(cv: 0.7510) - public: 0.728 • Add a process to decay the target every epoch (cv: 0.7699, +19pt) • Add a periodicity filter to the output (cv: 0.7807, +11pt) • Add a periodicity flag to the input as well (cv: 0.7870, +6pt) - public: 0.739 • batch_size: 16 → 4, hidden_size: 128 → 64, num_layers: 2 → 8 (cv: 0.7985, +11pt) - public: 0.755 • Normalize the score in the submission file by the daily score sum (cv: 0.8044, +6pt) • Remove month and day from the input (cv: 0.8117, +7pt) • Trim the edges of the chunk by 30 minutes on both sides (cv: 0.8142, +4pt) - public: 0.765 • Modify to concatenate the minute features to the final layer (cv: 0.8206, +6pt) - public: 0.768 19
{kind=link}
{kind=link}
{kind=link}
{kind=link}
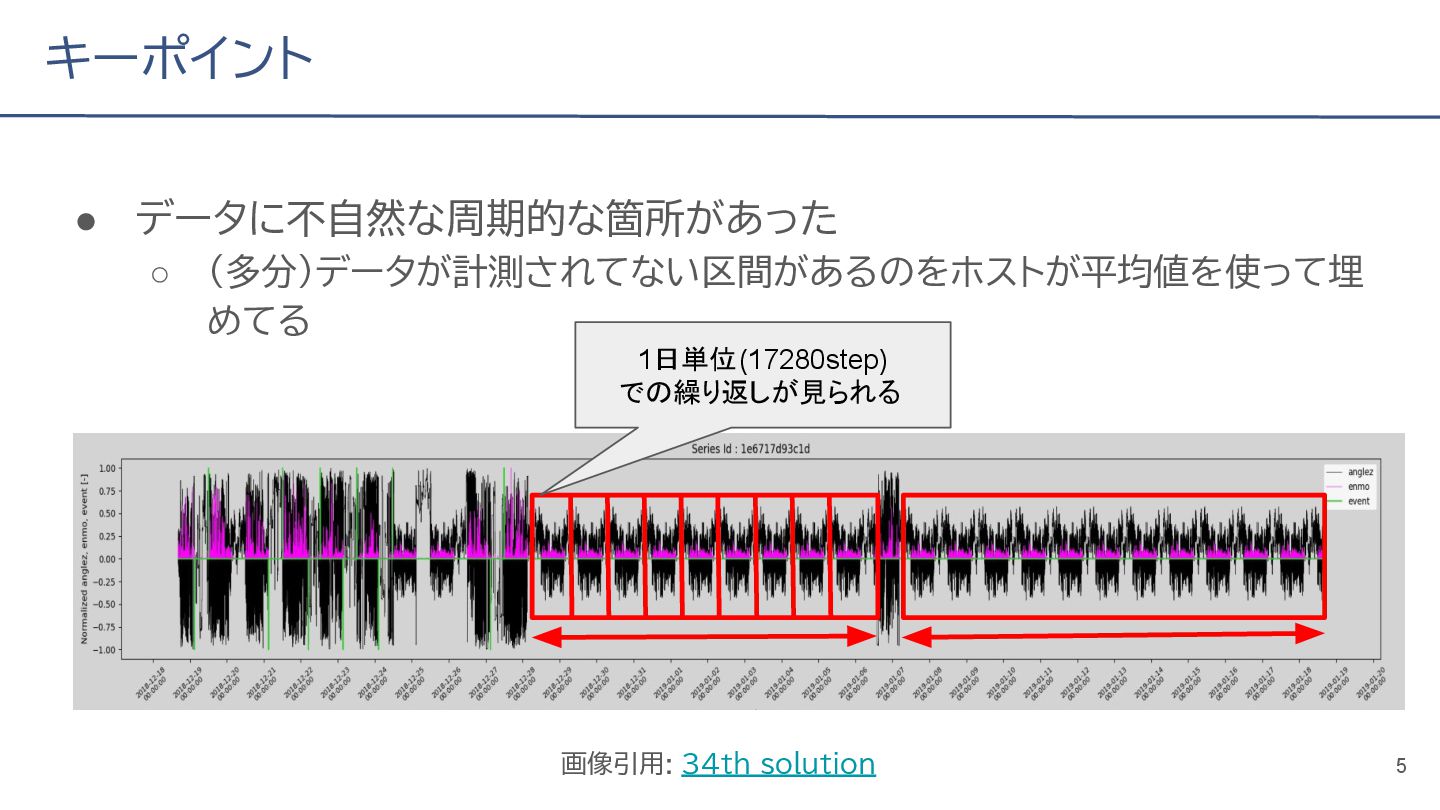{kind=link}
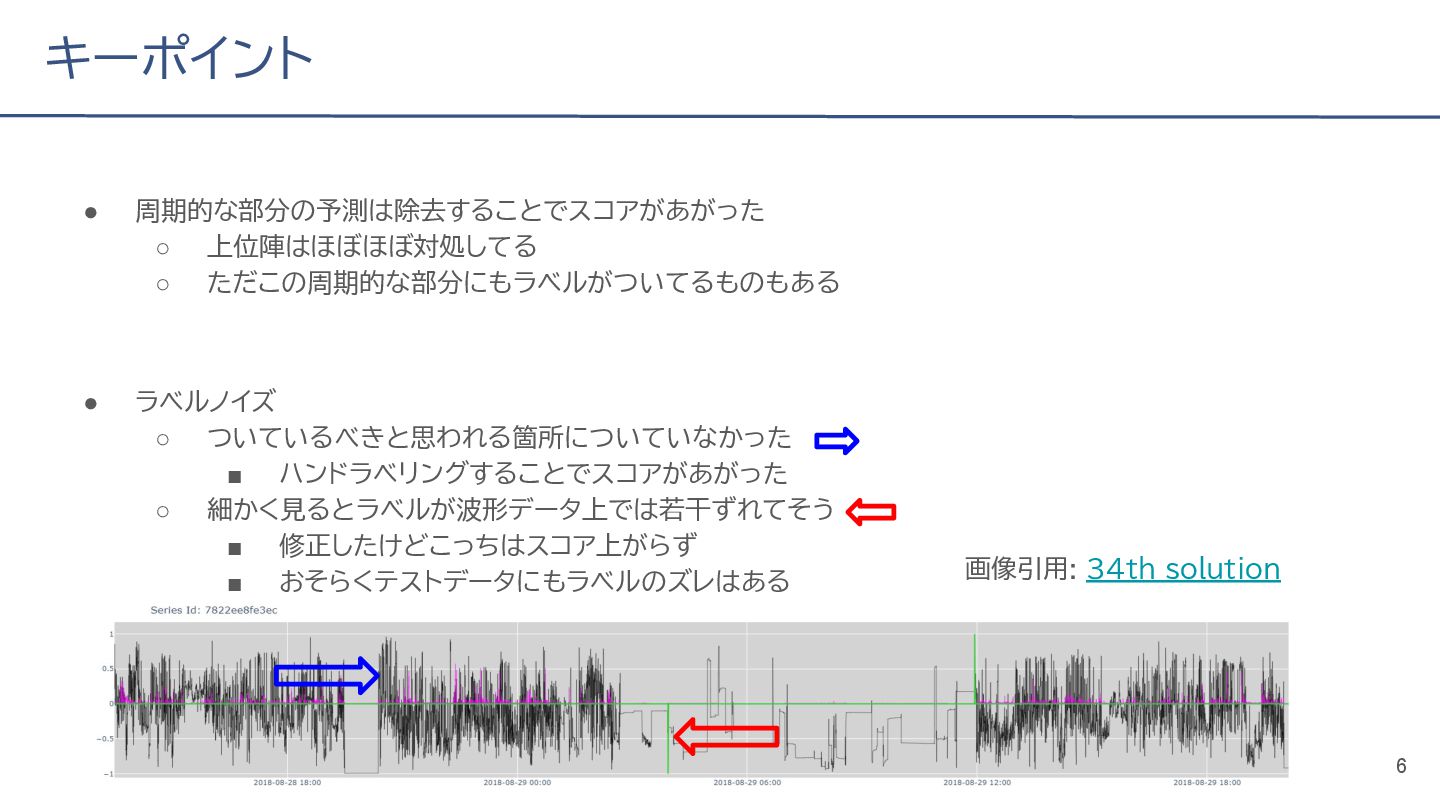{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
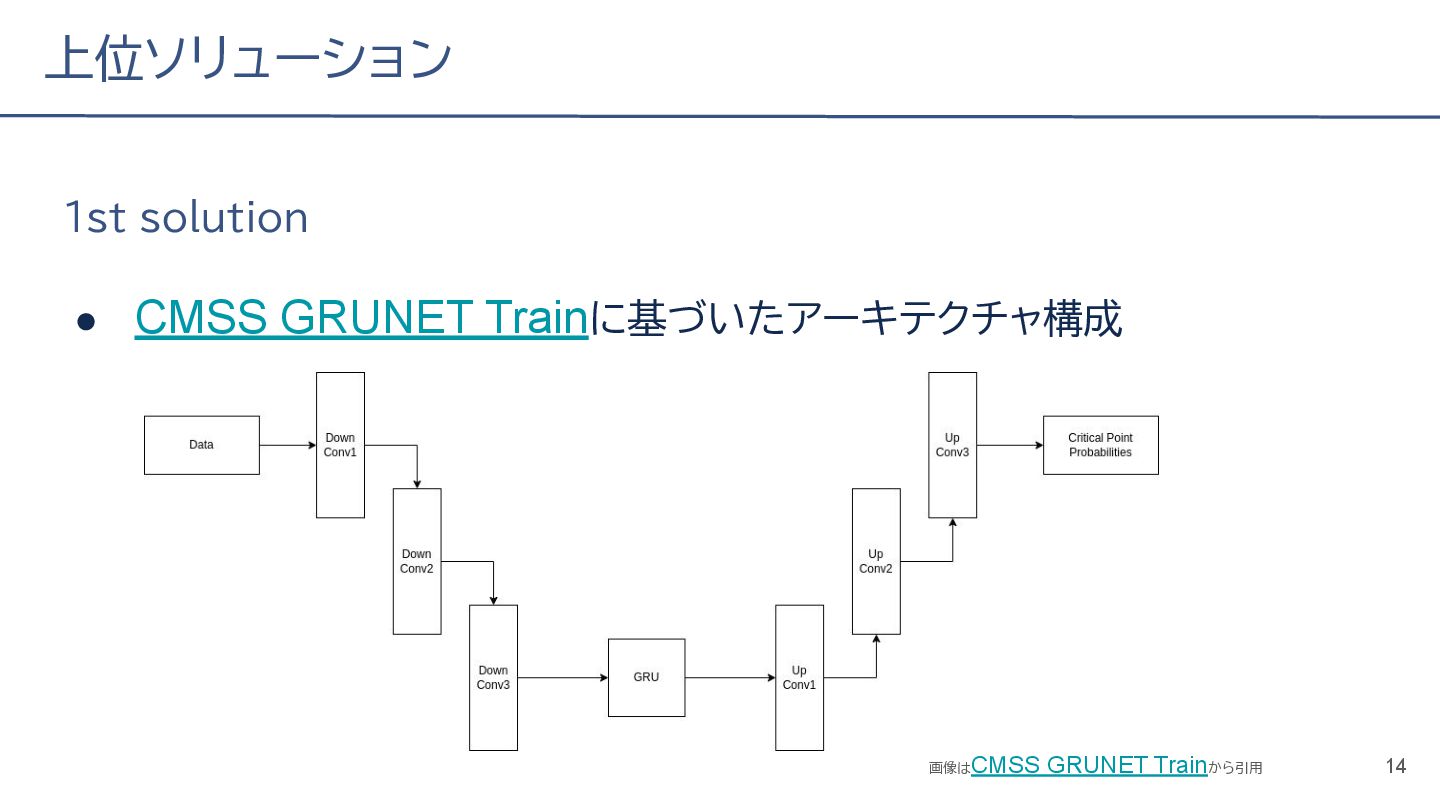{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}