Benjamin Bengfort, District Data Labs
Audience level: Intermediate
Topic area: Modeling
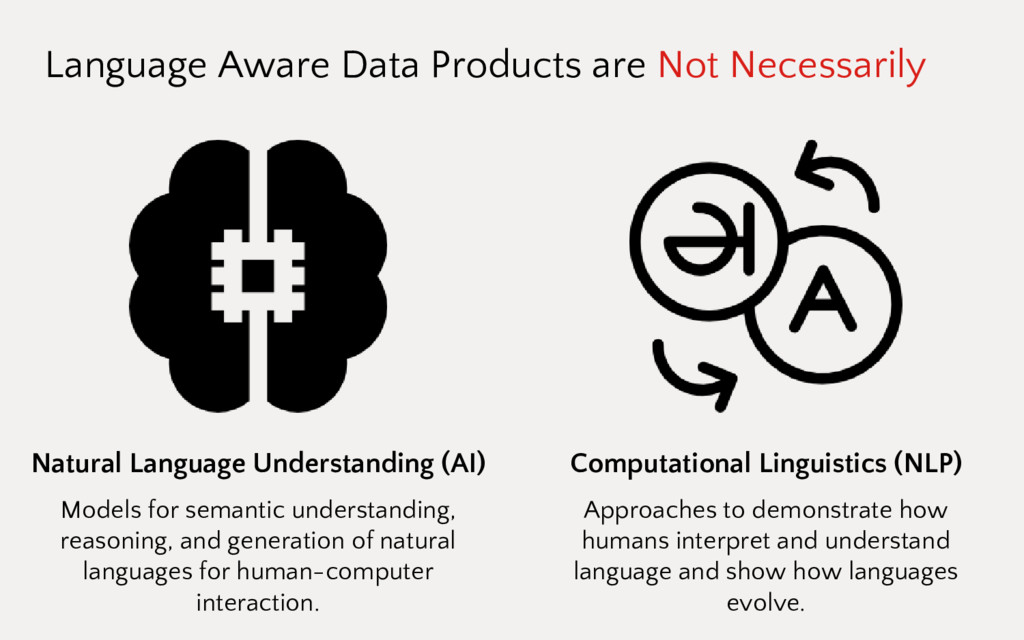
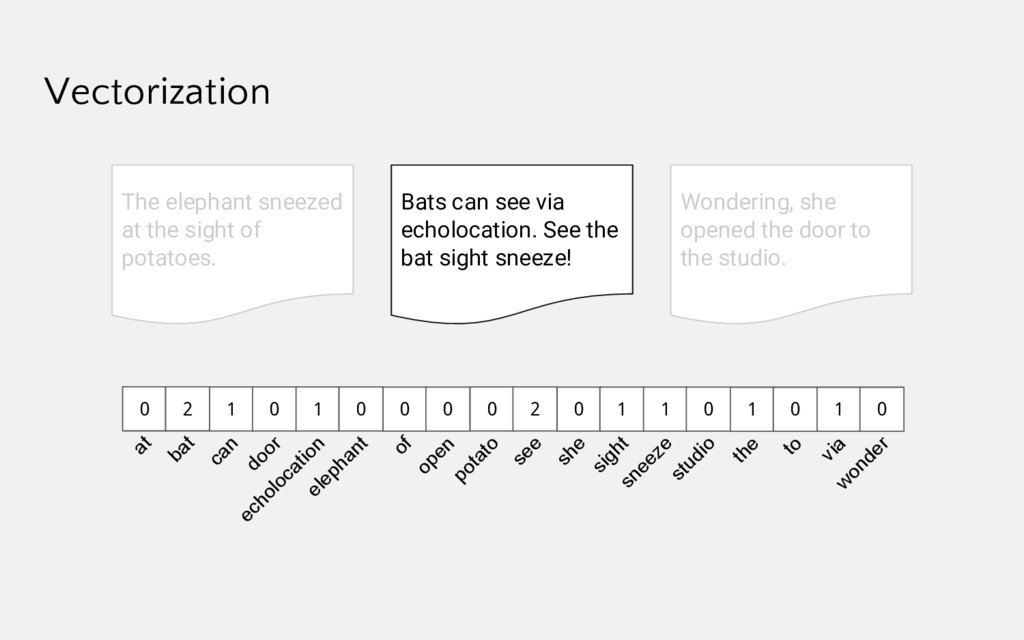
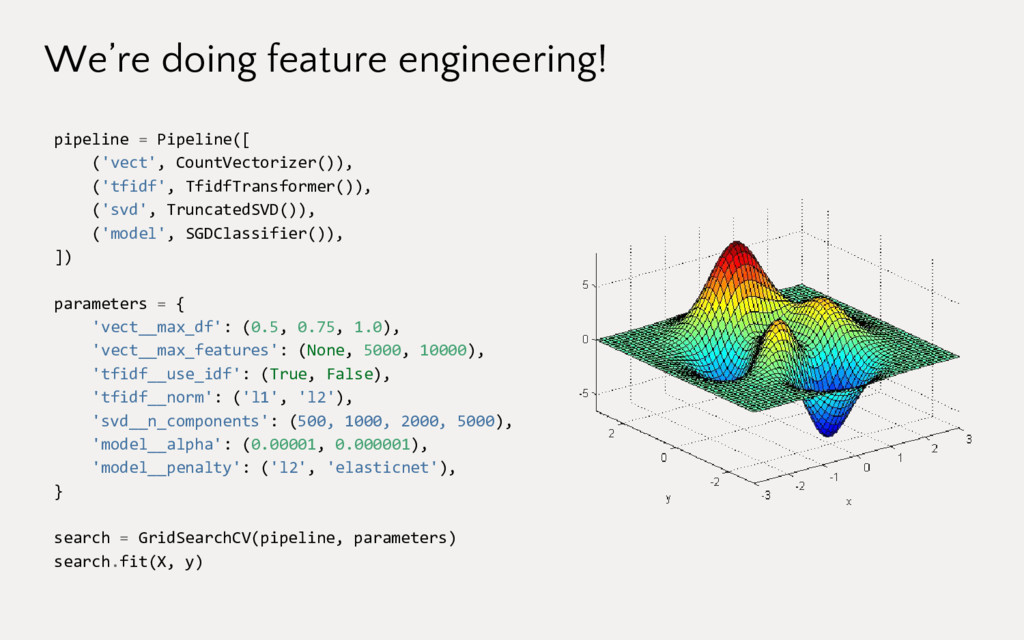
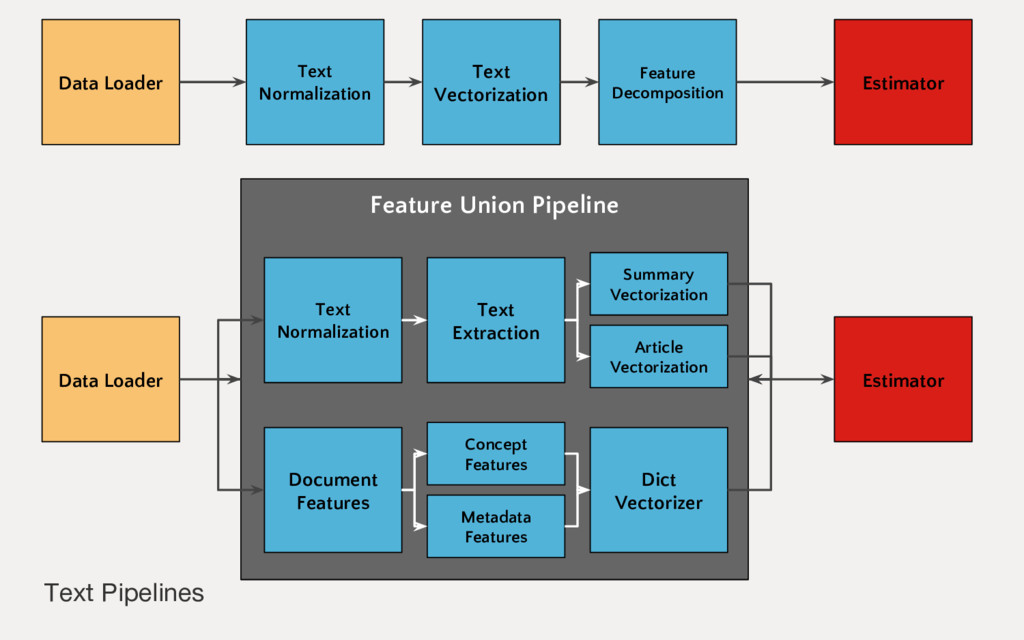
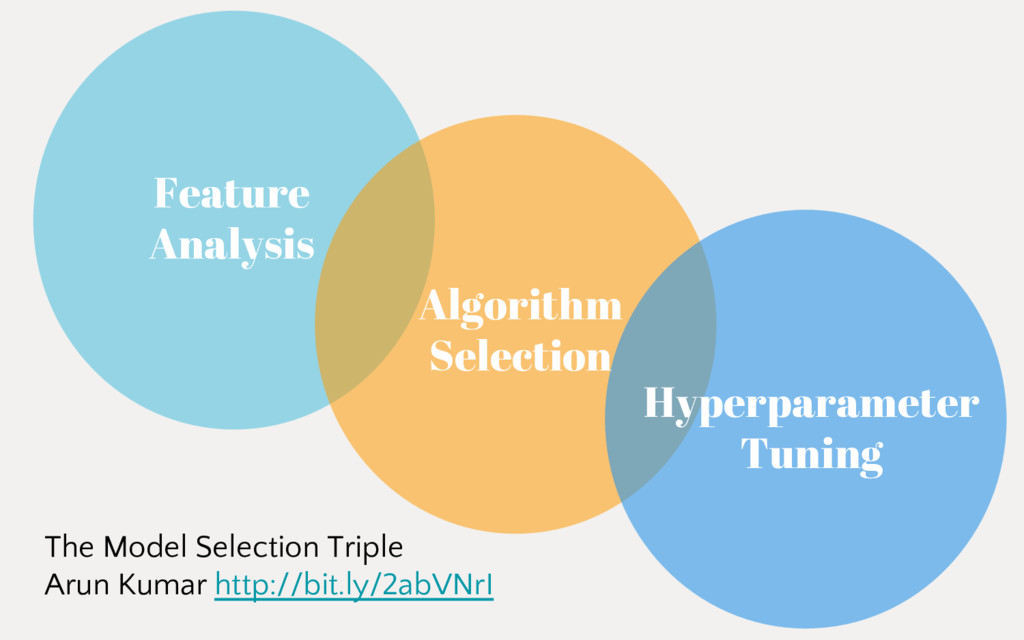
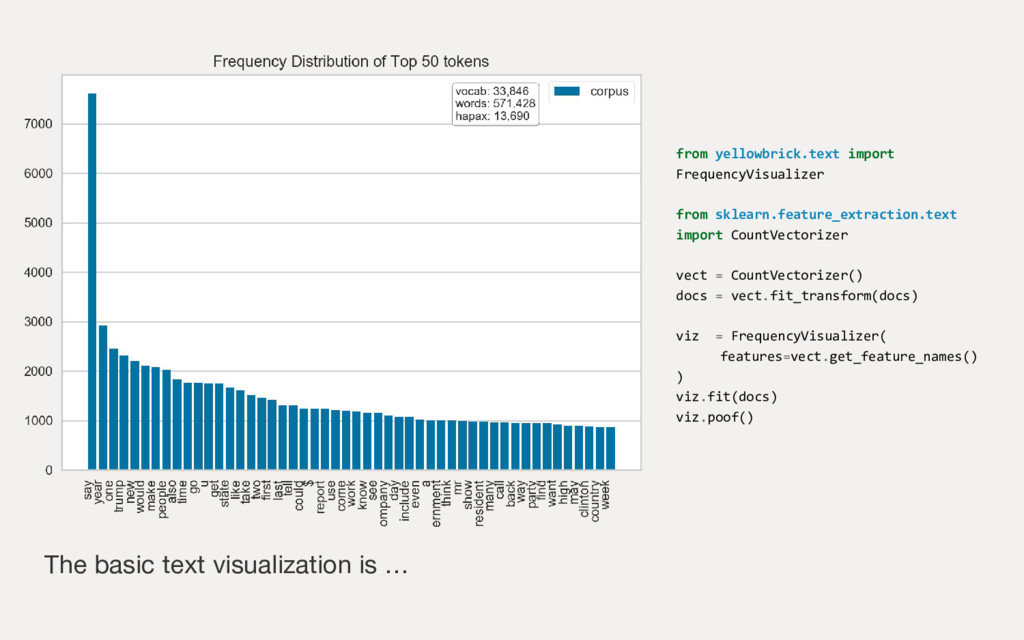
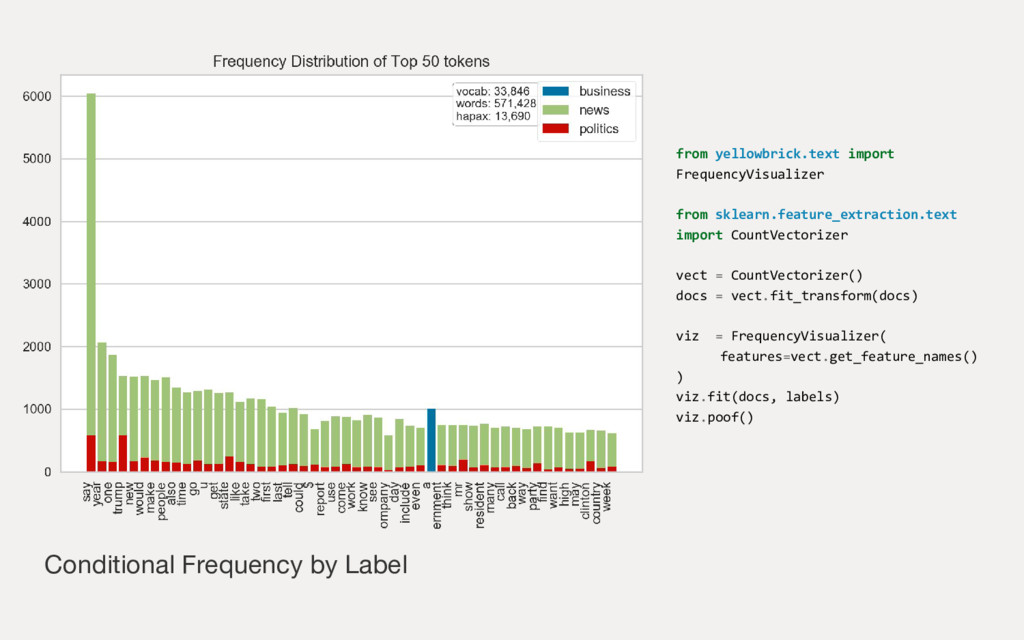
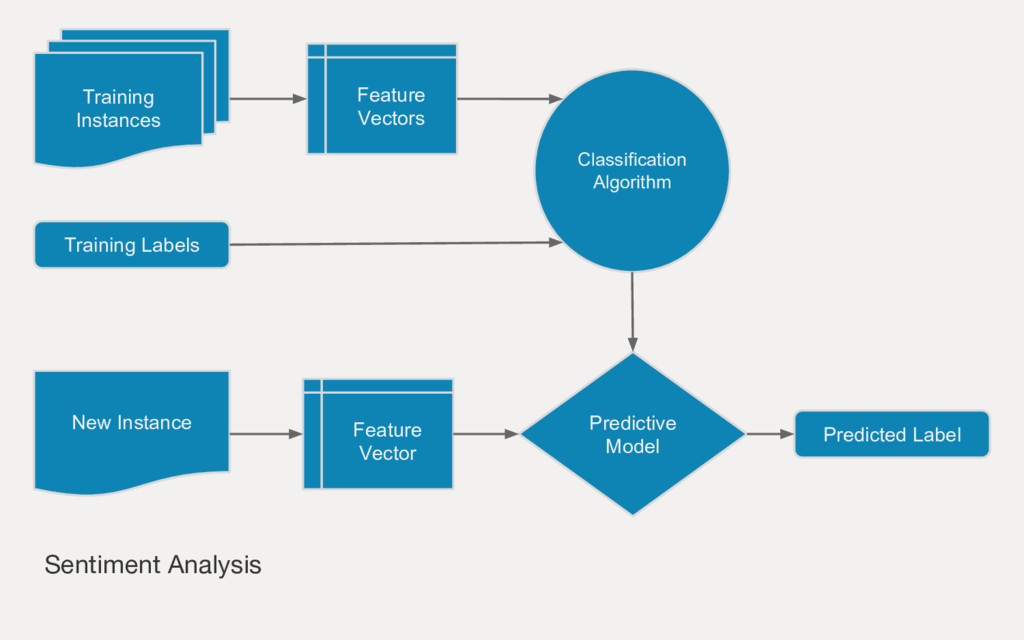
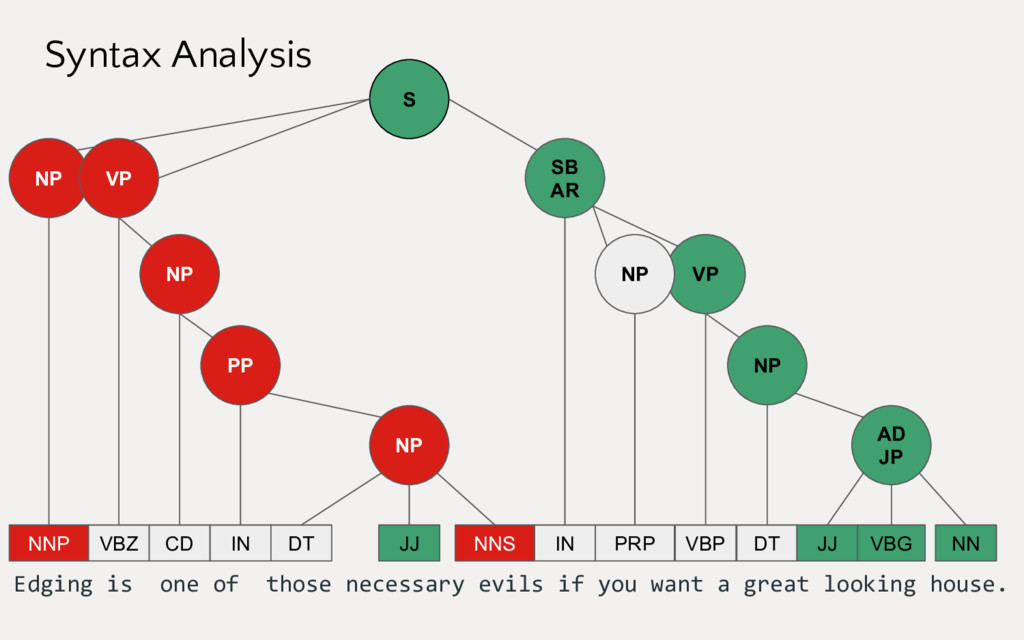
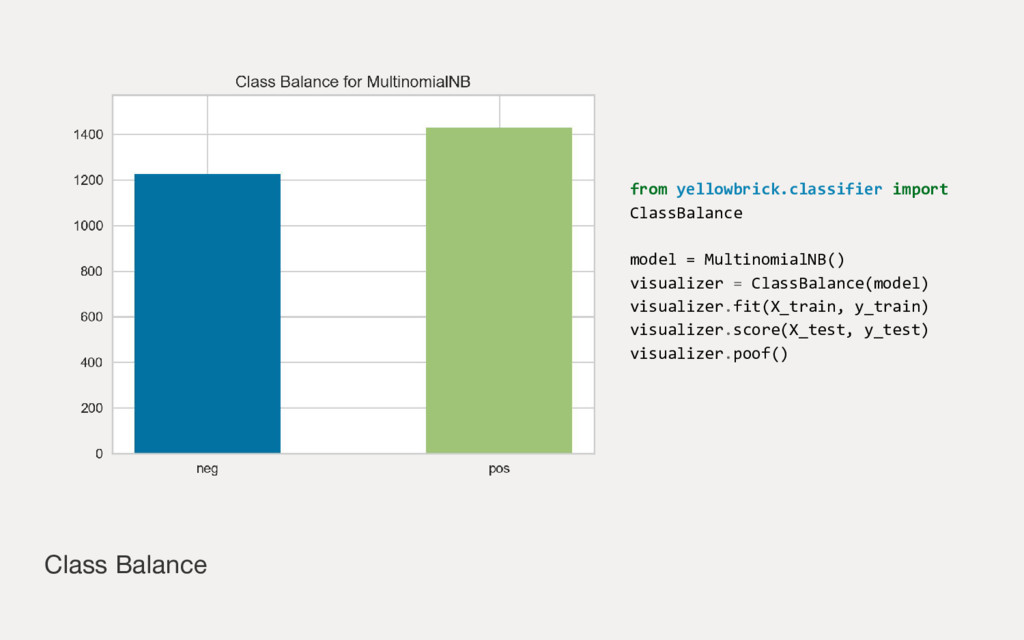
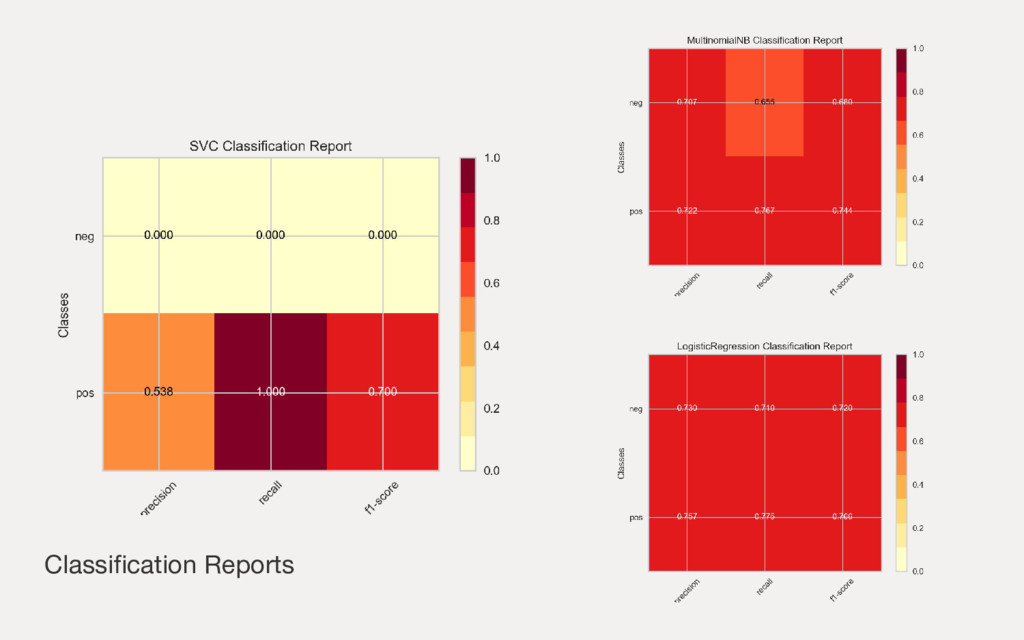
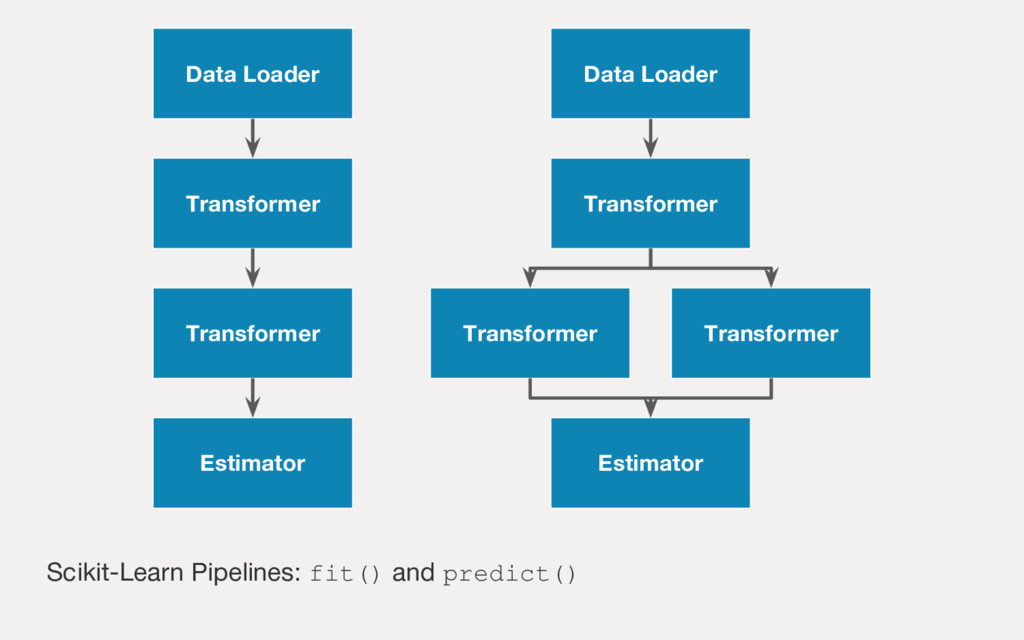
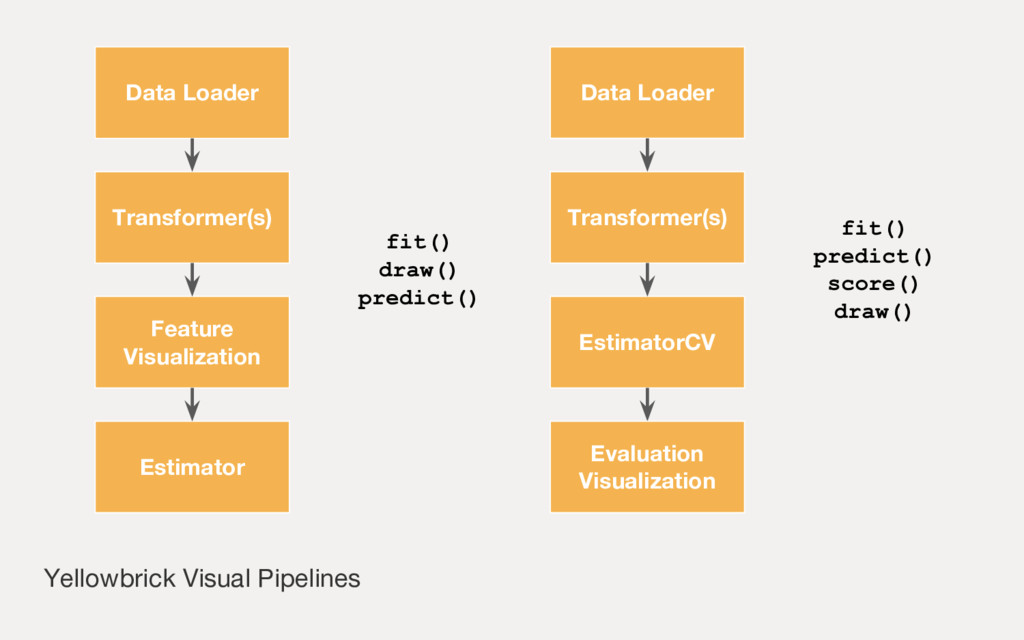
Employing machine learning in practice is half search, half expertise, and half blind luck. In this talk we will explore how to make the luck half less blind by using visual pipelines to steer model selection from raw input to operational prediction. We will look specifically at extending transformer pipelines with visualizers for sentiment analysis and topic modeling text corpora.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
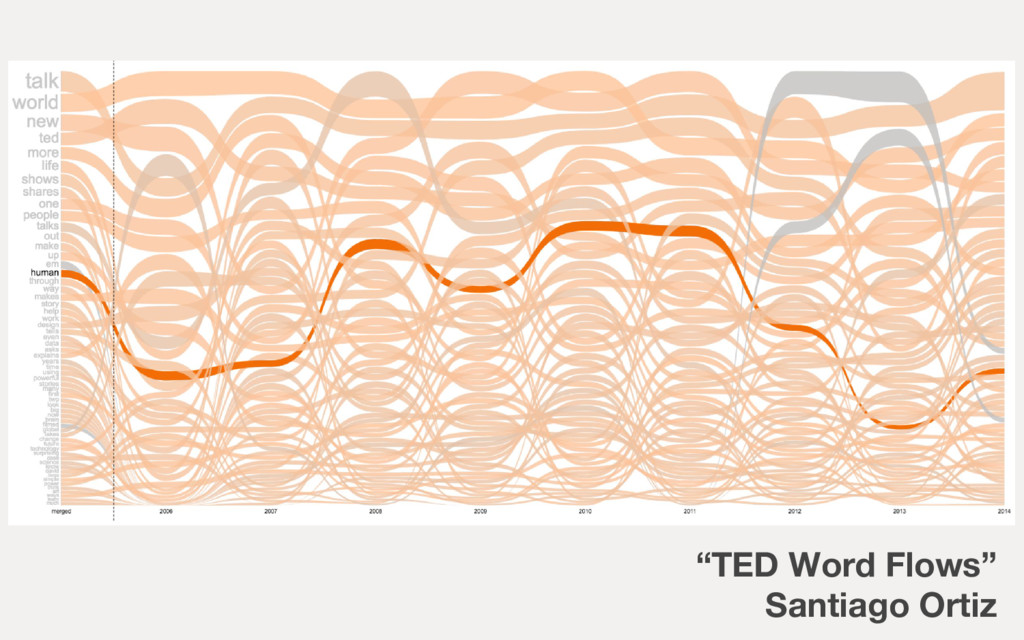{kind=link}
{kind=link}
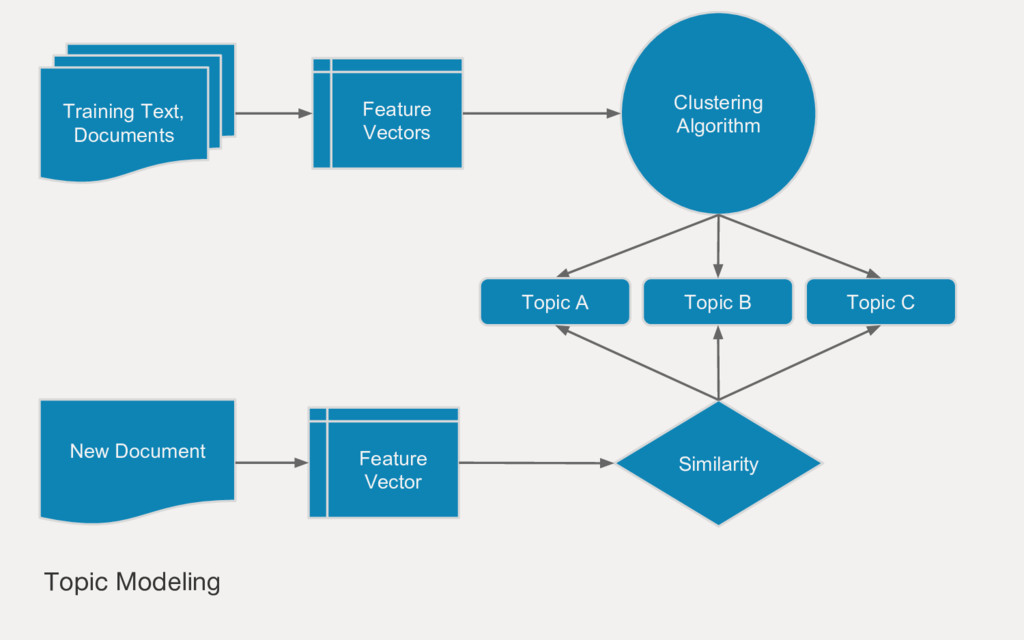{kind=link}
{kind=link}
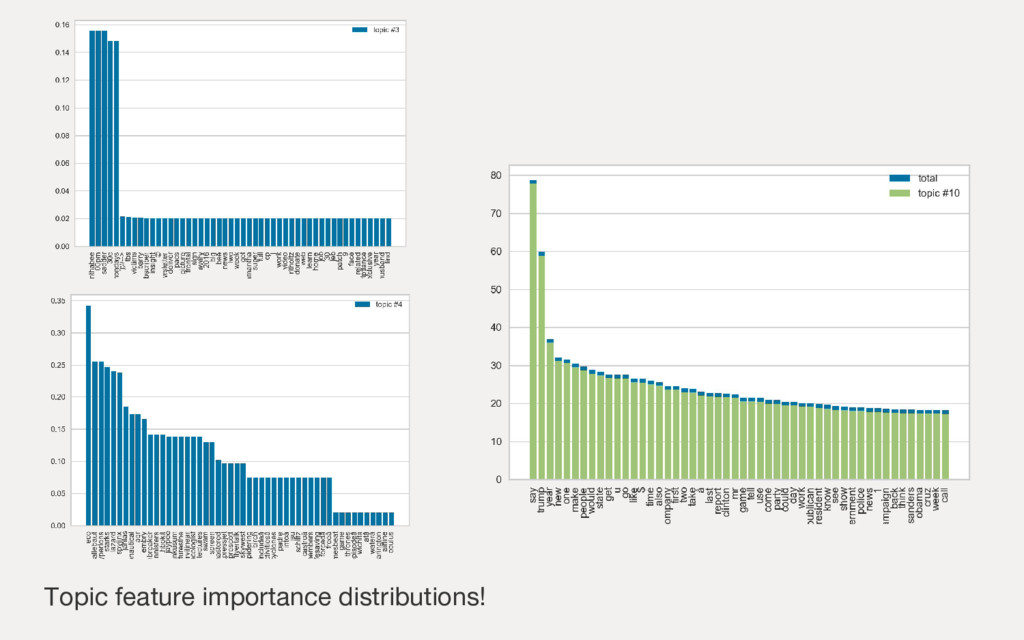{kind=link}
{kind=link}
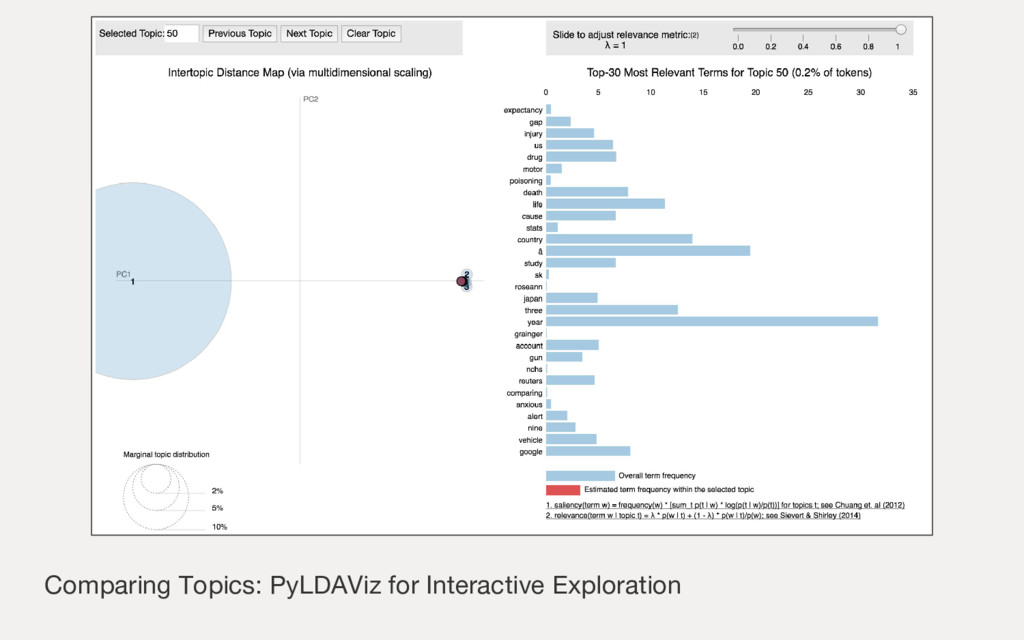{kind=link}
{kind=link}
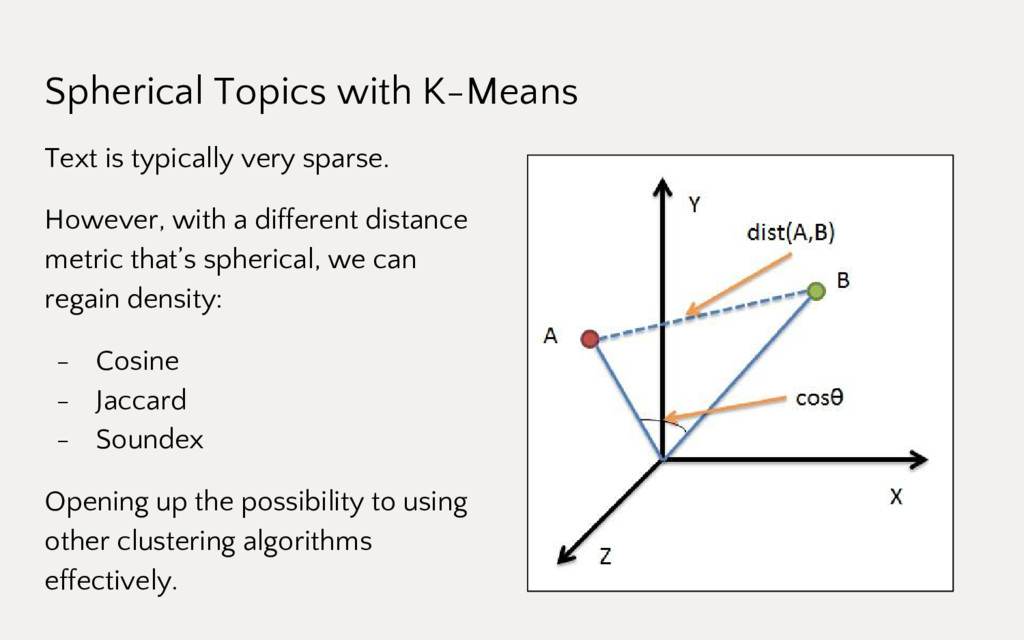{kind=link}
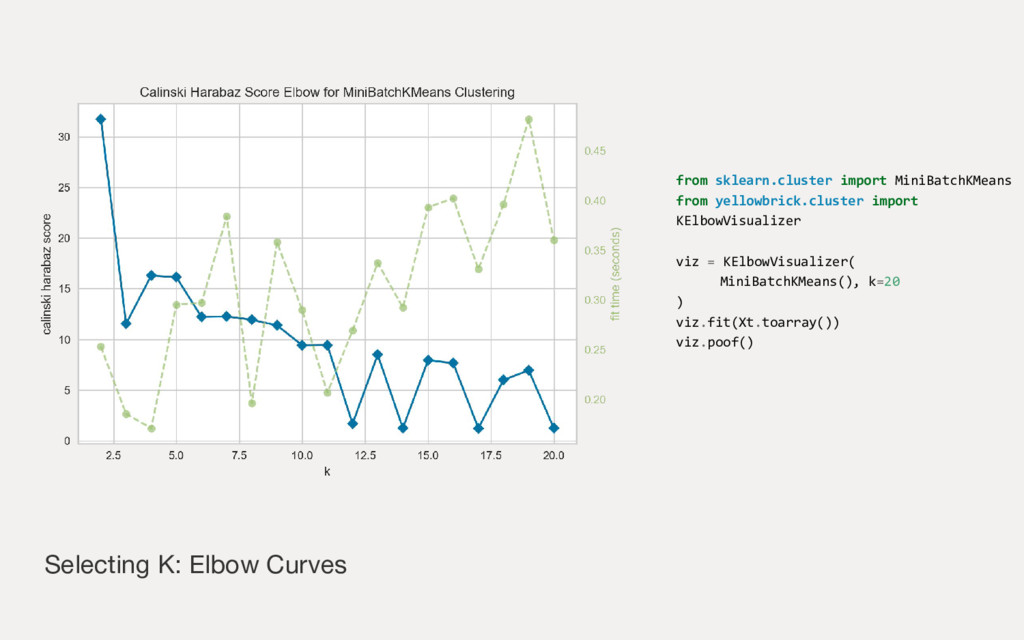{kind=link}
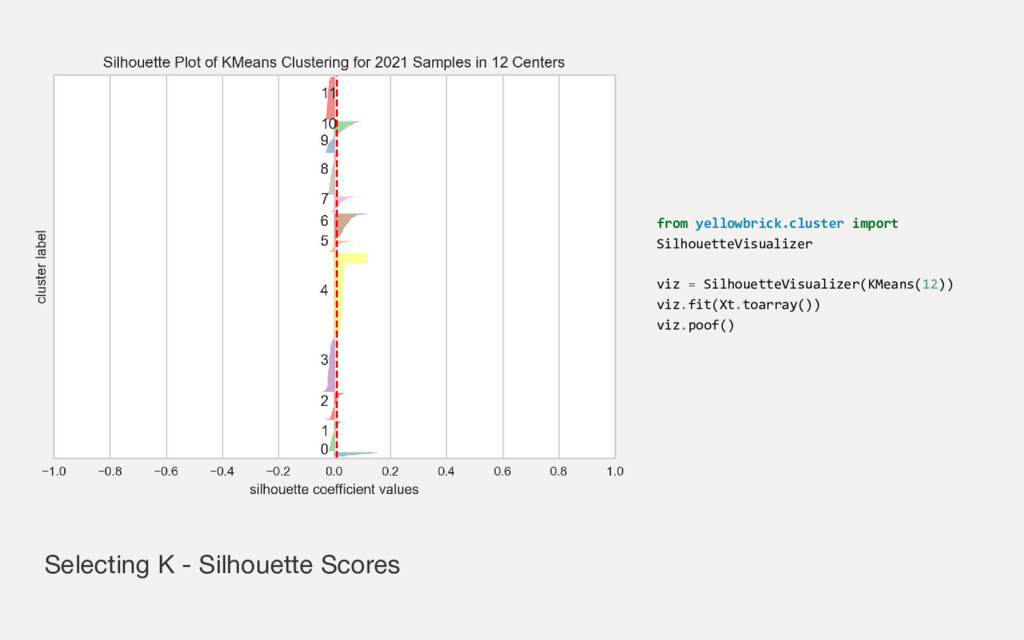{kind=link}
{kind=link}
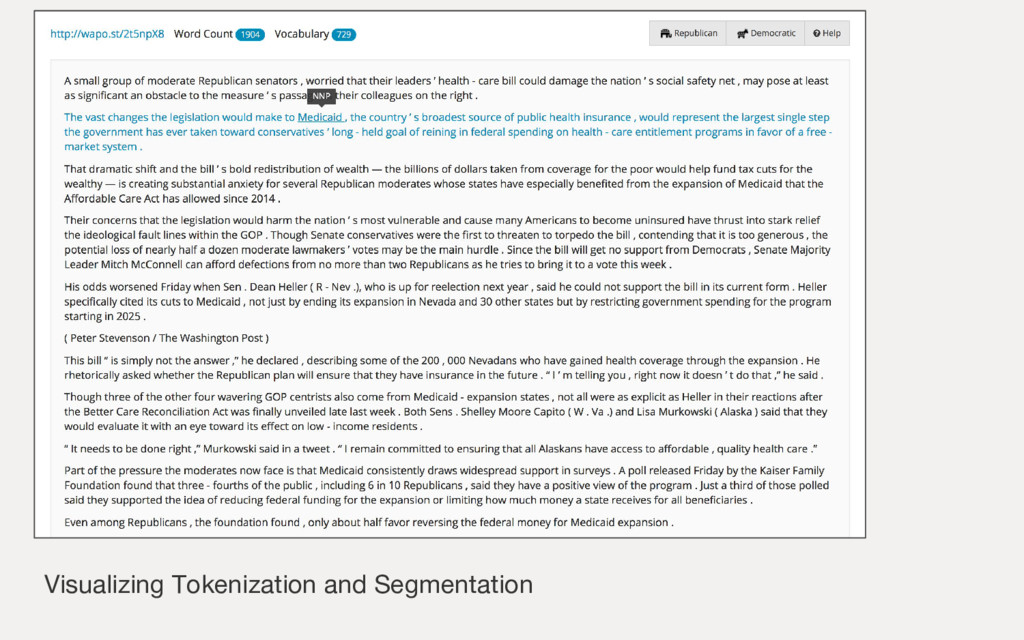{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}