 勇太(おざき ゆうた) 覚え方:尾崎豊(おざきゆたか)と一字違い 1990年和歌山県白浜町生まれ
生息地:千葉県松戸市 スキルセット 1. マネジメント/品質管理/データ分析 2. マイナスからゼロ、ゼロイチ 3. サーバーサイド(WEB/アプリ開発) @waichang111 経歴の詳細 はてなブログ
セッション内容 6 1.ここで差がつく成果集計 2.Redshift始めました 3.メンバー登録に関して
7 troccoの強みってなんだろう?
8 1.広告コネクタが豊富 2.RDB/DWHに連携ができる 3.DWHに対して更新ができる
9 ▪広告のtroccoの活用例 各媒体のレポートの内、取得したい項目を丸めて生データとして Redshiftで転送 整形、集計の際に必要となる設定値を カスタム変数で設定(trocco APIで動的 に更新できるようにする) Tableau 広告費集計+独自分析軸
(メディア,LP別など) ROAS,CVRなどの分析 広告媒体の運用調整 広告運用者 ① ② ① ② ③ ④
10 troccoの弱みってなんだろう?
11 1.転送データが引き継げない 2.trocco APIの用途が限定的 3.戻り値が受け取れない
1.ここで差がつく成果集計 12
13 ▪デジタルメディア事業 ー ビジネスモデル 売上の着地見込みを正確に早く算出して、 日々の施策のPDCAを回せるかが鍵
既存のアーキテクチャ 14 広告/ASP アーキテクチャ CUEBiC Analytics RDS Tableau データ抽出/整形/蓄積 データ分析
データ出力 独自の社内集計基盤システムCUEBiC Analyticsに広告と成果のレポートを取り込み 集計結果を保存し、Tableau上で事業部のメディア担当者が分析できる状態に出力
既存のアーキテクチャのそれぞれの役割 15 広告/成果データの ・データ設定 ・データインポート ・データ集計 ・データエクスポート データの保持 ・集計設定データ ・広告/成果の生データ
・広告/成果の集計データ データの加工 ・広告データ ・データの加工 データ分析 ・集計データの加工 ・ビジュアライズ CUEBiC Analytics RDS Tableau
既存のアーキテクチャ 16 広告/ASP アーキテクチャ CUEBiC Analytics RDS Tableau データ抽出/整形/蓄積 データ分析
データ出力 事業成長に伴い、広告/成果の説明変数が増え、集計方法も複雑化 CUEBiC Analyticsの老朽化し、事業の要求に耐えられなくなってきた・・・・ ・集計がずれている ・出力が遅い ・参照されない 個別実装が増え スプシの魔改造化・・・
既存のアーキテクチャ 17 広告/ASP アーキテクチャ CUEBiC Analytics RDS Tableau データ抽出/整形/蓄積 データ分析
データ出力 DX戦略としてCUEBiC Analyticsを解体し、ローコード化により業務効率化を測るとともに 広告/成果以外のデータの分析軸も取りうる基盤へのリプレイスを実施
18 troccoの強みを活かしつつ 弱みは代替しよう
リニューアル後のデータ分析環境でのそれぞれの役割 19 CUEBiC Analytics 広告データ/成果データ ・データ抽出 ・データ転送 ・データ整形 データの蓄積 データの加工
データの集計 データ分析 ・集計データの加工 ・ビジュアライズ 集計設定 Tableauのデータを連携 ・集計設定データ保存 ・その他マスタ保存 Oasis Tableau
実現したアーキテクチャ 20 広告/ASP アーキテクチャ データ抽出 集計設定 集計ロジック データ蓄積 データ分析 Oasis
Tableau Tableau troccoをフロントとして配置してDWHとしてAmazon Redshiftを選定。 troccoの転送設定とデータマート機能により大幅に処理の簡素化に成功
実現したアーキテクチャ 21 広告/ASP アーキテクチャ データ抽出 集計設定 集計ロジック データ蓄積 データ分析 Oasis
Tableau Tableau troccoの強みを活かしてデータマート機能でAmazon Redshiftの ストアドプロシージャーを呼び出し、集計処理をSQLで完結させた
実現したアーキテクチャ 22 troccoから一行記載するだけ。 SQLをtrocco上に直書きを回避しつつ責務をRedshiftに寄せることが可能に!! BigQueryのSQL ストアド プロ シージャを想像してください。 データマート-Amazon Redshift
導入後の試算効果 23 運用ミスによる集計誤差を自動化により40%低減 単価情報の精度向上により20%〜30%向上 コミュニケーション負荷20%〜30%軽減 8人月→4人月 Rubyエンジニア工数の64%をノーコード/SQLで代替 DXエンジニアの工数の37.5%を自動化により削減 エンジニアリング工数 集計誤差
最もフォーカスしたい点 データ設定 データ整形/集計 アウトプット データ収集 Rubyエンジニア工数の64%をノーコード/SQLで代替 前 後 運用保守/技術負債返済 運用保守/機能追加
troccoとSQLかければ なんとかなるのでは? 25
26 と・・・ 思われたが・・・・
直近の切実な悩み 27 広告/ASP アーキテクチャ データ抽出 集計設定 集計ロジック データ蓄積 データ分析 Oasis
Tableau Tableau troccoの弱みとして転送データが引き継げないことにより一時的なデータ設定の間口として Oasisを用意し、Redshiftのストアドプロシージャによる集計処理との分離が必要となった
直近の切実な悩み 28 アーキテクチャ データ抽出 集計設定 集計ロジック データ蓄積 Oasis Oasisからtrocco APIでの転送設定を起動とACTIVE
RECORDからRedshiftのストアドプロシー ジャの呼び出しが発生しており、Rails側に責務がじわじわ寄っている trocco API ストアドプロ シージャ
このままでは原点回帰 では?? 29
30 大丈夫です! 更新前提で組んでいます
なぜこうなったか? 31 転送設定に関してはカスタム変数がAPIのパラメータとして用意されており、外部サービスから 任意のパラメータを連携することが可能 転送ジョブの実行POST /jobs
なぜこうなったか? 32 一方でシンクジョブはAPIのエンドポイントがなく、Redshiftのストアドプロシージャに trocco経由で引数を渡すことができない・・・ 転送ジョブの実行POST /jobs
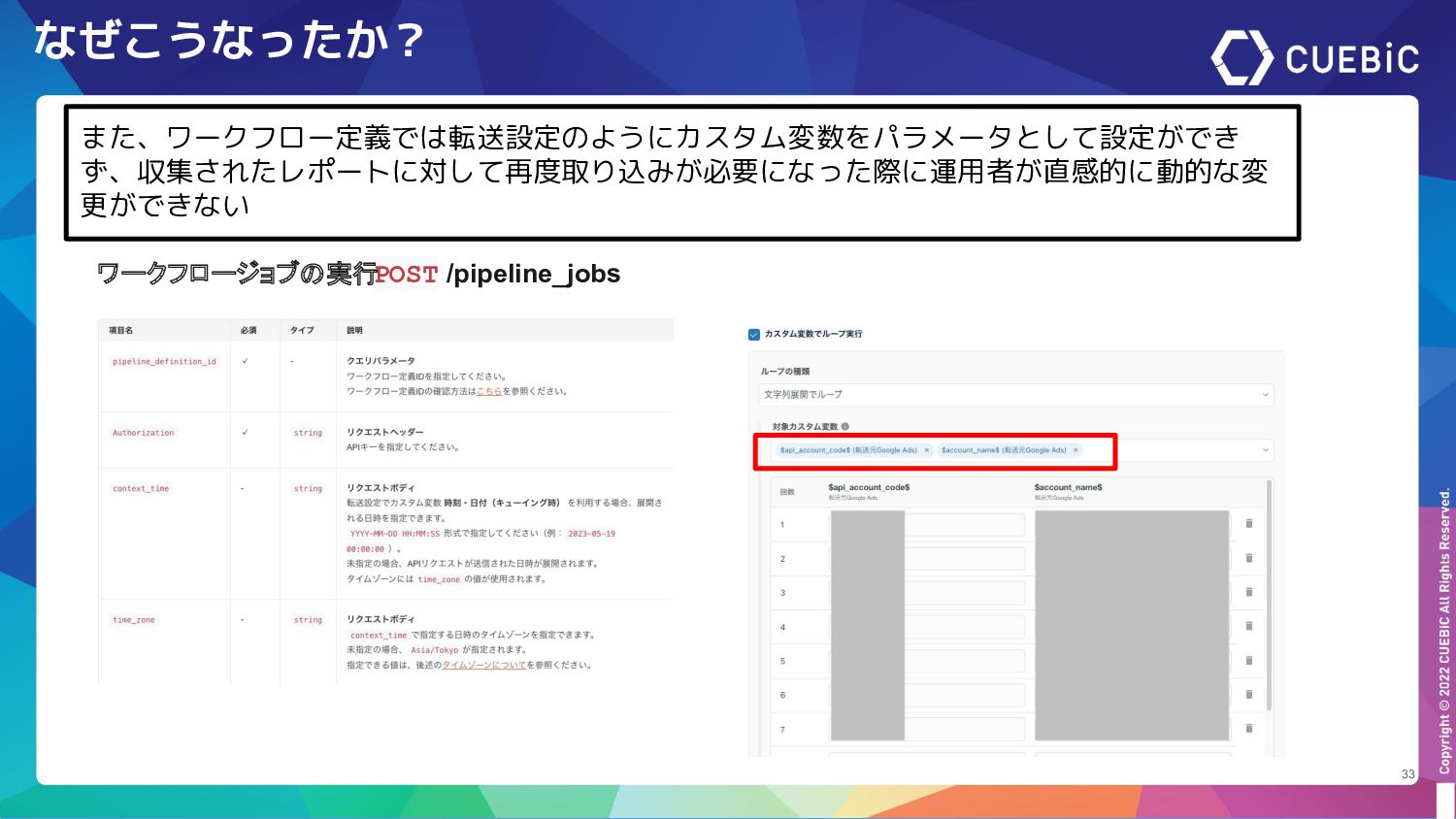
なぜこうなったか? 33 また、ワークフロー定義では転送設定のようにカスタム変数をパラメータとして設定ができ ず、収集されたレポートに対して再度取り込みが必要になった際に運用者が直感的に動的な変 更ができない ワークフロージョブの実行 POST /pipeline_jobs
Troccoへの期待 34 広告/ASP アーキテクチャ データ抽出 集計設定 集計ロジック データ蓄積 データ分析 Oasis
Tableau Tableau troccoのデータマート機能で設定したシンクジョブのAPI化やワークフローAPIのカスタム変数 の追加などにより、更なるローコード化が進む見込み
泥臭い作業はやっぱり 必要!! 35
いざってときは スクラッチで開発する 気概を持ち続けたい 36
お次はガラッと変わり ましてRedshiftについ て解説します 37
2.Redshift始めました 38
Redshift ServerlessとRedshiftの違い Redshift ServerlessはAuto Scalingされるが Redshiftは自前でコンピューティングリソースと ストレージリソースの調整が必要ということ
Redshiftの構成 Redshift クライアントから SQL クエリを受け付けコンパイルし、 コンピュートノードに配信 コンピュートノードは高速ローカル SSD ・キャッシュを 利用しており、該当データがキャッシュに存在しない場合は
マネージドストレージからブロック単位でデータ読み取りを実行 複数のコンピュートノードでこの処理を並列実行するため、 大量データを高速に処理することが可能 Amazon Redshift Serverless の概要 今までのAmazon Redshift(RA3 インスタンス)より引用
Redshift Serverlessの構成 Redshift Serverless クラスターという概念がなくなり、「名前空間」「ワー クグループ」というコンポーネントで管理される ノード部分の綿密なキャパシティプランニング(ノード数やイン スタンスタイプの決定)をする必要がなくなり、分析のためのク エリ実行時に自動でプロビジョニング・スケールしてくれる Amazon
Redshift Serverless の概要 Amazon Redshift Serverlessより引用
実際に運用前にぶつかった課題 1.Redshift Serverlessへの書き込み速度の劣化 ▶RubyのActiveRecordではupdate処理に大幅な劣化が見られた 2.RA3プラン移行による速度劣化の懸念 ▶同一RPUあたりの速度が劣化する可能性 3.Redshift Serverlessコスト肥大化の懸念 ▶日常的なレポート抽出/集計だけで月額15万円以上の費用が発生
コストメリットとパ フォーマンス両方の担 保が必要だ 43
解決策 1.Redshift Serverlessへの書き込み速度の劣化 ▶RedshiftからはFederated QueryでAuroraからデータを取得 2.RA3プラン移行による速度劣化の懸念 ▶RA3のクラスターも生成し、Redshift Serverlessと速度比較を実施 3.Redshift Serverlessではコスト肥大化の懸念
▶1,2検証後にRedshiftのプロビジョニングのRA3プランに変更
Federated Queryとは? いわゆる、RedshiftからPostgreSQLに対してデータベースリンクする機能(RDS,Aurora) 以下のような外部スキーマを定義することで、 接続が可能になります CREATE EXTERNAL SCHEMA apg FROM
POSTGRES DATABASE 'database-1' SCHEMA 'myschema' URI 'endpoint to aurora hostname' IAM_ROLE 'arn:aws:iam::123456789012:role/Redshift-Secre tsManager-RO' SECRET_ARN 'arn:aws:secretsmanager:us-west-2:12345678901 2:secret:federation/test/dataplane-apg-creds-Yb VKQw'; ※事前に適切なセキュリティグループ/ロールの設定が必要です 45 1.Federated Queryへの活用
1.Federated Queryへの活用 背景 Oasisからの設定内容の更新はRedshift Serverlessに対して直接Updateを行う想定だった ・速度劣化が見られたことからAWS社のSAと相談し、Auroraに責務を移すことに 検証結果 無事疎通が完了 詰まった点 AuroraでIPを許可する形をとっていたが、Redshift
Serverlessは公開IPがない →検証用にRedshift Serverlessを立てる必要があった 46
47 2.Redshiftプロビジョニング作成 当初検証想定 1.Redshift Serverlessから手動でスナップショットを作成 2.スナップショットからRedshiftのクラスターを生成
1.Redshift Serverlessから手動でスナップショットを作成 自動スナップショットからは生成不可のため、 手動でスナップショットを生成してクラスターの復元への復元を実施 48 2.Redshiftプロビジョニング作成
2.スナップショットからRedshiftのクラスターを生成 デフォルトで選択できるノードが16ノード!! 生成後にノードサイズ変更をしてもエラーと なり、ストレージサイズも下げられなかった スナップショットからの生成は断念 49 2.Redshiftプロビジョニング作成
代替検証 1.手動でRedshiftのクラスターを1ノードで生成 2.Redshift Serverlessからデータを移行 50 2.Redshiftプロビジョニング作成
データ移行ってめんどく さい 51
大部分は以下で移行完了 1.DBeaverからSQLファイルをエクスポート 2.クエリエディタからInsert文を直接実行 3.ストアドプロシージャーは定義情報から手動生成 困った点 ・クエリエディタ上ではInsertできる上限は300000文字 ・S3からコピーコマンドをするとキャストで化ける・・・ ・AWS Glueは同期設定するのがしんどい・・・(何よりコストがやばい) 52
2.Redshiftプロビジョニング作成
どうにかできないだろ うか・・・ 53
54 可能です。 そうtroccoならね!!
troccoはバックグラウンドでembulkで 1.S3に配置 2.S3からRedshiftにコピーを自動でやってくれる 面倒な実装や設定は一切不要。しかもカラムの型のキャストも完璧 55 2.Redshiftプロビジョニング作成
いよいよパフォーマン スチェック。速度劣化 しないでくれ・・・ 56
事前設定 1.troccoにRedshiftの接続情報を設定 2.実績のある広告媒体/ASPの転送設定を作成 3.データマート機能で集計のプロシージャを設定 4.ワークフロー機能で2,3を結んだものを実行 検証内容 同一の広告媒体/ASPでレポート取得/集計時間を Redshift Serverless vs
Redshiftで行う 57 3.パフォーマンス比較
広告媒体:検証 結果 レポート取得 Redshift:24秒 Redshift Serverless:2分25秒 Redshift 集計 Redshift:15秒 Redshift
Serverless:43秒 58 3.パフォーマンス比較
成果:検証結果 レポート取得 Redshift:39秒 Redshift Serverless:2分7秒 Redshift 集計 Redshift:3分49秒 Redshift Serverless:6分9秒
59 3.パフォーマンス比較
検証結果:サマリー サービス 広告 成果 比較項目 Redshift Redshift Serverless Redshift Redshift
Serverless 収集 24秒 2分25秒 39秒 3分49秒 集計 15秒 43秒 2分7秒 6分9秒 同一条件下ではRedshiftの方が優位な結果となった 要因 立ち上げ時のデータベース接続のオーバーヘッド 60 3.パフォーマンス比較
3.パフォーマンス比較 今回は1タスクあたりの速度比較だった 平均RPUが高くなった場合はRedshift Serverlessの方に軍配が 上がる可能性はあり ただし、現状の運用想定では毎朝のレポート取得と集計以外は RPUが100を超えるような負荷は想定されない 常時、速度維持を高RPUでも実現する必要はないためRA3への プラン変更を行った 61
結論
3.メンバー登録に関して 62
63 メンバーになっていただくことにより、優先的に案内いたします。 キュービックメンバー登録について CUEBiC TEC Blog セミナー案内 交流会の案内 登録フォームはこちら
64 ご清聴、ありがとうございました
Q&A 65
Q1 66 troccoにSQLを直書きせずに ストアドプロシージャの関数 をCALLすることによる効果/ メリットとは?
Q1.Answer 67 1.責務をtroccoからRedshiftに分けることができ、 troccoを使用する運用メンバーとエンジニアリング領域を分 離できる 2.troccoのAPIで補完できない機能を外部サービスから ストアドプロシージャーを呼び出すことで補完できる
Q1.Example データ設定 データ整形/集計 アウトプット データ収集 DXエンジニア 事業部担当者 データエンジニア Oasis Tableau
APPエンジニア 事業部担当者 開 発 運 用 DXエンジニア 整形の責務は分離
Q2 69 troccoやrailsを用いてRedshiftに蓄 積されたデータは、社内のどのよう な人員が活用するのか?
Q2.Answer 70 誰が? 事業部のSEO/ADの運用担当者や経営陣 1.ASP/広告媒体レポートの収集データを目的変数で分類 2.Tableauでメディアやクライアント別の収益を分析 3.売上目標と予測値のずれを認識しつつ、PDCAサイクルを 回して数値改善を行なう ※アウトプットのデータの粒度は担当者によって違いますが、 データを構成している最小の値は同じというような感じです
どのように?
Q3 71 今後troccoで新しく取り組んでいきた いこと
Q3.Answer 72 Redshiftの広告/成果データとの掛け合わせで シナジーを生み出す troccoのポテンシャルはマル チプラットフォーム間のデー タ連携にあり!!
Q3.Example 73 アーキテクチャ Tableau データ収集 データ分析 BigQueryに蓄積されたGA4データをtroccoのデータマート機能を使用して整形したデータを Amazon Auroraに退避し、TableauからカスタムSQLで参照する データ整形
Auroraをデータソースと して参照し、カスタム SQLでデータを取得 データマート機能でBigQueryのGA4蓄 積データを整形して、BigQueryに整形 後のデータをパーティションで作成 BigQueryデータを Amazon Auroraに転送 troccoワークフロー
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}